一、案例说明
1.案例说明
研究短视频平台进行品牌传播的关系情况,品牌维度分为品牌活动,品牌代言人,社会责任感和品牌赞助共4项。还有购买意愿数据。案例数据中还包括基本个体特征比如性别、年龄,学历,月收等。以及短视频平台观看情况和消费情况。数据样本为200个。
2.分析目的
先通过因子分析,用少量因子反映分析题目的信息,从而达到降低维度,便于分析的目的,然后对因子命名用于回归分析。研究品牌四个维度对于购买意愿的影响,最终得到结论。
二、SPSSAU操作
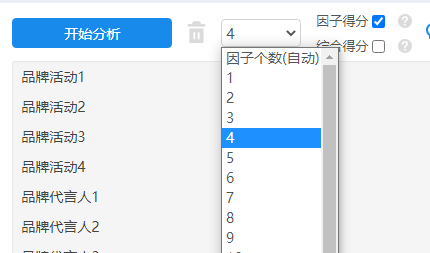
因为案例的预设维度为4所以将分析项拖拽到右侧分析框后,下拉选择因子个数为4并勾选因子得分。
三、因子分析结果
本案例因子分析结果主要分为五步,满足因子分析的条件后,要检查是否需要调整因子,否则结果可能会有偏差,调整因子后进行查看因子提取以及信息浓缩情况,最后进一步对于因子得分进行回归分析。下面一一说明。
1.前提条件
KMO值与Bartlete球形检验

使用因子分析进行信息浓缩研究,首先分析研究数据是否适合进行因子分析,从上表可以看出:KMO值为0.922,大于0.6,满足因子分析的前提要求,意味着数据可用于因子分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行因子分析。接下来查看分析项是否需要调整。
2.因子与测量项之间的关系
一般情况下,如果16项与4个因子之间的对应关系情况,与专业知识情况不符合,比如第一项被划分到了第一个因子下面,此时则说明可能Q1这项应该被删除处理,其出现了‘张冠李戴’现象。因而在进行分析时很可能会对部分不合理项进行删除处理。除此之外,也有可能会出现‘纠缠不清’现象。
(1)“张冠李戴”
一般情况下,如果16项与4个因子之间的对应关系情况,与专业知识情况不符合,比如Q1被划分到了第一个因子下面,此时则说明可能Q1这项应该被删除处理,其出现了‘张冠李戴’现象。例如案例中的“品牌代言人3”、“品牌代言人4”应该属于因子4但是分析时被划分到别的因子中。
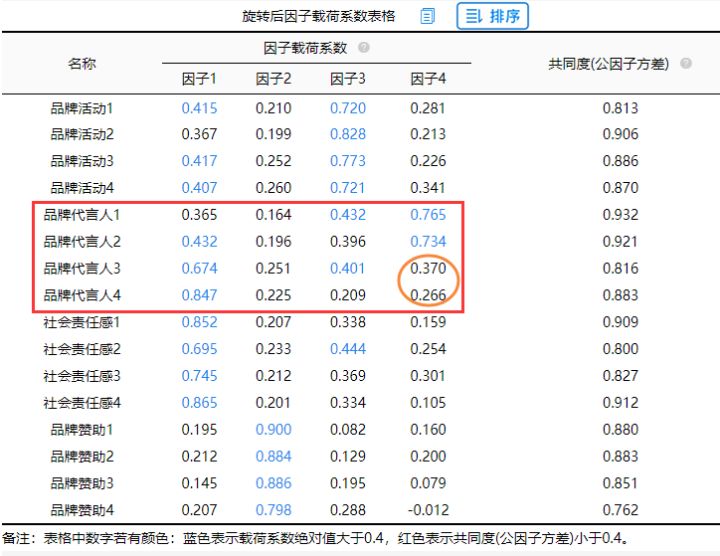
分析结果来源于SPSSAU
(2)“纠缠不清”
除了“张冠李戴”现象,有时候会出现‘纠缠不清’现象,比如案例中的“品牌活动1”可归属为因子1 ,同时也可归属到因子3,这种情况较为正常(称作‘纠缠不清’),需要结合实际情况处理即可,可将该项删除,也可不删除,此案例中“品牌活动1”按分析应属于因子3,所以不进行删除处理,通过分析其他‘纠缠不清’的分析项也是一样,都不进行删除处理,这时,分析带有一定主观性。(PS:案例中‘纠缠不清’的情况不只有“品牌活动1”比如“品牌活动3”等,需要根据实际情况选择是否处理)。
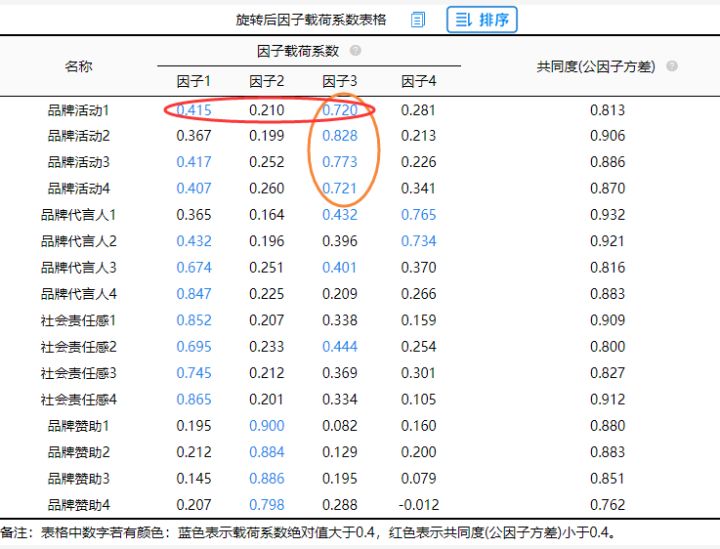
分析结果来源于SPSSAU
因子分析是一个多次重复的过程,比如删除某个或多个题项后,则需要重新再次分析进行对比选择等。最终目的在于:因子与分析项对应关系,与专业知识情况基本吻合。
总结可知,“品牌代言人3”、“品牌代言人4”应该属于因子4但是分析时被划分到别的因子中。属于“张冠李戴”现象所以需要删除处理。删除后重新分析如下。
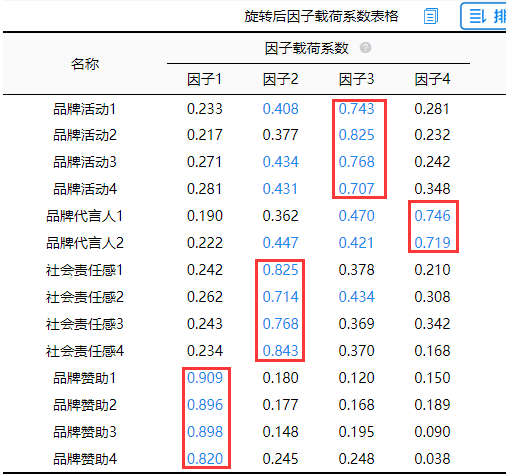
上图可知“品牌代言人1-2”可同时出现在因子3和因子4下并且1代言人2还出现在因子2下面,但考虑到因子4当前仅余下2项,因而表示可以接受,以及“品牌活动1、3、4”、“社会责任感2”是一样的,根据专业知识可考虑不用删除,最终找出四个因子,它们分别与项之间的对应关系良好。因子分析结束。
3.调整因子后的结果
(1)KMO 和 Bartlett 的检验

使用因子分析进行信息浓缩研究,首先分析研究数据是否适合进行因子分析,从上表可以看出:KMO值为0.914,大于0.6,满足因子分析的前提要求,意味着数据可用于因子分析研究。以及数据通过Bartlett 球形度检验(p<0.05),说明研究数据适合进行因子分析。
(2)因子载荷系数表
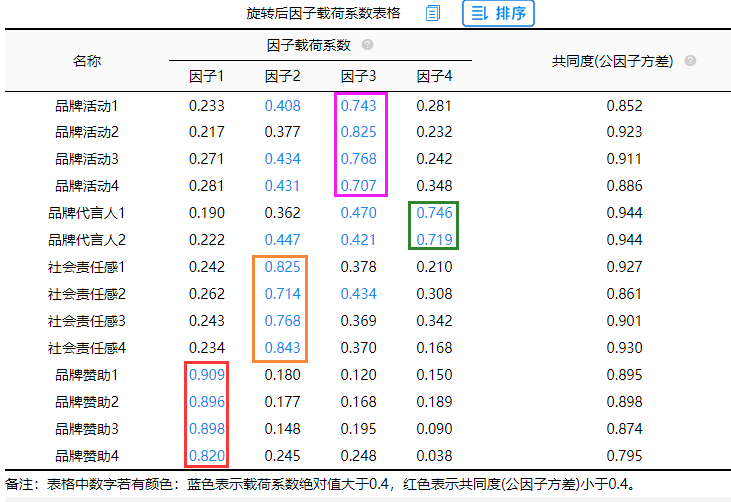
所有研究项对应的共同度值均高于0.4,意味着研究项和因子之间有着较强的关联性,因子可以有效的提取出信息。确保因子可以提取出研究项大部分的信息量之后,接着分析因子和研究项的对应关系情况(因子载荷系数绝对值大于0.4时即说明该项和因子有对应关系)。从上图可知 “品牌代言人2”可同时出现在因子2、因子3和因子4下面,但考虑到因子4当前仅余下2项,因而表示可以接受,其他分析项出现“纠缠不清”的情况也是就研究问题来说也是可以接受的。最终找出品牌活动、品牌代言、社会责任感以及品牌赞助共4个维度,它们分别与项之间的对应关系良好。因子分析结束。分析项不需要进一步调整,接下来进行查看因子的提取个数以及信息浓缩情况。
4.因子提取
(1)方差解释率
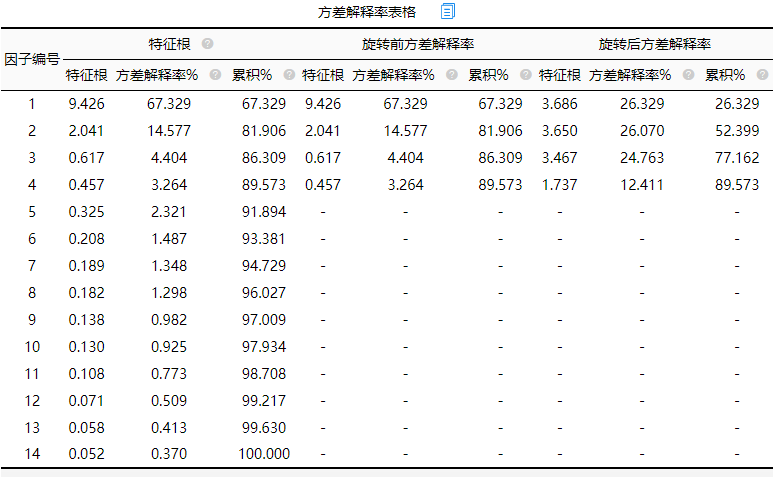
分析结果来源于SPSSAU
方差解释率可以说明因子包含原数据信息的多少,方差解释率越大说明因子包含的信息越多。因子分析中,主要关注旋转后的数据部分。由上图可以显示14个指标中,四个因子方差解释率分别为26.329%、26.329%、26.329%以及26.329%,累积方差解释率由这四项者相加为89.573%,累积方差解释率这个值没有固定标准,一般超过60%都可以接受。特征根对于因子的提取有什么作用,以下展开来说。
(2)特征根
特征根一般是指标旋转前每个因子的贡献程度。此值的总和与项目数匹配,此值越大,代表因子贡献越大。当然因子分析通常需要综合自己的专业知识综合判断,即使是特征根值小于1,也一样可以提取因子。在进行因子分析时,研究者没有预设因子数,系统就会以特征根“大于1”为标准进行划分。因为此案例在分析前的预设因子个数为4所以也同样可以进行分析。除了特征根之外SPSSAU还提供了更加直观的碎石图帮助判断。
- 碎石图
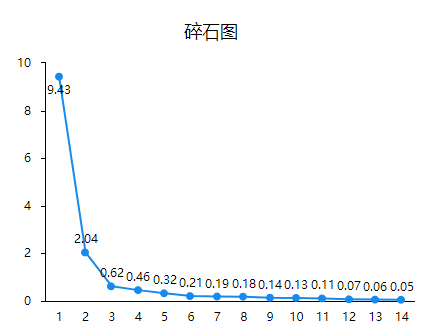
分析结果来源于SPSSAU
从图中可以看出,横轴表示指标数,纵轴表示特征根值,当提取前4个因子时,特征根值变化较明显,对解释原有变量的贡献较大;当提取4个以后的因子时,特征根变化也相对平稳,对原有变量贡献相对较小,由此可见提取前四个因子对原变量有的显著作用。碎石图仅辅助决策因子个数,如果由此图分析三个因子也是可以的。
此案例按专业知识来看提取四个因子,如果没有预设因子个数也可以默认让系统进行决策。提取后要观察因子的信息浓缩程度。
5.信息浓缩
旋转后因子载荷系数表
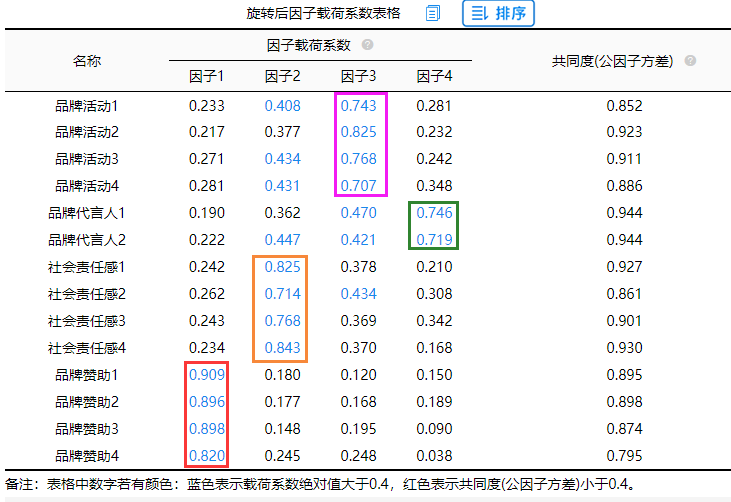
分析结果来源于SPSSAU
旋转后因子载荷系数可以用于判断因子与题项之间的对应关系,如果出现“张冠李戴”或者“纠缠不清”的情况需要关注,上述结果已经是处理后的结果,以及各个题项的共同度。如果某分析项对应的多个因子载荷系数绝对值均低于0.4,可考虑删除该项。上图分析中均大于0.4。所以不用删除调整。
从结果中可以看出,使用因子分析对14个项进行浓缩处理,浓缩为四个因子。因子与题项对应关系如下:
其中品牌赞助1-4在因子1上有较高的载荷,说明因子1可以解释这几个分析项,它们主要反映了短视频平台进行品牌传播中的品牌赞助;社会责任感1-4在因子2上有较高的载荷,它们主要反映了短视频平台进行品牌传播的社会责任感;品牌活动1-4在因子3上有较高的载荷,它们主要反映了短视频平台进行品牌传播的品牌活动;品牌代言人1-2在因子4上有较高的载荷,它们主要反映了短视频平台进行品牌传播的品牌代言人方面。
从上表可知:所有研究项对应的共同度值均高于0.4,意味着研究项和因子之间有着较强的关联性,因子可以有效的提取出信息。因为本篇案例是想得到因子得分后进行回归分析研究品牌四个维度对于购买意愿的影响,最终得到结论。所以对于因子分析权重方面不进行赘述,如想了解,可以点击文末链接进行查看。
6.因子得分
因子分析往往是预处理步骤,后续还需要结合具体研究目的进行分析,如回归分析、聚类分析等。此时,可能需要用到因子得分,返回分析页面勾选[因子得分]即可生成因子得分。
4个维度命名分别为品牌赞助、社会责任感、品牌活动以及品牌代言人如下:
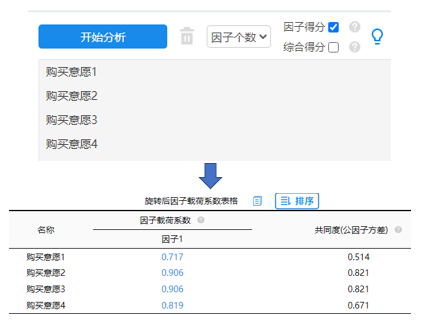
补充说明:对于购买意愿4项进行因子分析结果良好,并且将因子得分命名为“购买意愿”,部分结果如下
得到4个因子后,接下来进行线性回归。研究品牌四个维度对于购买意愿的影响,最终得到结论。
四、回归分析结果
因子分析结束后,可以用得到的分析项与几个因子的对应关系,通常可使用因子得分也可以使用平均分(问卷常使用平均分)继续后续用于回归分析。
4个维度命名分别为品牌赞助、社会责任感、品牌活动以及品牌代言人如 下:
将处理后的分析项进行回归分析研究品牌四个维度对于购买意愿是否有影响。其中自变量为“品牌赞助”、“社会责任感”、“品牌活动”以及“品牌代言人”,因变量为“购买意愿”。以下从分析过程、分析结果以及其它说明进行描述。
1.分析中间过程
此案例线性回归的分析中间过程将从F检验、模型拟合优度以及共线性三方面进行描述。
(1)F检验
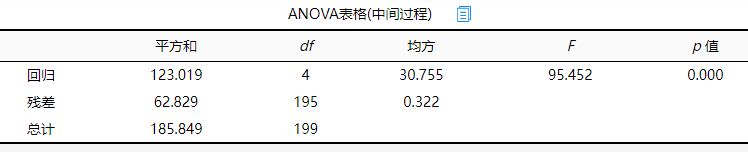
从上表可以看出,离差平方和为185.849,残差平方和为62.829,而回归平方和为123.019。回归方程的显著性检验中,统计量F=95.452,对应的p值远远小于0.05,被解释变量的线性关系是显著的,可以建立模型。建立模型后,还需要进一步查看模型的拟合优度。
(2)拟合优度

从上表可知,将“品牌赞助”、“社会责任感”、“品牌活动”以及“品牌代言人”作为自变量,而将顾客的“购买意愿”作为因变量进行线性回归分析,从上表可以看出,模型R方值为0.662,调整R方为0.655,其中R方是决定系数,模型拟合指标。反应Y的波动有多少比例能被X的波动描述。调整R方也是模型拟合指标。当x个数较多是调整R2比R2更为准确。意味着“品牌赞助”、“社会责任感”、“品牌活动”以及“品牌代言人”可以解释当前工资的66.2%变化原因。可见,模型拟合优度较好,说明被解释变量可以被模型解释的部分较多。接下来查看变量是否具有多重共线性。
(3)多重共线性
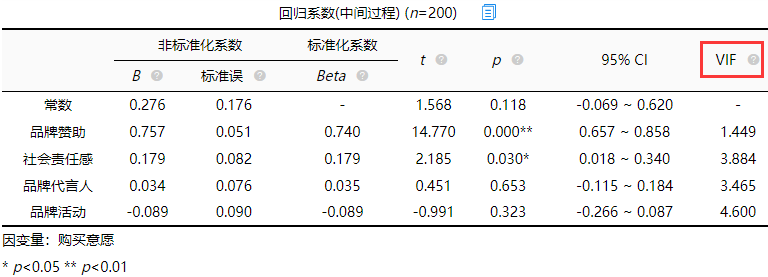
VIF值用于检测共线性问题,一般VIF值小于10即说明没有共线性(严格的标准是5),有时候会以容差值作为标准,容差值=1/VIF,所以容差值大于0.1则说明没有共线性(严格是大于0.2),VIF和容差值有逻辑对应关系,因此二选一即可,一般描述VIF值。在【线性回归】分析时,SPSSAU会智能判断共线性问题并且提供解决建议。 结果中可以看出,变量的VIF值均小于5,所以此案例不存在多重共线性的问题。
但是如果存在多重共线问题,建议三种解决方法一是使用逐步回归分析(让模型自动剔除掉共线性过高项);二是使用岭回归分析(使用数学方法解决共线性问题),三是进行相关分析,手工移出相关性非常高的分析项(通过主观分析解决),然后再做线性回归分析。
通过分析结果发现回归分析的F检验结果较好,并且模型模型拟合优度良好能够解释大部分信息以及不存在多重共线性问题。接下来对回归分析结果进行描述并得出结论。
2.线性回归分析结果

(1)模型公式
从上表可知,将“品牌赞助”、“社会责任感”、“品牌活动”以及“品牌代言人”作为自变量,而将购买意愿作为因变量进行线性回归分析,从上表可以看出,模型公式为:从上表可以看出,模型公式为:购买意愿=0.276 + 0.757*品牌赞助 + 0.179*社会责任感 + 0.034*品牌代言人-0.089*品牌活动 (对于此案例来说模型预测意义不大)。
(2)分析结果
对模型进行F检验时发现模型通过F检验(F=95.452,p=0.000<0.05),也即说明品牌活动,品牌代言人,社会责任感,品牌赞助中至少一项会对购买意愿产生影响关系,并且D-W值在数字2附近(一般时间序列模型才会考虑此值,其他无需过度关注),因而说明模型不存在自相关性,样本数据之间并没有关联关系,模型较好。最终具体分析可知:
品牌赞助的回归系数值为0.757(t=14.770,p=0.000<0.01),意味着品牌赞助会对购买意愿产生显著的正向影响关系。
社会责任感的回归系数值为0.179(t=2.185,p=0.030<0.05),意味着社会责任感会对购买意愿产生显著的正向影响关系。
品牌代言人的回归系数值为0.034(t=0.451,p=0.653>0.05),意味着品牌代言人并不会对购买意愿产生影响关系。
品牌活动的回归系数值为-0.089(t=-0.991,p=0.323>0.05),意味着品牌活动并不会对购买意愿产生影响关系。
总结分析可知:品牌赞助, 社会责任感会对购买意愿产生显著的正向影响关系。但是品牌代言人, 品牌活动并不会对购买意愿产生影响关系。
(3)影响关系大小
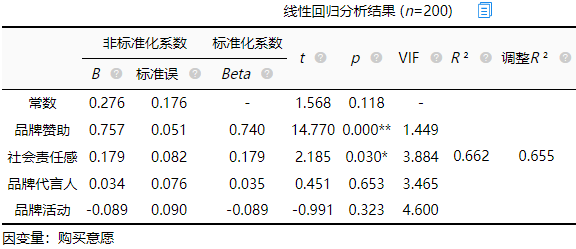
如果说自变量X已经对因变量Y产生显著影响(P< 0.01),还想对比影响大小,建议可使用标准化系数(?Beta)值的大小对比影响大小,Beta值大于0时正向影响,该值越大说明影响越大。Beta值小于0时负向影响,该值越小说明影响越大。品牌赞助, 社会责任感会对购买意愿产生显著的正向影响关系。二者标准化回归系数分别为:0.740、0.179,可以看出模型中“品牌赞助”对“购买意愿”影响最大其次是“社会责任感”。
3.其它
通过分析发现,四个自变量对于因变量均有影响并且关系均为正向影响关系,其中“品牌赞助”对“购买意愿”影响最大。除了上述内容外,SPSSAU还提供了因变量预测模型、简化格式以及coefPlot,但是模型预测等在此次分析中并不是重点。
(1)因变量预测模型
从上表可以看出,模型公式为:购买意愿=0.276 + 0.757*品牌赞助 + 0.179*社会责任感 + 0.034*品牌代言人-0.089*品牌活动(案例数据分析结果仅供参考)。
(2)简化格式
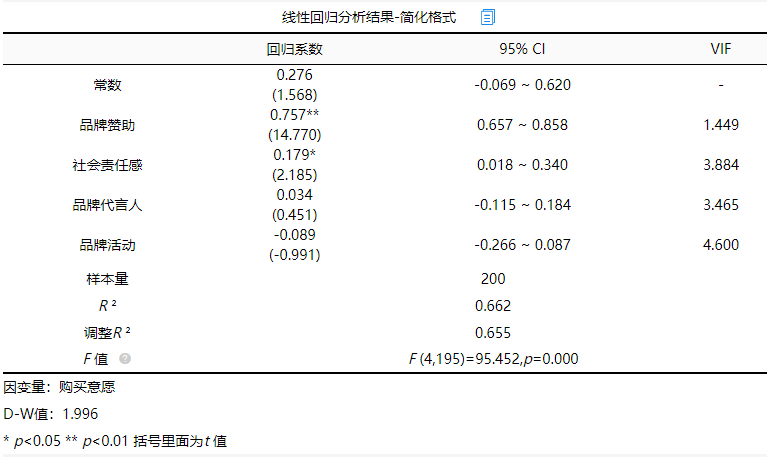
分析结果来源于SPSSAU
简化格式只提供了回归系数、95%CI以及VIF,其中一个“*”代表该项成0.05水平显著,两个“*”代表该项成0.01水平显著。所以“品牌赞助”、呈0.01水平显著,“社会责任感”呈0.05水平显著。
(3)coefPlot
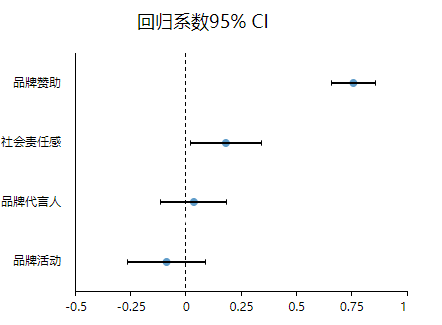
分析结果来源于SPSSAU
coefPlot展示具体的回归系数值和对应的置信区间,可直观查看数据的显著性情况,如果说置信区间包括数字0则说明该项不显著,如果置信区间不包括数字0则说明该项呈现出显著性。所以上图中“品牌赞助”、“社会责任感”两个分析项的置信区间都不包括0,都呈现显著性,其他两项包括0,所以不显著。
五、总结
本篇案例通过因子分析得到因子得分后进行回归分析,首先进行因子分析发现数据满足基本前提条件但是发现分析项需要调整,调整对应项后进行分析对因子提取、信息浓缩进行说明以及得到4个自变量,之后进行回归分析,牌赞助, 社会责任感会对购买意愿产生显著的正向影响关系。但是品牌代言人, 品牌活动并不会对购买意愿产生影响关系。并且发现“品牌赞助”对“购买意愿”影响最大。如果在实际分析中可以重点关注下“品牌赞助”指标。
更多干货请登录SPSSAU官方网站查看。

