ABCNet V2:����ʵʱ�˵����ı�ʶ�������ӦBezier��������
ժҪ:
????????ּ�ڽ�����ʶ�ɵ�ͳһ����еij���˵����ı���λ������������������ļ��Զ�������Խ��Խ��Ĺ�ע������Ȼ��һ������δ��������,�������ڴ���������״���ı�ʵ��ʱ����ǰ�ķ������Դ��·�Ϊ����: �����ַ��ĺͻ��ڷָ��,���ڷǽṹ�������,����ͨ����Ҫ�ַ������ע�ͺ�/���ӵĺ�����������,����ͨ����������Ӧ��������������v2 (ABCNet v2) ������˵����ı�ʶ�����⡣���ǵ���Ҫ�������ĸ�����: 1) �����״�ͨ����������Bezier��������Ӧ�����������״���ı�,����ڷָ�ķ������,�����߲��������ṩ�ṹ�������,���ҿ����ṩ�ɿصı�ʾ��2) ���������һ����ӱ��BezierAlign��,������ȡ������״���ı�ʵ����ȷ��������,����ǰ�ķ������������ʶ�ȡ�3) ����ǰ�ķ�����ͬ,��ǰ�ķ����������ܸ��ӵĺ��������еij�����������,���ǵ�ABCNet v2ά����һ������ˮ��,����ֻ�к������������ (NMS)��4) �����ı�ʶ�������������������������,ABCNet v2��һ�����ü���Ч�������������������˲�����λ��,������൱��ĸĽ�,���㿪�����Ժ��Բ��ơ��ڸ���˫�� (Ӣ�ĺ�����) �����ݼ��Ͻ��е��ۺ�ʵ�����,ABCNet v2����ʵ�����Ƚ�������,ͬʱ���ַdz��ߵ�Ч�ʡ�����Ҫ����,���ڶ��ı��ߵ�ģ�ͽ��������Ĺ�������,������Ƕ�ģ�ͽ��������Ը����������ABCNet v2������ʱ�䡣�����ʵʱӦ�ó���������м�ֵ�ġ������ģ�Ϳ���������ַ���: https:// git.io/AdelaiDet��
һ������
????????�����ij����ı�ʶ�������漰������������ģ��:�ı�����ʶ��,������ģ���ǰ�˳��ʵ�ֵġ� �����е�����ֻ����һ������,��ֱ�Ӵ���һ�������н���������õ�ģ�顣 ���ּķ�����̫���ܳ��������Ⱦ��������DZ��,��Ϊ���������ǹ�����,û�пɹ����Ĺ��ܡ�

?ͼƬ����:��ͼ(a)��,������ѭǰ��ķ���,ʹ��TPS[1]��STN[2]���������ı�����Ť���ɾ��Ρ� ��ͼ(b)��,����ʹ�����ɵ�Bezier���ߺ������Bezieralign��Ť�����,�Ӷ���߾��ȡ�
????????���,�˵��˳����ı��������[3],[4]��[5]��[6]��[7]��[8]��[9]��[10]��[11]��ֱ��������ͼ������ּ�¼��֮�佨��ͳһ��ӳ���ϵ�ķ���Խ��Խ�ܵ����ǵ����ӡ� �����ʶ������������ģ���ģ�����,��ƶ˵��˿�ܵ��ŵ����¡� ����,����ʶ����������������ȷ�ʡ� �ı�������������֮һ���������ԡ� Ȼ��,�����Ա��ֳ����е���۴������������Ļ�����,�����������������ˡ� Ϊ��ʹ����������ֲ�ͬģʽ������,һЩ����[3],[4],[5]���������������֮�������,�Զ˵��˵ķ�ʽѵ�����硣 ����,�˵��˿�����ڹ���������,�����������ٶ��ϱ��ֳ�����,���ʺ���ʵʱӦ�á� ���,Ŀǰ�Ķ���ʶ��ģ��ͨ��������ȫ�ü����ı�ͼ�������ʽ�ϳ�ͼ�����ѵ���� �˵���ģ�������ʹʶ��ģ����Ӧ������,��˽�����Ը����Ƚ�[10]��
????????�˵����ı�ʶ������з������Դ��·�Ϊ����: �����ַ��ĺͻ��ڷָ�ġ������ַ��ķ������ȼ���ʶ���ַ�,Ȼ��ͨ��Ӧ�ö���ķ���ģ��������ʡ���Ȼ��Ч,����Ҫ�������ַ���ע�͡�����,�����㷨ͨ����ҪһЩԤ����ij�����,�Ӷ���ʾ������³���Ժͷ����������о�����һ���ǻ���ϸ�ֵ�,�����ı�ʵ���ɷǽṹ��������ʾ,��ʹ�ú���ʶ���������ѡ�����,[1 2] �еĹ���������TPS [1] ��STN [2] ���轫ԭʼ��������Ť���ɾ�����״����ע��,�ַ����ܻ�����ʧ��,��ͼ1��ʾ������,�������,�ı�ʶ����Ҫ������ѵ������,�Ӷ�����ͳһ����е��Ż����ѡ�
Ϊ�˽����Щ����,�������������Ӧ��������������v2 (ABCNet v2),����һ�ֶ˵��˿�ѵ���Ŀ��,����ʵʱ������״�ij����ı���λ��ABCNet v2����ͨ������Ч��Bezier��������Ӧ��ʵ��������״�ij����ı����,������α߽�������,�������ɺ��Բ��Ƶļ��㿪��������,���������һ����ӱ�����������,��ΪBezierAlign,�Ծ�ȷ����������״�ı�ʵ���ľ�������,�Ӷ�����ʵ�ֽϸߵ�ʶ�ȡ������״γɹ��ز����˲����ռ� (Bezier����) ���ж����������ı���λ,�Ӷ�ʵ���˷dz�����Ч�Ĺܵ���
�� [13] �� [14] �� [15] �������������,���������ǵĻ���汾 [16] �д��ĸ�����Ľ���ABCNet: ������ȡ��������֧��ʶ���֧�Ͷ˵���ѵ�������ڲ��ɱ���ı����仯,�����ABCNet v2����˵���˫����,��ʵ�ָ��õ�ȷ�Ժ�Ч��Ȩ�⡣����,�������ǵĹ۲�,����֧�е�����������ں������ı�ʶ��������Ҫ��Ϊ��,���Dz�����һ�ֿ��Ժ��Բ��Ƶļ��㿪����������뷽������ʽ��������˲����е�λ��,�Ӷ��������˾��ȡ�����ʶ���֧,���Ǽ�����һ���ַ�ע��ģ��,��ģ����Եݹ��Ԥ��ÿ�����ʵ��ַ�,������ʹ���ַ������ע�͡�Ϊ��ʵ����Ч�Ķ˵�����ѵ,���ǽ�һ�������һ������Ӧ�˵�����ѵ (AET) ����,��ƥ��˵�����ѵ�ļ�⡣�������ʹʶ���֧�Լ����Ϊ����³���ԡ����,�������ABCNet v2����ǰ�����Ƚ��ķ����м����ŵ�,�ܽ�����:?
- ?�����״�ʹ��Bezier���߽�����һ���µ�,�������泡���ı��IJ�������ʾ������߽���ʾ���,�������˿ɺ��Եļ��㿪����
- ? ���������һ���µ��������뷽��,Ҳ����BezierAlign,�Ӷ�ʶ���֧���������ӵ�����ṹ��ͨ��������������,ʶ���֧������Ƴ�������Ľṹ��������Ч��������
- ? ABCNet v2�ļ��ģ��ͨ������˫���߶Ƚ�����ȫ���ı�������������߶��ı�ʵ����Ϊͨ�á�
- ? ��������֪,���ǵķ����ǵ�һ���ܹ��Ե�����ʽͬʱ����ʶ��ˮƽ������������״���ı�,ͬʱ����ʵʱ�����ٶȵĿ�ܡ�
- ? Ϊ�˽�һ���ӿ������ٶ�,���ǻ�������ģ����������,����ABCNet v2������ֻ�бʾ��Ƚ��͵�����´ﵽ����������ٶȡ�
- ? �ڸ��ֻ��Ͻ��е��ۺ�ʵ��֤�����������ABCNet v2��ȷ�Ժ��ٶȷ���������ı���λ���ܡ�
������ع���
????????�����ı�ʶ����Ҫͬʱ����ʶ���ı�,������ֻ�漰һ������ ���ڵij����ı�ʶ��ͨ����ͨ�������ļ���ʶ��ģ�ͼ����������ġ� �ò�ͬ����ϵ�ṹ�ֱ������ģ�ͽ������Ż��� ������,�˵��˷���(��2.2)ͨ��������ʶ�ɵ�һ��ͳһ��������,����������ı�ʶ������ܡ�?
2.1���볡���ı���λ
����һ����,���Ǽ�Ҫ�ع�����,�ص��Ǽ���ʶ��
2.1.1�����ı����
ͨ���������Կ��Թ۲쵽�ı����ķ�չ���ơ� ��ˮƽ���μ���Χ�б�ʾ�ľ۽�ˮƽ�����ı����,����ת���λ��ı��ΰ�Χ�б�ʾ�Ķ������ı����,�ٵ�ʵ���ָ���������α�ʾ��������״�����ı���⡣ ���ڻ���ˮƽ���εķ��������ݵ�Lucas���ˡ� [17],���й����˿����Ե�ˮƽICDAR'03���� ICDAR'03����������ݼ�(ICDAR'11[18]��ICDAR'13[19])��ˮƽ�����ı���ⷽ�������˴����о���Ա[20]��[21]��[22]��[23]��[24]��[25]��?
�� 2010 ��֮ǰ,���������ֻ��ע�����ˮƽ�����ı�,������ڷ�����ʵ��Ӧ����,���ж����ı������ڡ� Ϊ��,Ҧ���ˡ� ?[26] �����һ��ʵ�õļ��ϵͳ�Լ����ڶ���ı����Ķ���(MSRA-TD500)�� �÷��������ݼ���ʹ����ת�ľ��α߽��������ע�Ͷ����ı�ʵ���� ���� MSRA-TD500,���� NEOCR [27] �� USTBSV1K [28] ���ڵ������������ݼ��ij��ֽ�һ���ٽ������������ת���εķ��� [3]��[26]��[28]��[29]��[30] ?,[31]�� �� 2015 ������,ICDAR'15 [32] ��ʼΪÿ���ı�ʵ��ʹ�û����ĸ�����ı���ע��,��ٽ��������,��Щ�����ɹ���֤���˸����ա��������ı��μ�ⷽ������Խ�ԡ� ?SegLink ���� [33] ͨ�������Ԥ���ı�����,��ѧϰ����������������Ͻ���� ?
DMPNet [34] �۲쵽��ת�ľ��ο�����Ȼ��������Ҫ�ı�����������������ƥ���Ҫ���ص�,���������ʹ���ı��α߽���������и���Ԥ�����ı��λ������ڵ��ı��� ?EAST [35] �����ܼ�Ԥ��ṹֱ��Ԥ���ı��α߽�� ?WordSup [36] �����һ���Զ������ַ�����ĵ�������,�ڸ��ӳ����б��ֳ�³���ԡ� ?ICDAR 2015 �ijɹ����Լ�������������ı��ε����ݼ�,���� RCTW'17 [37]��MLT [38] �� ReCTS [39]�� ���,�о��ص��ѴӶ����ı����ת��������״���ı���⡣ ������״��Ұ����Ҫ���������ֳ���,�����ǵ���ʵ������Ҳ���Ժܳ���,������״����(ƿ�Ӻ�ʯ��)���������塢����ƽ��(�·���������վ�)��Ӳ�� ����־��ӡ�¡����Ƶȡ� ��һ�������ı����ݼ� CUTE80 [40] ���� 2014 �깹���ġ��������ݼ���Ҫ���ڳ����ı�ʶ��,��Ϊ�������� 80 ���ɾ���ͼ��,�ı�ʵ����Խ��١� Ϊ�˼��������״�ij����ı�,������������������Total-Text [41] �� SCUT-CTW1500 [42]�������ƽ�������Ӱ�����Ĺ��� [43]��[44]��[45]��[46]�� ?[47]��[48]��[49]��[50]��[51]�� ?TextSnake [47] �����һ�� FCN ��Ԥ���ı�ʵ���ļ�������,Ȼ�����Ƿ��鵽��������С� ?CRAFT [44] Ԥ���ı����ַ�����������ַ�֮��������� ?SegLink++ [48] �ṩ��һ��ʵ����֪���������,�����ܼ���������״���ı���⡣ ?PSENet [46] ����ѧϰ�ı��ں�,Ȼ����չ�����Ը��������ı�ʵ���� ?PAN [45] ���� PSENet [46],���ÿ�ѧϰ�ĺ�������,ͨ��Ԥ�����ص����ƶ������� �����ˡ� ?[52] ���ѧϰ����Ӧ�ı������ʾ�Լ��������״���ı��� ?DRRN [53] �������ȼ���ı����,Ȼ��ͨ��ͼ���罫���������һ�� ?ContourNet [50] ��������Ӧ RPN �Ͷ��������Ԥ���֧����߾��ȡ�
2.1.2�����ı�ʶ��
�����ı�ʶ��ּ��ͨ���ü����ı�ͼ��ʶ���ı���������ǰ�ķ��� [54],[55],��ѭ���¶��ϵķ���,����ͨ���������ڷָ��ַ�����ÿ���ַ����з���,Ȼ�����Ƿ���Ϊһ������,�Կ��������ھӵ������ԡ������ڳ����ı�ʶ���л�������õ�����,�������������ַ����İ�����ַ���ע�͡����û�д���ѵ�����ݼ�,������ģ��ͨ�����ܺõظ�����Su��Lu [56],[57] �����һ������HOG�����͵ݹ������� (RNN) �ij����ı�ʶ��ϵͳ,���dzɹ�����RNN���г����ı�ʶ���������Ʒ֮һ��
���,����˻���CNN�ĵݹ������緽�������϶��µķ�ʽִ��,�÷������Զ˵��˵�Ԥ���ı�����,�������κ��ַ���⡣Shi���ˡ�[58] ����������ʱ����� (CTC) [59] Ӧ���ھ���rnn�����缯�ɵ�cnn,��ΪCRNN����CTC��ʧ��ָ����,����CRNN��ģ�Ϳ�����Ч��ת¼ͼ�����ݡ���CTC��,ע����� [60] Ҳ�����ı�ʶ������������ҪӦ���ڳ����ı�ʶ��,�����ڲ������ı�ʶ������׳��������,����������״�ı�ʶ��ķ���ռ������λ,���Է�Ϊ����У���ķ�������У���ķ�����
����ǰ��,STN [2] �ͱ������� (TPS) [61] �����ֹ㷺ʹ�õ��ı�У��������Shi�� [62] ��������STN�ͻ���ע�����Ľ�������Ԥ���ı����С�[63] �еĹ���ʹ�õ����ı�У��ʵ���˸��õ����ܡ�����,���ˡ�[64] �����MORAN,��ͨ����λ��ƫ�Ƶ�ƫ�ƽ��лع��������ı���Liu���� [65] �����һ���ַ���֪������ (CharNet),���������ȼ���ַ�,Ȼ����ֱ�ת��Ϊˮƽ�ַ���ESIR [66] �����һ�ֵ���������ˮ��,���Խ��ı���λ�ô���ʧ��ת��Ϊ�����ʽ,�Ӷ����Թ�����Ч�Ķ˵��˳����ı�ʶ��ϵͳ��
Litman���� [67] ����������ͼ����Ӧ��TPS,Ȼ��Ϊ�Ӿ��������������ѵ�����ѡ����ע����������������������ķ�����,Cheng���� [68] �����һ�����ⶨ������ (AON) ����ȡ�ĸ�������������ַ�λ��������Li���� [69] Ӧ��2dע����Ʋ���������ı�����,ȡ��������ӡ����̵�Ч����Ϊ�˽��ע����Ư������,Yue�ȡ�[70] ��ʶ��ģ���������һ����ӱ��λ����ǿ��֧������,һЩ���������ǻ�������ָ�ġ��ε� [71] ����� [72] �����ͨ���Ӿ�������������зָ�ͷ��ࡣ
2.2�˵��˳����ı���λ
2.2.1����Ķ˵��˳����ı���λ
����ˡ� [3]�����ǵ�һ������˵��˿�ѵ���ij����ı���������� �÷����ɹ���ʹ��ROI��[73]ͨ�����ο�ܼ������ʶ�������� ������Ƴɴ���ˮƽ�ĺͼ��е��ı��� ���ĸĽ��汾[11]������������ܡ� ��˹�����ˡ� [74]�������һ���˵��˵�����ı�����ǡ� �����ˡ� [4]��Liu���ˡ� [5]������ê����,ͬʱ���ѵ���������ٶȡ� ����ʹ�����ƵIJ�������,���ı����������ROI��ת,�ֱ����ڴ��ı��μ��������ȡ������ ��ע��,�����ַ��������ܷ���������״�ij����ı���
2.2.2������״�Ķ˵��˳����ı���λ?
Ϊ�˼��������״�ij����ı�,Liao ���ˡ� [6] �����һ�� Mask TextSpotter,������ظĽ��� Mask RCNN,��ʹ���ַ����ල��ͬʱ����ʶ���ַ���ʵ�����롣�÷������������������״�����ı��Ķ�λ���ܡ���Ľ��汾 [10] ���ż����˶��ַ���ע�͵�����������ˡ� [75] �����Ԥ�������ı��μ��߽��� TextNet,Ȼ��ʹ����������������������������ʶ��
���,�ص��ˡ� [7] ����ʹ�� RoI Masking ����ע������״���ı�������ע��,��Ҫ����ļ�������϶���Ρ� [8] �еĹ��������һ��������״�ij����ı���λ����,��Ϊ CharNet,��Ҫ�ַ���ѵ�����ݺ� TextField [76] ��ʶ�������з��顣 [9] �����������һ���µIJ������� RoISlide,��ʹ�������ı�ʵ����Ԥ��Ƭ�ε��ں�����,�������������״�ij��ı�����³���ԡ�????????
�����ˡ� [12]���ȼ��������״�ı��ı߽��,ͨ��TPS�Լ����ı����н���,Ȼ��������ʶ���֧���ε��ˡ� [77]�����һ�ַָ������(SPN)��ȷ��ȡ�ı�����,����ѭ[10]������ս����
3���ǵķ���?
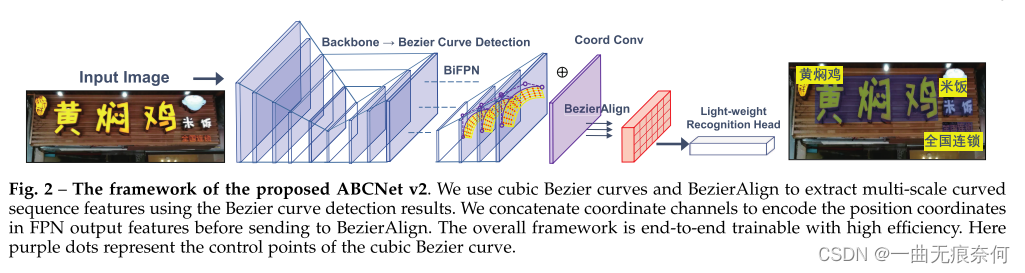
���ǵķ�����ֱ�۹ܵ���ͼ2��ʾ�� ��[78]��[79]��[80]������,���Dz��õ��Ρ���ê�ľ�����������Ϊ����ܡ� ê����Ƴ���������������ļ�⡣ �ڼ��ͷ���������ͼ���ܼ�Ԥ����,�ü��ͷ��4������Ϊ1,���Ϊ1��3��3�˵Ķѵ������㹹�ɡ� ������,���ǽ�����ABCNet V2�������ؼ�����:1)Bezier�����; 2)�������ģ��; 3)����; 4)������ע����ʶ��ģ��; 5)����Ӧ�˵�����ѵ����; 6)�ı���λ������?
3.1�����������?
����ڷָ�ķ���[44],[46],[47],[49],[76],[81]���,���ڻع�ķ������ʺ���������״���ı����,��[42],[52]��ʾ�� ��Щ������һ��ȱ������ˮ�߸���,������Ҫ���ӵĺ���������ܻ�����ս���� Ϊ�˼�������״�����ı�ʵ���ļ��,���������ͨ���Լ����ؼ�����лع������Bezier���ߵķ����� Bezier���߱�ʾ��Bernstein����ʽΪ���IJ�������C(t)�� �������ʽ(1)��ʾ:
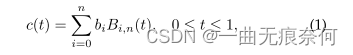
?����,n��ʾ��,bi��ʾ��i�����Ƶ�,bi,n(t)��ʾBernstein������ʽ,��ʽ(2)��ʾ:?

? �Ƕ���ʽϵ���� Ϊ����Bezier�������������״���ı�,���Ǵ����е����ݼ��п���������״�ij����ı�,��ͨ������֤������Bezier����(��n=3)������ϲ�ͬ��ʽ�����泡���ı�,�ر����ڴ��дʼ�ע�͵����ݼ��С� �߽��������ı��м�������ݼ��Ͽ��ܹ����ø���,���ı��м�������ݼ��п��ܻ���һ��ʵ���г��ֶ������ ��ʵ�鲿��,�����ṩ�˹���Bezier���ߵĽ����ıȽϡ� ����Bezier���ߵ�ͼʾ��ͼ3��ʾ��?
�Ƕ���ʽϵ���� Ϊ����Bezier�������������״���ı�,���Ǵ����е����ݼ��п���������״�ij����ı�,��ͨ������֤������Bezier����(��n=3)������ϲ�ͬ��ʽ�����泡���ı�,�ر����ڴ��дʼ�ע�͵����ݼ��С� �߽��������ı��м�������ݼ��Ͽ��ܹ����ø���,���ı��м�������ݼ��п��ܻ���һ��ʵ���г��ֶ������ ��ʵ�鲿��,�����ṩ�˹���Bezier���ߵĽ����ıȽϡ� ����Bezier���ߵ�ͼʾ��ͼ3��ʾ��?
?��������Bezier����,���ǿ��Խ�������״�ij����ı����������Ϊһ�������ڰ�Χ�лع�Ļع�����,���ܹ��а˸����Ƶ㡣 ��ע��,�����ĸ����Ƶ�(�ĸ�����)��ֱ�ı���������״�����ı��ĵ�������� Ϊ��һ����,������ÿ�����ߵ��������ϲ�ֵ������������Ƶ㡣 Ϊ��ѧϰ���Ƶ������,�����������ɡ�3.1.1��������Bezier����ע��,����ѭ[34]�����ƵĻع鷽����Ŀ����лع顣 ����ÿ���ı�ʵ��,����ʹ��?

?����Xmin��Ymin�ֱ��ʾ4���������Сx��yֵ�� Ԥ����Ծ���ĺô�������Bezier���߿��Ƶ��Ƿ�ͼ��߽��ء� �ڼ��ͷ�ڲ�,����ֻʹ��һ���������4��(n+1)(nΪBezier���߽���)���ͨ����ѧϰ��x�ͦ�y,�⼸������ѵ�,�������Ȼ��ȷ�ġ� �����ڡ�4������ϸ�ڡ�?
3.1.1������������ֵ����?
����һ����,���Ǽ�Ҫ�����������ԭʼע�͵Ļ���������Bezier���ߵ�����ֵ�� ������״�����ݼ�,����total-text[41]��scutctw1500[42],���ı�����ʹ�ö����ע�͡� �������߽߱��ϵ�ע�ǵ�{pi}n i=1,����pi��ʾ��iע�ǵ�,��ҪĿ�����������(1)������Bezier����c(t)�����Ų����� Ϊ��ʵ����һ��,���ǿ��Լ�Ӧ�ñ�����С�������,������ʾ:

?���� m ��ʾ���߽߱��ע�͵�������� ���� Total-Text �� SCUT-CTW1500,m �ֱ�Ϊ 5 �� 7�� ?t ��ͨ��ʹ���ۻ������������ܳ��ı���������ġ� ����ʽ(1)��ʽ(4),���ǽ�ԭ�������߱�עת��Ϊ�������ı��������ߡ� ��ע��,����ֱ��ʹ�õ�һ�������һ��ע�͵�ֱ���Ϊ��һ�� (b0) �����һ�� (bn) ���Ƶ㡣 ���ӻ��Ա���ͼ 1 ��ʾ,��������ɵĽ�����Ӿ����������Ա�ԭʼע���á� ����,���ڽṹ�����,����ͨ��Ӧ����������� BezierAlign(�μ� ��3.3)���ɵ��ƶ��ı�ʶ������,�����������ı�Ť��Ϊˮƽ��ʾ�� �������������ɵĸ�������ͼ 4 ��ʾ�����Ƿ����ļ���ʹ���ܹ���ͳһ�ı�ʾ��ʽ����������״��
3.2 COORDCONV
?�� [14] ��ָ��������,��ѧϰ (x,y) �ѿ����ռ��е������������ؿռ��е�����֮���ӳ��ʱ,���������ʾ�������ԡ�ͨ�����������ӵ�����ͼ������Ч�ؽ�������⡣��������������б����ʵ�� [15] Ҳ����,����������Ϊʵ���ָ��ṩ��Ϣ��ʾ��Let fouts��ʾFPN�IJ�ͬ����������,Oi,x��Oi,y�ֱ��ʾFPN�ĵ�i��������λ�� (�������˲�����λ��) �ľ���x��y���ꡣ����Oi,x��Oi,y����������ͼfox��foy��ɡ�����ֻ�ǽ�fox��foy���ӵ���ͨ��ά�ȵ����һ��foutsͨ�������,�γ��˾��и�������ͨ����������,��������뵽����������,���ں˴�С,����������С�ֱ�����Ϊ3��1��1�����Ƿ���,ʹ�����ּ�����������Դ����߳����ı���λ�����ܡ�

?3.3bezieralign?
Ϊ��ʵ�ֶ˵��˵�ѵ��,��ǰ�Ĵ�������������ø��ֲ���(��������)����������ʶ���֧��ͨ��,����������ʾ����������ü����̡�Ҳ����˵,����һ������ͼ����Ȥ����(RoI),ʹ�ò���������ȡRoI������,����Ч�����һ���̶���С������ͼ��Ȼ��,��ǰ���ڷǷֶεķ����IJ�������,����RoI��[3]��ROIROATE[5]���ı��������[4]��RoI�任[75],����ȷ����������״�ı���������ͨ�����ýṹ��Bezier���߽߱��IJ���������,�������BezierAlign������������/����,����Կ�����RoAlign�������չ[82]����RoIAlign��ͬ,BezierAlign�IJ���դ�����״���Ǿ��Ρ��෴,������״�����ÿһ�ж����ı��ı��������߽߱��������������ڿ��Ⱥ߶��Ϸֱ���еȾ���,��������������˫���Բ�ֵ��
?��ʽ��,������������ӳ���Bezier���߿��Ƶ�,�Դ�СΪHout��Wout�ľ����������ӳ�������������ؽ��д����� �Ծ���λ��(GIW,GIH)���������ͼ������GiΪ��,���Ǽ���T����:?

Ȼ�����ʽ(1)�������Bezier���߽߱�tp����Bezier���߽߱�bp�ĵ㡣 ����TP��BP,���ǿ���ͨ��ʽ(6)�Բ�����OP������������:

?����OP��λ��,���ǿ��Ժ�����Ӧ��˫���Բ�ֵ���������� ���ڶ������ľ�ȷ����,�ı�ʶ������ܵõ���ʵ���Ե���ߡ� ���ǽ�bezieralign�������������Խ����˱Ƚ�,��ͼ5��ʾ��


3.4����ע������ʶ���֧?
�ӹ����������Ժ�Bezieralign������,���������һ��������ʶ���֧,���1��ʾ,�Ա�����ִ�С� ����6�������㡢1��˫��LSTM���һ������ע������ʶ��ģ����ɡ� �ڻ���汾[16]��,���ǽ�CTC��ʧ[59]Ӧ����Ԥ��ͻ�������֮����ı��ַ�������,�����Ƿ��ֻ���ע������ʶ��ģ��[10]��[60]��[83]��[84]��ǿ��,���Ե��¸��õĽ���� ���ƶϽ�,�ü���Bezier���ߴ���ROI����,���3.1��ʾ�� ע��,��[16]��,����ֻʹ�����ɵ�Bezier��������ȡѵ�������е�ROI������ �ڱ�����,����Ҳ�����˼����(����3.5)��?
?ע����Ʋ�����RNN��ʼ״̬�ͳ�ʼ���ŵ�Ƕ��������������Ԥ�⡣ ��ÿһ����,�ݹ��ʹ��C-���SoftmaxԤ��(��ʾԤ�������)����ǰ������״̬�Ͳü���Bezier���������ļ�Ȩ������������ Ԥ���������,ֱ��Ԥ�����ĩβ(EOS)���š� Ӣ��γ̵İ༶������Ϊ96��(������EOS����),��˫��γ̵İ༶��������Ϊ5462�ˡ� ��ʽ��,��ʱ�䲽��t��,ע����Ȩ�������·�������:?

?����,HT-1����������״̬,K��W��U��B�ǿ�ѧϰ��Ȩ�ؾ���Ͳ����� �������������ļ�Ȩ�ͱ�ʾΪ:?
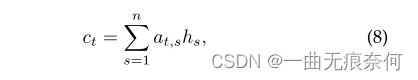
����at,s����Ϊ:

Ȼ��,���Ը�������״̬,������ʾ:?
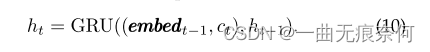
����,Embedt-1���ɷ��������ɵ���ǰ������yt��Ƕ������:

��1-ʶ���֧�Ľṹ,����CRNN�ļ汾[58]�� �������о�����,����С����Ϊ1�� n��ʾ������С�� C��ʾͨ����С�� h��w��ʾ�������ͼ�ĸ߶ȺͿ���,nclass��ʾԤ����ĸ�����?
?
?���,������Softmax���������Ƹ��ʷֲ�P(ut)��?
![]()
?����v��ʾҪѧϰ�IJ����� Ϊ���ȶ�ѵ��,���ǻ�ʹ���˽�ʦǿ�Ʋ���[85],�����ǵ�ʵ����,��Ԥ����ĸ�������Ϊ0.5�������,�ò��Դ���һ��������ʵ�ַ���������һ��Ԥ���GRUԤ�⡣?
3.5����Ӧ�˵���ѵ��
�����Ƿ����Ļ���汾[16]��,������ѵ����ֻʹ�û���������Bezieralign�����ı�ʶ���֧�� �ڲ��Խ�,���ü�������������ü��� ���ݹ۲���,����������������ֵBezier���߰�Χ�о�ȷʱ,���ܻ����һЩ�� Ϊ�˻�����Щ����,���������һ�ּ���Ч�IJ���,��Ϊ����Ӧ�˵���ѵ��(AET)�� ����ʽ��,������������ֵ���Ƽ����,Ȼ����NMS�������������� Ȼ��,���ڿ��Ƶ�����ľ������С�ܺ�,����Ӧ��ʶ�������ֵ�����ÿ�������:?

����cp*�ǿ��Ƶ�ĵ�����ֵ�� n�ǿ��Ƶ����Ŀ�� �ڶԼ��������ʶ���ע��,���Ǽؽ���Ŀ�����ӵ�ԭʼ�ĵ�����ֵ���н��н�һ����ʶ��ѵ����?
3.6�ı���λ����?
?�����ı��Ķ�Ӧ��ͨ��Ҫ�����ʵʱ��; Ȼ��,�������о����Խ���������Ӧ���ڳ����ı�ʶ�� ģ��������Ŀ�����ڲ�Ӱ���������ܵ�ǰ����,��ȫ����������ɢΪ�ͱ��������� ���������ı�ʾ����(��������)���á� �����������ؿ���ΪB����,������ƽ����ĿΪ2B�� ��������,�����������ؿ��ȱ��,���ѧϰģ�Ϳ��ܻ����������������½��� Ϊ���־���,��ɢ�����Ӧ��������:?
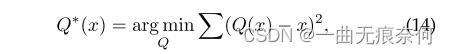
?����q(x)�����ӻ������� ��LSQ[86]�ļ�����,���IJ������·�����Ϊ�������ʡ� �����˵,�������Լ�������xa���κ�����xa,������ֵq(xa)��ͨ��һϵ�б任����ġ�?
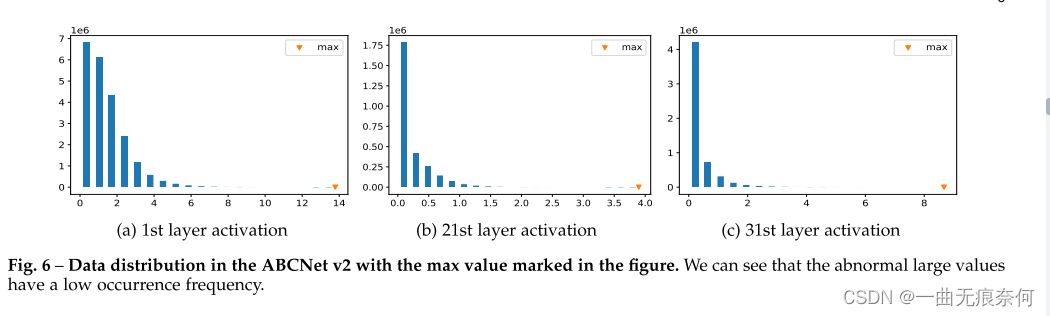
?����,���繤����Լ[87]��ָ����,�������е�ȫ�������ݶ�Ӧ������ӳ�䵽����ֵ�� ����һЩ�쳣�Ĵ�ֵ�dz�����,��ȫ���������к��ٳ��֡� ������ͼ6�н�һ�����ӻ���ABCNet v2��һЩ������ݷֲ�,���۲쵽�����Ƶ����� ���,����һ����ѧϰ������a����̬��������ɢ����Χ,�������������ݼ��õ��߽�:?

���,�ü���Χ(��ν��������)�е����ݱ�����ӳ�䵽����������,���ʽ(16)��ʾ:?

����l=2b�������ᵽ���������ĸ���,������������뺯���� ����,Ϊ�˱�������ǰ������ݷ�ֵ����,������ZA��Ӧ����Ӧ�ı�������,ͨ�����·����õ�Q(xa):?

?��֮,�������������д��:?

?�뼤�ͬ����,Ȩ�ز���ͨ����������ֵ,�������ɢ��֮ǰ�����������Ա任,������ʾ:?

?ģ��������һ����������Բ����������ݶ���ʧ(������). ������ΪԲ�������������������ݶȡ�����ֱͨ������(STE)�������һ���⡣������˵,���ǽ����뺯���ĵ���������дΪ1(?������ = 1). ����ʹ��С�����ݶ��½��Ż�����ѵ��ÿһ������������صIJ�����a�ͦ�w�Լ����������ԭʼ������Ӧע��,����ÿ��������,���������������a�ͦ�w�ֱ�Ϊ���뼤������Xa��Ȩ������Xw�е�����Ԫ�ع��������,����������ǰ���ڼ佻������˳��,���ʽ20��ʾ,�Ի�ø��õ�Ч�ʡ�ͨ������,��ʱ�ľ����������������ʽ����(����Ԫ��za�� Za��zw�� Zw��bλ����)�����,����Ӧ�ĸ��������,�������ӳ١��ڴ�ռ�ú��ܺķ���ʵ�����ơ�
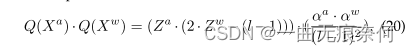
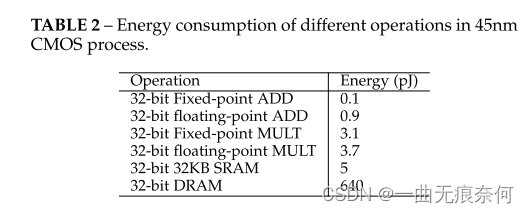
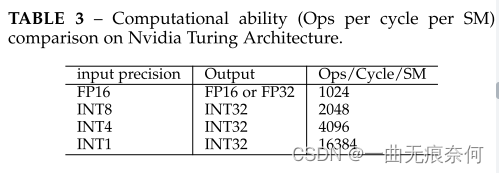
?������,���� b λ��������,���뼤���Ȩ�ؿ��Խ�ʡ 32 b �� �ڴ档�����ܺ�,�����ڱ� 2 ���г��˲�ͬ����Ƭ�ϲ����Ĺ����ܺijɱ������ǿ��Կ���,���� ADD �� MULT ���ܺijɱ�Զ���ڶ���������ܺijɱ�������,�� ALU �������,DRAM �������ĵ�����Ҫ�߳�һ�������������,������,��ȫ����ģ�����,����ģ���п��ܽ�ʡ�����������������ӳٷ���,����ģ�Ͷ�ȫ����ģ�͵�ʵ�ʼ���ȡ����ƽ̨�϶��������븡�������ļ����������� 3 ��ʾ�� Nvidia Turing �ܹ���ÿ�� SM ��ÿ�����ڵIJ��������ǿ��Դӱ� 3 ���˽,��ƽ̨�ϵ�ȫ���ȶ�Ӧ�����,8 λ�����п���ʵ�� 2 ���ļ��١�������ӡ����̵���,4 λ����Ͷ�Ԫ������(1 λ)�������ٶȷֱ��ȫ����ģ�Ϳ� 4 ���� 16 ����
4��ʵ��
?Ϊ������ABCNet V2����Ч��,�����ڶ��ֳ����ı����Ͻ�����ʵ��,�����������ı���ICDAR'15[32]��MSRA-TD500[26]��RECTS[39]�Լ�����������״�Ļ�Total-Text[41]��SCUT-CTW1500[42]�� ��Total-Text��SCUT-CTW1500�Ͻ�������ʴ�о�,����֤��������ķ�����ÿ����ɲ��֡�?
?
4.1ʵ��ϸ��?
?��������˵��,����˴�������������ѭ��������ǰ����һ����ͨ������,�� ResNet-50 [88] ���������������� (FPN) [89]�����ڼ���֧,������ 5 ������ͼ��Ӧ�� RoIAlign,�ֱ��ʷֱ�Ϊ����ͼ��� 1/8��1/16��1/32��1/64 �� 1/128,������ʶ���֧,BezierAlign ����������ͼ�Ͻ��д�С�ֱ�Ϊ 1/4��1/8 �� 1/16,��������Ŀ��Ⱥ߶ȷֱ�����Ϊ 8 �� 32�����ڴ�Ӣ�����ݼ�,Ԥѵ�������Ǵӹ������õĻ���Ӣ�ﵥ�ʼ�������ݼ����ռ���,������һ���������� 150K �ϳ����ݡ�7K ICDARMLT ���� [38] �Լ�ÿ�����ݼ�����Ӧѵ�����ݡ�Ȼ����Ŀ�����ݼ���ѵ��������Ԥѵ��ģ�͡���ע��,����֮ǰ���ָ� [16] �е� 15k COCO-Text [90] ͼ��δ�ڴ˸Ľ��汾��ʹ�á����� ReCTS ���ݼ�,���Dz��� LSVT [91]��ArT [92]��ReCTS [39] �ͺϳɵ�Ԥѵ��������ѵ��ģ�͡�����,���ǻ�������������ǿ����,��������߶�ѵ��,�̳ߴ�� 640 �� 896(���Ϊ 32)Ψһѡ��,���ߴ�С�� 1600;������ü�,����ȷ���ü�ͼ������ı�ʵ��(����һЩ���������������������,���Dz�Ӧ������ü�)������ʹ�� 4 �� Tesla V100 GPU ѵ�����ǵ�ģ��,ͼ��������СΪ 8������������Ϊ 260K;��ʼ��ѧϰ��Ϊ 0.01,�ڵ� 160K �ε���ʱ���� 0.001,�ڵ� 220K �ε���ʱ���� 0.0001��

?4.2��
Bezier���ߺϳ����ݼ�150k.���ڶ˵��˳����ı����ַ���,ʼ����Ҫ��������Ѻϳ����ݡ�����,���е�800k SynText���ݼ� [93] ��Ϊ�����ֱ�ı��ṩ��һ���ı��α߽��Ϊ��ʹ������״�ij����ı��������ͷḻ,��������һЩŬ��,��VGG�ϳɷ����ϳ���150K��ͼ������ݼ� (94,723ͼ�������ֱ�ı�,54,327ͼ������������ı�) [93]���ر��,���Ǵ�COCO-text [90] ��ɸѡ��40k���ı�����ͼ��,Ȼ��Ϊ�����ı���Ⱦ��ÿ������ͼ��ķָ��ɰ�ͳ�����ȡ�Ϊ������ϳ��ı�����״������,����ͨ��ʹ�ø���������������Ͽ�ϳɳ����ı�����VGG�ϳɷ���,��Ϊ�����ı�ʵ�����ɶ����ע�͡�Ȼ��,ͨ�� �� 3.1.1�����������ɷ���,��ע����������Bezier���������������ǵ��ۺ�����ʾ����ͼ8��ʾ����������Ԥѵ��,���ǰ�����������ͬ�ķ����ϳ���100K��ͼ��,����һЩʾ����ͼ9��ʾ��
Total-Text ���ݼ� [41] �� 2017 �����������Ҫ��������״�ij����ı���֮һ,���ǴӸ��ֳ������ռ���,���������ı��ij��������Ժ͵ͶԱȶȱ����� ������ 1,555 ��ͼ��,���� 1,255 ������ѵ��,300 �����ڲ��ԡ� Ϊ��ģ����ʵ����ij���,�����ݼ��Ĵ����ͼ���������ij����ı�,ͬʱ��֤ÿ��ͼ��������һ���������ı��� �ı�ʵ��ʹ�û��ڵ��ʼ���Ķ���ν���ע�͡� ������չ�汾[41]ͨ�����ı�ʶ������֮���ù̶���ʮ����ע��ÿ���ı�ʵ�����Ľ����ѵ������ע�͡� ���ݼ�������Ӣ���ı��� Ϊ�������˵��˽��,������ѭ����ǰ�ķ�����ͬ�Ķ�����,ʹ�� F-measure ����������ȷ�ȡ� ?SCUT-CTW1500 ���ݼ� [42] �� 2017 ���������һ����Ҫ��������״�����ı������� Total-Text ���,�����ݼ�����Ӣ�ĺ������ı��� ����,ע���ǻ����ı��м����,��������һЩ�����ĵ����ı�,������С�ı����ܶѵ���һ�� ?SCUT-CTW1500 ���� 1k ��ѵ��ͼ��� 500 ������ͼ��
ICDAR2015���ݼ�[32]�ṩ������ʵ������żȻ�����ͼ�� ����ǰ��ICDAR���ݼ���ͬ,����ǰ��ICDAR���ݼ���,�ı��Ǹɾ���,�������õ�,������ͼ����ˮƽ���С� �����ݼ�����1000��ѵ��ͼ���500�����ӱ����IJ���ͼ�� һЩ�ı�Ҳ�������κη�����κ�λ�ó���,��С��С��ֱ��ʽϵ͡� ע���ǻ��ڴʼ���,��ֻ����Ӣ��������?


?MSRA-TD500 ���ݼ� [26] ���� 500 �Ŷ�����Ӣ��ͼ��,���� 300 ��ͼ������ѵ��,200 ��ͼ�����ڲ��ԡ� �����ͼ��������������ġ� Ϊ�˿˷�ѵ�����ݵIJ���,����ʹ�������ᵽ�ĺϳ��������ݽ���ģ��Ԥѵ���� ?ICDAR'19-ReCTs ���ݼ� [39] ���� 25k ����ע�͵�����ͼ��,���� 20k ��ͼ������ѵ����,�������ڲ��Լ��� ��Ӣ���ı����,�����ı�������ͨ��Ҫ��ö�,�����ַ�6k��,�Ű渴��,���己�ࡣ �����ݼ���Ҫ�����̵��־���ı�,��Ϊÿ���ַ��ṩע�͡� ?ICDAR'19-ArT ���ݼ� [92] ��Ŀǰ����������״�����ı����ݼ��� ����Total-text��SCUT-CTW1500�Ľ�Ϻ����졣 ��ͼ����ÿ��ͼ������һ��������״���ı��� ���ı���������ںܴ���졣 ?Art ���ݼ������Ϊһ��ѵ����,���а��� 5,603 ��ͼ��� 4,563 �����ڲ��Լ��� ���е�Ӣ�ĺ������ı�ʵ�����ý��ܵĶ����ע�͡� ?ICDAR'19-LSVT ���ݼ� [91] �ṩ��ǰ��δ�еĴ����־��ı��� ���ܹ��ṩ�� 450k ͼ��,���зḻ����ʵ������Ϣ,���� 50k ������ע��(30k ����ѵ��,���� 20k ���ڲ���)�� �� Art [92] ����,�����ݼ�������һЩ�ö����ע�͵������ı���

4.3�����о�
Ϊ��������������������Ч��,�������������ݼ��Ͻ�������ʴ�о�,Total-Text��SCUT-CTW1500�� ���Ƿ���,���ڳ�ʼ���IJ�ͬ,����һЩѵ���� ����,�ı�ʶ������Ҫ�������ַ����ܱ���ȷʶ�� Ϊ�˱�����Щ����,���Ƕ�ÿ�ַ�����������ѵ��,������ƽ������� ������5��ʾ,����������ģ�鶼�������������ݼ��϶Ի���ģ�Ͳ������ԵĸĽ��� ���ǿ��Կ���,ʹ�û���ע������ʶ��ģ��,��Total-Text��SCUT-CTW1500�ϵ�ʶ�����ֱ������2.7%��7.9%�� Ȼ��,����ʹ�û���ע������ʶ���֧������������ģ�顣 һЩ��������:?
ʹ�� biFPN �ܹ�,������Զ������ 1.9% �� 1.6%,�������ٶȽ����� 1 FPS�����,�������ٶȺ�ȷ��֮��ȡ���˸��õ�ƽ�⡣
? ʹ�á�3.2 ���ᵽ���������,���������ݼ��ϵĽ�����Էֱ�������� 2.8% �� 2.9%����ע��,���ָĽ������������Եļ��㿪����
? ���ǻ������ˡ�3.5 ���ᵽ��AET ����,����ֱ������1.2% ��1.7%��
? ���,���ǽ�����ʵ����չʾ���������߽������������Ӱ������������˵,����ʹ�� 4 �ױ���������Ϊ��ͬ�ĺϳ�ͼ�����ʵͼ�������������л�����ʵ��Ȼ��,����ͨ���ع���Ƶ㲢ʹ�� 4 �� BezierAlign ��ѵ�� ABCNet v2���������ֱ����� 3 ��������ͬ���� 5 ��ʾ�Ľ������,����˳���������ı���λ���,�������ڲ����ı���ע�͵� SCUT-CTW1500 �ϡ�����ͬ��ʵ��������,������ Totaltext ���ݼ���ʹ�� 5 �� Bezier ���߽�һ������ʵ��;Ȼ��,��������,���Ƿ��־� E2E Hmean ����,���ܴ� 66.2% �½��� 65.5%�����ݹ۲�,���Ǽ����½���������Ϊ���ߵĽ������ܵ��¿��Ƶ�ľ��ұ仯,����ܻ�Ӿ�ع���Ѷȡ�ʹ���Ľױ��������ߵ�һЩ�����ͼ 10 ��ʾ�����ǿ��Կ������߽����Ը�����,�Ӷ����Ը�ȷ�زü��ı������Թ�����ʶ��
����ͨ����Bezieralign����ǰ�IJ����������бȽ�����һ��������,��ͼ5��ʾ�� Ϊ�˹�ƽ�Ϳ��ٵıȽ�,����ʹ����һ��С��ѵ���Ͳ��������� ��4����ʾ�Ľ������,Bezieralign�����������ƶ˵��˵Ľ���� ���Ե�������ͼ11��ʾ�� ��һ����ʴ�о�������Bezier������ʱ������,���ǹ۲쵽Bezier����������Χ�м�����ֻ�����˿��Ժ��Եļ��㿪����?
4.4�����Ƚ�ˮƽ�ıȽ�
?
?
?
�ڼ��Ͷ˵����ı���λ������,���ǽ����ǵķ�������ǰ�ķ��������˱Ƚϡ� ������������ȷ���˰���������ֵ�Ͳ��Թ�ģ���ڵ��������á� ���ڼ������,�������ĸ����ݼ��Ͻ�����ʵ��,��������������״�����ݼ�(Total-Text��SCUT-CTW1500)����������������ݼ�(MSRA-TD500��ICDAR2015)��һ��˫�����ݼ�RECTS�� ��6�еĽ������,���ǵķ��������������ĸ����ݼ���ʵ�����Ƚ�������,������ǰ�����Ƚ��ķ�����?
���ڶ˵��˵ij����ı���λ����,ABCNet v2��SCUT-CTW1500��ICDAR 2015���ݼ���ʵ�����������,����������ǰ�ķ����� ������7��ʾ�� ��Ȼ���ǵķ�����RECTS���ݼ��ϵ�1-NED�����Mask TextSpotter[10]��,��������Ϊ����û��ʹ�����ṩ��CharacterLevel��Χ��,�������ٶȷ������ǵķ�����ʾ�����Ե����ơ� ��һ����,���ݱ�6,������TextSpotter[10]���,ABCNet v2��Ȼ����ʵ�ָ��õļ�����ܡ� ���Լ��Ķ��Խ����ͼ7��ʾ�� ��ͼ�����ǿ��Կ���,ABCNet v2ʵ���˶Ը����ı���ǿ���������,����ˮƽ��������������ı�,���ܼ����ı�������ʽ��?
4.5��Mask TextSpotter V3��ȫ��Ƚ�?
ʹ���������ݽ��бȽϡ� ���Ƿ���������ķ�����ʹ������ѵ�����ݾͿ���ʵ����ϣ���Ķ�λ����� Ϊ����֤��Ч��,����ʹ�� Mask TextSpotter v3 [77] �Ĺٷ�����,��������ͬ�����ý���ʵ��,��ʹ�� TotalText �Ĺٷ�ѵ������ѵ��ģ�͡� ������˵,���Ƿ������Ż�����ѧϰ�� (0.002) ����Ϊ�� Mask TextSpotter v3 ��ͬ�� ������С����Ϊ 4,���ַ��������� 23 ��ε���ѵ���� Ϊȷ�������ַ������������,Mask TextSpotter v3 ����С�ߴ�Ϊ 800��1000��1200 �� 1400,���ߴ�Ϊ 2333����������С�ߴ� 1000 �����ߴ� 4000 ���С� ��������С�ߴ�Ϊ 640 �� 896,���Ϊ 32,���ߴ�����Ϊ 1600��Ϊ���ȶ�ѵ��,������ѵ����ʹ�� AET ���ԡ� ���Ե���С�ߴ�Ϊ 1000,���ߴ�Ϊ 1824�����ǻ����������������ҵ� Mask TextSpotter v3 �������ֵ�� ��ͬ�����Ľ����ͼ 12 ��ʾ�����ǿ��Կ���,��Ȼ Mask TextSpotter v3 һ��ʼ�����ø���,�����Ƿ��������ս������(56.41% vs. 53.82%)��



?ʹ�ô��ģ���ݽ��бȽϡ� ���ǻ�ʹ�����㹻��ѵ����������Mask TextSpotter V3���и����ıȽϡ� ����ʽ��,����ʹ��Bezier���ߺϳ����ݼ�(150K)��MLT(7K)��TotalText��ϸ��ѵ��Mask TextSpotter V3,���������ǵķ�����ȫ��ͬ�� ѵ����ģ��������С����������������������Ϊ4.1�����ᵽ����ͬ�� ��������������Ϊ����TextSpotter V3�ҵ������ֵ�� ������8��ʾ,�������ǿ��Կ���Mask TextSpotter V3��F-������������ABCNet V1 0.9,ABCNet V2��������Mask TextSpotter V3(65.1%��70.4%)�� ����ͬ�IJ��Գ߶�(���ߴ�����Ϊ1824)���豸(RTX A40)�²���������ʱ��,��һ��֤���˸÷�������Ч�ԡ�?
?4.6������
��һ����Ԥ���������������������� ���ǹ۲쵽���ֳ�������,���ǿ��ܻ�����ABCNet v2�ij����ı���λ���ܡ�?

?��һ����ʾ��ͼ 13 ��ʾ���С��ı�ʵ�����������ַ�������ÿ���ַ�,�Ķ�˳���Ǵ����ҡ����Ƕ�������ʵ��,�Ķ�˳���Ǵ��ϵ��¡����� Bezier ���������ı�ʵ���Ľϳ����ڲ��,��� BezierAlign ��������ԭʼ������Ƚ���һ����ת����,����ܵ�����ȫ��ͬ�ĺ��塣��һ����,�������ֻռ����ѵ������һС����,�����ױ������ʶ���Ԥ��Ϊ�����������,��ڶ����ַ��ġ�������ʾ���ڶ�����������ڲ�ͬ��������,��ͼ 13 �м���ʾ��ǰ�����ַ����ò�Ѱ�����鷨������д��,�������ʶ��һ����˵,�����սֻ��ͨ�������ѵ��ͼ�������⡣���ǻ�����CTW1500�IJ��Լ�����һ���������������,��ͬһ���ı�ʵ���д����������ϵIJ���,��ͼ13�ĵ�������ʾ�������������,�ͽ��������α��������߿��ܻ��ܵ�����,��Ϊ������״��ʾ��ȷ,�ַ���i���������ʶ��Ϊ��д��I��������,����������ټ�,�����Ƕ�����Щʹ�õ��ʼ��߽������ݼ���

4.7�����ٶ�
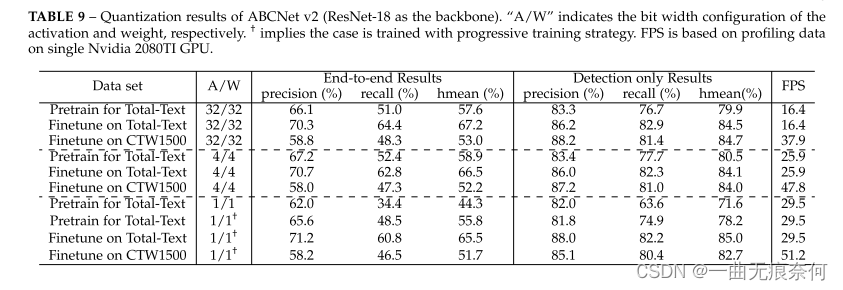
Ϊ�˽�һ�����������������DZ��ʵʱ����,������������������������������ٶȡ�����ģ�Ͳ����������ͬ������,���б� 5 ����ʾ�Ļ���ע������ʶ���֧�����ɱ� ResNet-18 ȡ��,������������ٶ�,��ֻ�����˱ʾ��ȡ��� 9 �б����˾��и�������λ����(4/1 λ)��������������ܡ����г���ȫ���������Խ��бȽϡ�Ϊ��ѵ����������,���������ںϳ����ݼ���Ԥѵ���˵�λģ�͡�Ȼ��,������ר�����ݼ� TotalText �� CTW1500 ���������Ի�ø��õ����ܡ�������Ԥѵ��ģ�ͺ���ģ�͵�ȷ�Խ������Ԥѵ���ڼ�,ѵ���� 260K ����,������СΪ 8����ʼѧϰ������Ϊ 0.01,�� 160K �� 220K ����ʱ���� 10������ TotalText ���ݼ�����,������С����Ϊ 8,��ʼѧϰ������Ϊ 0.001�������� 5K �ε������� CTW1500 ���ݼ��Ͻ�����ʱ,������С�ͳ�ʼѧϰ����ͬ������,�ܵ�����������Ϊ 120k,�����ڵ��� 80k ʱѧϰ�ʳ��� 10����֮ǰ��������������,���������������е����о�����,�������������㡣���û���ر�˵��,���罫ʹ��ȫ���ȶ�Ӧ����г�ʼ����
�ӱ�9��,���ǿ����˽,�������ǵ�����������4λģ���ܹ������ȫ����ģ���൱�����ܡ�����,�ںϳ����ݼ���Ԥѵ����4λģ�͵Ķ˵���hmean��������ȫ����ģ��(57.6%��58.9%)������,TotalText��CTW1500��4λģ�͵Ķ˵���hmean�ֱ��ȫ����ģ�͵�0.7%(67.2%��66.5%)��0.8%(53.0%��52.2%)����ʵ��,4λģ�͵����ܼ���û���½�(��ͼ������Ŀ����������Ҳ������ͬ���Ĺ۲�[98]),�����ȫ���ȳ����ı���λģ�������൱������ࡣȻ��,����������������кܴ���½�,�˵���hmean��Ϊ44.3%��Ϊ�˲���,���ǽ���ʹ�ý���ʽѵ����ѵ��BNN(������������)ģ��,�����������ؿ�����С(����,4bit�� 2���ء� 1λ)��ʹ���µ�ѵ������(���д���?�IJ���),��������������ܵõ��������ơ�����,ʹ��BNNģ���ںϳ����ݼ���ѵ���Ķ˵���hmean����ȫ���ȶ�Ӧ��hmean��1.8%(57.6%��55.8%)��������������֮��,���ǻ��Ƚ�������ģ�ͺ�ȫ����ģ�͵������ٶȡ���ʵ����,ֻ��������������������һ�����,���籣����ȫ���ȵ�LSTM���ӱ�9���Կ���,�������½����������,ABCNet v2�Ķ����������ܹ�ʵʱ����TotalText��CTW1500���ݼ���
5����
���������ABCNet V2--һ��ʵʱ�Ķ˵��˷���,��ʹ��Bezier����������������״�ij����ı������ ABCNet V2ͨ��������Bezier�����ع�������״�ij����ı�,ʵ������Bezier�����������״�ij����ı��� �����Χ�м�����,���ǵķ��������˿��Ժ��Եļ�����ۡ� ��������Bezier���߰�Χ��,���ǿ���ͨ��һ���µ�Bezieralign����Ȼ������һ����������ʶ���֧,�����ȷ����ȡ������������Ҫ��,�����Ƕ����������ı�ʵ���� �ڲ�ͬ���ݼ��ϵ��ۺ�ʵ��֤������������������Ч��,����ʹ��ע����ʶ��ģ�顢BIFPN�ṹ�����������һ���µ�����Ӧ�˵���ѵ�����ԡ� ���,��������˽���������Ӧ����ʵʱ�����ģ�Ͳ���,��ʾ�˹㷺��Ӧ��DZ����

