本博客讲解如何利用Faster-RCNN去训练Pascol VOC数据集或者训练自定义数据集。
Faster-RCNN原理,参考博文:RCNN、Fast-RCNN、Faster-RCNN理论合集
如何在pytorch中找到Faster-RCNN源码
通过import detection.faster_rcnn, 然后按Ctr + 鼠标左键,就可以参考faster_rcnn所实现的一些源码了
import torchvision.models.detection.faster_rcnn
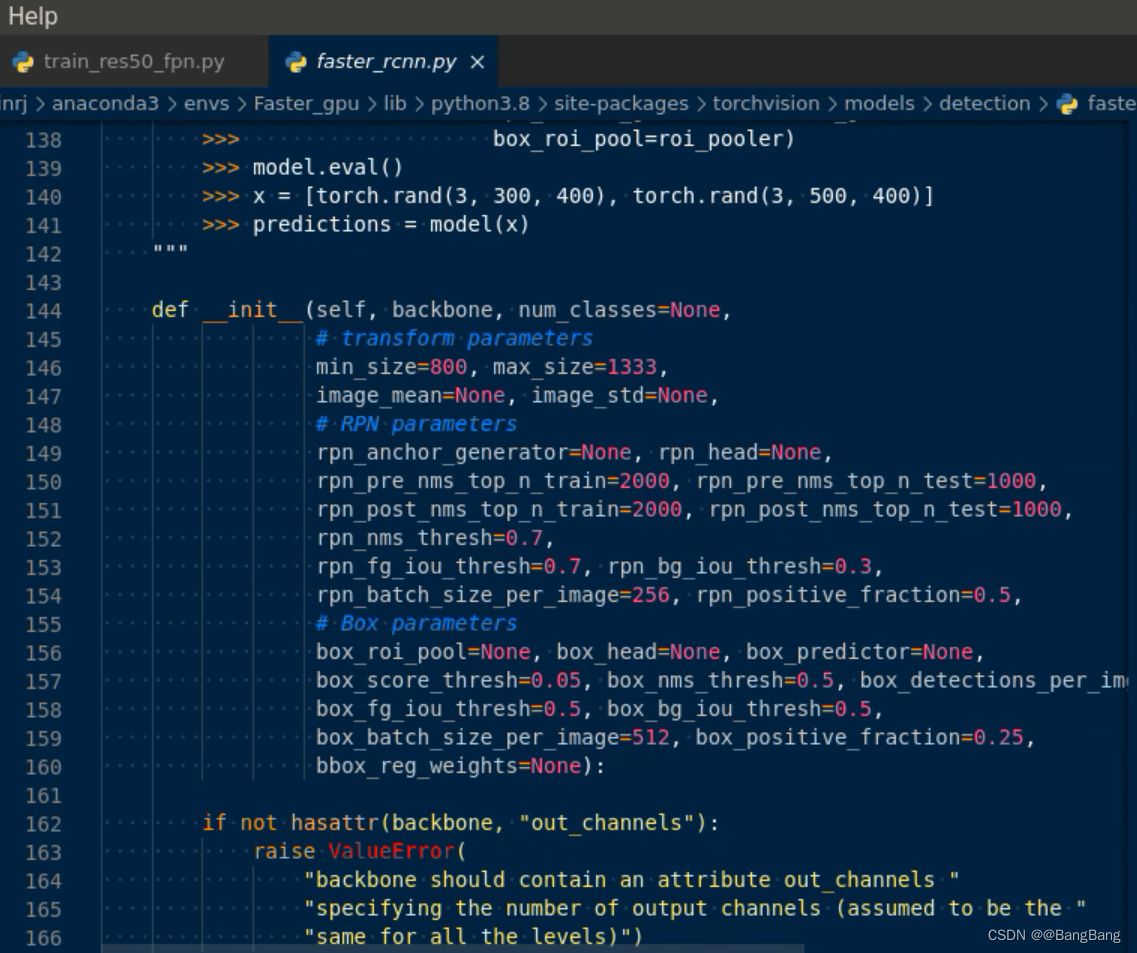
但这里其实只是代码的一部分,和训练相关的代码这里并没有,根据官方的提示。可以在pytorch github中找到
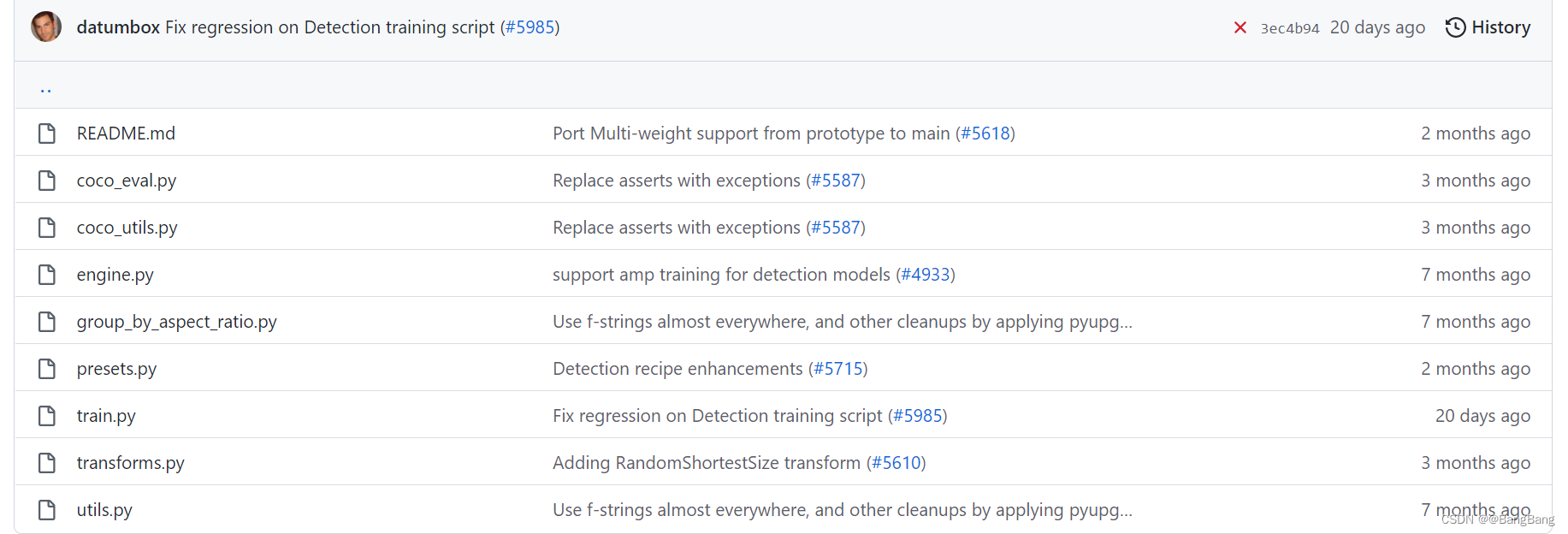
可以看到训练相关的源代码了,如果自己想看faster-cnn源代码可以结合这两部分。
训练准备
环境配置
- Python3.6/3.7/3.8
- Pytorch1.7.1(注意:必须是1.6.0或以上,因为使用官方提供的混合精度训练1.6.0后才支持)
- pycocotools(Linux:pip install pycocotools; Windows:pip install pycocotools-windows(不需要额外安装vs))
- Ubuntu或Centos(不建议Windows)
- 最好使用GPU训练
- 详细环境配置见requirements.txt
这里有使用到coco的评价准则,所以需要安装pycocotools,系统的话建议使用Linux,训练最好也是使用GPU训练
文件结构
├── backbone: 特征提取网络(分类网络),可以根据自己的要求选择
├── network_files: Faster R-CNN网络(包括Fast R-CNN以及RPN等模块)
├── train_utils: 训练验证相关模块(包括cocotools)
├── my_dataset.py: 自定义dataset用于读取VOC数据集
├── train_mobilenet.py: 以MobileNetV2做为backbone进行训练
├── train_resnet50_fpn.py: 以resnet50+FPN做为backbone进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
├── validation.py: 利用训练好的权重验证/测试数据的COCO指标,并生成record_mAP.txt文件
└── pascal_voc_classes.json: pascal_voc标签文件
- 其中
backbone就是一系列分类网络,可以根据自己的需求进行选择,我这边根据官方的样例使用了两个backbone:mobienetv2 和resnet50+fpn(特征金字塔结构); - train_utils就是pytorch github官方给出的训练代码,我这边将他们放在
train_utils文件中。 my_dataset.py:自定义dataset去读取VOC数据集,官方也提供了直接读取VOC数据集的工具,我这里主要是强调如何自己读取dataset,了解自定义数据集的原理之后就可以按照自己的需求创建自定义数据集,编写相应的脚本去读取就可以了。train_mobilenet.py: 以MobileNetV2做为backbone进行训练,该backbone预测特征层只有一层,和Faster-RCNN论文描述的方法基本上保持一致train_resnet50_fpn.py: 以resnet50+FPN做为backbone进行训练,个人比较推荐用这个脚本,因为该脚本的训练效果是很好的,如果你要在实际应用去使用的话,尽可能去使用该脚本。对于train_mobilenet.py: 以MobileNetV2做为backbone进行训练,准确率相比要低很多,不建议在实际项目中去使用,主要原因一方面是训练数据不够多,另外该官方没有提供完整的预训练模型权重,但官方给出了完整的resnet50+FPN的预训练权重。基于resnet50+FPN预训练权重进行迁移学习,就能很快迭代到属于自己的模型了。train_multi_GPU.py: 针对使用多GPU的用户使用,它的训练方法和单GPU训练方法是不一样的,单GPU可以直接在IDE环境中run脚本文件进行训练。但train_multi_GPU.py需要在终端命令行窗口输入指令进行训练。validation.py: 利用训练好的权重验证/测试数据的COCO指标,并生成record_mAP.txt文件pascal_voc_classes.json:pascal_voc标签文件,标签文件如下:
{
"aeroplane": 1,
"bicycle": 2,
"bird": 3,
"boat": 4,
"bottle": 5,
"bus": 6,
"car": 7,
"cat": 8,
"chair": 9,
"cow": 10,
"diningtable": 11,
"dog": 12,
"horse": 13,
"motorbike": 14,
"person": 15,
"pottedplant": 16,
"sheep": 17,
"sofa": 18,
"train": 19,
"tvmonitor": 20
}
标签为啥没有从0开始? 因为在我们目标检测当中,一般0是专门留给我们的背景的。虽然我们说pascal_voc只有20个类别,其实实际训练过程中给出了21个类别,专门为背景设了一个类别。
预训练权重下载
预训练权重下载地址(下载后放入backbone文件夹中)
- MobileNetV2 backbone: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth,在faster-rcnn中MobileNetV2预训练权重只有backbone权重,其中RPN和fast-rcnn部分的权重是没有的,所以训练效果也不是特别的好
- ResNet50+FPN backbone: https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth,
给的是完整的模型权重,不仅包括back_bone部分,还包括RPN和Fast-RCNN后半部分的权重。所以针对ResNet50+FPN给出的权重,可以针对自己的数据集进行较好的迁移学习,并且很快能得到一个比较理想的结果 - 注意,下载的预训练权重记得要重命名,比如在train_resnet50_fpn.py中读取的是
fasterrcnn_resnet50_fpn_coco.pth文件, 不是fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
数据集
本例程使用的是PASCAL VOC2012数据集
- Pascal VOC2012 train/val数据集下载地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
- 如果不了解数据集或者想使用自己的数据集进行训练,请参考bilibili:https://b23.tv/F1kSCK
- 使用ResNet50+FPN以及迁移学习在VOC2012数据集上得到的权重: 链接:https://pan.baidu.com/s/1ifilndFRtAV5RDZINSHj5w 提取码:dsz8
训练方法
- 确保提前准备好数据集
- 确保提前下载好对应预训练模型权重,下载好后放在项目的
backbone文件夹中,代码中是从backbone文件中寻找预训练权重的。 - 若要训练mobilenetv2+fasterrcnn,直接使用train_mobilenet.py训练脚本,建议在学术研究中使用
- 若要训练resnet50+fpn+fasterrcnn,直接使用train_resnet50_fpn.py训练脚本,建议在工程应用中使用
- 若要使用多GPU训练,使用
python -m torch.distributed.launch --nproc_per_node=8 --use_env train_multi_GPU.py
指令,nproc_per_node参数为使用GPU数量
- 如果想指定使用哪些GPU设备可在指令前加上
CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备)
CUDA_VISIBLE_DEVICES=0,3 python -m torch.distributed.launch --nproc_per_node=2 --use_env train_multi_GPU.py
其中torch.distributed.launch是一个多进程的工具,可以开启多个进程执行python脚本,同时调用多个GPU进行加速训练。nproc_per_node指定GPU的个数,train_multi_GPU.py就是项目中训练多GPU的代码
注意事项
- 在使用训练脚本时,注意要将
--data-path(VOC_root)设置为自己存放VOCdevkit文件夹所在的根目录
由于带有FPN结构的Faster RCNN很吃显存,如果GPU的显存不够(如果batch_size小于8的话)建议在create_model函数中使用默认的norm_layer, 即不传递norm_layer变量,默认去使用FrozenBatchNorm2d(即不会去更新参数的bn层),使用中发现效果也很好。 - 训练过程中保存的
results.txt是每个epoch在验证集上的COCO指标,前12个值是COCO指标,后面两个值是训练平均损失以及学习率 - 在使用预测脚本时,要将
train_weights设置为你自己生成的权重路径。 - 使用
validation文件时,注意确保你的验证集或者测试集中必须包含每个类别的目标,并且使用时只需要修改--num-classes、--data-path和--weights-path即可,其他代码尽量不要改动
训练脚本讲解
这里以train_mobienet.py代码进行讲解
- 定义训练的设备类型,是
gpu还是cpu
device = torch.device(parser_data.device if torch.cuda.is_available() else "cpu")
print(device)
- 定义图像预处理的函数
data_transform = {
"train": transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(0.5)]),
"val": transforms.Compose([transforms.ToTensor()])
}
ToTensor():包含了两个功能:1. 图片归一化到(0,1) 2.将nd.array数据转换为tensor
目标检测图像预处理和分类网络的预处理是不一样的,比如transforms.RandomHorizontalFlip(0.5),因为在我们目标检测中,我们对图片水平方向进行随机翻转的话,我们所标注的GT Box坐标也同样需要进行水平翻转。
- 自定义数据集
VOC_root = parser_data.data_path
# load train data set
train_data_set = VOC2012DataSet(VOC_root, data_transform["train"], True)
并通过dataloader载入数据集:
# 注意这里的collate_fn是自定义的,因为读取的数据包括image和targets,不能直接使用默认的方法合成batch
train_data_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=4,
shuffle=True,
num_workers=0,
collate_fn=utils.collate_fn)
其中collate_fn代码
def collate_fn(batch):
return tuple(zip(*batch))
batch_size的大小需要根据你电脑的GPU显存去设计,如果提示显存不够就需要减小batch_size的大小。
同理验证集的数据集
# load validation data set
val_data_set = VOC2012DataSet(VOC_root, data_transform["val"], False)
val_data_set_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=utils.collate_fn)
- num_class类别是加上背景的,所以这里是21
# create model num_classes equal background + 20 classes
model = create_model(num_classes=21)
print(model)
model.to(device)
- Faster-RCNN还有点麻烦,是分开两部分进行训练的
阶段1:冻结前置特征提取网络权重(backbone),训练rpn以及fast-rcnn最终预测网络部分
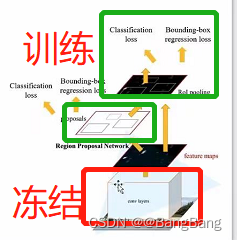
以backbone为mobienet为例,训练第一阶段载入mobienet v2的backbone模型初始化backbone这块,然后冻结backbone去训练RPN以及Fast-RCNN的后半部分。通过固定backbone权重去微调RPN和Fast-RCNN的后半部分。
这里通过5个epoch对网络进行微调,并保存模型
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# first frozen backbone and train 5 epochs #
# 首先冻结前置特征提取网络权重(backbone),训练rpn以及最终预测网络部分 #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
for param in model.backbone.parameters():
param.requires_grad = False
# define optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
num_epochs = 5
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, print_freq=50)
# evaluate on the test dataset
utils.evaluate(model, val_data_set_loader, device=device)
torch.save(model.state_dict(), "./save_weights/pretrain.pth")
阶段2:解冻前置特征提取网络权重(backbone),接着训练整个网络权重。
这里代码借鉴pytorch 上实现的resnet50+fpn代码来实现的。
# 冻结backbone部分底层权重
for name, parameter in model.backbone.named_parameters():
split_name = name.split(".")[0]
if split_name in ["0", "1", "2", "3"]:
parameter.requires_grad = False
else:
parameter.requires_grad = True
冻结了backbone的部分底层权重,比如前一两层都是相对通用的特征。而且我们的pascal_voc的训练数据不是很大,也就5000多张图片,训练整个网络其实是远远不够的。最终的结果来看,它比训练整个模型的效果要好一点。
对require_grad=True对需要训练的参数进行训练,学习率策略lr_scheduler,设置为每隔5步,将学习率降低为原来的0.33倍。
# define optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# learning rate scheduler
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=5,
gamma=0.33)
这里迭代了20 个epoch,每迭代一个epoch,将学习率的调整策略lr_scheduler,执行一个step方法,这样就记录了已经执行了一步了,每隔5步,它将会降低一次学习率。
num_epochs = 20
for epoch in range(num_epochs):
# train for one epoch, printing every 50 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, print_freq=50, warmup=True)
# update the learning rate
lr_scheduler.step()
保存权重这块,我这里是从第10个epoch开始保存的,在我训练过程中,我发现基本上在第10个epoch就开始收敛了。
注意这里保存的权重,并不光指模型的权重,之前在训练分类网络的时候,基本上就将model.state_dict()权重进行保存。这里除了保存模型权重之外,还保存了有关优化器optimizer的状态以及学习策略lr_sheduler以及epoch数,这样我们再后面如果想接着你上次训练的话,可以载入这些参数,接着上次的方法继续训练了。
for epoch in range(num_epochs):
# train for one epoch, printing every 50 iterations
utils.train_one_epoch(model, optimizer, train_data_loader,
device, epoch, print_freq=50, warmup=True)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
utils.evaluate(model, val_data_set_loader, device=device)
# save weights
if epoch > 10:
save_files = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch}
torch.save(save_files, "./save_weights/mobile-model-{}.pth".format(epoch))
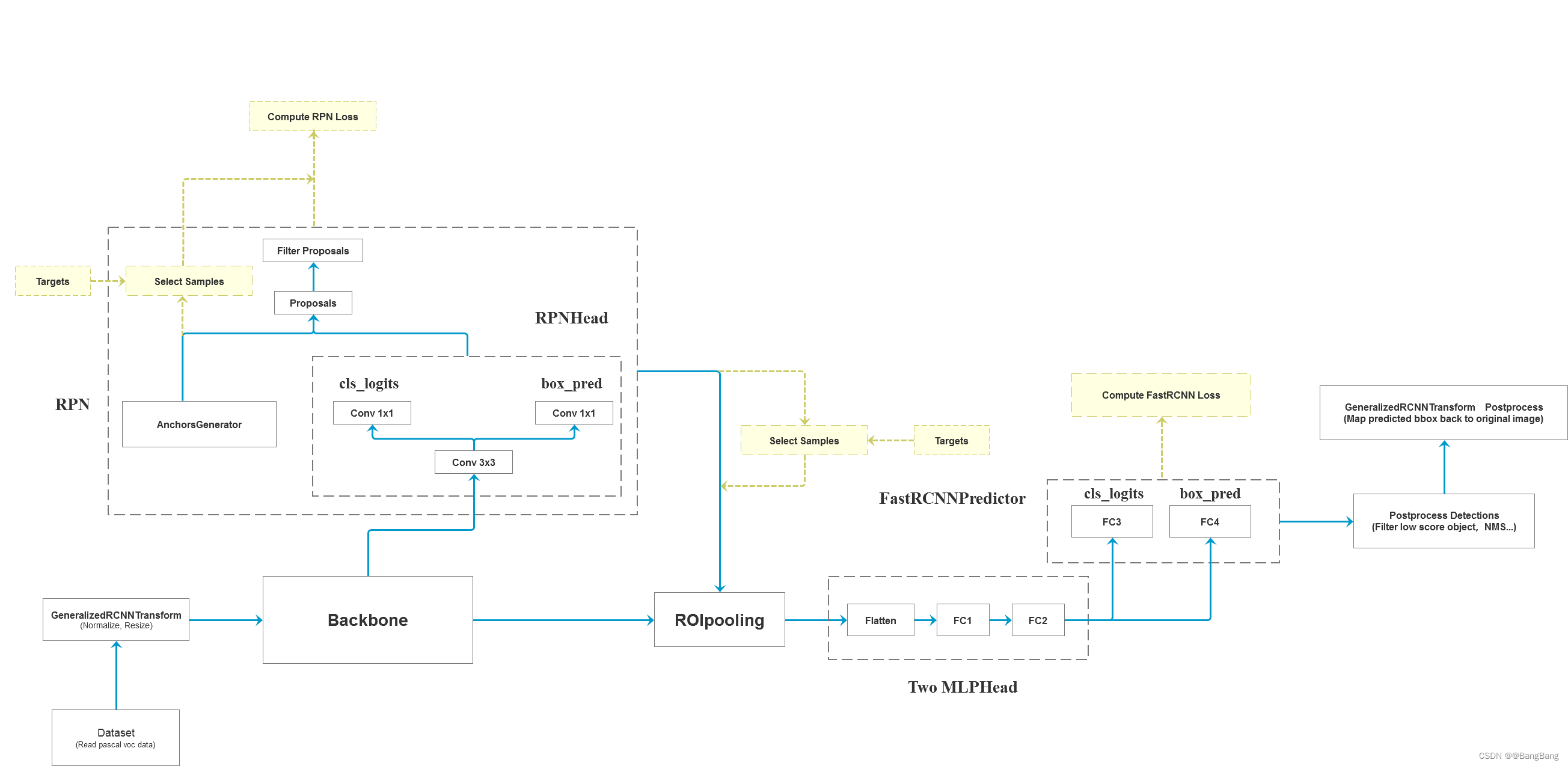
Faster RCNN框架图