mmclassification
һ��MMCLS��Ŀ
1.���ú�mmcv��,��GitHub������mmclassification����Ŀ��
2.���configs/resnet/resnet18_8xb16_cifar10.py�ļ�����˵��,8xb16��ʾ8����,ÿ������batch_size�Ĵ�С��16,cifar10��ʾԤѵ��ģ��ʹ�õ����ݼ���
configs\resnet\resnet50_8xb32-mixup_in1k.pymixup��ʾ������ǿ�IJ��ԡ�
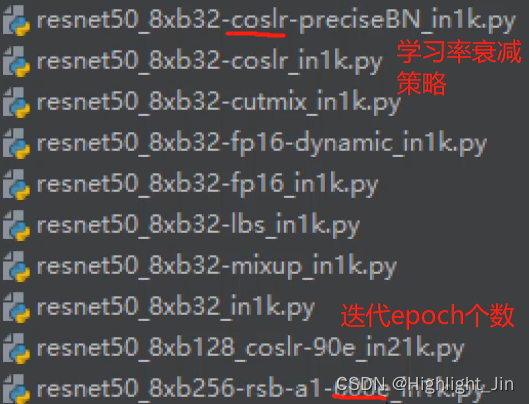
3.configs/resnet/resnet18_8xb16_cifar10.py�����ļ��Ľ���
_base_ = [
'../_base_/models/resnet18.py', '../_base_/datasets/imagenet_bs32.py',
'../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
]
# ����ṹ�Ķ��塢���ݼ��Ķ��塢ѧϰ�IJ���(ѧϰ�ʵ�˥����ѧϰ����)��ģ�ͱ���λ�� ѵ�����̵�һЩ
(1)�鿴../_base_/models/resnet18.py
# model settings
model = dict(
type='ImageClassifier', # ����
backbone=dict(
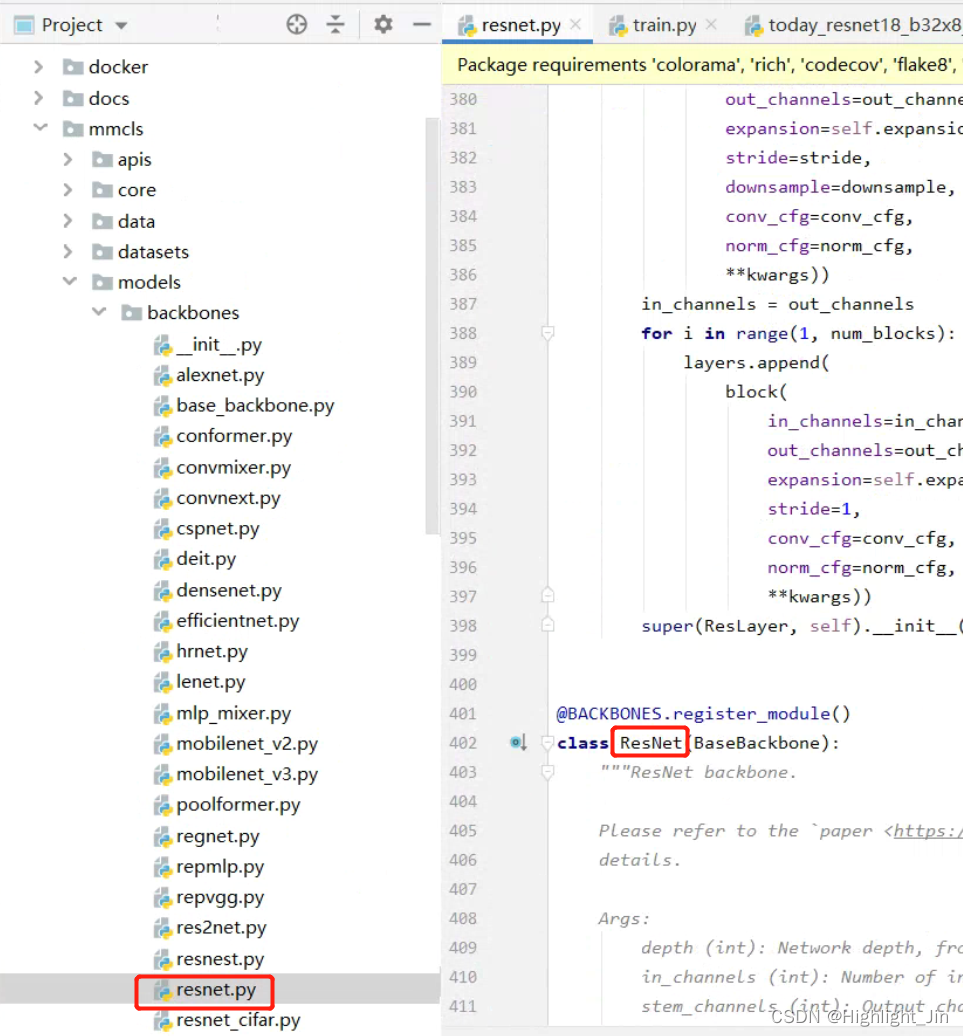
type='ResNet', # ѡȡ��backbone,��models/backbones��ѡ��
depth=18, # �������.
num_stages=4, # stage������
out_indices=(3, ), # ��������������,��0��ʼ
style='pytorch'), # pytorch��caffee
neck=dict(type='GlobalAveragePooling'), # ��backbone��ȡ����������һЩ�ںϲ���
head=dict( # ���
type='LinearClsHead', # FC
num_classes=1000, # ������
in_channels=512, # ����backbone��neck��,��Ҫ��
loss=dict(type='CrossEntropyLoss', loss_weight=1.0), # ��ʧ����
topk=(1, 5), # ������
))
typeָ��Դ��Ȼᵽ��ȥ��,��Ӧһ��һ������,����Ϲд�ġ�����ImageClassifierȥ��ͼ��λ��Ѱ��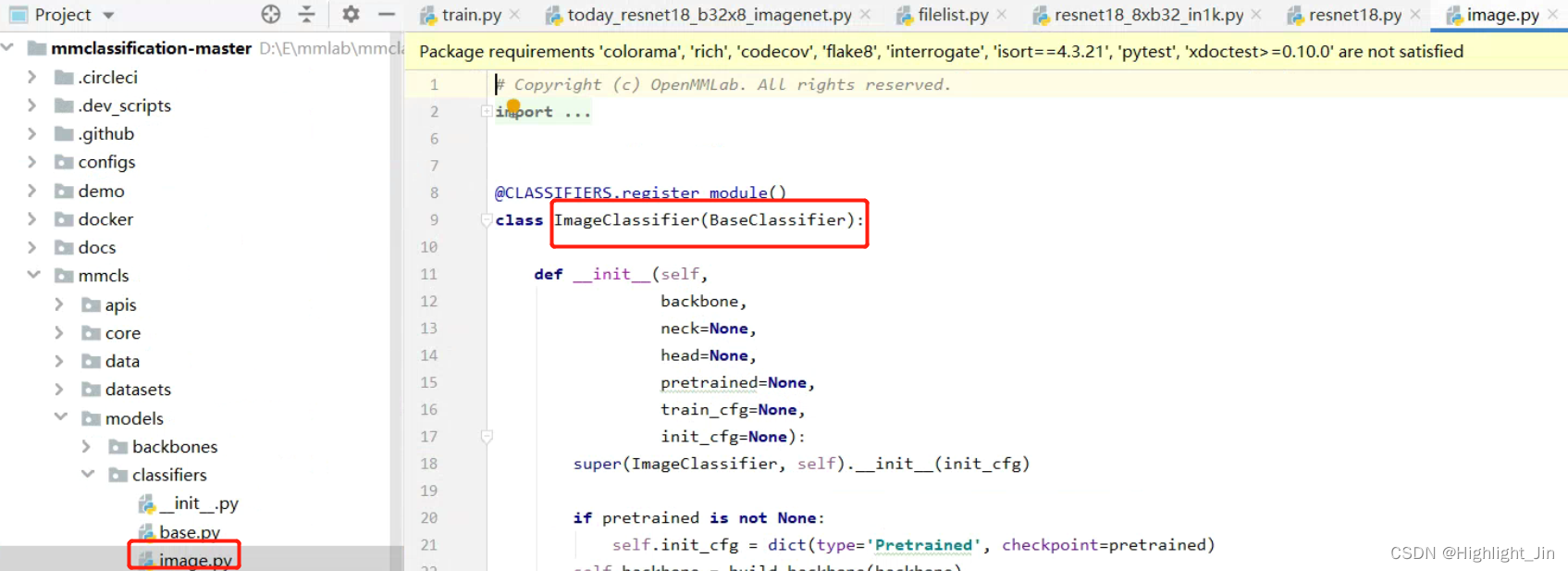
����ResNet����ͼ��λ��Ѱ��
֮�������neck���н�����
(2)�鿴../_base_/datasets/imagenet_bs32.py
# dataset settings
dataset_type = 'ImageNet' # ���������ij��Լ���
img_norm_cfg = dict( # ��һ��,��ֵ������
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'), # ��ͼ������,��Щ������datase_type����
dict(type='RandomResizedCrop', size=224), # ����ü�
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'), # ��ת����
dict(type='Normalize', **img_norm_cfg), # ��һ��
dict(type='ImageToTensor', keys=['img']), # ת����Tensor,��Ҫ��. keys��ʾ��˭������,�����ֵ��dataset_type ����
dict(type='ToTensor', keys=['gt_label']), # ��ǩת����Tensor
dict(type='Collect', keys=['img', 'gt_label']) # ����dataloader,����һ��ͼ��ͱ�ǩ
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data = dict(
samples_per_gpu=32, # ������batchsize;�ÿ�ſ���batchsize
workers_per_gpu=2,
train=dict(
type=dataset_type, # ָ��dataset_type,�����Լ�д֮�����
data_prefix='data/imagenet/train', # �����ݡ��Լ����ݵ�·������ָ����ǩ,���ļ��е����ֵ�����ǩ
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val', # ������
ann_file='data/imagenet/meta/val.txt', # ����ǩ
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='accuracy') # ��������epoch,��һ����֤��,metric������
dataset_type = 'ImageNet' ���ݵĸ�ʽ,��һ����ImageNet,�����Լ�������ѡ����ʵĸ�ʽ���˴�ָ��ImageNet,�Ͱ���mmcls/datasets/imagenet.py�ж���Ľ��ж�ȡ��
samples_per_gpu=32, ������batchsize;�ÿ�ſ���batchsize,���ѵ����������ô�����ᱨ�Դ�,�ǾͰ����´�����size��ֵ��С��
train_pipeline = [
dict(type='LoadImageFromFile'), # ��ͼ������,��Щ������datase_type����
dict(type='RandomResizedCrop', size=224),
(3)�鿴../_base_/schedules/imagenet_bs256.py
# optimizer
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None) # ���ֵ����
# learning policy ѧϰ��˥��
lr_config = dict(policy='step', step=[30, 60, 90]) # �������ٴ�(stepָ��)֮��ʼ˥��
runner = dict(type='EpochBasedRunner', max_epochs=100) # ����epoch�Ĵ���
(4)�鿴../_base_/default_runtime.py
# checkpoint saving
checkpoint_config = dict(interval=1) # ��,�˴���1��epoch���б���
# yapf:disable
log_config = dict(
interval=100, # �������ٴ���,������־����Ϣ
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None # ���ļ���ģ��
resume_from = None # ����һ��epoch�б����checkpoint����ѵ��
workflow = [('train', 1)] # Ĭ��ֵ,����
�������������������ļ�
ָ����ѡģ�͵�·��,��mmclassification��Ŀ¼��,��D:\E\mmlab\mmclassification-master\tools\train.py,ָ��train.py�в�����·��,����D:\E\mmlab\mmclassification-master\configs\resnet\resnet18_8xb32_in1k.py,����һ��train.py,ִ��֮����ڴ˴�D:\E\mmlab\mmclassification-master\tools\work_dirs\resnet18_b32x8_imagenet\resnet18_b32x8_imagenet.py���������ļ������Ƶ�D:\E\mmlab\mmclassification-master\configs\resnet·����,����������Ϊmy_resnet18_b32x8_imagenet.py��
���������ļ��ж������ݼ�
����һ:�����ļ��ж������ݼ�,�˷���������flower_data�����͵�����
(1)����,���������ɵ������ļ��е�num_classes,�˴���flower_data���ݼ�����˵��,һ����102������,����num_classes=102������mmcls/datasets/imagenet.py��CLASSES =[]�����ġ�
(2)��data��data_prefix�ֶ�,�����ݵ�·��,���ʡ�Ե�ann_file,��ֱ�Ӱ��ļ��е����ֵ�����ǩ�����
(3)��checkpoint_config��ֵ,checkpoint_config = dict(interval=50) , ��50������һ��
������:�����Լ������ݼ�
(1)���е�ѵ�����ݼ�����һ���ļ�����,ѵ������train�ļ����¡�
(2)mmcls/datasets���Լ�дһ���ļ�,����imagenet����д,���˼���ôд,�Լ���ôд��
(3)��mmcls/datasets\__init__�а��Լ���������ݼ��������м���,�������¡�
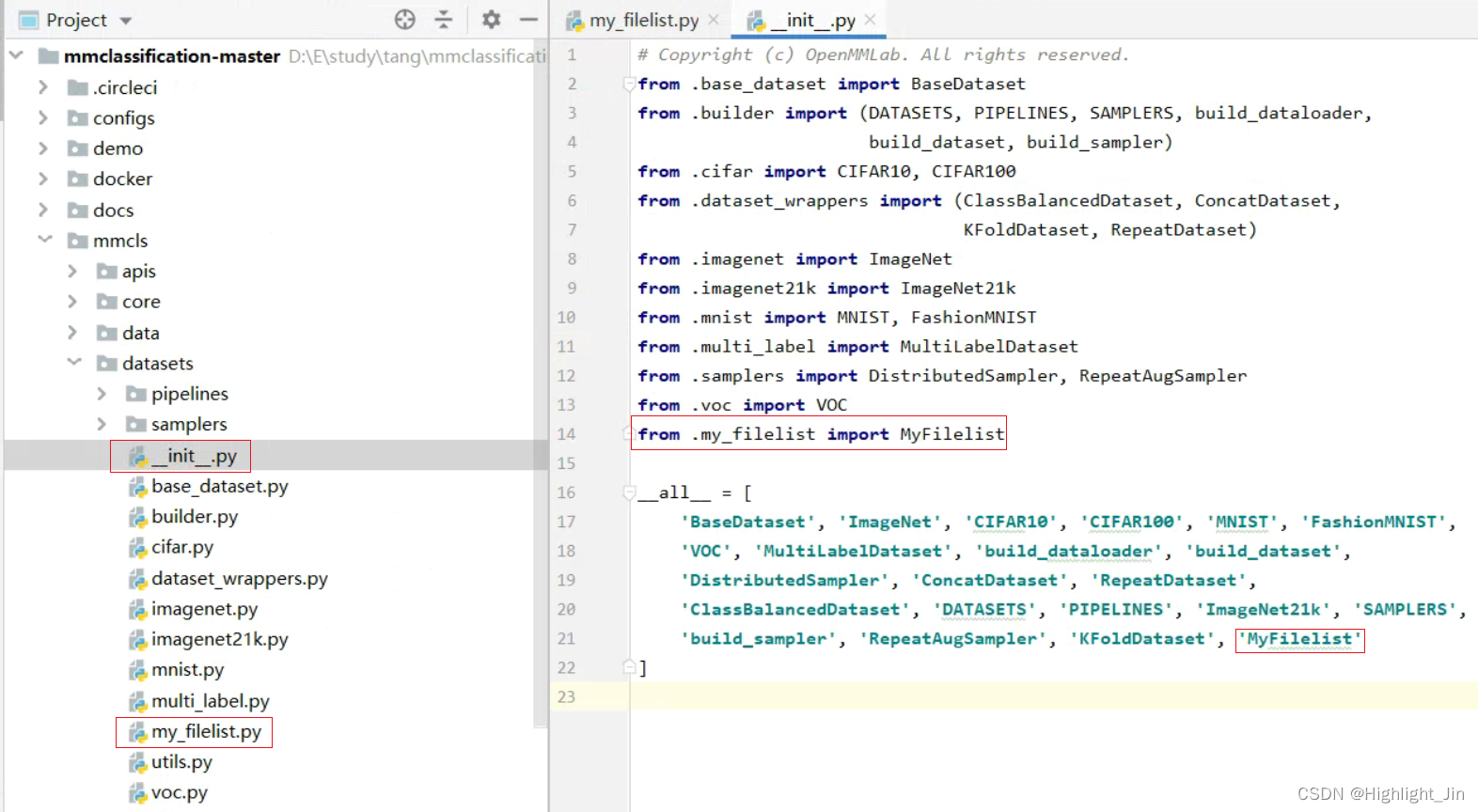
(4)�����ɵ����������ļ��н�����,���ݲ���Ҫ�ij����¸�ʽ,train��valid��test
type='MyFilelist',
data_prefix='D:\\eclipse-workspace\\PyTorch4\\mmclassification-master\\mmcls\\data\\flower_data\\train_filelist',
ann_file='D:\\eclipse-workspace\\PyTorch4\\mmclassification-master\\mmcls\\data\\flower_data\\train.txt',
�ġ�����demo��Ч��
(1)demo/image_demo.py�½��мIJ���
image_05094.jpg ../configs/resnet/today_resnet18_8xb32_in1k.py ../tools/work_dirs/resnet18_8xb32_in1k/epoch_100.pth
ͨ�������зֱ�ָ��img��config��checkpoint,ͨ���������е���ͼƬ�IJ��ԡ�
(2)��������ģ��Ч��:��tools/test.py�ļ��½���
#../configs/resnet/today_resnet18_8xb32_in1k.py ../tools/work_dirs/resnet18_8xb32_in1k/epoch_100.pth --show
#--show-dir ../tools/work_dirs/resnet18_8xb32_in1k/val_result
#--metrics accuracy recall
ͨ��ָ�����ϲ���,�����������ݵIJ��ԡ�
�塢MMCLS������һ���µ�ģ��
�����ɵ����������ļ��н����ġ�
backboneһ�����滻��
1.��Neck��
����Щ���Ի���?��mmcls/models/necks�ط�Ѱ�ҡ�
2.head���е���ʧ����
����Լ����һ����ʧ����,ʾ������:
Ȼ����__init__������
����������ļ��н�����
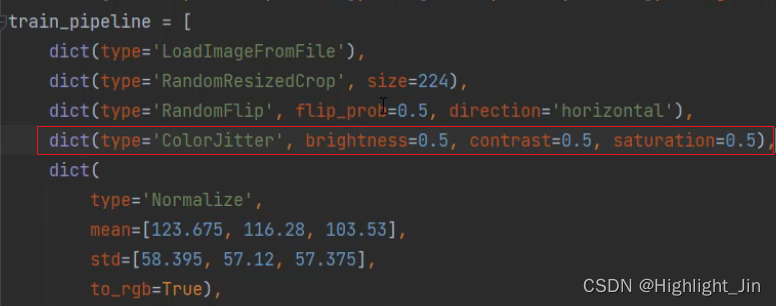
3.����������ǿ
mmcls/datasets/pipelines/transforms.py����һЩ������ǿ�IJ���������һ�����ݴ����IJ���,����:
4.����ָ��Ԥѵ��ģ��,ͨ��load_from����
5.����mixup����
��configs/resnet/resnet50_b32x8_mixup_imagenet.py �ļ��п���
_base_ = 'resnet50_8xb32-mixup_in1k.py'
_deprecation_ = dict(
expected='resnet50_8xb32-mixup_in1k.py',
reference='https://github.com/open-mmlab/mmclassification/pull/508',
)
Ȼ��ȥ_base_ָ�����ļ���,��train_cfg���Ƶ��Լ��������ļ���head����,����num_classes����


����������ǿ���̿��ӻ�չʾ
��tools/visualizations�ļ�����,��һ�����ӻ���ģ�顣��3���ļ�,vis_cam.py��vis_lr.py��vis_pipeline.py��vis_cam.py��������ͼ���й�ע������vis_lr.pyѧϰ�ʵĿ��ӻ��仯��vis_pipeline.pyͼ�������뾭����ת��ƽ�ơ����Ų���,���շŵ�ģ�͵���,���ӻ���һϵ�в�������ô����,������Щ�Ρ�(������ģ��֮ǰ����������Щ����)
(1)vis_pipeline.py�Ľ���
���ò����Ľ���:
config:�����ļ���ָ��
--output-dir:���ͼ�������·��
--phase:ѡ����ӻ������ݼ�train��test��val
--number:ѡ����ӻ�ͼ�������
--mode:չʾ��ģʽ,չʾԭʼͼ��original,����
"original" means show images load from disk'
'; "transformed" means to show images after transformed; "concat" '
'means show images stitched by "original" and "output" images. '
'"pipeline" means show all the intermediate images. Default concat.'
--show:whether to display images in pop-up window. Default False.
--modeָ��pipeline���ʾ��:

--modeָ��transformed���ʾ��:ת����֮��Ľ��ʾ��

--modeָ��concat���ʾ��:

(2)vis_cam.py�Ľ���,Grad-Cam���ӻ�����,���ӻ�ϸ����Ч������
- ������Ҫ��װ
pip install "grad-cam>=1.3.6" - ָ������
img��config��checkpoint��--target-category��ʾThe target category to get CAM��--target-layers����ָ���鿴��һ������ͼ��CAM,Ĭ�������һ��Cthe norm layer in the last block��--preview-model�����������,���ӡ��ģ�͵Ľṹ,����������������� - ָ��������ʾ��
cat-dog.png ../../configs/resnet/resnet18_8xb32_in1k.py D:\\E\\mmlab\\mmclassification-master\\mmcls\\data\\resnet18_8xb32_in1k_20210831-fbbb1da6.pth
--target-category 238 --target-category 281
cat-dog.png ../../configs/resnet/resnet18_8xb32_in1k.py D:\\E\\mmlab\\mmclassification-master\\mmcls\\data\\resnet18_8xb32_in1k_20210831-fbbb1da6.pth
--target-layers backbone.layer2.1.conv2
�ߡ�ģ�ͷ����ű�ʹ��
tools/analysis_tools�л��Ƶ�ͼ�����Ǻܺÿ�:analysis_logslog����һЩָ��,��ӡ����,���Ի�����get_flops.py����IJ������ͼ�����
1.�����������,loss�Ľ��ͼ��
��Ŀ¼������־�ļ�
��������ʾ��:
plot_curve ../work_dirs/resnet18_b32x8_imagenet/20220601_112055.log.json --keys loss accuracy_top-1
2.�������ʱ��
��������ʾ��
cal_train_time ../work_dirs/resnet18_b32x8_imagenet/20220601_112055.log.json
ƽ��һ�ε������軨��ʱ��

3.get_flops.py����IJ������ͼ�����
��������ʾ��:
../../configs/resnet/today_resnet18_b32x8_imagenet.py --shape 224 224
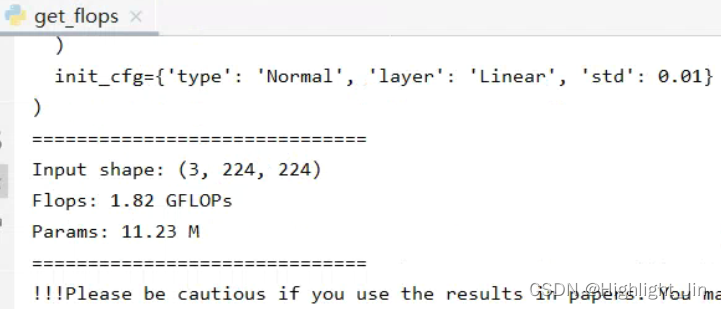
��������ѵ��ѵ��û��ϵ����ģ���Լ�����ͼ��Ĵ�С�йء�

