����ģ��
���÷���:������ѧ���ѧϰ��
�ı����������ݵ�һ����Ҫ���ӡ���ʵ��,���ǽ�ʹ����Ȼ����ģ����Ϊ�������������ӵĻ��������ڴ�,ֵ�ö�һЩ������и���ϸ�����ۡ���������,���ǽ��ѵ���(���ַ�����)��Ϊ��ɢ�۲��ʱ�����С����賤��ΪT���ı��еĴ�����Ϊw1;w2;��;wT,��ô,����ɢʱ��������,wt(1 < t < T)���Ա���Ϊʱ�䲽��t��������ǩ��
p ( w 1 , w 2 , �� , w T ) . p(w_1, w_2, \ldots, w_T). p(w1?,w2?,��,wT?).
����ģ���Ƿdz����õġ�����,һ�����������ģ���ܹ�����������Ȼ�ı�,ֻ��һ�λ�һ����wt ~ p(wt|wt-1; . . .w1 ) ��ʹ�ô��ֻ��ĺ�����ȫ��ͬ,������һ��ģ���г��ֵ������ı����ᱻ��Ϊ��Ȼ����,����Ӣ���ı�������,����������һ��������ĶԻ�,ֻ�轫�ı�������ǰ�ĶԻ�Ƭ���м��ɡ���Ȼ,�������������һ��ϵͳ����Զ,��Ϊ����Ҫ�����ı�,�������������ɷ���������ݡ�
Ȼ��,����ģ�ͼ�ʹ����������ʽ��Ҳ�Ƿdz����õġ�����, ��to recognize speech�� and ��to wreck a nice beach�� �����������������dz����ơ�����ܻ�������ʶ������������,����������ͨ������ģ�ͺ������,��Ϊ����ģ�ͻ�ܾ��ڶ��ַ���,��Ϊ���ܻ��ơ�ͬ��,��һ���ļ��ܽ��㷨��,ֵ��֪�����ǡ���ҧ�ˡ��ȡ���ҧ������Ƶ�ʸߵö�,���ߡ������dz����̡���һ���൱���˲�����˵��,���������dz�,���̡���Ҫ���Եöࡣ
һ������һ������ģ��
һ���Զ�����������,����Ӧ����ζ�һ���ļ�,������һ���ʵ����н��н�ģ�����ǿ�����������������һ����Ӧ��������ģ�͵ķ����������Ǵ�Ӧ�û����ĸ��ʹ���ʼ��
p ( w 1 , w 2 , �� , w T ) = �� t = 1 T p ( w t �O w 1 , �� , w t ? 1 ) . p(w_1, w_2, \ldots, w_T) = \prod_{t=1}^T p(w_t | w_1, \ldots, w_{t-1}). p(w1?,w2?,��,wT?)=t=1��T?p(wt?�Ow1?,��,wt?1?).
����,һ�������ĸ��ɵ��ʺͱ�������ɵ��ı����еĸ��ʽ�������:
p ( S t a t i s t i c s , i s , f u n , . ) = p ( S t a t i s t i c s ) p ( i s �O S t a t i s t i c s ) p ( f u n �O S t a t i s t i c s , i s ) p ( . �O S t a t i s t i c s , i s , f u n ) . p(\mathrm{Statistics}, \mathrm{is}, \mathrm{fun}, \mathrm{.}) = p(\mathrm{Statistics}) p(\mathrm{is} | \mathrm{Statistics}) p(\mathrm{fun} | \mathrm{Statistics}, \mathrm{is}) p(\mathrm{.} | \mathrm{Statistics}, \mathrm{is}, \mathrm{fun}). p(Statistics,is,fun,.)=p(Statistics)p(is�OStatistics)p(fun�OStatistics,is)p(.�OStatistics,is,fun).
Ϊ�˼�������ģ��,������Ҫ���㵥�ʵĸ��ʺ���ǰ�������ʵ���������,������ģ�Ͳ�����
������,���Ǽ���ѵ�����ݼ���һ�������ı����Ͽ�,������ά���ٿ���Ŀ�����ڱ��ƻ������Ϸ����������ı�������ĸ��ʿ���ͨ��ѵ�����ݼ��и����������Դ�Ƶ�����㡣
����,p(Statistics)���Ա�����Ϊ�κ��� "ͳ�� "һ�ʿ�ʼ�ľ��ӵĸ��ʡ�һ��������ôȷ�ķ����Ǽ��� "ͳ�� "����ʵ����г��ִ���,Ȼ����������Ͽ��е��ܴ�����
���ַ�����Ч���൱��,�ر��Ƕ���Ƶ�����ֵĴʡ�
p ^ ( i s �O S t a t i s t i c s ) = n ( S t a t i s t i c s ? i s ) n ( S t a t i s t i c s ) . \hat{p}(\mathrm{is}|\mathrm{Statistics}) = \frac{n(\mathrm{Statistics~is})}{n(\mathrm{Statistics})}. p^?(is�OStatistics)=n(Statistics)n(Statistics?is)?.
Ϊ�˼�������ģ��,������Ҫ���㵥�ʵĸ��ʺ���ǰ�������ʵ���������,������ģ�Ͳ�����
������,���Ǽ���ѵ�����ݼ���һ�������ı����Ͽ�,������ά���ٿ���Ŀ�����ڱ��ƻ������Ϸ����������ı���
����ĸ��ʿ���ͨ��ѵ�����ݼ��и����������Դ�Ƶ�����㡣����,p(Statistics)���Ա�����Ϊ�κ��� "Statistics "һ�ʿ�ʼ�ľ��ӵĸ��ʡ�
һ��������ôȷ�ķ����Ǽ��� "ͳ�� "����ʵ����г��ִ���,Ȼ����������Ͽ��е��ܴ��������ַ�����Ч���൱��,�ر��Ƕ���Ƶ�����ֵĴʡ�
һ�������IJ����ǽ���ij����ʽ��������˹ƽ�����������������汴Ҷ˹��ʱ���Ѿ��������������,��ʱ�Ľ�������������м���������һ��С�������������ڴ�������,����,ͨ��
p ^ ( w ) = n ( w ) + ? 1 / m n + ? 1 ? p ^ ( w �� �O w ) = n ( w , w �� ) + ? 2 p ^ ( w �� ) n ( w ) + ? 2 ? p ^ ( w �� �� �O w �� , w ) = n ( w , w �� , w �� �� ) + ? 3 p ^ ( w �� , w �� �� ) n ( w , w �� ) + ? 3 \begin{aligned} \hat{p}(w) & = \frac{n(w) + \epsilon_1/m}{n + \epsilon_1} \ \hat{p}(w'|w) & = \frac{n(w,w') + \epsilon_2 \hat{p}(w')}{n(w) + \epsilon_2} \ \hat{p}(w''|w',w) & = \frac{n(w,w',w'') + \epsilon_3 \hat{p}(w',w'')}{n(w,w') + \epsilon_3} \end{aligned} p^?(w)?=n+?1?n(w)+?1?/m??p^?(w���Ow)?=n(w)+?2?n(w,w��)+?2?p^?(w��)??p^?(w�����Ow��,w)?=n(w,w��)+?3?n(w,w��,w����)+?3?p^?(w��,w����)??
�����ϵ��?i>0�����������ڶ��̶���ʹ�ý϶����еĹ���ֵ��Ϊ�ϳ����е���䡣����,m�����������Ĵʵ�������������Kneser-Neyƽ�����ͱ�Ҷ˹�Dz�����������ɵ�һ���൱ԭʼ�ı��塣
�������ʵ����һĿ��ĸ���ϸ��,��Wood���˵�Sequence Memoizer, 2012�����ҵ���,������ģ�ͺܿ�ͻ��ñ���:����,������Ҫ�洢���еļ���,���,����ȫ�����˴ʵĺ��塣
����,"è "�� "è "Ӧ�ó�������ص��ᄈ�С��������ѧϰ������ģ�ͺ��ʺϿ��ǵ���һ�㡣��һ��,Ҫ���ݶ�����ᄈ��������ģ�����൱���ѵġ�
���,���ĵ������м������Կ϶����µ�,���,�ؼ�����ǰ�����ĵ������е�Ƶ�ʵ�ģ��������һ������ֲ��ѡ�
���������Ʒ�ģ�ͺ�n-grams
�����������漰���ѧϰ�Ľ������֮ǰ,���ǻ���ҪһЩ�������ع���������һ���ж������ɷ�ģ�͵����ۡ������ǰ���Ӧ�������Խ�ģ�����p(wt+1|wt; . .w1)=p(wt+1|wt),�������ϵķֲ�����һ�������Ʒ����ԡ����ߵĽ�����Ӧ�ڸ�����������ϵ����͵��������ǿ���Ӧ��һЩ����ֵ��Ϊ���н�ģ��
p ( w 1 , w 2 , w 3 , w 4 ) = p ( w 1 ) p ( w 2 ) p ( w 3 ) p ( w 4 ) ? p ( w 1 , w 2 , w 3 , w 4 ) = p ( w 1 ) p ( w 2 �O w 1 ) p ( w 3 �O w 2 ) p ( w 4 �O w 3 ) ? p ( w 1 , w 2 , w 3 , w 4 ) = p ( w 1 ) p ( w 2 �O w 1 ) p ( w 3 �O w 1 , w 2 ) p ( w 4 �O w 2 , w 3 ) \begin{aligned} p(w_1, w_2, w_3, w_4) &= p(w_1) p(w_2) p(w_3) p(w_4)\ p(w_1, w_2, w_3, w_4) &= p(w_1) p(w_2 | w_1) p(w_3 | w_2) p(w_4 | w_3)\ p(w_1, w_2, w_3, w_4) &= p(w_1) p(w_2 | w_1) p(w_3 | w_1, w_2) p(w_4 | w_2, w_3) \end{aligned} p(w1?,w2?,w3?,w4?)?=p(w1?)p(w2?)p(w3?)p(w4?)?p(w1?,w2?,w3?,w4?)?=p(w1?)p(w2?�Ow1?)p(w3?�Ow2?)p(w4?�Ow3?)?p(w1?,w2?,w3?,w4?)?=p(w1?)p(w2?�Ow1?)p(w3?�Ow1?,w2?)p(w4?�Ow2?,w3?)?
���������漰һ������������������,��Щģ��ͨ������Ϊ���֡����ֺ�����ģ�͡���������,���ǽ�ѧϰ�����Ƹ��õ�ģ�͡�
������Ȼ����ͳ��
�����ǿ���������ʵ����������ι����ġ�Ϊ�˿�ʼ,���Ǵ�H.G. Wells�ġ�ʱ��������м����ı�������һ���൱С�����Ͽ�,ֻ��3�����,����������Ҫ˵����Ŀ����˵,����㹻�ˡ�����ʵ���ļ���������ʮ���֡�����,���ǽ��ļ����Ϊ����,�����Ա����źʹ�д��ĸ����Ȼ�������һЩ��ص���Ϣ,�����ڼ���һ��ļ���ͳ���Ǻ����õġ������ǿ���ǰ������ʲô���ӵġ�
import sys
sys.path.insert(0, '..')
import collections
import re
with open('../data/timemachine.txt', 'r') as f:
lines = f.readlines()
raw_dataset = [re.sub('[^A-Za-z]+', ' ', st).lower().split() for st in lines]
for st in raw_dataset[8:12]:
print('tokens:', len(st), st)
tokens: 13 ['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
tokens: 12 ['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
tokens: 11 ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
tokens: 10 ['fire', 'burned', 'brightly', 'and', 'the', 'soft', 'radiance', 'of', 'the', 'incandescent']
����������Ҫ������뵽һ�����ʼ������С�����Ǽ������ݽṹ�����ó��ĵط�����Ϊ���Ǵ��������еĻ�ƹ�����
counter = collections.Counter([t for s in raw_dataset for t in s])
print(" 'traveller'�Ĵ�Ƶ:", counter['traveller'])
print(counter.most_common(10))
frequency of 'traveller': 61
[('the', 2261), ('i', 1267), ('and', 1245), ('of', 1155), ('a', 816), ('to', 695), ('was', 552), ('in', 541), ('that', 443), ('my', 440)]
����������������,�����еĴ���ʵ�Ǻ����ĵ�,���������������ڴ�ͳ��NLP��,����ͨ������Ϊֹͣ��,��˱����˵��ˡ�
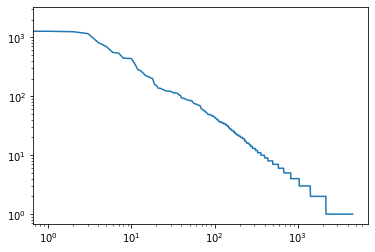
Ҳ����˵,������Ȼ��������,�������,���ǻ��ǻ�ʹ�����ǡ�Ȼ��,��һ�������൱�����,�Ǿ��Ǵʵ�Ƶ��˥�����൱�졣��10���ʵ�Ƶ�ʻ��������ܻ�ӭ���Ǹ��ʵ�1/5��Ϊ�˵õ�һ�����õĸ���,���ǻ����˵���Ƶ�ʵ�ͼ����
%matplotlib inline
from matplotlib import pyplot as plt
wordcounts = [count for i,count in counter.most_common()]
plt.loglog(wordcounts);
?
?
�������������һЩ�ܻ����Ķ����C�ʵ�Ƶ����һ����ȷ�ķ�ʽѸ��˥�����ڴ�����ǰ�ĸ��ʵ��������(��the������i������and������of��)֮��,����ʣ�µĴ��ڶ���ͼ�϶���ѭһ��ֱ�ߡ�����ζ�ŵ��ʷ���Zipf����,�ö���ָ��,��ĿƵ�������¹�ʽ����
n(x) ~ (x + c) -a,���log n(x) = -a log(x + c) + const��
���������ͨ������ͳ�ƺ�ƽ��������������ģ��,��Ӧ���Ѿ���������ͣ�ˡ��Ͼ�,���ǽ����߹�β����Ƶ��,Ҳ���Dz��������ֵĴʡ����Ǵʶ�(�Լ�����������)��?��������������
for st in raw_dataset[0:1]:
print(st)
for tk in st:
print(tk)
['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
the
time
machine
by
h
g
wells
wse = wseq[0:11] # ȡ����
print(wse)
word_pairs = [pair for pair in zip(wse[:-1], wse[1:])]
print(word_pairs) # �������ڴ�������,�洢ΪԪ��
['the', 'time', 'machine', 'by', 'h', 'g', 'wells', 'i', 'the', 'time', 'traveller']
[('the', 'time'), ('time', 'machine'), ('machine', 'by'), ('by', 'h'), ('h', 'g'), ('g', 'wells'), ('wells', 'i'), ('i', 'the'), ('the', 'time'), ('time', 'traveller')]
# raw_dataset�ǰ��зִʵ����б�
wseq = [tk for st in raw_dataset for tk in st] # �������б���Ԫ�ض�չ��,�����д������һ���б�֮��
word_pairs = [pair for pair in zip(wseq[:-1], wseq[1:])] # �����������
print('���ڴ������Ԫ��\n', word_pairs[:10])
counter_pairs = collections.Counter(word_pairs)
print('���������ʽ\n', counter_pairs.most_common(10))
���ڴ������Ԫ��
[('the', 'time'), ('time', 'machine'), ('machine', 'by'), ('by', 'h'), ('h', 'g'), ('g', 'wells'), ('wells', 'i'), ('i', 'the'), ('the', 'time'), ('time', 'traveller')]
���������ʽ
[(('of', 'the'), 309), (('in', 'the'), 169), (('i', 'had'), 130), (('i', 'was'), 112), (('and', 'the'), 109), (('the', 'time'), 102), (('it', 'was'), 99), (('to', 'the'), 85), (('as', 'i'), 78), (('of', 'a'), 73)]
����������ֵ��ע��ġ���10����Ƶ���Ĵʶ���,��9������ֹͣ����ɵ�,ֻ��һ����ʵ�ʵ����йبC��ʱ�䡱�������ǿ������Ƶ�ʵı����Ƿ��뵥��Ƶ�ʵı�����ͬ��
word_triples = [triple for triple in zip(wseq[:-2], wseq[1:-1], wseq[2:])] # ���ڵ������������
counter_triples = collections.Counter(word_triples) # �����ڵ�����������Ͻ��м���
print('���ڵ�����������Ͻ��м���\n', counter_triples.most_common(10))
���ڵ�����������Ͻ��м���
[(('the', 'time', 'traveller'), 59), (('the', 'time', 'machine'), 30), (('the', 'medical', 'man'), 24), (('it', 'seemed', 'to'), 16), (('it', 'was', 'a'), 15), (('here', 'and', 'there'), 15), (('seemed', 'to', 'me'), 14), (('i', 'did', 'not'), 14), (('i', 'saw', 'the'), 13), (('i', 'began', 'to'), 13)]
word_triples = [triple for triple in zip(wseq[:-2], wseq[1:-1], wseq[2:], wseq[3:])] # ���ڵ�4���������
four_triples = collections.Counter(word_triples) # �����ڵ�4��������Ͻ��м���
print('���ڵ��ĸ�������Ͻ��м���\n', four_triples)
# wordcounts�ǵ�������ļ���
wordcounts = [count for i,count in counter.most_common()]
bigramcounts = [count for _,count in counter_pairs.most_common()] # ����������ϼ���,ֻ��ʾtop����
triplecounts = [count for _,count in counter_triples.most_common()] # ����������ϼ���,ֻ��ʾtop����
fourcounts = [count for _,count in four_triples.most_common()] # 4��������ϼ���,ֻ��ʾtop����
plt.loglog(wordcounts, label='word counts');
plt.loglog(bigramcounts, label='bigram counts');
plt.loglog(triplecounts, label='triple counts');
plt.loglog(fourcounts, label='four counts');
plt.legend();
?
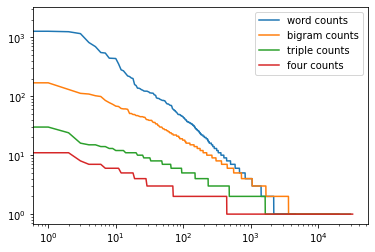
����ͼ���൱�����˷ܵ�,ԭ���кܶࡣ����,���˵���֮��,���������ƺ�Ҳ����ѭZipf����,����ָ���ϵ�,��ȡ�������г��ȡ����,���ص�n-grams�����������ࡣ���������ϣ��,�����д����൱��Ľṹ������,����n-grams���ֵ÷dz���,��ʹ��������˹ƽ�����൱���ʺ��������Խ�ģ�����,���ǽ�ʹ�û������ѧϰ��ģ�͡�
�ġ�ժҪ
-
����ģ������Ȼ���Դ�����һ����Ҫ������
-
n-gramsͨ���ض�������ϵΪ�����������ṩ��һ�������ģ�͡�
-
��������һ������,�����Ǻ��ٻ��δ���֡������Ҫ����ƽ������,����ͨ����Ҷ˹�Dz�������ͨ�����ѧϰ��
-
Zipf����֧����unigrams��n-grams�ĵ��ʷֲ���
-
�кܶ�ṹ,��û���㹻��Ƶ����ͨ��ƽ��������Ƶ���ĵ�����ϡ�

