�Ӿ�SLAM�ܽᡪ��SuperPoint / SuperGlue
�Ӿ�SLAM�ܽᡪ��SuperPoint / SuperGlue
���Ҹտ�ʼ�Ӵ�SLAM�㷨��ʱ��������һ�����н�:��SLAM��ʵ����Ҫ����ǰ��,�������ƥ�������㹻³��,��˾Ϳ��Ա�÷dz���,��ʱ�Լ��ܽ��һƪ��ͳ�Ӿ������IJ����Ӿ�SLAM�ܽᡪ���Ӿ�����������,���ڵ�ʱ�����ѧϰ�˽ⲻ��,��˲�û�к��ǻ������ѧϰ���Ӿ�����ƥ�䷽��,��ʵ����,�������ѧϰ������ƥ��Ч��ҪԶ���ڴ�ͳ�����������ͽ��������2018�������SuperPoint��2020�������SuperGlue��ƪ��Ϊ��������ѧϰ�㷨����ѧϰ�ܽᡣ
1. SuperPoint
SuperPoint������2018��,ԭ������Ϊ��SuperPoint: Self-Supervised Interest Point Detection and Description
��,�÷���ʹ���ල�ķ�ʽѵ����һ��������ȡͼ�������Լ����������ӵ����硣
1.1 ����ṹ
SuperPoint������ṹ����ͼ��ʾ:

����֪��,ͼ������ͨ������������,�������Ѿ�����������,��ͼ��������֧���ֱ�������ȡ����������������ӡ���������ʹ����VGG-Style��Encoder���ڽ���ͼ��ߴ���ȡ����,Encoder�����ɾ����㡢Max-Pooling��ͷ����Լ�������,ͨ������Max-Pooling�㽫ͼ��ߴ��Ϊ�����
1
/
8
1/8
1/8,��������:
# Shared Encoder
x = self.relu(self.conv1a(data['image']))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x)) # x���������(N,128,W/8, H/8)
������������ȡ����,��·�Ƚ�ά�� ( W / 8 , H / 8 , 128 ) (W/8, H/8, 128) (W/8,H/8,128)����������Ϊ ( W / 8 , H / 8 , 65 ) (W/8, H/8, 65) (W/8,H/8,65)��С,����� 65 65 65�ĺ���������ͼ��ÿһ�����ر�ʾԭͼ 8 �� 8 8\times8 8��8�ľֲ��������һ�����ֲ�������������ʱ���������Dustbinͨ��,ͨ��Softmax�Լ�Reshape�IJ���,����������ָ�Ϊԭͼ��С,��������:
# Compute the dense keypoint scores
cPa = self.relu(self.convPa(x)) # x����(N,128,W/8, H/8)
scores = self.convPb(cPa) # scores����(N,65,W/8, H/8)
scores = torch.nn.functional.softmax(scores, 1)[:, :-1] # scores����(N,64,W/8, H/8)
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8) # scores����(N,W/8, H/8, 8, 8)
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8) # scores����(N,W/8, H/8)
scores = simple_nms(scores, self.config['nms_radius'])
����ָ��ע������������ȶ���Dustbinͨ��������ͼ����Softmax�������ٽ���Slice�ġ�����û��Dustbinͨ��,�� 8 �� 8 8\times8 8��8�ľֲ�������û��������ʱ,����Softmax��64ά�������Ʊػ��ǻ���һ����Խϴ��ֵ���,������Dustbinͨ����Ϳ��Ա����������,�����Ҫ��Softmax�������ٽ���Slice������پ���NMS����Ӧ�ϴ��λ�ü�Ϊ����������㡣
����������������ȡ����,�����Ƚ�ά�� ( W / 8 , H / 8 , 128 ) (W/8, H/8, 128) (W/8,H/8,128)����������Ϊ ( W / 8 , H / 8 , 256 ) (W/8, H/8, 256) (W/8,H/8,256)��С,���� 256 256 256�������Ǽ��������������ά�ȡ�����ͨ�����й�һ��������������λ��ͨ��˫���Բ�ֵ�õ�����������
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa) # descriptor������(N,256,8,8)
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1) # ��ͨ�����й�һ��
# Extract descriptors
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]
����˫���Բ�ֵ��صIJ�����sample_descriptors��,�ú�������:
def sample_descriptors(keypoints, descriptors, s: int = 8):
""" Interpolate descriptors at keypoint locations """
b, c, h, w = descriptors.shape
keypoints = keypoints - s / 2 + 0.5
keypoints /= torch.tensor([(w*s - s/2 - 0.5), (h*s - s/2 - 0.5)],
).to(keypoints)[None]
# ����*s��ԭ����keypoints��(W,H)����ͼ����ȡ��,��descriptorĿǰ����(W/s,H/s)������ͼ����ȡ��
keypoints = keypoints*2 - 1 # normalize to (-1, 1)
args = {'align_corners': True} if torch.__version__ >= '1.3' else {}
descriptors = torch.nn.functional.grid_sample(
descriptors, keypoints.view(b, 1, -1, 2), mode='bilinear', **args) # ˫���Բ�ֵ
descriptors = torch.nn.functional.normalize(
descriptors.reshape(b, c, -1), p=2, dim=1)
return descriptors
���Ͼ������SuperPointǰ���������������������ȡ����,����������������������ѵ����?
1.2 ��ʧ����
�������ǿ��»����������������������ν�����ʧ������,��ʧ������ʽ����: L ( X , X �� , D , D �� ; Y , Y �� , S ) = L p ( X , Y ) + L p ( X �� , Y �� ) + �� L d ( D , D �� , S ) \mathcal{L}\left(\mathcal{X}, \mathcal{X}^{\prime}, \mathcal{D}, \mathcal{D}^{\prime} ; Y, Y^{\prime}, S\right)=\mathcal{L}_{p}(\mathcal{X}, Y)+\mathcal{L}_{p}\left(\mathcal{X}^{\prime}, Y^{\prime}\right)+\lambda \mathcal{L}_{d}\left(\mathcal{D}, \mathcal{D}^{\prime}, S\right) L(X,X��,D,D��;Y,Y��,S)=Lp?(X,Y)+Lp?(X��,Y��)+��Ld?(D,D��,S)���� L p \mathcal{L}_{p} Lp?Ϊ��������ص���ʧ, L d \mathcal{L}_{d} Ld?Ϊ����������ص���ʧ,���� X \mathcal{X} X�� Y Y Y�� D \mathcal{D} D�ֱ�Ϊͼ����ͨ��������ȡ�������㡢�������������������ֵ��
�����������ʧ L p \mathcal{L}_{p} Lp?����Ϊһ����������ʧ: L p ( X , Y ) = 1 H c W c �� h = 1 w = 1 H c , W c l p ( x h w ; y h w ) \mathcal{L}_{p}(\mathcal{X}, Y)=\frac{1}{H_{c} W_{c}} \sum_{{h=1 \\ w=1}}^{H_{c}, W_{c}} l_{p}\left(\mathbf{x}_{h w} ; y_{h w}\right) Lp?(X,Y)=Hc?Wc?1?h=1w=1��Hc?,Wc??lp?(xhw?;yhw?)���� l p ( x h w ; y h w ) = ? log ? ( exp ? ( x h w y ) �� k = 1 65 exp ? ( x h w k ) ) l_{p}\left(\mathbf{x}_{h w} ; y_{h w}\right)=-\log \left(\frac{\exp \left(\mathbf{x}_{h w y}\right)}{\sum_{k=1}^{65} \exp \left(\mathbf{x}_{h w k}\right)}\right) lp?(xhw?;yhw?)=?log(��k=165?exp(xhwk?)exp(xhwy?)?)���� H c = H / 8 H_{c}=H/8 Hc?=H/8, W c = W / 8 W_{c}=W/8 Wc?=W/8; y h w y_{h w} yhw?Ϊ��ֵ,�� 8 �� 8 8\times8 8��8�ķ������ĸ�PixelΪ������; x h w \mathbf{x}_{h w} xhw?��һ������Ϊ 65 65 65����������,������ÿһ����ֵ������Ӧ��Pixel�����������Ӧֵ��
�������������ʧ L d \mathcal{L}_{d} Ld?����Ϊһ����ҳ��ʧ(Hinge-Loss,��SVM�㷨���õ�): L d ( D , D �� , S ) = 1 ( H c W c ) 2 �� h = 1 w = 1 H c , W c �� h �� = 1 w �� = 1 H c , W c l d ( d h w , d h �� w �� �� ; s h w h �� w �� ) \mathcal{L}_{d}\left(\mathcal{D}, \mathcal{D}^{\prime}, S\right)=\frac{1}{\left(H_{c} W_{c}\right)^{2}} \sum_{{h=1 \\ w=1}}^{H_{c}, W_{c}} \sum_{{h^{\prime}=1 \\ w^{\prime}=1}}^{H_{c}, W_{c}} l_{d}\left(\mathbf{d}_{h w}, \mathbf{d}_{h^{\prime} w^{\prime}}^{\prime} ; s_{h w h^{\prime} w^{\prime}}\right) Ld?(D,D��,S)=(Hc?Wc?)21?h=1w=1��Hc?,Wc??h��=1w��=1��Hc?,Wc??ld?(dhw?,dh��w����?;shwh��w��?)���� l d ( d , d �� ; s ) = �� d ? s ? max ? ( 0 , m p ? d T d �� ) + ( 1 ? s ) ? max ? ( 0 , d T d �� ? m n ) l_{d}\left(\mathbf{d}, \mathbf{d}^{\prime} ; s\right)=\lambda_{d} * s * \max \left(0, m_{p}-\mathbf{d}^{T} \mathbf{d}^{\prime}\right)+(1-s) * \max \left(0, \mathbf{d}^{T} \mathbf{d}^{\prime}-m_{n}\right) ld?(d,d��;s)=��d??s?max(0,mp??dTd��)+(1?s)?max(0,dTd��?mn?)���� �� d \lambda_{d} ��d?Ϊ�����Ȩ��, s h w h �� w �� s_{h w h^{\prime} w^{\prime}} shwh��w��?Ϊ�ж���ͨ����Ӧ��������жϷ�Ϊͬһ��������ĺ���: s h w h �� w �� = { 1 , ?if? �� H p h w ^ ? p h �� w �� �� �� 8 0 , ?otherwise? s_{h w h^{\prime} w^{\prime}}= \begin{cases}1, & \text { if }\left\|\widehat{\mathcal{H} \mathbf{p}_{h w}}-\mathbf{p}_{h^{\prime} w^{\prime}}\right\| \leq 8 \\ 0, & \text { otherwise }\end{cases} shwh��w��?={1,0,??if?������?Hphw? ??ph��w��?������?��8?otherwise??���� p \mathbf{p} pΪ 8 �� 8 8\times8 8��8�ķ�������ĵ�,�� H p h w ^ \widehat{\mathcal{H} \mathbf{p}_{h w}} Hphw? ?�� p h �� w �� \mathbf{p}_{h^{\prime} w^{\prime}} ph��w��?����С��8������ʱ��Ϊƥ��ɹ�,һ���Ÿ���Ӧ����ʵ��һ�������㡣���������������º�ҳ��ʧ,��ƥ��ɹ�ʱ,�����ƶ� d T d �� \mathbf{d}^{T} \mathbf{d}^{\prime} dTd��������������ֵ m p m_{p} mp?ʱ����гͷ�;��ƥ��ʧ��ʱ,�����ƶ� d T d �� \mathbf{d}^{T} \mathbf{d}^{\prime} dTd��С�ڸ�������ֵ m p m_{p} mp?ʱ����гͷ�������������ʧ����������,��ƥ��ɹ�ʱ,���ƶȾ�Ӧ�úܴ�,ƥ��ʧ��ʱ,���ƶȾ�Ӧ�ú�С��
1.3 �Լලѵ������
���Ͼ�����·��ʧ��������ض���,��SuperPoint�����к���Ҫ��һ���־��Dz��ලѵ��,�������������������������ʵ�ලѵ���ġ�����ѵ��һ����Ϊ���¼�����:
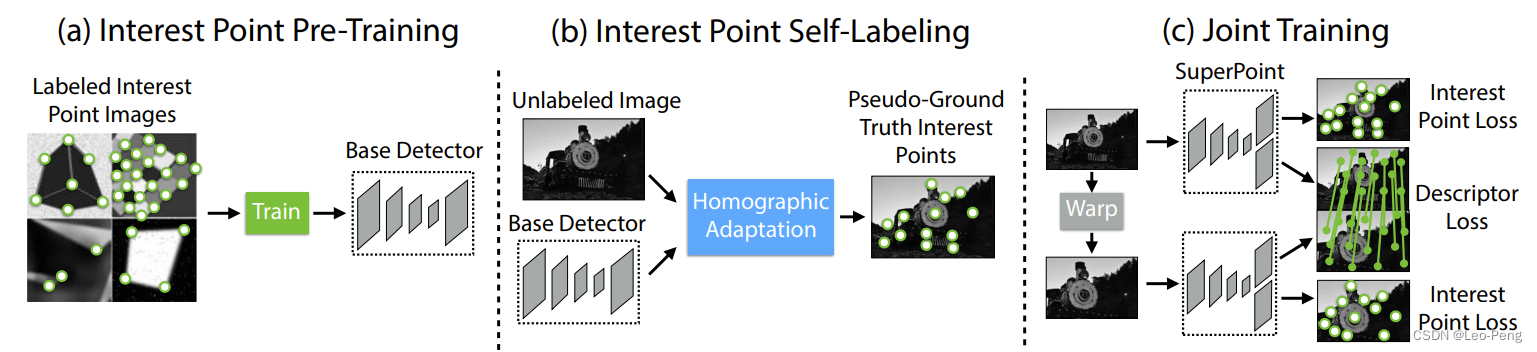
��һ����������ͼ��ʾ��Synthetic Shapes Dataset�Ͻ���Ԥѵ��,ѵ���Ľ����ΪMagicPoint����Ȼ���ںϳɵ����ݼ��Ͻ���ѵ����,�����������ᵽMagicPoint��Corner-Like Structure����ʵ����Ҳ�߱�һ���ķ�������,����Ը����ձ�ij���,MagicPoint��Ч���ͻ��½�,Ϊ�����������˵ڶ���,��Homographic Adaption��

�ڶ�����Homographic Adaption����������ͼ��ʾ:

���Ǽ���
f
��
(
?
)
f_{\theta}(\cdot)
f��?(?)ΪMagicPoint�ļ��ģ��,
I
I
IΪ����ͼ��,
X
\mathbf{X}
XΪMagicPoint����������,
H
\mathcal{H}
HΪ����ĵ�Ӧ��������������:
x
=
f
��
(
I
)
\mathbf{x}=f_{\theta}(I)
x=f��?(I)���Ƕ�ͼ����е�Ӧ�任,������������㷨�߱���Ӧ������(��Ҳ������ϣ���߱���),��ô��Ӧ���������¹�ʽ:
H
x
=
f
��
(
H
(
I
)
)
\mathcal{H} \mathbf{x}=f_{\theta}(\mathcal{H}(I))
Hx=f��?(H(I))�Թ�ʽ���б任:
x
=
H
?
1
f
��
(
H
(
I
)
)
\mathbf{x}=\mathcal{H}^{-1} f_{\theta}(\mathcal{H}(I))
x=H?1f��?(H(I))Ȼ��Ŷ���Dz��������ܶ�������Ӧ����Ϳ��Եõ��㹻��ľ߱���Ӧ�����Ե����������ֵ:
F
^
(
I
;
f
��
)
=
1
N
h
��
i
=
1
N
h
H
i
?
1
f
��
(
H
i
(
I
)
)
\hat{F}\left(I ; f_{\theta}\right)=\frac{1}{N_{h}} \sum_{i=1}^{N_{h}} \mathcal{H}_{i}^{-1} f_{\theta}\left(\mathcal{H}_{i}(I)\right)
F^(I;f��?)=Nh?1?i=1��Nh??Hi?1?f��?(Hi?(I))
���������Ǹ���ǰ���ṩ����ʧ�������е���ѵ����
���Ͼ����SuperPoint�㷨�Ļ���ԭ������,��Ч������: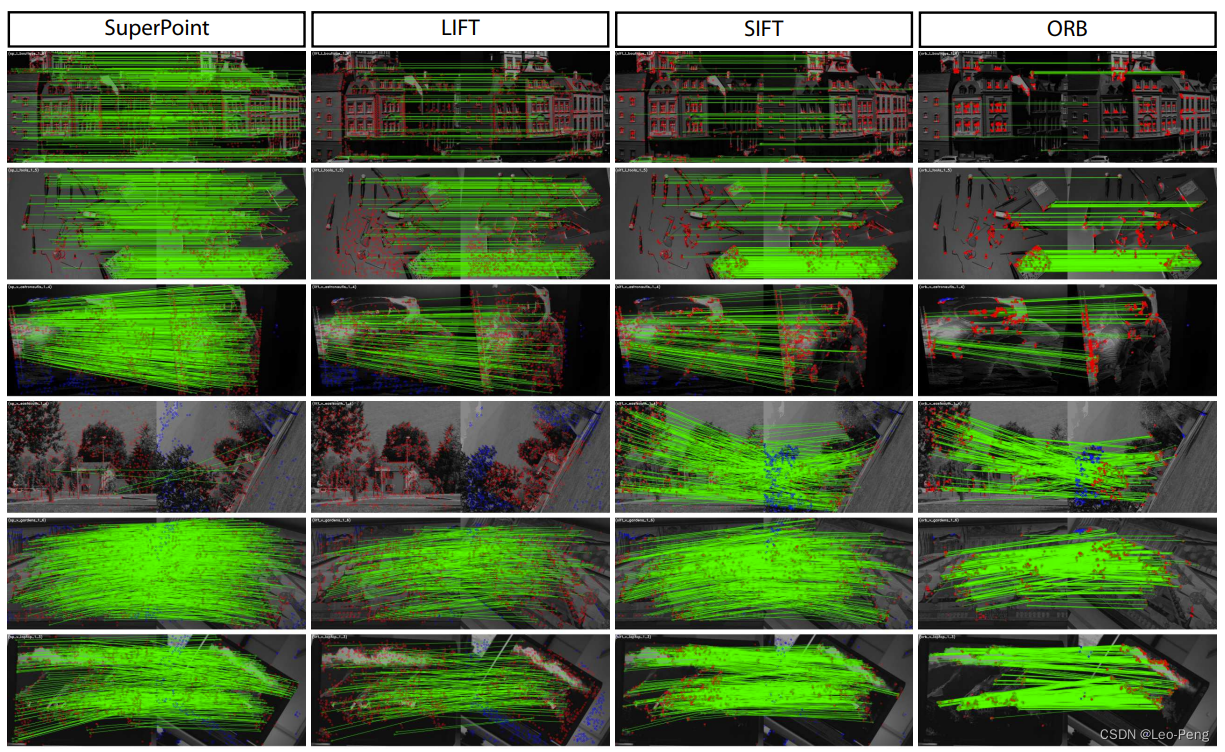
���ǿ��Կ���������SuperPoint�ı�����ʵ�ܲ�,����֪����Ӧ�仯������ǰ�������dz����д���ƽ��,�������еij�������Ȼ��̫������������,���Ч��Ҳ��Ƚϲ�,��Ҳ������SuperPoint���Լලѵ���µ�һЩ����֮����
2. SuperGlue
SupreGlue������2020��,ԭ������Ϊ��SuperGlue: Learning Feature Matching with Graph Neural Networks��,������������Transformerʵ����һ��2D������ƥ�䷽��������֪��,�ھ����SLAM�����,ǰ�˽���������ȡ,��˽��з������Ż�,���м�dz���Ҫ��һ����������ƥ��,��ͳ������ƥ��ͨ���ǽ������ڡ�RASANC��һЩ�㷨���д���,SuperGlue���Ƴ���SLAM�㷨����˵������ѧϰ��һ����Ҫ��̱����������������������漰��Transformer�����֪ʶ,���ⲿ��֪ʶ����Ϥ��ͬѧ���Բο���������Ӿ��㷨����Transformerѧϰ�ʼ���
2.1 Sinkhorn�㷨
SuperGlue�����и������㷨Pipeline����ͼ��ʾ:
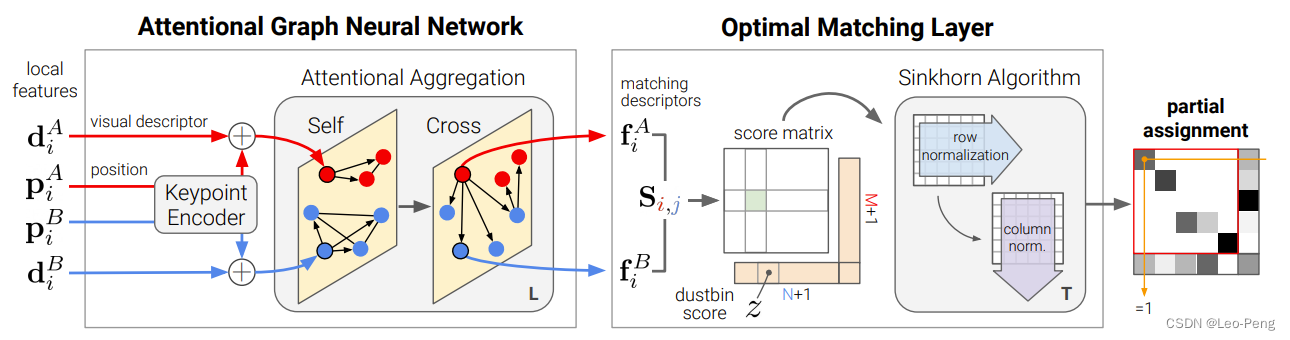
���㷨Pipeline���Կ���,�㷨ͨ��Attentional Graph Neural Network���һ��Score Matrix,��Optimal Matching Layer��ʹ��Sinkhorn Algorithm�õ����յ�ƥ����,��������������������Score Matrix��ʲô,������������εõ����Score Matrix,Ҫ�����Score Matrix�ĺ���,���Ǿ͵����˽�Sinkhorn Algorithm�Ļ���ԭ����
Sinkhorn Algorithm����������д�������,������������С���۽�һ���ֲ�ת��Ϊ��һ���ֲ�������,�������Dzο�����Notes on Optimal Transport�е�һ��������˵�����㷨:
�����е�ˮ������ͷ������±���ʾ:
| ˮ����� | ƻ�� | ���� |
|---|---|---|
| ���� | 2 | 1 |
��ͥ��Ա��ˮ�������������±���ʾ:
| ��ͥ��Ա | СA | СB | СC |
|---|---|---|---|
| �������� | 1 | 1 | 1 |
Ȼ���Ŷӳ�Ա��ͬ��ͥ��Ա�Բ���ˮ����ϲ�ó̶Ȼ���һ��,���±���ʾ:
| СA | СB | СC | |
|---|---|---|---|
| ƻ�� | 0 | 1 | 2 |
| ���� | 2 | 0 | 1 |
��ô������������ˮ������ʹ������������?������ǽ��������һ������ͼ����Ļ�,��ô����ʹ��������ƥ�����KM�㷨���,���Ƕ���ͼ����Ҫ������Dz����ֵ�,Ҳ����˵ˮ���Dz������п��ġ�����Sinkhorn Algorithm������ǿ�������,Ҳ�����������Ƿ�ˮ����ʱ����Խ�ˮ���п��֡�
��������ͨ����ʽ�����������,���Ƕ����ͥ��Ա��ˮ��������Ϊ
c
=
(
1
,
1
,
1
)
?
\mathbf{c}=(1,1,1)^{\top}
c=(1,1,1)?,ˮ���������ֲ�Ϊ
r
=
(
2
,
1
)
?
\mathbf{r}=(2,1)^{\top}
r=(2,1)?,���������Ƕ���������
U
(
r
,
c
)
U(\mathbf{r}, \mathbf{c})
U(r,c)Ϊ
U
(
r
,
c
)
=
{
P
��
R
>
0
n
��
m
�O
P
1
m
=
r
,
P
?
1
n
=
c
}
U(\mathbf{r}, \mathbf{c})=\left\{P \in \mathbb{R}_{>0}^{n \times m} \mid P \mathbf{1}_{m}=\mathbf{r}, P^{\top} \mathbf{1}_{n}=\mathbf{c}\right\}
U(r,c)={P��R>0n��m?�OP1m?=r,P?1n?=c}
U
(
r
,
c
)
U(\mathbf{r}, \mathbf{c})
U(r,c)���������з���Ŀ�����,���������Ǹ����Ŷӳ�Ա�����Ķ�����ʧ����
M
M
M,������ѵķ��䷽��Ӧ������
d
M
(
r
,
c
)
=
min
?
P
��
U
(
r
,
c
)
��
i
,
j
P
i
j
M
i
j
d_{M}(\mathbf{r}, \mathbf{c})=\min _{P \in U(\mathbf{r}, \mathbf{c})} \sum_{i, j} P_{i j} M_{i j}
dM?(r,c)=P��U(r,c)min?i,j��?Pij?Mij?ע�����ﲻ�Ǿ������,������������������ӡ�ʹ��Sinkhorn Algorithm���������������ʵ�dz���,����ͼ��ʾ:
 ���ȸ�����ʧ����
M
M
M����һ���������
P
��
=
e
?
��
M
P_{\lambda}=e^{-\lambda M}
P��?=e?��M,Ȼ����е�������,ÿ�ε����Ƚ�ÿһ�е�ֵ���й�һ�������
r
\mathbf{r}
r,Ҳ����ʹ�÷������������е�ֵ����������Ϊ
r
\mathbf{r}
r,������б�ʾƻ���ķ������,��ô
r
=
2
\mathbf{r}=2
r=2��ͬ��,��ÿ�н��й�һ�������
C
\mathbf{C}
C,��˵���ֱ������,������ķ�����������������ŷ���������д��һ���dz��IJ��Գ�������:
���ȸ�����ʧ����
M
M
M����һ���������
P
��
=
e
?
��
M
P_{\lambda}=e^{-\lambda M}
P��?=e?��M,Ȼ����е�������,ÿ�ε����Ƚ�ÿһ�е�ֵ���й�һ�������
r
\mathbf{r}
r,Ҳ����ʹ�÷������������е�ֵ����������Ϊ
r
\mathbf{r}
r,������б�ʾƻ���ķ������,��ô
r
=
2
\mathbf{r}=2
r=2��ͬ��,��ÿ�н��й�һ�������
C
\mathbf{C}
C,��˵���ֱ������,������ķ�����������������ŷ���������д��һ���dz��IJ��Գ�������:
import numpy as np
cost = np.array([[0,1,2],[2,0,1]], dtype=np.float)
row_weight = np.array([2,1])
col_weight = np.array([1,1,1])
for _ in range(100):
cost = cost / np.sum(cost, axis=1).reshape(2, -1) * row_weight.reshape(2, -1)
print(cost)
cost = cost / np.sum(cost, axis=0).reshape(-1, 3) * col_weight.reshape(-1, 3)
print(cost)
�������Ľ��Ϊ:
[[0. 1. 0.99340351]
[1. 0. 0.00659649]]
�ܺ�����,�㷨��ƻ���ָ��˸�ϲ����СB��СC,��СA�õ��������������,����㷨������ʵ�dz���,����Ϊʲô���������ܵõ�����?ʲô����»����?��Щ��������ʱû��Ͷ��̫��ʱ��ȥ�����˽�,֮����ʱ���ٲ��ϡ�
2.2 ����ṹ
�������ǽ�ϴ���һ��һ������SuperGlue������Pipeline�������õ�Score���� S \mathbf{S} S�Լ�SuperGlue�㷨����ڵ�������������ʵ�ֵ�һЩTrick:
�ٶ��� A �� B A��B A��B����ͼ��,�ֱ���� M M M�� N N N��������,�ֱ��Ϊ A : = { 1 , �� , M } \mathcal{A}:=\{1, \ldots, M\} A:={1,��,M}�� B : = { 1 , �� , N } \mathcal{B}:=\{1, \ldots, N\} B:={1,��,N},ÿ���������� ( p , d ) (\mathbf{p}, \mathbf{d}) (p,d)��ʾ,���� p i : = ( x , y , c ) i \mathbf{p}_{i}:=(x, y, c)_{i} pi?:=(x,y,c)i?Ϊ�� i i i���������(��һ�����)λ�ú����Ŷ�, d i �� R D \mathbf{d}_{i} \in \mathbb{R}^{D} di?��RDΪ�� i i i��������������������������ȶ����������������������������б���: ( 0 ) x i = d i + M L P e n c ( p i ) { }^{(0)} \mathbf{x}_{i}=\mathbf{d}_{i}+\mathbf{M L P}_{\mathrm{enc}}\left(\mathbf{p}_{i}\right) (0)xi?=di?+MLPenc?(pi?)�����þ����������λ�ú��������������ͬһ������ ( 0 ) x i { }^{(0)} \mathbf{x}_{i} (0)xi?,ʹ������������ƥ��ʱ�ܹ�ͬʱ���ǵ�����������λ�õ�������,�˽�Transformer��ͬѧӦ���뵽����ʵ����Transformer���ձ��õ�Positional Encoding���ڴ����������������:
self.kenc = KeypointEncoder(self.descriptor_dim, self.keypoint_encoder)
desc0 = desc0 + self.kenc(kpts0, data['scores0'])
desc1 = desc1 + self.kenc(kpts1, data['scores1'])
class KeypointEncoder(torch.jit.ScriptModule):
""" Joint encoding of visual appearance and location using MLPs"""
def __init__(self, feature_dim, layers):
super().__init__()
self.encoder = MLP([3] + layers + [feature_dim])
nn.init.constant_(self.encoder[-1].bias, 0.0)
@torch.jit.script_method
def forward(self, kpts, scores):
inputs = [kpts.transpose(1, 2), scores.unsqueeze(1)] # ע�����ォScoreҲConcatenate������
return self.encoder(torch.cat(inputs, dim=1))
def MLP(channels: list, do_bn=True):
""" Multi-layer perceptron """
n = len(channels)
layers = []
for i in range(1, n):
layers.append(
nn.Conv1d(channels[i - 1], channels[i], kernel_size=1, bias=True))
if i < (n-1):
if do_bn:
layers.append(nn.BatchNorm1d(channels[i]))
layers.append(nn.ReLU())
return nn.Sequential(*layers)
���������Ǿ��ǽ����� ( 0 ) x i { }^{(0)} \mathbf{x}_{i} (0)xi?�����Attention Graph Neural Network,���������ﶨ��������Graph,�ֱ������������� i i i��ͬһ��ͼ���ڵ�����������������ͼ E self? \mathcal{E}_{\text {self }} Eself??�Լ����������� i i i����һ��ͼ���ڵ�������������ͼ E cross? \mathcal{E}_{\text {cross }} Ecross??������ͨ��Transformer���������� i i i��ͼ E \mathcal{E} E����Ϣ m E �� i \mathbf{m}_{\mathcal{E} \rightarrow i} mE��i?,�������Ϣ����ԭ������"message"��ֱ��,��������Ϊͨ��Transformer��ȡ����������Ϣ m E �� i \mathbf{m}_{\mathcal{E} \rightarrow i} mE��i?�����������: m E �� i = �� j : ( i , j ) �� E �� i j v j \mathbf{m}_{\mathcal{E} \rightarrow i}=\sum_{j:(i, j) \in \mathcal{E}} \alpha_{i j} \mathbf{v}_{j} mE��i?=j:(i,j)��E��?��ij?vj? �� i j = Softmax ? j ( q i k j ) \alpha_{i j}=\operatorname{Softmax}_{j}\left(\mathbf{q}_{i} \mathbf{k}_{j}\right) ��ij?=Softmaxj?(qi?kj?)����, v j \mathbf{v}_{j} vj?�� q i \mathbf{q}_{i} qi?�� k j \mathbf{k}_{j} kj?�ֱ�Ϊvalue��query��key,�����������: q i = W 1 ( ? ) x i Q + b 1 \mathbf{q}_{i}=\mathbf{W}_{1}{ }^{(\ell)} \mathbf{x}_{i}^{Q}+\mathbf{b}_{1} qi?=W1?(?)xiQ?+b1? [ k j v j ] = [ W 2 W 3 ] ( ? ) x j S + [ b 2 b 3 ] \left[\begin{array}{l} \mathbf{k}_{j} \\ \mathbf{v}_{j} \end{array}\right]=\left[\begin{array}{l} \mathbf{W}_{2} \\ \mathbf{W}_{3} \end{array}\right]{ }^{(\ell)} \mathbf{x}_{j}^{S}+\left[\begin{array}{l} \mathbf{b}_{2} \\ \mathbf{b}_{3} \end{array}\right] [kj?vj??]=[W2?W3??](?)xjS?+[b2?b3??]��������:
self.attn = MultiHeadedAttention(num_heads, feature_dim)
message = self.attn(x, source, source)
class MultiHeadedAttention(torch.jit.ScriptModule):
""" Multi-head attention to increase model expressivitiy """
prob: List[torch.Tensor]
def __init__(self, num_heads: int, d_model: int):
super().__init__()
assert d_model % num_heads == 0
self.dim = d_model // num_heads
self.num_heads = num_heads
self.merge = nn.Conv1d(d_model, d_model, kernel_size=1)
self.proj = nn.ModuleList([deepcopy(self.merge) for _ in range(3)]) # ��Ӧ��ͬ��W
self.prob = []
@torch.jit.script_method
def forward(self, query, key, value):
batch_dim = query.size(0)
query, key, value = [l(x).view(batch_dim, self.dim, self.num_heads, -1)
for l, x in zip(self.proj, (query, key, value))] # ͨ��������ȡquery��key��value
x, prob = attention(query, key, value) # ����attention����
self.prob.append(prob)
return self.merge(x.contiguous().view(batch_dim, self.dim*self.num_heads, -1)) # �ϲ���ͷ���
def attention(query, key, value):
dim = query.shape[1]
scores = torch.einsum('bdhn,bdhm->bhnm', query, key) / dim**.5
prob = torch.nn.functional.softmax(scores, dim=-1)
return torch.einsum('bhnm,bdhm->bdhn', prob, value), prob
�õ���Ϣ m E �� i \mathbf{m}_{\mathcal{E} \rightarrow i} mE��i?��,���ǽ�һ����������: ( ? + 1 ) x i A = ( ? ) x i A + MLP ? ( [ ( ? ) x i A �� m E �� i ] ) { }^{(\ell+1)} \mathbf{x}_{i}^{A}={ }^{(\ell)} \mathbf{x}_{i}^{A}+\operatorname{MLP}\left(\left[(\ell) \mathbf{x}_{i}^{A} \| \mathbf{m}_{\mathcal{E} \rightarrow i}\right]\right) (?+1)xiA?=(?)xiA?+MLP([(?)xiA?��mE��i?])���� ( ? ) x i A { }^{(\ell)} \mathbf{x}_{i}^{A} (?)xiA?Ϊ�� l l l ��ͼ�� A A A�������� i i i��Ӧ������, [ ? �� ? ] [\cdot \| \cdot] [?��?]��ʾ��Concatenate����,ֵ��ע�����,�� l l l ΪΪ����ʱ����� E self? \mathcal{E}_{\text {self }} Eself??����Ϣ,�� l l l Ϊż��ʱ������� E cross? \mathcal{E}_{\text {cross }} Ecross??����Ϣ���ⲿ�ִ���������ʾ:
desc0, desc1 = self.gnn(desc0, desc1)
self.gnn = AttentionalGNN(self.descriptor_dim, self.GNN_layers)
class AttentionalGNN(torch.jit.ScriptModule):
def __init__(self, feature_dim: int, layer_names: list):
super().__init__()
self.layers = nn.ModuleList([
AttentionalPropagation(feature_dim, 4)
for _ in range(len(layer_names))])
self.names = layer_names
@torch.jit.script_method
def forward(self, desc0, desc1):
for i, layer in enumerate(self.layers):
layer.attn.prob = []
if self.names[i] == 'cross':
src0, src1 = desc1, desc0
else: # if name == 'self':
src0, src1 = desc0, desc1
delta0, delta1 = layer(desc0, src0), layer(desc1, src1)
desc0, desc1 = (desc0 + delta0), (desc1 + delta1) # �����൱��residual���
return desc0, desc1
class AttentionalPropagation(torch.jit.ScriptModule):
def __init__(self, feature_dim: int, num_heads: int):
super().__init__()
self.attn = MultiHeadedAttention(num_heads, feature_dim)
self.mlp = MLP([feature_dim*2, feature_dim*2, feature_dim])
nn.init.constant_(self.mlp[-1].bias, 0.0)
@torch.jit.script_method
def forward(self, x, source):
message = self.attn(x, source, source)
return self.mlp(torch.cat([x, message], dim=1)) # ����������Ĺ�ʽ��Ӧ�Ĵ������
���ﷴ������Self-/Cross-Attention��Ŀ��ԭ����ָ����Ϊ��ģ���������ƥ��ʱ��������Ĺ���,��ʵSelf-AttentionΪ��ʹ���������Ӿ߱�ƥ���������,��Cross-Attention��Ϊ����Щ�߱������Եĵ���ͼ���������ƶȱȽϡ����������ԭ�����������кܺõĿ��ӻ�����,����ͼ��ʾ:
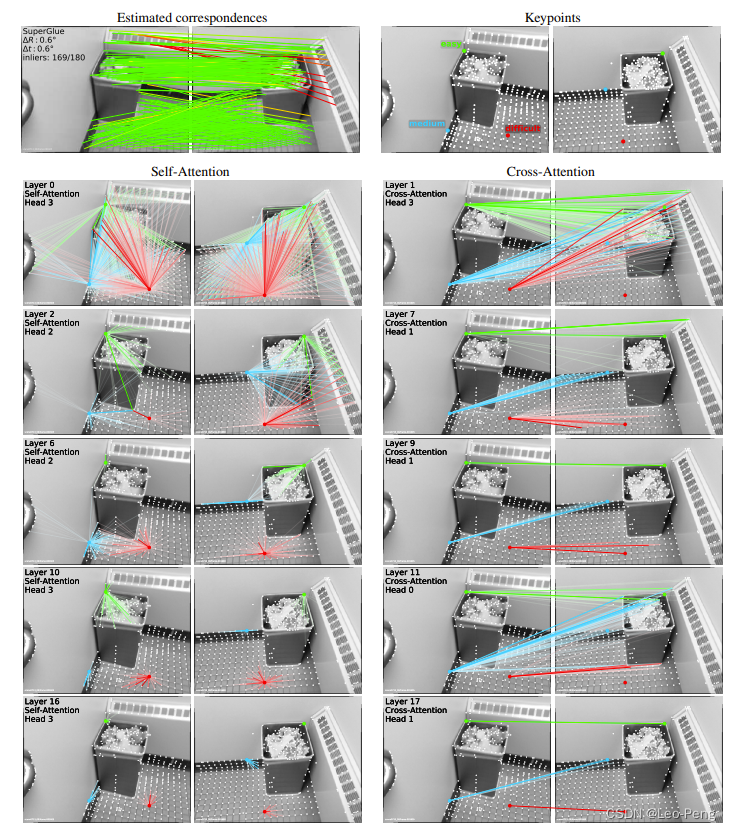
����,��ɫ����ɫ�ͺ�ɫ�ֱ����ƥ����еȺ����ѵ�������,�����Self-Attention�Ŀ��ӻ�������ǿ��Կ���,��dz��ʱ,�������������ͼ�������е�������,�������������������,Self-Attention�����������Լ������Ƶ�������(����λ�ú���������),��Cross-Attention����Ҳ����ͬ��,���������������������������ȷƥ��㡣�������ǿ��Թ۲쵽,��ɫ�����������������,����ע���������������IJ������Ӷ���С��
�����Attention Graph Neural Network�����,���Ƕ��������������������һ��MLP������������ƥ���õ�Score���� S i , j \mathbf{S}_{i, j} Si,j?: f i A = W ? ( L ) x i A + b , ? i �� A \mathbf{f}_{i}^{A}=\mathbf{W} \cdot{ }^{(L)} \mathbf{x}_{i}^{A}+\mathbf{b}, \quad \forall i \in \mathcal{A} fiA?=W?(L)xiA?+b,?i��A f i B = W ? ( L ) x i B + b , ? i �� B \mathbf{f}_{i}^{B}=\mathbf{W} \cdot{ }^{(L)} \mathbf{x}_{i}^{B}+\mathbf{b}, \quad \forall i \in \mathcal{B} fiB?=W?(L)xiB?+b,?i��B S i , j = < f i A , f j B > , ? ( i , j ) �� A �� B , \mathbf{S}_{i, j}=<\mathbf{f}_{i}^{A}, \mathbf{f}_{j}^{B}>, \forall(i, j) \in \mathcal{A} \times \mathcal{B}, Si,j?=<fiA?,fjB?>,?(i,j)��A��B,���� < ? , ? > <��, ��> <?,?>Ϊ��˲���,��Ӧ��������:
# Final MLP projection.
mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1)
# Compute matching descriptor distance.
scores = torch.einsum('bdn,bdm->bnm', mdesc0, mdesc1)
scores = scores / self.descriptor_dim**.5
self.final_proj = nn.Conv1d(self.descriptor_dim, self.descriptor_dim, kernel_size=1, bias=True)
���������Ƕ�scores����Ӧ��Sinkhorn�㷨:
scores = log_optimal_transport(
scores, self.bin_score,
iters=self.config['sinkhorn_iterations'])
def log_sinkhorn_iterations(Z: torch.Tensor, log_mu: torch.Tensor, log_nu: torch.Tensor, iters: int) -> torch.Tensor:
""" Perform Sinkhorn Normalization in Log-space for stability"""
u, v = torch.zeros_like(log_mu), torch.zeros_like(log_nu)
for _ in range(iters):
u = log_mu - torch.logsumexp(Z + v.unsqueeze(1), dim=2)
v = log_nu - torch.logsumexp(Z + u.unsqueeze(2), dim=1)
return Z + u.unsqueeze(2) + v.unsqueeze(1)
def log_optimal_transport(scores: torch.Tensor, alpha: torch.Tensor, iters: int) -> torch.Tensor:
""" Perform Differentiable Optimal Transport in Log-space for stability"""
b, m, n = scores.shape
one = scores.new_tensor(1)
ms, ns = (m*one).to(scores), (n*one).to(scores)
bins0 = alpha.expand(b, m, 1)
bins1 = alpha.expand(b, 1, n)
alpha = alpha.expand(b, 1, 1)
couplings = torch.cat([torch.cat([scores, bins0], -1),
torch.cat([bins1, alpha], -1)], 1)
norm = - (ms + ns).log()
log_mu = torch.cat([norm.expand(m), ns.log()[None] + norm])
log_nu = torch.cat([norm.expand(n), ms.log()[None] + norm])
log_mu, log_nu = log_mu[None].expand(b, -1), log_nu[None].expand(b, -1)
Z = log_sinkhorn_iterations(couplings, log_mu, log_nu, iters)
Z = Z - norm # multiply probabilities by M+N
return Z
Sinkhorn�㷨ԭ�����������Ѿ����ܹ�,����ֵ��ע���һ�����㷨�������ƥ��ʧ������Ĵ���Trick,�������ر����ᵽ��һ����,���������������ƥ��ʧ�ܵ����,��ô���ǵõ��ķ������ P �� [ 0 , 1 ] M �� N \mathbf{P} \in[0,1]^{M \times N} P��[0,1]M��NӦ������: P 1 N �� 1 M ?and? P ? 1 M �� 1 N \mathbf{P} \mathbf{1}_{N} \leq \mathbf{1}_{M} \quad \text { and } \quad \mathbf{P}^{\top} \mathbf{1}_{M} \leq \mathbf{1}_{N} P1N?��1M??and?P?1M?��1N?���д��������� 1 M \mathbf{1}_{M} 1M?�� 1 N \mathbf{1}_{N} 1N?�ֱ�Ϊ����Ϊ M M M�� N N N,Ԫ��ֵΪ 1 1 1��������Ϊ����÷������ P \mathbf{P} P,������ͨ������÷־��� S �� R M �� N \mathbf{S} \in \mathbb{R}^{M \times N} S��RM��N���,����������ʵ�����д����ڵ���������,�ܻ���������ƥ�䲻�ϵ����,Ϊ��,�����ڵ÷־�������һ�к�һ����ΪDustbin: S �� i , N + 1 = S �� M + 1 , j = S �� M + 1 , N + 1 = z �� R \overline{\mathbf{S}}_{i, N+1}=\overline{\mathbf{S}}_{M+1, j}=\overline{\mathbf{S}}_{M+1, N+1}=z \in \mathbb{R} Si,N+1?=SM+1,j?=SM+1,N+1?=z��R��ʱ,������������չΪ a = [ 1 M ? N ] ? \mathbf{a}=\left[\begin{array}{ll}\mathbf{1}_{M}^{\top} & N\end{array}\right]^{\top} a=[1M???N?]?�� b = [ 1 N ? M ] ? \mathbf{b}=\left[\begin{array}{ll}\mathbf{1}_{N}^{\top} & M\end{array}\right]^{\top} b=[1N???M?]?,�ҷ����������: P �� 1 N + 1 = a ?and? P �� ? 1 M + 1 = b \overline{\mathbf{P}} \mathbf{1}_{N+1}=\mathbf{a} \quad \text { and } \quad \overline{\mathbf{P}}^{\top} \mathbf{1}_{M+1}=\mathbf{b} P1N+1?=a?and?P?1M+1?=b��ʵ��Ҳ�ܺ�����,���ڴ�ƥ���,Ҫ�������ֻ������һ��ƥ���ƥ��,���Ƕ���Dustbin,����ܹ� M M M���� N N N��ƥ�����֮��Ӧ,Ҳ����˵�������������е�ƥ��㶼û��ƥ���ϡ�
2.3 ��ʧ����������ѵ��
SuperGlue����ʧ����������ʾ: ?Loss? = ? �� ( i , j ) �� M log ? P �� i , j ? �� i �� I log ? P �� i , N + 1 ? �� j �� J log ? P �� M + 1 , j \begin{aligned} \text { Loss }=&-\sum_{(i, j) \in \mathcal{M}} \log \overline{\mathbf{P}}_{i, j} -\sum_{i \in \mathcal{I}} \log \overline{\mathbf{P}}_{i, N+1}-\sum_{j \in \mathcal{J}} \log \overline{\mathbf{P}}_{M+1, j} \end{aligned} ?Loss?=??(i,j)��M��?logPi,j??i��I��?logPi,N+1??j��J��?logPM+1,j??���� M = { ( i , j ) } ? A �� B \mathcal{M}=\{(i, j)\} \subset \mathcal{A} \times \mathcal{B} M={(i,j)}?A��BΪƥ������ֵ, I ? A \mathcal{I} \subseteq \mathcal{A} I?A�� J ? B \mathcal{J} \subseteq \mathcal{B} J?BΪͼ�� A A A�� B B B��û��ƥ���ϵ������㡣
���������ѵ�����������ĵĸ�¼�����ᵽ:
(1)��������Depth��λ����ֵ�����ݼ���ȡ��ֵ,����������ͨ��ʹ��SuperPoint����SIFT�ֱ�����֪λ�˵�����ͼ�����������,����Depth��һ��ͼ���������ͶӰ����һ��ͼ����,ͨ����ͶӰ����ж���Щ����ƥ��ɹ��ĵ���Ϊ��ֵ�������������ڸ�����,Ҳ����û��ƥ���ϵĵ�,Ҫ����ͶӰ������һ����ֵ��
(2)SuperGlue��Indoor��Outdoor��Homograpy�任�����ֱ�ѵ��,Indoor��Outdoor����ѵ��ʹ��Homograpy�任��ģ����Ϊ���á�
(3)SuperGlue��SuperPoint������ѵ����,�ֱ�ʹ��������SuperPoint����ֱ���м���������ȡ�Ĺ���,��ѵ��������,��ⲿ�ֵ�����Ȩ����ס,ֻѵ��������ȡ���ֵ����硣
���Ͼ����SuperPoint��SuperGlue���ܽ�,����SuperPoint��SuperGlue,������ʹ��NN������ƥ��ķ���Ҳ�в���,����:
��OpenGlue: Open Source Graph Neural Net Based Pipeline for Image Matching��
ƥ���ٶȸ���;
��LoFTR: Detector-Free Local Feature Matching with Transformers��
������ƥ��,��������������Ч���ر��;
��MatchFormer: Interleaving Attention in Transformers for Feature Matching��
�Ľ���LoFTR, ��Attention�������������,�������������ƥ���ڴ��ӽDZ仯ʱ��ƥ������
��Щ�㷨֮����ʱ�������������,�����ӭ����~

