����Ŀ¼
8-�����㷨
8.1 ��������
ʲô�Ǿ���,��������ʲô��
8.1.1 ����
����ѧϰ����ľ������ල��ѧϰ����,����Ŀ����Ϊ����֪����������ƶȽ���������������������DZ������Ԥ���Լ�����ѹ����ȥ��
DZ�����Ԥ��,����˵���Ի���ͨ��ijЩ���������ֶ����û����в�ͬ�ķ��ࡣ����ѹ������ָ���������й����,�Ϳ����ñȽ��ٵĵ�One-hot����������ԭ�����ر�������
����,�ȿ�����Ϊһ�������Ĺ���,Ҳ������Ϊ��������ѧϰ�����Ԥ����ģ�顣
8.1.2 ��������
����һ������ N N N�������������� X = { x 1 , x 2 , . . . , x N } X=\{x_1,x_2,...,x_N\} X={x1?,x2?,...,xN?},Ҫ������N����������һ�����ַ�ʽ,����Щ��������Ϊm�� C 1 , C 2 , C 3 , . . . , C m C_1,C_2,C_3,...,C_m C1?,C2?,C3?,...,Cm?,ʹ������
C i �� ? , i = 1 , 2 , . . . , m C_i\ne \phi,i=1,2,...,m Ci?��?=?,i=1,2,...,m
U i = 1 , 2 , . . , m C i = X U_{i=1,2,..,m}C_i=X Ui=1,2,..,m?Ci?=X
C i ? C j = ? , i �� j C_i\bigcap C_j=\phi,i\ne j Ci??Cj?=?,i��?=j
8.1.3 �㷨����
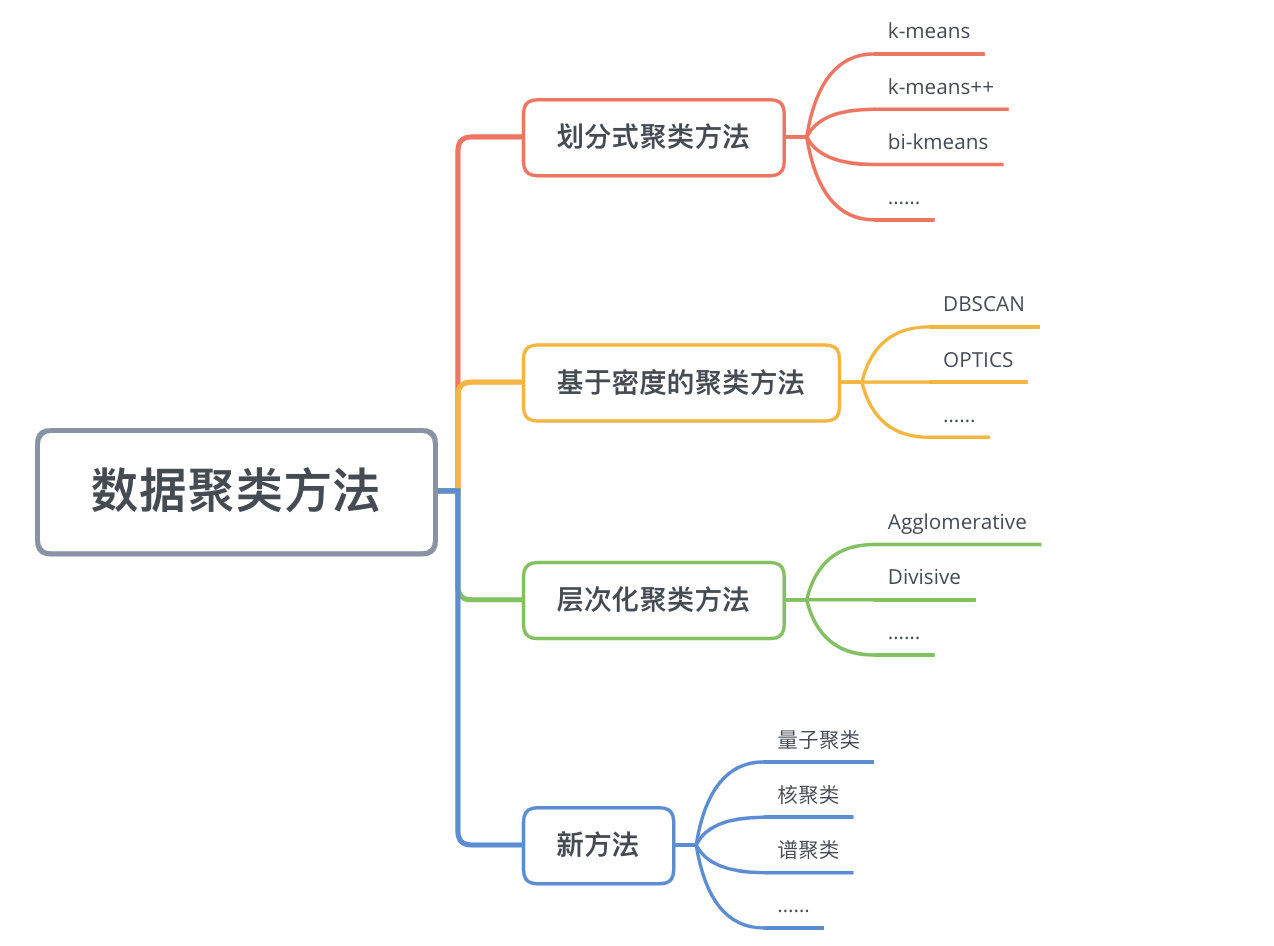
�����㷨��Ҫ��:
- ��ᷨ
- ������
- ������ʧ�������Ż���:K-means,���ʾ���
- �����ܶȵľ���
- ������������:��������㷨,����������㷨;�ӿռ�����㷨;���ں˵ľ������
��������
��Ȼ ��������Ǻܰ���,���Խ��С��������,������ۡ�,���Ǿ���ȷ�غܶ���Ӱ�졣
����:
1.����ѡ��ͬ,���²�ͬ�Ľ��
2.���ƶȶ�����ͬ,���²�ͬ�Ľ��
3.����ķ�����ͬ,���²�ͬ�Ľ����κ����ලѧϰ��ָ��
- ����ָ��
- �������
8.1.4 ��ѧ��
������������n������,ÿ��������m�����Ե������������,�������Ͽ����þ���X��ʾ:
X
=
[
x
i
j
]
m
��
n
=
[
x
11
x
12
?
x
1
n
x
21
x
22
?
x
2
n
?
?
?
?
x
m
1
x
m
2
?
x
m
n
]
X=[x_{ij}]_{m\times n}=\begin{bmatrix} x_{11}&x_{12}&\cdots&x_{1n} \\ x_{21}&x_{22}&\cdots&x_{2n} \\ \vdots &\vdots&\cdots&\vdots \\ x_{m1}&x_{m2}&\cdots&x_{mn} \end{bmatrix}
X=[xij?]m��n?=??????x11?x21??xm1??x12?x22??xm2???????x1n?x2n??xmn????????
������������X,
x
i
,
x
j
��
X
,
x
i
=
(
x
1
i
,
x
2
i
,
.
.
.
,
x
m
i
)
T
,
x
j
=
(
x
1
j
,
x
2
j
,
.
.
.
,
x
m
j
)
T
x_i,x_j\in X,x_i=(x_{1i},x_{2i},...,x_{mi})^T,x_j=(x_{1j},x_{2j},...,x_{mj})^T
xi?,xj?��X,xi?=(x1i?,x2i?,...,xmi?)T,xj?=(x1j?,x2j?,...,xmj?)T
1) ����
�� G G G��ʾ����,�� x i , x j x_i,x_j xi?,xj?��ʾ���е�����, N G N_G NG?��ʾ G G G�е���������, d i j d_{ij} dij?��ʾ���� x i x_i xi?������ x j x_j xj?֮��ľ���
���صĶ���
����������� ,������ G G G�е������������� x i , x j x_i,x_j xi?,xj?,�� d i j �� T d_{ij}\le T dij?��T, ��� G G G��ʾΪһ������
2) ���ص�����
-
��ľ�ֵ x �� G = 1 N G �� i = 1 N G x i \overline{x}_G=\frac{1}{N_G}\sum_{i=1}^{N_G}x_i xG?=NG?1?��i=1NG??xi?
-
���ֱ�� D G = m a x x i , x j �� G d i j D_G=max_{x_i,x_j\in G}d_{ij} DG?=maxxi?,xj?��G?dij?
-
�������ɢ������ A G = �� i = 1 N G ( x i ? x �� G ) ( x i ? x �� G ) T A_G=\sum_{i=1}^{N_G}(x_i-\overline{x}_G)(x_i-\overline{x}_G)^T AG?=��i=1NG??(xi??xG?)(xi??xG?)T
-
�����������
S G = 1 m ? 1 A G S_G=\frac{1}{m-1}A_G SG?=m?11?AG?
= 1 m ? 1 �� i = 1 N G ( x i ? x �� G ) ( x i ? x �� G ) T =\frac{1}{m-1}\sum_{i=1}^{N_G}(x_i-\overline{x}_G)(x_i-\overline{x}_G)^T =m?11?��i=1NG??(xi??xG?)(xi??xG?)T
3) ������֮��ľ���
�� C p C_p Cp?���� C q C_q Cq?֮��ľ��� D ( p , q ) D(p,q) D(p,q),Ҳ��Ϊ����
ǰ���ַ�������� C p C_p Cp?�� C q C_q Cq?֮��ľ������±���ʾ��
| ���ƶȶ�����(�����С) | |
|---|---|
| ��̾��������(Single-link) | $D_{pq}=min{d_{ij |
| ��������ȫ����(Complete-link) | $D_{pq}=max{d_{ij} |
| ���ľ��� | D p q = d x �� p x �� q D_{pq}=d_{\overline{x}_p\overline{x}_q} Dpq?=dxp?xq?? |
| ƽ������(UPGMA) | D p q = 1 C p C q �� x i �� C p �� x j �� C q d i j D_{pq}=\frac{1}{C_pC_q}\sum_{x_i \in C_p}\sum_{x_j \in C_q}d_{ij} Dpq?=Cp?Cq?1?��xi?��Cp??��xj?��Cq??dij? |
8.2 ����ָ��
���۾����㷨���ܺû���
�������ܶ������·�����,
һ���ǽ���������ij��"�ο�ģ��",���бȽ�,��Ϊ�ⲿָ��,
��һ����ֱ�Ӳο����������������κβο�ģ��,��Ϊ�ڲ�ָ��
8.2.1 �ⲿָ��
a = �O S S �O , S S = { ( x i , x j ) �O �� i = �� j , �� i ? = �� j ? , i < j } b = �O S D �O , S D = { ( x i , x j ) �O �� i = �� j , �� i ? �� �� j ? , i < j } c = �O D S �O , D S = { ( x i , x j ) �O �� i �� �� j , �� i ? = �� j ? , i < j } b = �O D D �O , D D = { ( x i , x j ) �O �� i �� �� j , �� i ? �� �� j ? , i < j } a=|SS|,SS=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*=\lambda_j^*,i<j\} \\ b=|SD|,SD=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda_i^*\ne\lambda_j^*,i<j\} \\ c=|DS|,DS=\{(x_i,x_j)|\lambda_i\ne \lambda_j,\lambda_i^*=\lambda_j^*,i<j\} \\ b=|DD|,DD=\{(x_i,x_j)|\lambda_i\ne\lambda_j,\lambda_i^*\ne\lambda_j^*,i<j\} a=�OSS�O,SS={(xi?,xj?)�O��i?=��j?,��i??=��j??,i<j}b=�OSD�O,SD={(xi?,xj?)�O��i?=��j?,��i??��?=��j??,i<j}c=�ODS�O,DS={(xi?,xj?)�O��i?��?=��j?,��i??=��j??,i<j}b=�ODD�O,DD={(xi?,xj?)�O��i?��?=��j?,��i??��?=��j??,i<j}
������������ࡣ
����a��ʾ
C
C
C����������ͬ��������
C
?
C^*
C?Ҳ������ͬ����������,
b
b
b��ʾ
C
C
C����������ͬ��������
C
?
C^*
C?�������ڲ�ͬ����������
| S | D | |
|---|---|---|
| S | |SS| | |SD| |
| D | |DS| | |DD| |
1) Jaccardϵ��
(Jaccard Coefficient,���JC)
J
C
=
a
a
+
b
+
c
JC=\frac{a}{a+b+c}
JC=a+b+ca?
2) FMָ��
Fowlkes adn Mallows Index,���FMI
F
M
I
=
a
a
+
b
?
a
a
+
c
FMI=\sqrt{\frac{a}{a+b}\cdot \frac{a}{a+c}}
FMI=a+ba??a+ca??
3) Ranָ��
��֪ a + b + c + d = m ( m ? 1 ) / 2 a+b+c+d=m(m-1)/2 a+b+c+d=m(m?1)/2
Rand Index,���RI
m��ʾ��������
R
=
a
+
d
a
+
b
+
c
+
d
=
2
(
a
+
d
)
m
(
m
?
1
)
R=\frac{a+d}{a+b+c+d}=\frac{2(a+d)}{m(m-1)}
R=a+b+c+da+d?=m(m?1)2(a+d)?
4) Mirkinָ��
M K = b + c a + b + c + d = 2 ( b + c ) m ( m ? 1 ) MK=\frac{b+c}{a+b+c+d}=\frac{2(b+c)}{m(m-1)} MK=a+b+c+db+c?=m(m?1)2(b+c)?
�������ܶ����Ľ������[0,1]֮��,ֵԽ��Խ��
����
����,һ����
5������,�ֳ�2�ء�
ʹ�þ������Ĵ�
| ��� | ���� |
|---|---|
| C 1 C_1 C1? | x 1 , x 2 , x 3 x_1,x_2,x_3 x1?,x2?,x3? |
| C 2 C_2 C2? | x 4 , x 5 x_4,x_5 x4?,x5? |
Ŀ���
| ��� | ���� |
|---|---|
| C 1 ? C_1^* C1?? | x 1 , x 2 , x 4 x_1,x_2,x_4 x1?,x2?,x4? |
| C 2 ? C_2^* C2?? | x 3 , x 5 x_3,x_5 x3?,x5? |
�����������ĺ�Ŀ���,����
a��ʾ C C C��
��������ͬ�������� C ? C^* C?Ҳ������ͬ������������ֻ�� ( x 1 , x 2 ) (x_1,x_2) (x1?,x2?)���������ӵ��������� C C C�� ( x 1 , x 2 ) (x_1,x_2) (x1?,x2?)���� C 1 C_1 C1?��,�� C ? C^* C?�� ( x 1 , x 2 ) (x_1,x_2) (x1?,x2?)���� C 1 C_1 C1?�ء�������������
| a=|SS| | ( x 1 , x 2 ) (x_1,x_2) (x1?,x2?) | 1 |
| b=|SD| | ( x 1 , x 3 ) , ( x 2 , x 3 ) , ( x 4 , x 5 ) (x_1,x_3),(x_2,x_3),(x_4,x_5) (x1?,x3?),(x2?,x3?),(x4?,x5?) | 3 |
| c=|DS| | ( x 1 , x 4 ) , ( x 2 , x 4 ) , ( x 3 , x 5 ) (x_1,x_4),(x_2,x_4),(x_3,x_5) (x1?,x4?),(x2?,x4?),(x3?,x5?) | 3 |
| d=|DD| | ( x 1 , x 5 ) , ( x 2 , x 5 ) , ( x 3 , x 4 ) (x_1,x_5),(x_2,x_5),(x_3,x_4) (x1?,x5?),(x2?,x5?),(x3?,x4?) | 3 |
������ⲿָ��Ϊ
J C = a a + b + c = 1 7 JC=\frac{a}{a+b+c}=\frac{1}{7} JC=a+b+ca?=71?
F M I = a a + b ? a a + c = 1 4 FMI=\sqrt{\frac{a}{a+b}\cdot \frac{a}{a+c}}=\frac{1}{4} FMI=a+ba??a+ca??=41?
R = 2 ( a + d ) m ( m ? 1 ) = 2 5 R=\frac{2(a+d)}{m(m-1)}=\frac{2}{5} R=m(m?1)2(a+d)?=52?
8.2.2 �ڲ�ָ��
���Ǿ������Ĵػ���
C
=
{
C
1
,
C
2
,
?
?
,
C
k
}
C=\{C_1,C_2,\cdots,C_k\}
C={C1?,C2?,?,Ck?}����
a
v
g
(
C
)
=
2
�O
C
�O
(
�O
C
�O
?
1
)
��
1
��
i
<
j
��
�O
C
�O
d
i
s
t
(
x
i
,
x
j
)
d
i
a
m
(
C
)
=
max
?
1
��
i
<
j
��
�O
C
�O
d
i
s
t
(
x
i
,
x
j
)
d
m
i
n
(
C
i
,
C
j
)
=
min
?
x
i
��
C
i
,
x
j
��
C
j
d
i
s
t
(
x
i
,
x
j
)
d
c
e
n
(
C
i
,
C
j
)
=
d
i
s
t
(
��
i
,
��
j
)
avg(C)=\frac{2}{|C|(|C|-1)}\sum_{1\le i<j\le|C|}dist(x_i,x_j) \\ diam(C)=\max_{1\le i<j\le|C|}dist(x_i,x_j) \\ d_{min}(C_i,C_j)=\min_{x_i\in C_i,x_j\in C_j} dist(x_i,x_j) \\ d_{cen}(C_i,C_j)=dist(\mu_i,\mu_j)
avg(C)=�OC�O(�OC�O?1)2?1��i<j���OC�O��?dist(xi?,xj?)diam(C)=1��i<j���OC�Omax?dist(xi?,xj?)dmin?(Ci?,Cj?)=xi?��Ci?,xj?��Cj?min?dist(xi?,xj?)dcen?(Ci?,Cj?)=dist(��i?,��j?)
�ٸ�����

avg?�C����������ƽ������
a
v
g
(
C
1
)
=
2
3
��
(
3
?
1
)
��
(
�O
x
1
?
x
2
�O
+
�O
x
1
?
x
3
�O
+
�O
x
2
?
x
3
�O
)
a
v
g
(
C
2
)
=
2
2
��
(
2
?
1
)
��
(
�O
x
4
?
x
5
�O
)
a
v
g
(
C
3
)
=
2
2
��
(
2
?
1
)
��
(
�O
x
6
?
x
7
�O
)
avg(C_1)=\frac{2}{3\times (3-1)}\times(|x_1-x_2|+|x_1-x_3|+|x_2-x_3|) \\ avg(C_2)=\frac{2}{2\times (2-1)}\times(|x_4-x_5|) \\ avg(C_3)=\frac{2}{2\times (2-1)}\times(|x_6-x_7|)
avg(C1?)=3��(3?1)2?��(�Ox1??x2?�O+�Ox1??x3?�O+�Ox2??x3?�O)avg(C2?)=2��(2?1)2?��(�Ox4??x5?�O)avg(C3?)=2��(2?1)2?��(�Ox6??x7?�O)
diam?�C����������������
d
i
a
m
(
C
1
)
=
�O
x
1
?
x
3
�O
d
i
a
m
(
C
2
)
=
�O
x
4
?
x
5
�O
d
i
a
m
(
C
3
)
=
�O
x
6
?
x
7
�O
diam(C_1)=|x_1-x_3| \\ diam(C_2)=|x_4-x_5| \\ diam(C_3)=|x_6-x_7|
diam(C1?)=�Ox1??x3?�Odiam(C2?)=�Ox4??x5?�Odiam(C3?)=�Ox6??x7?�O
dmin(Ci,Cj)�C�ؼ���������С����
d
m
i
n
(
C
1
,
C
2
)
=
�O
x
3
?
x
4
�O
d
m
i
n
(
C
2
,
C
3
)
=
�O
x
5
?
x
6
�O
d
m
i
n
(
C
1
,
C
3
)
=
�O
x
3
?
x
6
�O
dmin(C_1,C_2)=|x_3-x_4| \\ dmin(C_2,C_3)=|x_5-x_6| \\ dmin(C_1,C_3)=|x_3-x_6|
dmin(C1?,C2?)=�Ox3??x4?�Odmin(C2?,C3?)=�Ox5??x6?�Odmin(C1?,C3?)=�Ox3??x6?�O
dcen(Ci,Cj)�C�����ļ����
��
1
=
(
C
1
,
C
2
)
=
x
1
+
x
2
+
x
3
3
,
��
2
=
x
4
+
x
5
2
,
��
3
=
x
6
+
x
7
2
d
c
e
n
(
C
1
,
C
2
)
=
�O
��
1
?
��
2
�O
d
c
e
n
(
C
2
,
C
3
)
=
�O
��
2
?
��
2
�O
d
c
e
n
(
C
1
,
C
3
)
=
�O
��
1
?
��
3
�O
\mu_1=(C_1,C_2)=\frac{x_1+x_2+x_3}{3},\mu_2=\frac{x_4+x_5}{2},\mu_3=\frac{x_6+x_7}{2} \\ dcen(C_1,C_2)=|\mu_1-\mu_2| \\ dcen(C_2,C_3)=|\mu_2-\mu_2| \\ dcen(C_1,C_3)=|\mu_1-\mu_3|
��1?=(C1?,C2?)=3x1?+x2?+x3??,��2?=2x4?+x5??,��3?=2x6?+x7??dcen(C1?,C2?)=�O��1??��2?�Odcen(C2?,C3?)=�O��2??��2?�Odcen(C1?,C3?)=�O��1??��3?�O
DBָ��
D B I = 1 k �� i = 1 k max ? j �� i ( a v g ( C i ) + a v g ( C j ) d c e n ( �� i , �� j ) ) DBI=\frac{1}{k}\sum_{i=1}^k\max_{j\ne i}(\frac{avg(C_i)+avg(C_j)}{d_{cen}(\mu_i,\mu_j)}) DBI=k1?i=1��k?j��?=imax?(dcen?(��i?,��j?)avg(Ci?)+avg(Cj?)?)
Dunnָ��
D I = min ? 1 �� i �� k { min ? j �� i ( d m i n ( C i , C j ) max ? 1 �� l �� k d i a m ( C l ) } DI=\min_{1\le i\le k}\{\min_{j\ne i}(\frac{d_{min(C_i,C_j)}}{\max_{1\le l\le k}diam(C_l)}\} DI=1��i��kmin?{j��?=imin?(max1��l��k?diam(Cl?)dmin(Ci?,Cj?)??}
8.3 �������(���ƶ�)
����Խ��,���ƶ�ԽС
������������
n
n
n������,ÿ��������
m
m
m�����Ե������������,�������Ͽ����þ���
X
X
X��ʾ:
X
=
[
x
i
j
]
m
��
n
=
[
x
11
x
12
?
x
1
n
x
21
x
22
?
x
2
n
?
?
?
?
x
m
1
x
m
2
?
x
m
n
]
X=[x_{ij}]_{m\times n}=\begin{bmatrix} x_{11}&x_{12}&\cdots&x_{1n} \\ x_{21}&x_{22}&\cdots&x_{2n} \\ \vdots &\vdots&\cdots&\vdots \\ x_{m1}&x_{m2}&\cdots&x_{mn} \end{bmatrix}
X=[xij?]m��n?=??????x11?x21??xm1??x12?x22??xm2???????x1n?x2n??xmn????????
������������X,
x
i
,
x
j
��
X
,
x
i
=
(
x
1
i
,
x
2
i
,
.
.
.
,
x
m
i
)
T
,
x
j
=
(
x
1
j
,
x
2
j
,
.
.
.
,
x
m
j
)
T
x_i,x_j\in X,x_i=(x_{1i},x_{2i},...,x_{mi})^T,x_j=(x_{1j},x_{2j},...,x_{mj})^T
xi?,xj?��X,xi?=(x1i?,x2i?,...,xmi?)T,xj?=(x1j?,x2j?,...,xmj?)T
1) ����
- �Ǹ��� d i j �� 0 d_{ij}\ge 0 dij?��0
- ͬһ�� d i j = 0 d_{ij}=0 dij?=0,���ҽ��� i = j i=j i=j
- �Գ��� d i j = d j i d_{ij}=d_{ji} dij?=dji?
- ֱ���� d i j �� d i k + d k j d_{ij}\le d_{ik}+d_{kj} dij?��dik?+dkj?
2) �ɿɷ�˹������
d i j = ( �� k = 1 m �O x k i ? x k j �O p ) 1 p , p �� 1 d_{ij}=(\sum_{k=1}^m|x_{ki}-x_{kj}|^p)^{\frac{1}{p}},p\ge 1 dij?=(��k=1m?�Oxki??xkj?�Op)p1?,p��1
ŷ�Ͼ���
����֮��ֱ�����
�� p = 2 p=2 p=2ʱ��Ϊŷ�Ͼ���(Euclidean distance)
d i j = ( �� k = 1 m �O x k i ? x k j �O 2 ) 1 2 d_{ij}=(\sum_{k=1}^m|x_{ki}-x_{kj}|^2)^{\frac{1}{2}} dij?=(��k=1m?�Oxki??xkj?�O2)21?
�����پ���
��p=1ʱ��Ϊ�����پ���(Manhattan distance)
d i j = �� k = 1 m �O x k i ? x k j �O d_{ij}=\sum_{k=1}^m|x_{ki}-x_{kj}| dij?=��k=1m?�Oxki??xkj?�O
�б�ѩ�����
��p= �� \infty ��ʱ��Ϊ�б�ѩ�����(Chebyshev distance)
d i j = m a x k �O x k i ? x k j �O d_{ij}=max_k|x_{ki}-x_{kj}| dij?=maxk?�Oxki??xkj?�O
3) ������ŵ��˹����
����һ��������
X
X
X,
X
=
[
x
i
j
]
m
��
n
X=[x_{ij}]_{m \times n}
X=[xij?]m��n?,��Э�������ΪS,����
x
i
x_i
xi?������
x
j
x_j
xj?֮���������ŵ��˹�������
d
i
j
d_{ij}
dij?����Ϊ
d
i
j
=
[
(
x
i
?
x
j
)
T
S
?
1
(
x
i
?
x
j
)
]
1
2
x
i
=
(
x
1
i
,
x
2
i
,
.
.
.
,
x
m
i
)
T
,
x
j
=
(
x
1
j
,
x
2
j
,
.
.
.
,
x
m
j
)
T
d_{ij}=[(x_i-x_j)^TS^{-1}(x_i-x_j)]^{\frac{1}{2}} \\ x_i=(x_{1i},x_{2i},...,x_{mi})^T,x_j=(x_{1j},x_{2j},...,x_{mj})^T
dij?=[(xi??xj?)TS?1(xi??xj?)]21?xi?=(x1i?,x2i?,...,xmi?)T,xj?=(x1j?,x2j?,...,xmj?)T
4) ���ϵ��
����
x
i
x_i
xi?������
x
j
x_j
xj?֮������ϵ������Ϊ:
r
i
j
=
��
k
=
1
m
(
x
k
i
?
x
��
i
)
(
x
k
j
?
x
��
j
)
[
��
k
=
1
m
(
x
k
i
?
x
��
i
)
2
��
k
=
1
m
(
x
k
j
?
x
��
j
)
2
]
1
2
x
��
i
=
1
m
��
k
=
1
m
x
k
i
,
x
��
j
=
1
m
��
k
=
1
m
x
k
j
r_{ij}=\frac{\sum_{k=1}^m(x_{ki}-\overline{x}_i)(x_{kj}-\overline{x}_j)}{[\sum_{k=1}^m(x_{ki}-\overline{x}_i)^2\sum_{k=1}^m(x_{kj}-\overline{x}_j)^2]^{\frac{1}{2}}} \\ \overline{x}_i=\frac{1}{m}\sum_{k=1}^mx_{ki},\overline{x}_j=\frac{1}{m}\sum_{k=1}^mx_{kj}
rij?=[��k=1m?(xki??xi?)2��k=1m?(xkj??xj?)2]21?��k=1m?(xki??xi?)(xkj??xj?)?xi?=m1?k=1��m?xki?,xj?=m1?k=1��m?xkj?
5) �����
s i j = �� k = 1 m x k i x k j [ �� k = 1 m x k i 2 �� k = 1 m x k j 2 ] 1 2 s_{ij}=\frac{\sum_{k=1}^mx_{ki}x_{kj}}{[\sum_{k=1}^mx_{ki}^2\sum_{k=1}^mx_{kj}^2]^\frac{1}{2}} sij?=[��k=1m?xki2?��k=1m?xkj2?]21?��k=1m?xki?xkj??
�����
https://zhuanlan.zhihu.com/p/100557559
8.4 ԭ�;���(����ʽ����)
8.4.1 K��ֵ(k-means)
1) ����
K-means�ǻ�����ʧ������С����˼���,����������
D
=
{
x
1
,
x
2
,
��
,
x
m
}
D=\{x_1,x_2,\dots,x_m\}
D={x1?,x2?,��,xm?},����ֺ��Ϊ
C
=
{
c
1
,
c
2
,
��
,
c
k
}
C=\{c_1,c_2,\dots,c_k\}
C={c1?,c2?,��,ck?},K-means����ʧ��������Ϊ:
E
=
��
i
=
1
k
��
x
��
C
i
�O
�O
x
?
��
i
�O
�O
2
��
i
=
1
�O
C
i
�O
��
x
��
C
i
x
E=\sum_{i=1}^k\sum_{x\in C_i}||x-\mu_i||^2 \\ \mu_i=\frac{1}{|C_i|}\sum_{x\in C_i}x
E=i=1��k?x��Ci?��?�O�Ox?��i?�O�O2��i?=�OCi?�O1?x��Ci?��?x
��
i
\mu_i
��i? �Ǵ�
C
i
C_i
Ci?�ľ�ֵ����
��ȻҪ��С���������,��ôֻҪ�Ѹ��������鵽���Լ�������Ǹ�����������
˵�˻�����
����֮���ŷ�Ͼ���Ϊ d i j = �� k = 1 m ( x k i ? x k j ) 2 = �O �O x i ? x j �O �O 2 d_{ij}=\sum_{k=1}^m(x_{ki}-x_{kj})^2=||x_i-x_j||^2 dij?=��k=1m?(xki??xkj?)2=�O�Oxi??xj?�O�O2
��ʧ����Ϊ����������������֮�������ܺ�: W ( C ) = �� l = 1 k �� C ( i ) = l �O �O x i ? x �� l �O �O 2 W(C)=\sum_{l=1}^k\sum_{C(i)=l}||x_i-\overline{x}_l||^2 W(C)=��l=1k?��C(i)=l?�O�Oxi??xl?�O�O2
x �� l = { x �� 1 l , x �� 2 l , �� , x �� m l } \overline{x}_l=\{\overline{x}_{1l},\overline{x}_{2l},\dots,\overline{x}_{ml}\} xl?={x1l?,x2l?,��,xml?}Ϊ��I��ľ�ֵ��������, W ( C ) W(C) W(C)��Ϊ��������
k��ֵ�������������Ż�����: C ? = a r g m i n W ( C ) = a r g m i n C �� l = 1 k �� C ( i ) = l �O �O x i ? x �� l �O �O 2 C^*=argminW(C)=argmin_{C}\sum_{l=1}^k\sum_{C(i)=l}||x_i-\overline{x}_l||^2 C?=argminW(C)=argminC?��l=1k?��C(i)=l?�O�Oxi??xl?�O�O2
2) �㷨�Ƶ�

����: n n n�������ļ��� X X X
���:�������ϵľ��� C ? C^* C?
-
��ʼ��,�� t = 0 t=0 t=0,���ѡ�� k k k����������Ϊ��ʼ��������
m ( 0 ) = ( m 1 ( 0 ) , �� , m l ( 0 ) , �� , m k ( 0 ) ) m^{(0)}=(m_1^{(0)},\dots,m_l^{(0)},\dots,m_k^{(0)}) m(0)=(m1(0)?,��,ml(0)?,��,mk(0)?)
-
���������о���,�Թ̶��������� m ( t ) = ( m 1 ( t ) , �� , m l ( t ) , �� , m k ( t ) ) m^{(t)}=(m_1^{(t)},\dots,m_l^{(t)},\dots,m_k^{(t)}) m(t)=(m1(t)?,��,ml(t)?,��,mk(t)?),���� m k ( t ) m_k^{(t)} mk(t)?Ϊ�� C l C_l Cl?������,
����ÿ�������������ĵľ���,��ÿ������ָ�ɵ�������������ĵ�����,���ɾ����� C ( t ) C^(t) C(t)
-
�����µ�������,�Ծ����� C ( t ) C^{(t)} C(t),���㵱ǰ�������е������ľ�ֵ,��Ϊ�µ�������
m ( t + 1 ) = ( m 1 ( t + 1 ) , �� , m l ( t + 1 ) , �� , m k ( t + 1 ) ) m^{(t+1)}=(m_1^{(t+1)},\dots,m_l^{(t+1)},\dots,m_k^{(t+1)}) m(t+1)=(m1(t+1)?,��,ml(t+1)?,��,mk(t+1)?)
-
����������������ֹͣ����,��� C ? = C ( t ) C^*=C^{(t)} C?=C(t),������ t = t + 1 t=t+1 t=t+1
�㷨���Ӷ� O ( m n k ) O(mnk) O(mnk),����mΪ����ά��,nΪ��������,kΪ������
3) ����
��������
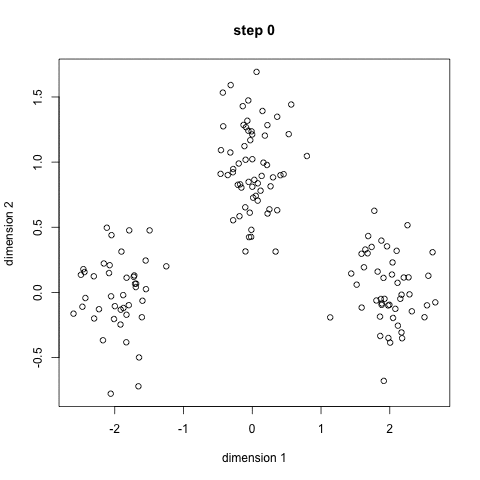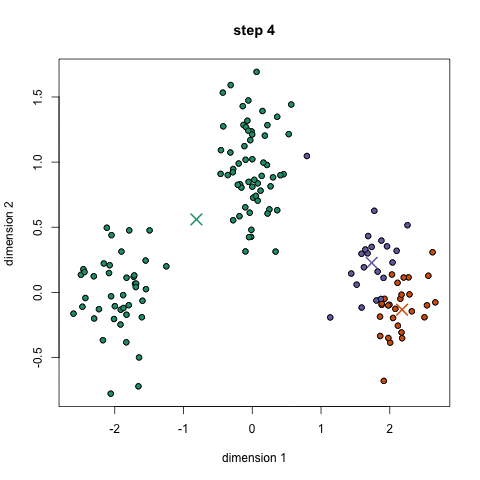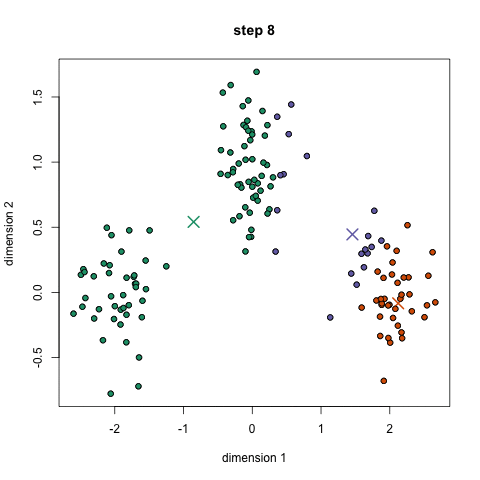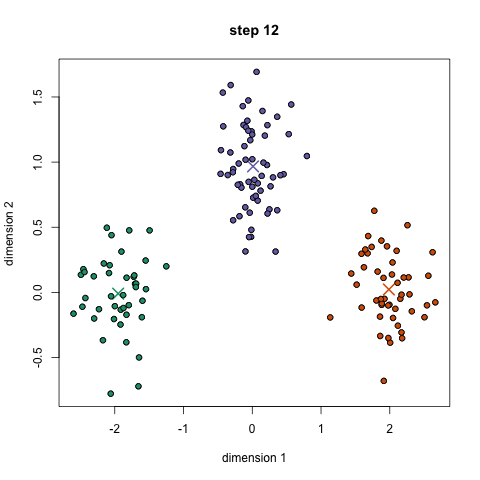
import re
import random
import scipy.io as sio
import numpy as np
import matplotlib.pyplot as plt
from time import *
from sklearn.datasets import make_blobs
def find_closet_centroids(X, centroids):
"""
�����������
"""
result = []
for x in X:
# ����ÿ���� �����ĵ�ľ���
distance = np.sum((x - centroids) ** 2, axis=1)
# ��ȡÿ���㵽�ĸ����ĵ��λ����С,�ͻ���Ϊ����
result.append(np.argmin(np.sqrt(distance)))
# print(result)
# [0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 0 ��ʾ�ǵ�1 ��
# 2 ��ʾ�ǵ�2 ��
return np.array(result)
def compute_centroids(X, idx):
"""
�����µĴ�����
"""
# K��һ���ֳɵ�����
K = int(np.max(idx)) + 1
# mΪX������,300,
# n ����2
m = X.shape[0]
n = X.shape[-1]
# �µĴ�����
centroids = np.zeros((K, n))
# ����ÿ����,�ж��ٸ�
counts = np.zeros((K,n))
for i in range(m):
centroids[int(idx[i])] += X[i]
counts[int(idx[i])] += 1
# �Դ�����,����ƽ��ֵ���õ��ľ����µĴ�����
centroids = centroids / counts
# print(counts)
return centroids
def cost(X, idx, centrodis):
"""
������ʧ����
:param X:
:param idx:
:param centrodis:
:return:
"""
c = 0
for i in range(len(X)):
c += np.sum((X[i] - centrodis[int(idx[i])]) ** 2)
c /= len(X)
return c
def random_initialization(X, K):
"""
���ѡ��K������,��Ϊ������
:param X: ndarray,���е�
:param K: int,���������
:return: ndarray,������
"""
res = np.zeros((1, X.shape[-1]))
m = X.shape[0]
rl = []
while True:
index = random.randint(0, m)
if index not in rl:
rl.append(index)
if len(rl) >= K:
break
for index in rl:
res = np.concatenate((res, X[index].reshape(1, -1)), axis=0)
return res[1:]
def k_means(X, K):
"""
k-means�����㷨,
:param X: ndarray,�������
:param K: int,�ֳɾ��������
:return: tuple,(idx, centroids_all)
idx,ndarray Ϊÿ�������������ǩ
centroids_all,[ndarray,...]���������ÿ�ֵĴ�����
"""
centroids = random_initialization(X, K)
centroids_all = [centroids]
idx = np.zeros((1,))
last_c = -1
now_c = -2
# iterations = 200
# for i in range(iterations):
while now_c != last_c: # ������ʱ�����㷨,���߿�������ָ����������
# ���ÿ������������
idx = find_closet_centroids(X, centroids)
last_c = now_c
# ������ʧ����
now_c = cost(X, idx, centroids)
# �������¹滮��Ĵ���,���¹滮�������ĵ�
centroids = compute_centroids(X, idx)
# ��¼ѵ�����������е����ĵ�
centroids_all.append(centroids)
return idx, centroids_all
def visualizing(X, idx, centroids_all):
"""
���ӻ��������ʹ����ĵ��ƶ�����
:param X: ndarray,�������
:param idx: ndarray,ÿ�������������ǩ
:param centroids_all: [ndarray,...]���������ÿ�ֵĴ�����
:return: None
"""
# ����ͼ��
plt.scatter(X[..., 0], X[..., 1], c=idx)
xx = []
yy = []
for c in centroids_all:
xx.append(c[..., 0])
yy.append(c[..., 1])
plt.plot(xx, yy, 'rx--')
plt.show()
if __name__ == '__main__':
begin_time = time()
print("========����ʼ============")
# data = sio.loadmat("ex7data2.mat")
# X = np.array(data['X']) # (300,2)
# �������5������
X, y = make_blobs(centers=5, random_state=20, cluster_std=1)
# print(x)
idx, centroids_all = k_means(X, 5)
visualizing(X, idx, centroids_all)
end_time = time()
run_time = end_time - begin_time
print("========�������============")
print('��ѭ����������ʱ��:', run_time)
4) ��ȱ��
�ŵ�:
ԭ���Ƚϼ�,ʵ��Ҳ�Ǻ�����,�����ٶȿ�;����Ч������;�㷨�Ŀɽ��ͶȱȽ�ǿ;��Ҫ��Ҫ���εIJ��������Ǵ���k��
ȱ��:
1���������ĵĸ���K��Ҫ���ȸ���,���Kֵ��ѡ���Ƿdz����Թ��Ƶġ��ܶ�ʱ��,���Ȳ���֪�����������ݼ�Ӧ�÷ֳɶ��ٸ����������;һ��ͨ��������֤ȷ��;
2����ͬ�ij�ʼ�������Ŀ��ܵ�����ȫ��ͬ�ľ��������㷨�ٶ������ڳ�ʼ���ĺû�,��ʼ�ʵ���벻��̫��;
3������������������ݲ�ƽ��,�����������������������ʧ��,���߸��������ķ��ͬ,�����Ч������;
4���÷��������ڷ��ַ�����״�Ĵػ��С���ܴ�Ĵ�,���ڲ��������ݼ��Ƚ�������;
5�����������쳣��Ƚϵ����С�
6�����������ھ�ֵ(����������)��
7�����õ�������,�õ��Ľ��ֻ�Ǿֲ����š�
8.4.2 LVQ
8.4.3 ��˹��Ͼ���GMM
1) ����
��˹���ģ��(GMM)���Կ�����k-meansģ�͵�һ���Ż���������һ�ֹ�ҵ�糣�õļ����ֶ�,Ҳ��һ������ʽģ�͡�
��˹���ģ����ͼ�ҵ���ά��˹ģ���ʷֲ��Ļ�ϱ�ʾ,�Ӷ���ϳ�������״�����ݷֲ�������ij�����,GMM��������k-means��ͬ�ķ�ʽ���о��ࡣ
ֻ�ǽ���˹�ֲ�����Ҷ˹��ʽ��������Ȼ���;�����˼·�������һ�ַ�����,���ױ�������ȥ�е���������ġ�
2) ��ѧ��
a) ��˹�ֲ�
�����Ǹ�˹�ֲ��ĸ����˹�ֲ�����̬�ֲ���һ�������������֪��һԪ��̬�ֲ��ı���ʽ��������������:
f
(
x
)
=
1
2
��
��
e
?
(
x
?
��
)
2
2
��
2
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
f(x)=2��?��1?e?2��2(x?��)2?
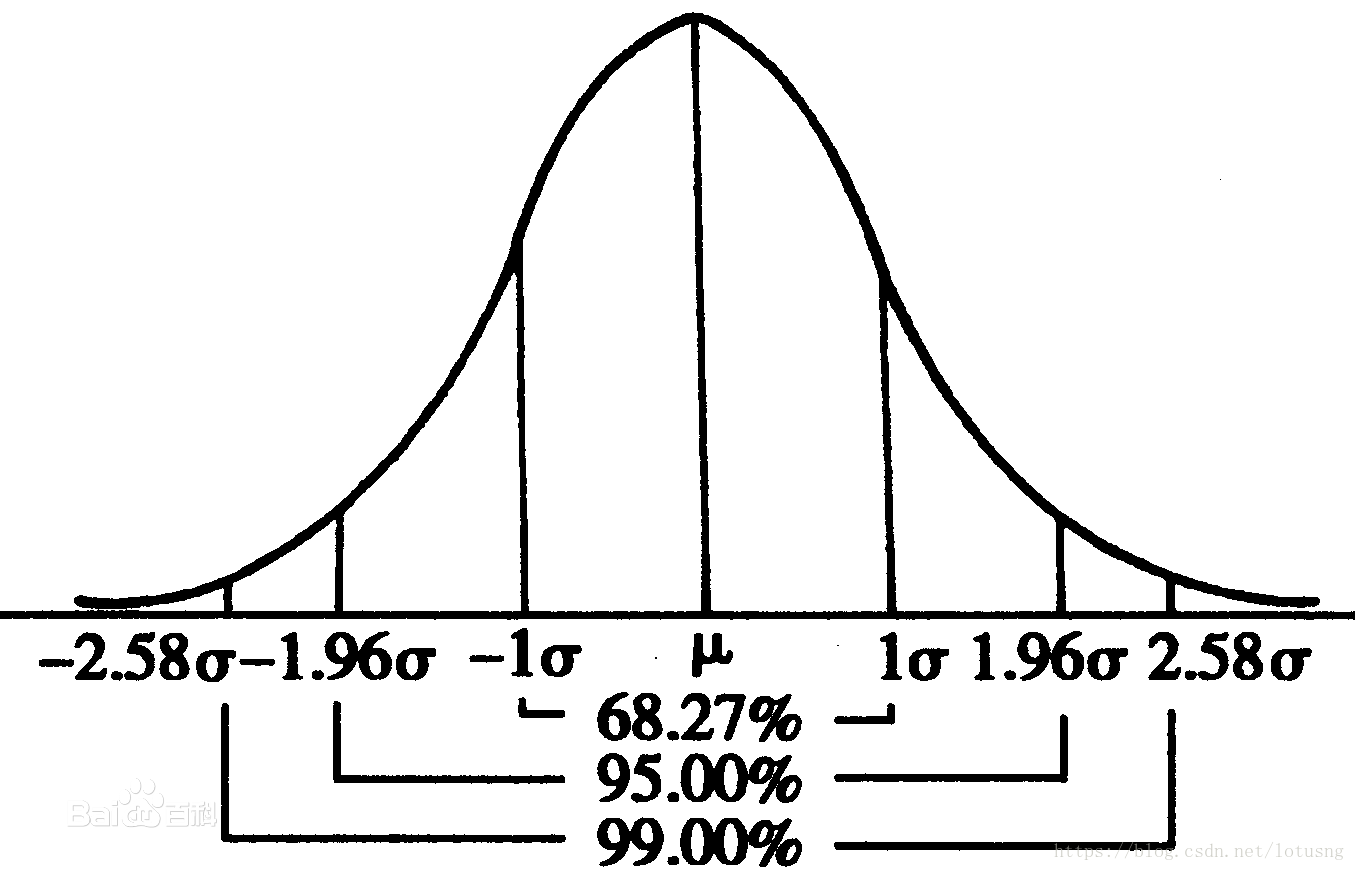
��̬�ֲ����Լ�Ϊ N ( �� , �� 2 ) N(\mu,\sigma^2) N(��,��2),������Ĺ�ʽ�����Կ��Կ���һԪ��̬�ֲ�ֻ���������� �� \mu ���� �� \sigma ��,��������������������̬���ߵġ���խ�������߰����� ���������Ϊ1��
b) ��Ԫ��˹�ֲ�
���ϲο�
https://www.cnblogs.com/bingjianing/p/9117330.html
https://www.zhihu.com/question/36339816
�ȼ���n������ x = [ x 1 , x 2 , �� , x n ] T x=[x_1,x_2,\dots,x_n]^T x=[x1?,x2?,��,xn?]T,�ҷ�����̬�ֲ�(ά�Ȳ���ض�Ԫ��̬�ֲ�),
����ά�ȵľ�ֵ E ( x ) = [ �� 1 , �� 2 , �� , �� n ] T E(x)=[\mu_1,\mu_2,\dots,\mu_n]^T E(x)=[��1?,��2?,��,��n?]T,
���� �� ( x ) = [ �� 1 , �� 2 , �� , �� n ] T \sigma(x)=[\sigma_1,\sigma_2,\dots,\sigma_n]^T ��(x)=[��1?,��2?,��,��n?]T
�������ϸ����ܶȹ�ʽ:
f
(
x
)
=
p
(
x
1
,
x
2
,
��
,
x
n
)
=
p
(
x
1
)
p
(
x
2
)
��
p
(
x
n
)
=
1
(
2
��
)
n
��
1
��
2
��
��
n
e
?
(
x
1
?
��
1
)
2
2
��
1
2
?
(
x
2
?
��
2
)
2
2
��
2
2
?
?
(
x
n
?
��
n
)
2
2
��
n
2
f(x)=p(x_1,x_2,\dots,x_n)=p(x_1)p(x_2)\dots p(x_n) \\ =\frac{1}{(\sqrt{2\pi})^n\sigma_1\sigma_2\dots\sigma_n}e^{-\frac{(x_1-\mu_1)^2}{2\sigma_1^2}-\frac{(x_2-\mu_2)^2}{2\sigma_2^2}\dots-\frac{(x_n-\mu_n)^2}{2\sigma_n^2}}
f(x)=p(x1?,x2?,��,xn?)=p(x1?)p(x2?)��p(xn?)=(2��?)n��1?��2?����n?1?e?2��12?(x1??��1?)2??2��22?(x2??��2?)2???2��n2?(xn??��n?)2?
��
z
2
=
?
(
x
1
?
��
1
)
2
2
��
1
2
?
(
x
2
?
��
2
)
2
2
��
2
2
?
?
(
x
n
?
��
n
)
2
2
��
n
2
,
��
z
=
��
1
��
2
��
��
n
��z^2=-\frac{(x_1-\mu_1)^2}{2\sigma_1^2}-\frac{(x_2-\mu_2)^2}{2\sigma_2^2}\dots-\frac{(x_n-\mu_n)^2}{2\sigma_n^2},\sigma_z=\sigma_1\sigma_2\dots\sigma_n
��z2=?2��12?(x1??��1?)2??2��22?(x2??��2?)2???2��n2?(xn??��n?)2?,��z?=��1?��2?����n?
������Ԫ��̬�ֲ��ֿ���д��һԪ����Ư������ʽ��(ע��һԪ���Ԫ�IJ��):
f
(
z
)
=
1
(
2
��
)
n
��
n
e
?
z
2
2
f(z)=\frac{1}{(\sqrt{2\pi})^n\sigma_n}e^{-\frac{z^2}{2}}
f(z)=(2��?)n��n?1?e?2z2?
��Ϊ��Ԫ��̬�ֲ����ź�ǿ�ļ���˼��,�����Ӵ����ĽǶȿ���z���ѿ���z�ĸ��ʷֲ�����,������Ҫת���ɾ�����ʽ:
z
2
=
z
T
z
=
[
x
1
?
��
1
,
x
2
?
��
2
,
��
,
x
n
?
��
n
]
[
1
��
1
2
0
��
0
0
1
��
2
2
��
0
?
��
��
?
0
0
��
1
��
n
2
]
[
x
1
?
��
1
,
x
2
?
��
2
,
��
,
x
n
?
��
n
]
T
z^2=z^Tz=[x_1-\mu_1,x_2-\mu_2,\dots,x_n-\mu_n] \begin{bmatrix} \frac{1}{\sigma_1^2}&0&\dots&0 \\ 0&\frac{1}{\sigma_2^2}&\dots&0 \\ \vdots&\dots&\dots&\vdots \\ 0&0&\dots&\frac{1}{\sigma_n^2} \end{bmatrix} [x_1-\mu_1,x_2-\mu_2,\dots,x_n-\mu_n]^T
z2=zTz=[x1??��1?,x2??��2?,��,xn??��n?]???????��12?1?0?0?0��22?1?��0?��������?00?��n2?1?????????[x1??��1?,x2??��2?,��,xn??��n?]T
��ʽ�Ƚϳ�,������Ҫ��һ�±����滻:
x ? �� x = [ x 1 ? �� 1 , x 2 ? �� 2 , �� , x n ? �� n ] T x-\mu_x=[x_1-\mu_1,x_2-\mu_2,\dots,x_n-\mu_n]^T x?��x?=[x1??��1?,x2??��2?,��,xn??��n?]T
����һ������
�� = [ �� 1 2 0 �� 0 0 �� 2 2 �� 0 ? �� �� ? 0 0 �� �� n 2 ] \sum=\begin{bmatrix}\sigma_1^2&0&\dots&0\\ 0&\sigma_2^2&\dots&0\\ \vdots&\dots&\dots&\vdots\\ 0&0&\dots&\sigma_n^2\end{bmatrix} ��=??????��12?0?0?0��22?��0?��������?00?��n2????????
�� \sum ���������� X X X��Э�������, i��j�е�Ԫ��ֵ��ʾ x i �� x j x_i��x_j xi?��xj?��Э����
��Ϊ���ڱ���֮�����������,����ֻ�жԽ����� ( i = j ) (i = j) (i=j)����Ԫ��,�����ط�������0,�� x i x_i xi?����������Э����͵��ڷ���
��
\sum
����һ���Խ���,���ݶԽǾ��������,���������:
(
��
)
?
1
=
[
1
��
1
2
0
��
0
0
1
��
2
2
��
0
?
��
��
?
0
0
��
1
��
n
2
]
(\sum)^{-1}=\begin{bmatrix} \frac{1}{\sigma_1^2}&0&\dots&0 \\ 0&\frac{1}{\sigma_2^2}&\dots&0 \\ \vdots&\dots&\dots&\vdots \\ 0&0&\dots&\frac{1}{\sigma_n^2} \end{bmatrix}
(��)?1=???????��12?1?0?0?0��22?1?��0?��������?00?��n2?1?????????
�ԽǾ��������ʽ = �Խ�Ԫ�صij˻�
�� z = �O �� �O 1 2 = �� 1 �� 2 �� �� n \sigma_z=|\sum|^{\frac{1}{2}}=\sigma_1\sigma_2\dots\sigma_n ��z?=�O���O21?=��1?��2?����n?
�滻����֮��,��ʽ���Լ�Ϊ:
z T z = ( x ? �� x ) T �� 1 2 ( x ? �� x ) z^Tz=(x-\mu_x)^T\sum^{\frac{1}{2}}(x-\mu_x) zTz=(x?��x?)T��21?(x?��x?)
������zΪ�Ա����ı���˹�ֲ�������:
һ��Ķ�Ԫ��˹������ʽ:
f ( z ) = 1 ( 2 �� ) n �� n e ? z 2 2 f ( x ) = 1 ( 2 �� ) n �O �� �O 1 2 e ? ( x ? �� x ) T ( �� ) ? 1 ( x ? �� x ) 2 f(z)=\frac{1}{(\sqrt{2\pi})^n\sigma_n}e^{-\frac{z^2}{2}} \\ f(x)=\frac{1}{(\sqrt{2\pi})^n|\sum|^{\frac{1}{2}}}e^{-\frac{(x-\mu_x)^T(\sum)^{-1}(x-\mu_x)}{2}} f(z)=(2��?)n��n?1?e?2z2?f(x)=(2��?)n�O���O21?1?e?2(x?��x?)T(��)?1(x?��x?)?
ע��ǰ���ϵ���仯:�ӷDZ���̬�ֲ�->����̬�ֲ���Ҫ�������ܶȺ����ĸ߶�ѹ�� �O �� �O 1 2 |\sum|^{\frac{1}{2}} �O���O21?��, ��һά -> nά�Ĺ�����,ÿ����һά,�߶Ƚ�ѹ�� 2 �� \sqrt{2\pi} 2��?��
��Ԫ��˹��������ͼ�����������Ϊ1��������һ������������x��������,y��������,�����������ص����ݾͿ�����z���ҵ���������������Ⱥ����ռ�ı���(������)��ͬ����,�е��������е����ص�������Ⱥ���������,����·������ͨͨ��·�ˡ�
c) ��Ҷ˹��ʽ
P ( A i �O B ) = P ( A i ) P ( B �O A i ) �� j = 1 n P ( A j ) P ( B �O A j ) P(A_i|B)=\frac{P(A_i)P(B|A_i)}{\sum_{j=1}^nP(A_j)P(B|A_j)} P(Ai?�OB)=��j=1n?P(Aj?)P(B�OAj?)P(Ai?)P(B�OAi?)?
d) ������Ȼ
2) �㷨�Ƶ�

nά�����ĸ�˹�ֲ�Ϊ:
p ( x ) = 1 ( 2 �� ) n �O �� �O 1 2 e ? ( x ? �� x ) T ( �� ) ? 1 ( x ? �� x ) 2 p(x)=\frac{1}{(\sqrt{2\pi})^n|\sum|^{\frac{1}{2}}}e^{-\frac{(x-\mu_x)^T(\sum)^{-1}(x-\mu_x)}{2}} p(x)=(2��?)n�O���O21?1?e?2(x?��x?)T(��)?1(x?��x?)?
�ɱ�Ҷ˹����,���� x j x_j xj?���� i i i��ĺ������Ϊ:
KaTeX parse error: No such environment: align at position 8: \begin{?a?l?i?g?n?}? p_M(z_j=i|x_j)��
����ʽ��дΪ �� j i \gamma_{ji} ��ji?
������ x j x_j xj?���ʽΪ
�� j = a r g m a x i �� { 1 , 2 , �� , k } �� j i \lambda_j=argmax_{i\in \{1,2,\dots,k\}}\gamma_{ji} ��j?=argmaxi��{1,2,��,k}?��ji?
��ÿһ������һ��ϵ��,���ö�����Ȼ,��
L L ( D ) = l n ( �� j = 1 m P M ( x j ) ) �� j = 1 m l n ( �� i = 1 k �� i ? P ( x j �O �� i , �� i ) ) LL(D)=ln(\prod_{j=1}^mP_M(x_j)) \\ \sum_{j=1}^mln(\sum_{i=1}^k\alpha_i\cdot P(x_j|\mu_i,\sum_i)) LL(D)=ln(j=1��m?PM?(xj?))j=1��m?ln(i=1��k?��i??P(xj?�O��i?,i��?))
��ʽ�ֱ�� �� , �� \sum,\mu ��,�������Ϊ0,��
�� i = �� j = 1 m �� j i x j �� j = 1 m �� j i �� i = �� j = 1 m �� j i ( x j ? �� i ) ( x j ? �� i ) T �� j = 1 m �� j i \mu_i=\frac{\sum_{j=1}^m\gamma_{ji}x_j}{\sum_{j=1}^m\gamma_{ji}} \\ \sum_i=\frac{\sum_{j=1}^m\gamma_{ji}(x_j-\mu_i)(x_j-\mu_i)^T}{\sum_{j=1}^m\gamma_{ji}} ��i?=��j=1m?��ji?��j=1m?��ji?xj??i��?=��j=1m?��ji?��j=1m?��ji?(xj??��i?)(xj??��i?)T?
ϵ�����Ϊ1,�����Լ��,������Ȼ������������ʽΪ
�� i = 1 m �� j = 1 m �� j i \alpha_i=\frac{1}{m}\sum_{j=1}^m\gamma_{ji} ��i?=m1?��j=1m?��ji?
3) ����
����
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
#����ʵ������
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples=700, centers=4,
cluster_std=0.5, random_state=2019)
X = X[:, ::-1] #���㻭ͼ
from sklearn.mixture import GaussianMixture as GMM
gmm = GMM(n_components=4).fit(X) #ָ���������ĸ���Ϊ4
labels = gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
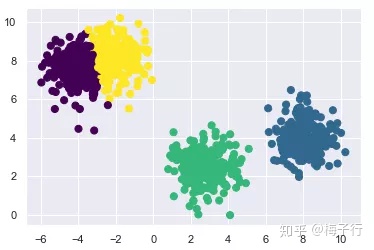
��ʹ��EM�㷨���е���:1.ѡ��λ�úͳ�ʼ��״2.ѭ��ֱ������:
E����:����ÿ����,Ϊÿ����ֱ�����ɸû��ģ���ڵ�ÿ���������ɵĸ��ʡ�
M����:����ģ�Ͳ��������ģ��������Щ�����Ŀ����ԡ�
���㷨��֤�ù����ڵIJ����ܻ�������һ���ֲ����Ž⡣
����
�����
https://www.cnblogs.com/lunge-blog/p/11792226.html
����
���,�ܶ�,������
1,0.697,0.460
2,0.774,0.376
3,0.634,0.264
4,0.608,0.318
5,0.556,0.215
6,0.403,0.237
7,0.481,0.149
8,0.437,0.211
9,0.666,0.091
10,0.243,0.267
11,0.245,0.057
12,0.343,0.099
13,0.639,0.161
14,0.657,0.198
15,0.360,0.370
16,0.593,0.042
17,0.719,0.103
18,0.359,0.188
19,0.339,0.241
20,0.282,0.257
21,0.748,0.232
22,0.714,0.346
23,0.483,0.312
24,0.478,0.437
25,0.525,0.369
26,0.751,0.489
27,0.532,0.472
28,0.473,0.376
29,0.725,0.445
30,0.446,0.459
����
file='xigua4.txt'
x=[]
with open(file) as f:
f.readline()
lines=f.read().split('\n')
for line in lines:
data=line.split(',')
x.append([float(data[-2]),float(data[-1])])
y=np.array(x)
# 2 �㷨����
import numpy as np
import random
def probability(x,u,cov):
cov_inv=np.linalg.inv(cov)
cov_det=np.linalg.det(cov)
return np.exp(-1/2*((x-u).T.dot(cov_inv.dot(x-u))))/np.sqrt(cov_det)
def gauss_mixed_clustering(x,k=3,epochs=50,reload_params=None):
features_num=len(x[0])
r=np.empty(shape=(len(x),k))
# ��ʼ��ϵ��,��ֵ������Э�������
if reload_params!=None:
a,u,cov=reload_params
else:
a=np.random.uniform(size=k)
a/=np.sum(a)
u=np.array(random.sample(list(x),k))
cov=np.empty(shape=(k,features_num,features_num))
# ��ʼ��Ϊֻ�жԽ��߲�Ϊ0
for i in range(k):
for j in range(features_num):
cov[i][j]=[0]*j+[0.5]+[0]*(features_num-j-1)
step=0
while step<epochs:
# E��:����r_ji
for j in range(len(x)):
for i in range(k):
r[j,i]=a[i]*probability(x[j],u[i],cov[i])
r[j]/=np.sum(r[j])
for i in range(k):
r_toal=np.sum(r[:,i])
u[i]=np.sum([x[j]*r[j,i] for j in range(len(x))],axis=0)/r_toal
cov[i]=np.sum([r[j,i]*((x[j]-u[i]).reshape((features_num,1)).dot((x[j]-u[i]).reshape((1,features_num)))) for j in range(len(x))],axis=0)/r_toal
a[i]=r_toal/len(x)
step+=1
C=[]
for i in range(k):
C.append([])
for j in range(len(x)):
c_j=np.argmax(r[j,:])
C[c_j].append(x[j])
return C,a,u,cov
��֤
res,A,U,COV=gauss_mixed_clustering(y)
import matplotlib.pyplot as plt
%matplotlib inline
colors=['green','blue','red','black','yellow','orange']
for i in range(len(res)):
plt.scatter([d[0] for d in res[i]],[d[1] for d in res[i]],color=colors[i],label=str(i))
plt.scatter([d[0] for d in U],[d[1] for d in U],color=colors[-1],marker='^',label='center')
plt.xlabel('density')
plt.ylabel('suger')
plt.legend()
50�۹���
res,A,U,COV=gauss_mixed_clustering(y,reload_params=[A,U,COV])
for i in range(len(res)):
plt.scatter([d[0] for d in res[i]],[d[1] for d in res[i]],color=colors[i],label=str(i))
plt.scatter([d[0] for d in U],[d[1] for d in U],color=colors[-1],marker='^',label='center')
plt.xlabel('density')
plt.ylabel('suger')
plt.legend()
�����
https://zhuanlan.zhihu.com/p/81255623
https://blog.csdn.net/lotusng/article/details/79990724
8.5 �ܶȾ���
8.5.1 ����
k-means�㷨���������ݾ������õ�Ч��,�ܹ����ݾ����������ݷ�Ϊ��״��Ĵ�,�����ڷ���״�����ݵ�,������Ϊ����,��k-means�㷨�ڻ������ݵľ���ʱ,���ǿ����ᷢ��ʲô�����
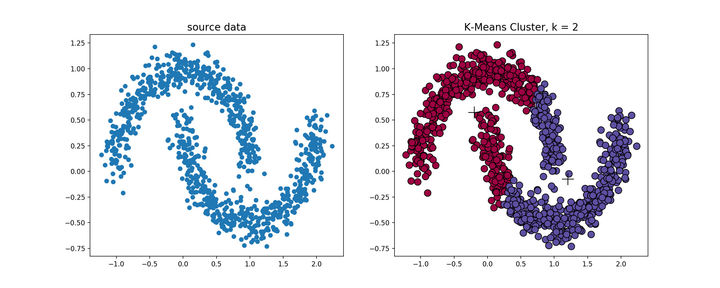
����ͼ���Կ���,kmeans��������˴���Ľ��,���ʱ�����Ҫ�õ������ܶȵľ������,
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)��һ���Ƚ��д����ԵĻ����ܶȵľ����㷨,�����ھ�ֵת�ƾ����㷨,�����м����������ŵ㡣
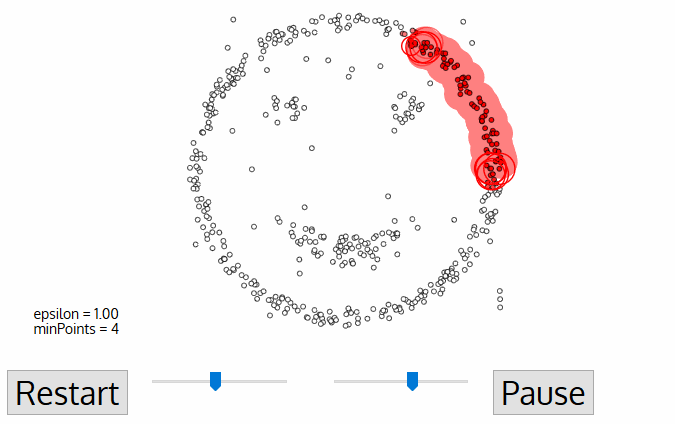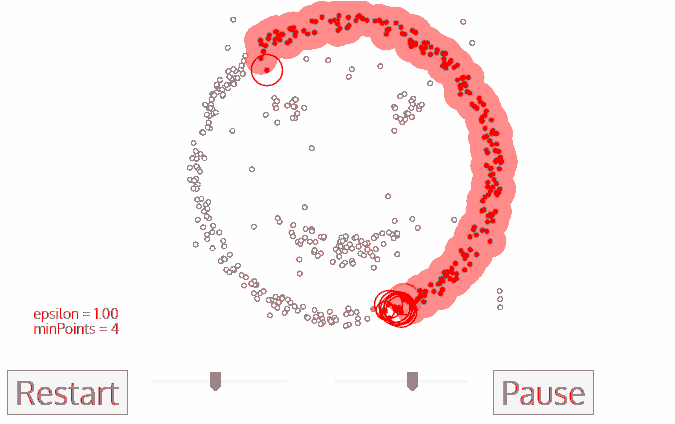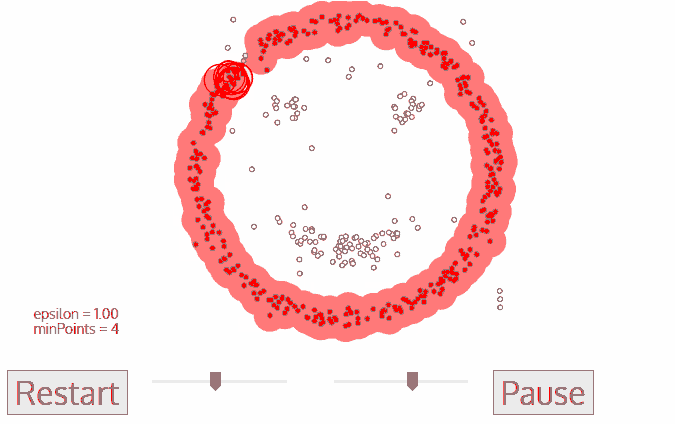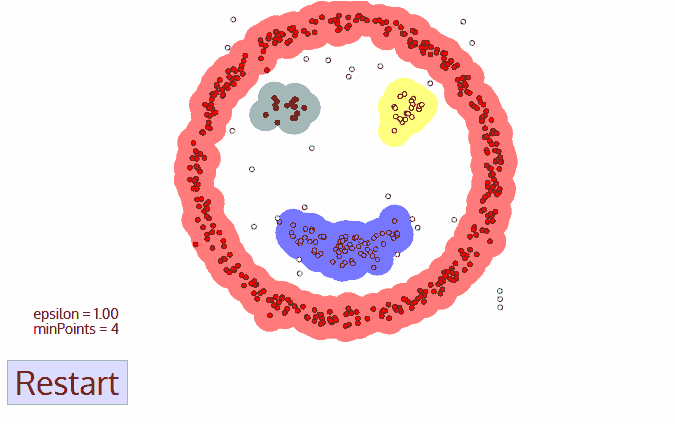
DBSCAN�㷨�ĺ���˼����:��һ����Ħ������ڵ��ھӵ��������õ����ڿռ���ܶ�,���㷨�����ҳ���״�������cluster,���Ҿ����ʱ�����Ȳ���Ҫ����cluster��������
���õ��ܶȾ����㷨:DBSCAN��MDCA��OPTICS��DENCLUE�ȡ�
�ܶȾ������Ҫ�ص���:
- ����������״�Ĵ�
- ���������ݲ�����
- һ��ɨ��
- ��Ҫ�ܶȲ�����Ϊֹͣ����
- ���������Ӷȸ�
8.5.2 ��ظ���
����һ�����ݼ� D = { x 1 , x 2 , �� , x m } D=\{x_1,x_2,\dots,x_m\} D={x1?,x2?,��,xm?}
-
? \epsilon ? ��ʾ�뾶
-
? \epsilon ?����( ? \epsilon ? neighborhood,Ҳ��ΪEps),���������ڰ뾶 ? \epsilon ?�ڵ�����
N ? ( x ) = { y �� X : d i s t ( x , y ) �� ? } N_\epsilon(x)=\{y\in X:dist(x,y)\le \epsilon\} N??(x)={y��X:dist(x,y)��?}
-
�ܶ�
? \epsilon ?������x���ܶ�,��һ������ֵ,�����ڰ뾶 ? \epsilon ?
p ( x ) = �O N ? ( x ) �O p(x)=|N_\epsilon(x)| p(x)=�ON??(x)�O
-
MinPts
��-����������������Сֵ��Ҳ���ΪM
-
���Ķ���
�� x i x_i xi?�� ? \epsilon ?�������ٰ���MinPts������,��| N ? ( x i ) �O �� M i n P t s N_\epsilon(x_i)|\ge MinPts N??(xi?)�O��MinPts,�� x i x_i xi?��һ�����Ķ���
-
�ܶ�ֱ��
�� x j x_j xj?λ�� x i x_i xi?�� ? \epsilon ?������,�� x i x_i xi?�Ǻ��Ķ���,��� x j x_j xj?�� x i x_i xi?���ܶ�ֱ��
-
�ܶȿɴ�(density-reachable)
�������һ�������� p 1 , p 2 , . . p m p_1,p_2,..p_m p1?,p2?,..pm?,���� p 1 = x i , p n = x j , p_1=x_i,p_n=x_j, p1?=xi?,pn?=xj?,�� p i + 1 p_{i+1} pi+1?�� p i p_i pi?�ܶ�ֱ��,��ô�� x j x_j xj?�Ǵ� x i x_i xi?�ܶȿɴ�ġ�
-
�ܶ�����(density-connected)
�ڼ���X��,�������һ������o,ʹ�ö���x��y�Ǵ�o���ڦź�m�ܶȿɴ��,��ô����x��y�ǹ��ڦź�m�ܶ������ġ�
���Է���,�ܶȿɴ���ֱ���ܶȿɴ�Ĵ��ݱհ�,�������ֹ�ϵ�ǷǶԳƵġ��ܶ������ǶԳƹ�ϵ��DBSCANĿ�����ҵ��ܶ������������ϡ�
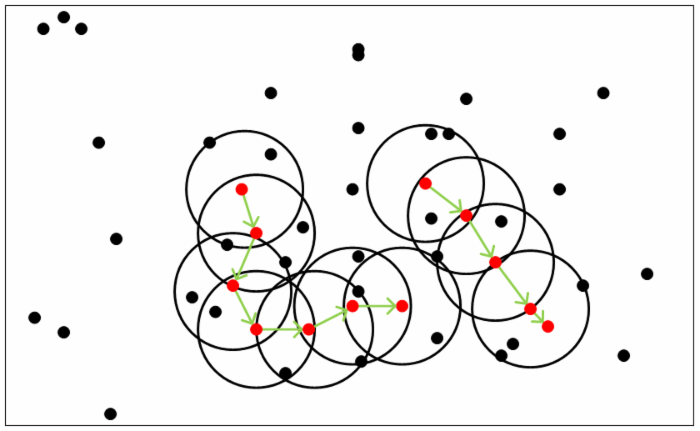
����ͼ���Ժ�������������������,ͼ��MinPts=5,��ɫ�ĵ㶼�Ǻ��Ķ���,��Ϊ��?-����������5����������ɫ�������ǷǺ��Ķ������к��Ķ����ܶ�ֱ����������Ժ�ɫ���Ķ���Ϊ���ĵij�������,������ڳ�������,�����ܶ�ֱ�ͼ������ɫ��ͷ�������ĺ��Ķ���������ܶȿɴ���������С�����Щ�ܶȿɴ���������е�?-���������е�����������ܶ������ġ�
8.5.3 DBSCAN�㷨�Ƶ�
1�����һ����x�Ħ������������m������,��һ��x��Ϊ���Ķ�����´�;
2��Ѱ�Ҳ��ϲ����Ķ���ֱ���ܶȿɴ�Ķ���;
3��û���µ���Ը��´ص�ʱ��,�㷨������

����:������ D = { x 1 , x 2 , �� , x m } D=\{x_1,x_2,\dots,x_m\} D={x1?,x2?,��,xm?},������� ( ? , M i n P t s ) (\epsilon,MinPts) (?,MinPts),�������������ʽ
���:�ػ���
��ʼ�����Ķ��� �� = ? \Omega=\phi ��=?,��ʼ�������k=0,��ʼ��Ϊ������������ F F F.�ػ��� C = ? C=\phi C=?
����j=1,2,��,m,��������IJ����ҳ����еĺ��Ķ���
a) ͨ����������ķ�ʽû�ҵ����� x j x_j xj?�� ? \epsilon ?������������ N ? ( x j ) N_\epsilon(x_j) N??(xj?)
b) ����������������������� �O N ? ( x j ) �O �� M i n P t s |N_\epsilon(x_j)|\ge MinPts �ON??(xj?)�O��MinPts,������ x j x_j xj?������Ķ����������� �� = �� ? { x j } \Omega=\Omega \bigcup\{x_j\} ��=��?{xj?}
������Ķ��� �� = ? \Omega=\phi ��=?,���㷨����,����ת�벽��4
�ں��Ķ��Ϧ���,���ѡ��һ�����Ķ���o,��ʼ����ǰ�غ��Ķ������ �� c u r r e n t = { o } \Omega_{current}=\{o\} ��current?={o},��ʼ��������k=k+1,��ʼ����ǰ���������� C k = { o } C_k=\{o\} Ck?={o},����δ���ʺ��Ķ���Ϊδ���ʼ��� F = F ? { o } F=F-\{o\} F=F?{o}��
�����ǰ�غ��Ķ������ �� c u r r e n t = ? \Omega_{current}=\phi ��current?=?,��ǰ����� C k C_k Ck?�������,���´ػ��� C = { C 1 , C 2 , . . C k } C=\{C_1,C_2,..C_k\} C={C1?,C2?,..Ck?},���º��Ķ��� �� = �� ? C k \Omega=\Omega-C_k ��=��?Ck?,ת�벽��3,������º��Ķ��� �� = �� ? C k \Omega=\Omega-C_k ��=��?Ck?��
�ڵ�ǰ�غ��Ķ������ �� c u r r e n t \Omega_{current} ��current?��ȡ��һ�����Ķ��� o �� o^\prime o����ͨ�����������ֵ ? �� �� \epsilon���� ?������������ N ? ( o �� ) N_\epsilon(o^\prime) N??(o��),�� �� = N ? ( o �� ) ? F \Delta=N_\epsilon(o^\prime)\bigcap F ��=N??(o��)?F,���µ�ǰ�ؼ��� C k = C k ? �� C_k=C_k\bigcup \Delta Ck?=Ck??��,����Ϊ������������ F = F ? �� F=F-\Delta F=F?��,���� �� c u r r e n t = �� c u r r e n t ? ( �� ? �� ) ? o �� \Omega_{current}=\Omega_{current}\bigcup (\Delta\bigcap \Omega)-o^\prime ��current?=��current??(��?��)?o��,ת�벽��5
������,�ػ��� C = { C 1 , C 2 , . . . , C k } C=\{C_1,C_2,...,C_k\} C={C1?,C2?,...,Ck?}
�㷨��������:
1��ÿ�������ٰ���һ�����Ķ���
2���Ǻ��Ķ�������Ǵص�һ����,���ɴصı�Ե��
3���������ٶ���Ĵر���Ϊ��������
8.5.4 ����
import re
import random
from sklearn.cluster import DBSCAN
import scipy.io as sio
import numpy as np
import matplotlib.pyplot as plt
from time import *
from sklearn.datasets import make_blobs
from sklearn import datasets
def dbscan(data_set, eps, min_pts):
"""
data_set ���ݼ�,[n,2]
eps �����С��Χ
min_pts һ���������ٰ������ٸ�����
"""
examples_nus = np.shape(data_set)[0] # ��������
unvisited = [i for i in range(examples_nus)] # δ�����ʵĵ�
visited = [] # �ѱ����ʵĵ�
# clusterΪ������,��ʾ��ӦԪ���������
# Ĭ����һ������Ϊexamples_nus��ֵȫΪ-1���б�,-1��ʾ������
cluster = [-1 for i in range(examples_nus)]
k = - 1 # ��k��Ǵغ�,�����-1��ʾ��������
while len(unvisited) > 0: # ֻҪ����û�б����ʵĵ�ͼ���ѭ��
p = random.choice(unvisited) # ���ѡ��һ��δ�����ʶ���
unvisited.remove(p)
visited.append(p)
nighbor = [] # nighborΪp��eps�������,�ܶ�ֱ�ӿɴ�
for i in range(examples_nus):
if i != p and np.sqrt(np.sum(np.power(data_set[i, :] - data_set[p, :], 2))) <= eps: # �������,���Ƿ���������
nighbor.append(i)
if len(nighbor) >= min_pts: # ��������ڶ����������min_pts˵����һ�����Ķ���
k = k + 1
cluster[p] = k # ��ʾp������k�����
for pi in nighbor: # ����Ҫ�Ҹ��������ܶȿɴ�
if pi in unvisited:
unvisited.remove(pi)
visited.append(pi)
# nighbor_pi��pi��eps�������
nighbor_pi = []
for j in range(examples_nus):
if np.sqrt(np.sum(np.power(data_set[j] - data_set[pi], 2))) <= eps and j != pi:
nighbor_pi.append(j)
if len(nighbor_pi) >= min_pts: # pi�Ƿ��Ǻ��Ķ���,ͨ�������ܶ�ֱ�ӿɴ����p���ܶȿɴ�
for t in nighbor_pi:
if t not in nighbor:
nighbor.append(t)
if cluster[pi] == -1: # pi�������κ�һ����,˵����pi��ֵδ�Ķ�
cluster[pi] = k
else:
cluster[p] = -1 # ��Ȼ����һ��������
return np.array(cluster)
if __name__ == '__main__':
# centers = [[1, 1], [-1, -1], [1, -1]]
# ���ɷ����� factor��ʾ����Ȧ�����
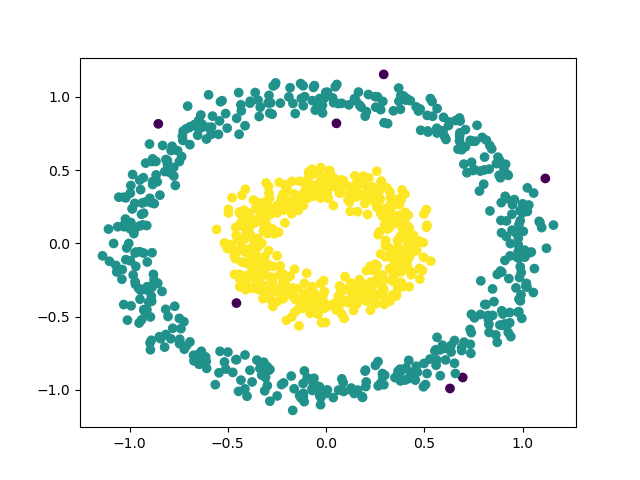
X, Y1 = datasets.make_circles(n_samples=1000, factor=.4, noise=.07)
print(X)
eps = 0.1 # ����뾶
min_pts = 2 # ���Ķ���
cluster = dbscan(X, eps, min_pts)
print(cluster.shape)
print(np.unique(cluster))
plt.figure()
plt.scatter(X[:, 0], X[:, 1], c=cluster)
plt.show()
plt.figure()
y_pred = DBSCAN(eps=0.1).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
�������
��Ҫ����ģ��
X, Y1 = datasets.make_moons(n_samples=200, noise=None, shuffle=True, random_state=None)
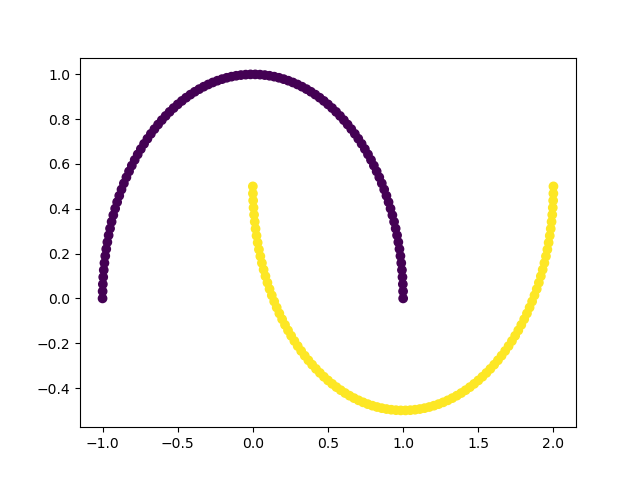
�����Լ���
datasets.make_biclusters() # Ϊ˫�������ɾ��г�����Խǽṹ�����顣
datasets.make_blobs() # �������ھ���ĸ���ͬ�Ը�˹�ߵ㡣
datasets.make_checkerboard() # Ϊ˫�������ɾ��з������̽ṹ�����顣
datasets.make_circles() # ��2ά������һ������һ��СԲ�Ĵ�Բ��
datasets.make_classification() # ����һ�����n��������⡣
datasets.make_friedman1() # ���ɡ�Friedman#1���ع����⡣
datasets.make_friedman2() # ���ɡ�Friedman#2���ع����⡣
datasets.make_friedman3() # ���ɡ�Friedman#3���ع����⡣
datasets.make_gaussian_quantiles() # ���ɸ���ͬ�Ը�˹������λ�����������
datasets.make_hastie_10_2() # ΪHastine����ʹ�õĶ����Ʒ����������ݡ�
datasets.make_low_rank_matrix() # ���ɾ�����������ֵ�ĵ��Ⱦ���
datasets.make_moons() # ����������İ�Բ��
datasets.make_multilabel_classification() # ����һ��������ǩ�������⡣
datasets.make_regression() # ����һ������ع����⡣
datasets.make_s_curve() # ����S�������ݼ���
datasets.make_sparse_coded_signal() # ���ź�����Ϊ�ֵ�Ԫ�ص�ϡ����ϡ�
datasets.make_sparse_spd_matrix() # ����ϡ��Գ���������
datasets.make_sparse_uncorrelated() # ���ɾ���ϡ�費�����Ƶ�����ع����⡣
datasets.make_spd_matrix() # ����һ������Գ���������
datasets.make_swiss_roll() # ������ʿ�����ݼ���
8.5.5 ��ȱ��
**�ŵ�:**����Ҫȷ��Ҫ���ֵľ������,������û��ƫ��;������,�ھ����ͬʱ�����쳣��,�����ݼ��е��쳣�㲻����;����������״�ʹ�С�Ĵ�,��Ե�,K-Means֮��ľ����㷨һ��ֻ���������ݼ���
**ȱ��:**��������ʱ�ڴ����Ĵ�,���K-Means������һЩ;���������ܶȲ����ȡ�����������ܴ�ʱ,���������ϲ�,��ʱ��DBSCAN����һ�㲻�ʺ�;
�����
https://www.jianshu.com/p/5e5bcf3ec9d6
(3����Ϣ) pythonʵ��DBSCAN����_�����ϵ�Сú��IJ���-CSDN����_dbscan����pythonʵ��
8.6 ����
8.6.1 ����
��ξ���(Hierarchical Clustering)�Ǿ����㷨��һ��,ͨ�����㲻ͬ������ݵ������ƶ�������һ���в�ε�Ƕ���������ھ�������,��ͬ����ԭʼ���ݵ���������Ͳ�,���Ķ�����һ������ĸ��ڵ㡣���������������¶��Ϻϲ������϶��·������ַ���,��ƪ���½��ܺϲ�����
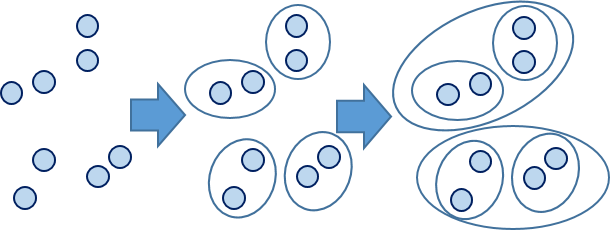
Դ����:
����:
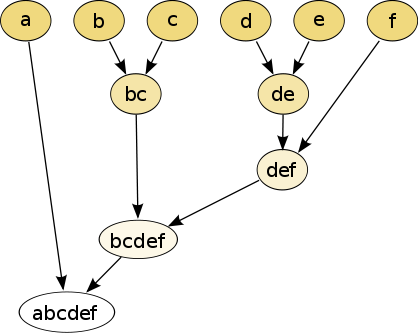
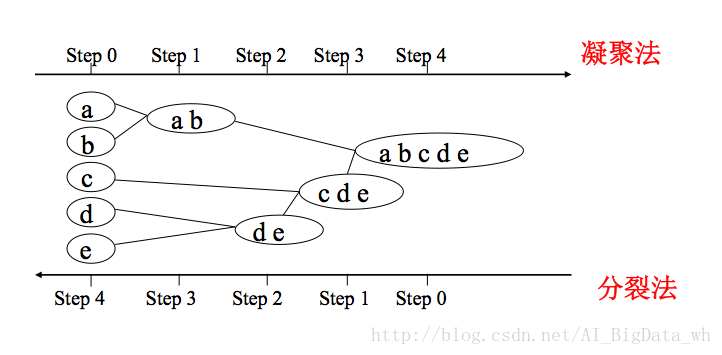
1.���۲�ξ���:AGNES�㷨(�Ե�����)
���Ƚ�ÿ��������Ϊһ����,Ȼ��ϲ���Щԭ�Ӵ�ΪԽ��Խ��Ĵ�,ֱ��ij���ս�����������
2.���Ѳ�ξ���:DIANA�㷨(�Զ�����)
���Ƚ����ж�������һ������,Ȼ����ϸ��ΪԽ��ԽС�Ĵ�,ֱ���ﵽ��ij���ս�������
8.6.2 ��ѧ��
��������� C i C_i Ci?�� C j C_j Cj?,�����صľ������ͨ�����¶���õ�
��̾���: d m i n ( C i , C j ) = m i n p �� C i , q �� C j �O p ? q �O d_{min}(C_i,C_j)=min_{p\in C_i,q\in C_j}|p-q| dmin?(Ci?,Cj?)=minp��Ci?,q��Cj??�Op?q�O
������ d m a x ( C i , C j ) = m a x p �� i , q �� C j �O p ? q �O d_{max}(C_i,C_j)=max_{p\in _i,q\in C_j}|p-q| dmax?(Ci?,Cj?)=maxp��i?,q��Cj??�Op?q�O
��ֵ���� d m e a n ( C i , C j ) = �O p �� ? q �� �O , �� �� p �� = 1 �O C i �O �� p �� C i p , q �� = �� q �� C j q d_{mean}(C_i,C_j)=|\overline{p}-\overline{q}|,����\overline{p}=\frac{1}{|C_i|}\sum_{p\in C_i}p,\overline{q}=\sum_{q\in C_j}q dmean?(Ci?,Cj?)=�Op??q?�O,����p?=�OCi?�O1?��p��Ci??p,q?=��q��Cj??q
ƽ������ d a v g ( C i , C j ) = 1 �O C i �O �O C j �O �� p �� C i �� q �� C j �O p ? q �O d_{avg}(C_i,C_j)=\frac{1}{|C_i||C_j|}\sum_{p\in C_i}\sum_{q\in C_j}|p-q| davg?(Ci?,Cj?)=�OCi?�O�OCj?�O1?��p��Ci??��q��Cj??�Op?q�O
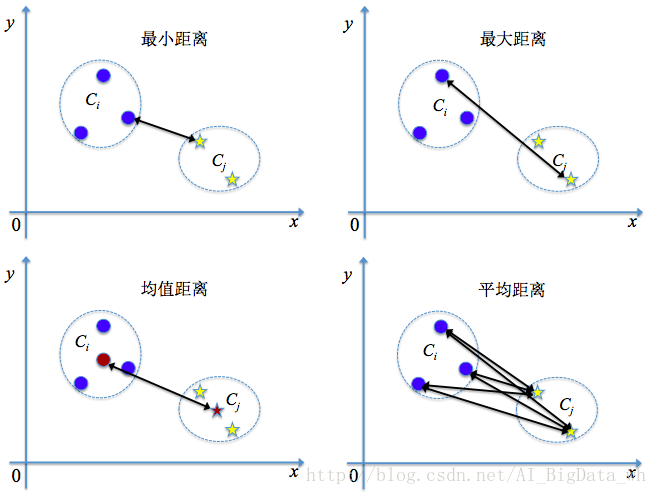
��Ȼ��С�������������ص���������������������������ص���Զ������������ֵ�����������ص�����λ�þ�������ƽ���������������ص�����������ͬ����������������� d m i n , d m a x , d a v g d_{min},d_{max},d_{avg} dmin?,dmax?,davg?����ʱ��AGNES�㷨����Ӧ�س�Ϊ�������ӡ�����ȫ���ӡ������ӡ��㷨��
8.6.3 �㷨�Ƶ�
AGNES(�Ե����������㷨)�㷨�ľ��岽��������ʾ:
����:����n����������ݿ⡣
���:������ֹ���������ɸ��ء�
(1) ��ÿ������һ����ʼ��;
(2) REPEAT(�ظ�)
(3) �������������صľ���,���ҵ������������;
(4) �ϲ�������,�����µĴصļ���;
(5) UNTIL ��ֹ�����õ����㡣

8.6.4 ����
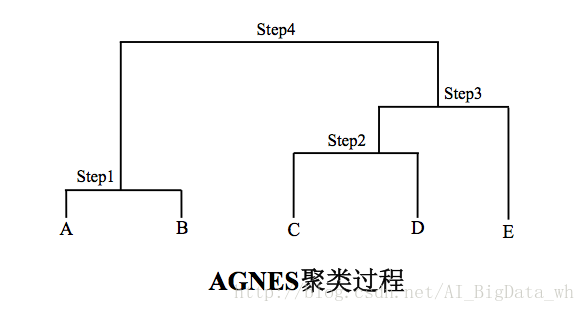
ʹ��AGNES�㷨����������ݼ����о���,����С�������ؼ�ľ��롣�տ�ʼ����5����: C 1 = { A } , C 2 = { B } , C 3 = { C } , C 4 = { D } , C 5 = { E } C_1=\{A\},C_2=\{B\},C_3=\{C\},C_4=\{D\},C_5=\{E\} C1?={A},C2?={B},C3?={C},C4?={D},C5?={E}
| ������ | A | B | C | D | E |
|---|---|---|---|---|---|
| A | 0 | 0.4 | 2 | 2.5 | 3 |
| B | 0.4 | 0 | 1.6 | 2.1 | 1.9 |
| C | 2 | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.5 | 2.1 | 0.6 | 0 | 1 |
| E | 3 | 1.9 | 0.8 | 1 | 0 |
step1.�� C 1 C_1 C1?�ʹ� C 2 C_2 C2?�ľ������,�����ߺϲ�,�õ��µĴؽṹ: C 1 = { A , B } , C 2 = { C } , C 3 = { D } C_1=\{A,B\},C_2=\{C\},C_3=\{D\} C1?={A,B},C2?={C},C3?={D}�� C 4 = { E } C_4=\{E\} C4?={E}
| ������ | AB | C | D | E |
|---|---|---|---|---|
| AB | 0 | 1.6 | 2.1 | 1.9 |
| C | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.1 | 0.6 | 0 | 1 |
| E | 1.9 | 0.8 | 1 | 0 |
Step2. �������� C 2 C_2 C2?�ʹ� C 3 C_3 C3?�ľ������,�����ߺϲ�,�õ��µĴؽṹ: C 1 = { A , B } , C 2 = { C , D } C_1=\{A,B\},C_2=\{C,D\} C1?={A,B},C2?={C,D}�� C 3 = { E } C_3=\{E\} C3?={E}
| ������ | AB | CD | E |
|---|---|---|---|
| AB | 0 | 1.6 | 1.9 |
| CD | 1.6 | 0 | 0.8 |
| E | 1.9 | 0.8 | 0 |
Step3. �������� C 2 C_2 C2?�ʹ� C 3 C_3 C3?�ľ������,�����ߺϲ�,�õ��µĴؽṹ: C 1 = { A , B } C_1=\{A,B\} C1?={A,B}�� C 2 = { C , D , E } C_2=\{C,D,E\} C2?={C,D,E}
| ������ | AB | CDE |
|---|---|---|
| AB | 0 | 1.6 |
| CDE | 1.6 | 0 |
Step4. ���ֻʣ�´� C 1 C_1 C1?�ʹ� C 2 C_2 C2?,���ߵ��������Ϊ1.6,�����ߺϲ�,�õ��µĴؽṹ: C 1 = { A , B , C , D , E } C_1=\{A,B,C,D,E\} C1?={A,B,C,D,E}
��ξ��������ֹ����:
- �趨һ����С������ֵ d �� \overline{d} d,���������������صľ����Ѿ����� d �� \overline{d} d,�����Dz����ٺϲ�,������ֹ��
- ���صĸ���k,���õ��Ĵصĸ����Ѿ��ﵽ k �� \overline{k} k,�������ֹ��
from sklearn import datasets
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import pandas as pd
iris = datasets.load_iris()
irisdata = iris.data
clustering = AgglomerativeClustering(linkage='ward', n_clusters=3)
res = clustering.fit(irisdata)
print "�����ص�������Ŀ:"
print pd.Series(clustering.labels_).value_counts()
print "������:"
print confusion_matrix(iris.target,clustering.labels_)
plt.figure()
d0 = irisdata[clustering.labels_==0]
plt.plot(d0[:,0],d0[:,1],'r.')
d1 = irisdata[clustering.labels_==1]
plt.plot(d1[:,0],d1[:,1],'go')
d2 = irisdata[clustering.labels_==2]
plt.plot(d2[:,0],d2[:,1],'b*')
plt.xlabel("Sepal.Length")
plt.ylabel("Sepal.Width")
plt.title("AGNES Clustering")
plt.show()
�����
https://blog.csdn.net/jmh1996/article/details/83959465
https://zhuanlan.zhihu.com/p/100557559
https://zhuanlan.zhihu.com/p/104355127
https://blog.csdn.net/AI_BigData_wh/article/details/78073444
https://www.cnblogs.com/pinard/p/6208966.html

