作者?Taylor, Mary, 翻译?李翊玮
关于 OpenVINO? 深度学习工作台的三部分系列文章
关于该系列
- 了解如何转换、微调和打包 推理就绪的 TensorFlow 模型,该模型针对英特尔?硬件进行了优化,仅使用 Web 浏览器。每一步都在云中使用 OpenVINO? 深度学习工作台和 Intel? DevCloud for the Edge 进行。
- 第一部分:我们向您展示英特尔?深度学习推理工具及其工作原理的基础知识。
- 第二部分(此文):我们使用OpenVINO深度学习工作台完成导入,转换和基准测试TensorFlow模型的每个步骤。
- 第三部分:我们向您展示如何更改精度级别以提高性能,以及如何使用OpenVINO深度学习工作台仅使用浏览器导出随时可运行的推理包。
第二部分:使用 OpenVINO 深度学习工作台在英特尔硬件上导入、转换 TensorFlow 模型并进行基准测试
在第一部分中,我们解释了深度学习推理的基础知识以及它在英特尔硬件上的工作原理。然后,我们向您展示了如何获得免费的英特尔? DevCloud for the Edge 帐户,以便您可以使用 OpenVINO 深度学习工作台开始在线转换和优化推理模型。
在第二部分中,我们将引导您完成从TensorFlow模型为英特尔硬件创建优化的推理模型,并运行您的第一个基准测试。
如果您还没有,请注册DevCloud for the Edge。它是免费的,只需要几分钟。拥有帐户后,登录到 DevCloud 并启动 OpenVINO 深度学习工作台。
?
步骤一:创建配置并导入TensorFlow模型
若要开始,请单击“创建”创建新配置。您可以根据需要创建任意数量的配置 ―使用不同的模型、优化和目标硬件。
首先,单击深度学习工作台起始页上的创建。
接下来,我们将导入模型。您可以上传自己的模型,也可以从我们的开放模型动物园获取一个。在本演示中,让我们从 Open Model Zoo 导入一个基于 COCO 的对象检测模型。
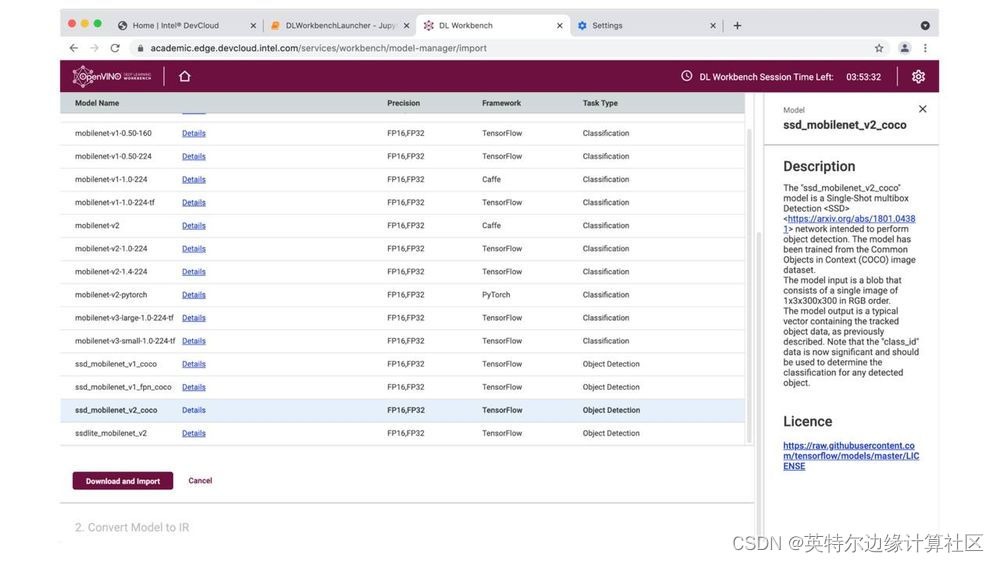
您可以导入自己的模型,也可以使用我们的开放模型动物园中的模型。
第二步:将TensorFlow模型转换为英特尔?红外文件
OpenVINO 深度学习工作台(使用模型优化器)修剪,合并层,并将来自多个框架的模型转换为可用于任何英特尔硬件的中间文件(IR文件)。IR 文件包括具有模型拓扑的.xml文件和具有权重和值的二进制 (.bin) 文件。
要进行转换,我们所要做的就是选择我们的精度级别:GPU可以运行FP32或FP16。Intel? Movidius? VPU 以 FP16 运行。CPU 以 FP32运行。为了简单起见,我们将在CPU上运行此演示,因此我们将选择FP32。
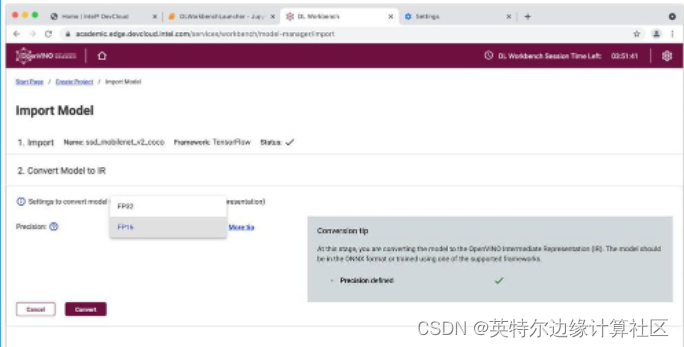
?选择FP32或FP16并进行转换。
第三步:在 DevCloud 中选择目标设备 由于我们通过 DevCloud运行工作台,因此我们可以访问每个英特尔?处理器的架构、英特尔凌动?、英特尔?酷睿?、英特尔?至强?和英特尔? Movidius? VPU。
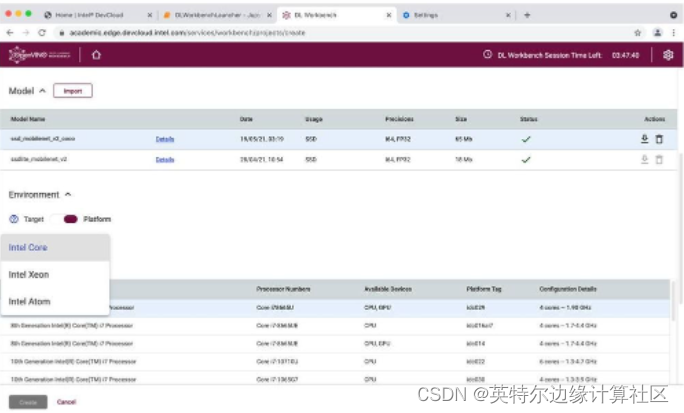
试用英特尔? CPU、集成 GPU、VPU 和 FPGA。
让我们选择英特尔?至强? 6258R(又名Cascade Lake)。它具有英特尔?深度学习加速功能,这将使我们能够在FP32和INT8中运行我们的模型,以实现更快的推理处理。
英特尔?至强? 6258R 具有英特尔?深度学习加速技术,因此我们可以测试 INT8 性能。
?
第四步:获取数据集
现在我们有一个可以运行的模型,我们需要一个数据集进行基准测试。您可以上传自己的数据集
或生成随机数据集。数据集可以注释,也可以不注释。
如果测量模型准确性很重要,则需要一个带注释的数据集。如果您更关心性能或想要执行默认校准,则可以在不进行注释的情况下工作。对于此示例,我们将使用 GitHub 中的 COCO 数据集,而不带注释。
请务必选中“验证数据集提示”。它告诉您如何构建文件并将其存档以进行上传。
注意:您还可以在本地计算机上运行深度学习工作台。本地版本和 DevCloud 版本的功能略有不同。您可以在 OpenVINO? 工具包文档中了解本地计算机上的Dl Workbench 功能的差异。
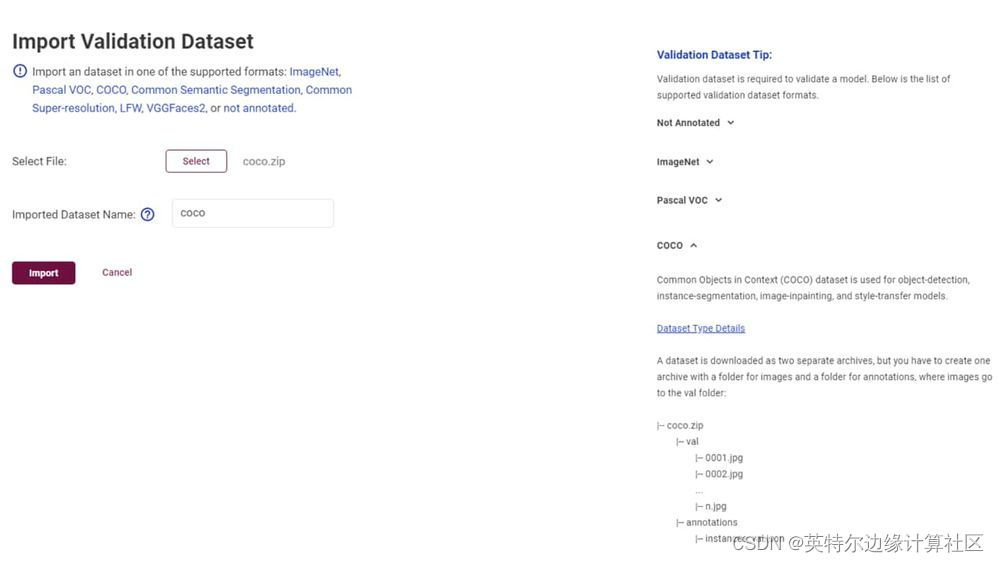
请务必遵循验证数据集提示中概述的目录结构。
第五步:对模型进行基准测试
现在我们开始看看深度学习工作台真正闪耀的地方。我们的第一次测试运行创建了一个包含大量信息的单一基准测试。我们可以看到 nGraph 和运行时图,并解压缩每一层的执行时间。
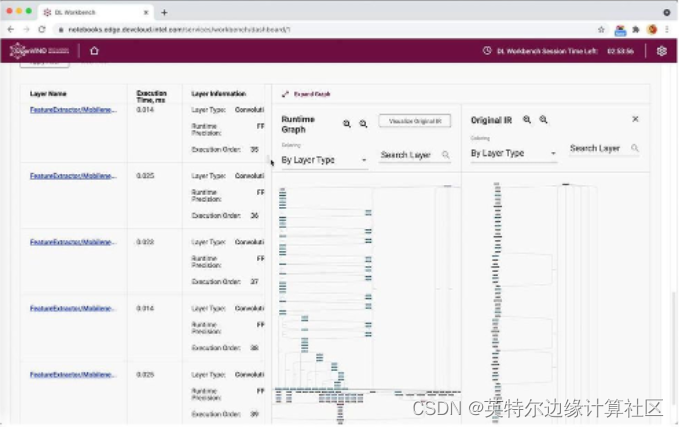
每次测试运行都会创建一个基准测试,其中包含大量的逐层性能数据。
我们可以运行更多测试,包括具有不同批大小和流的组推理,并更广泛地了解模型的性能。
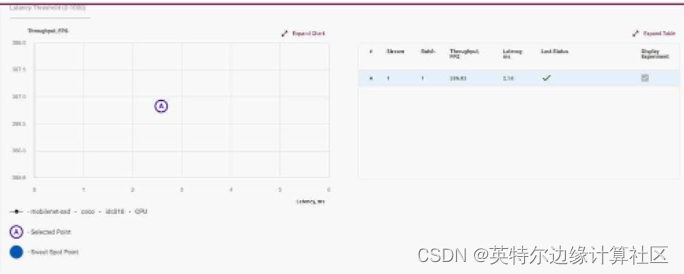
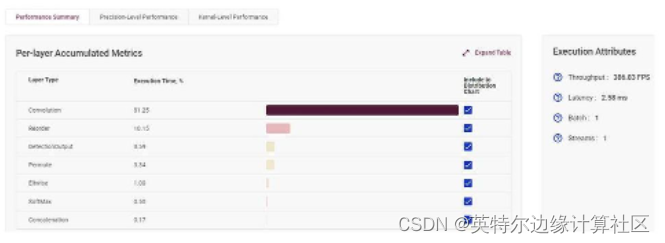
深度学习工作台基准测试提供了广泛的性能数据。
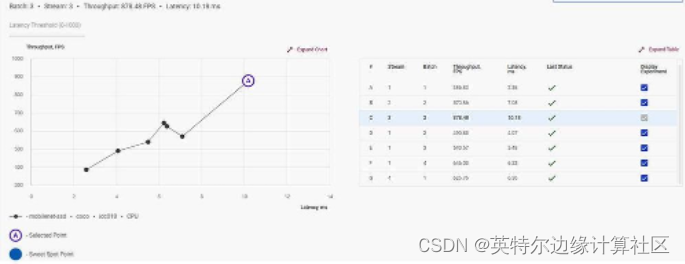
您运行的每个测试都会创建一个新的基准。将性能曲线拖动到目标基准测试,Workbench 将调整模型以达到目标。
第六步:选择性能点
我们所做的每次运行都会? 在性能图上创建一个基准测试,该基准根据吞吐量和每秒分析的图像数(在本例中)绘制延迟(运行推理所需的时间)。
我们可以选择吞吐量和处理速度的任何平衡; 我们所要 做的就是点击一下。工作台将自动创建一个达到该标记的推理配置文件。
下一步 - 第三部分:分析、优化和打包用于在英特尔架构上部署的 TensorFlow 模型
在下一篇文章中,我们将探讨 OpenVINO 深度学习工作台中的一些高级工具,将模型转换为 INT8,并向您展示打包生产就绪型应用是多么容易。

