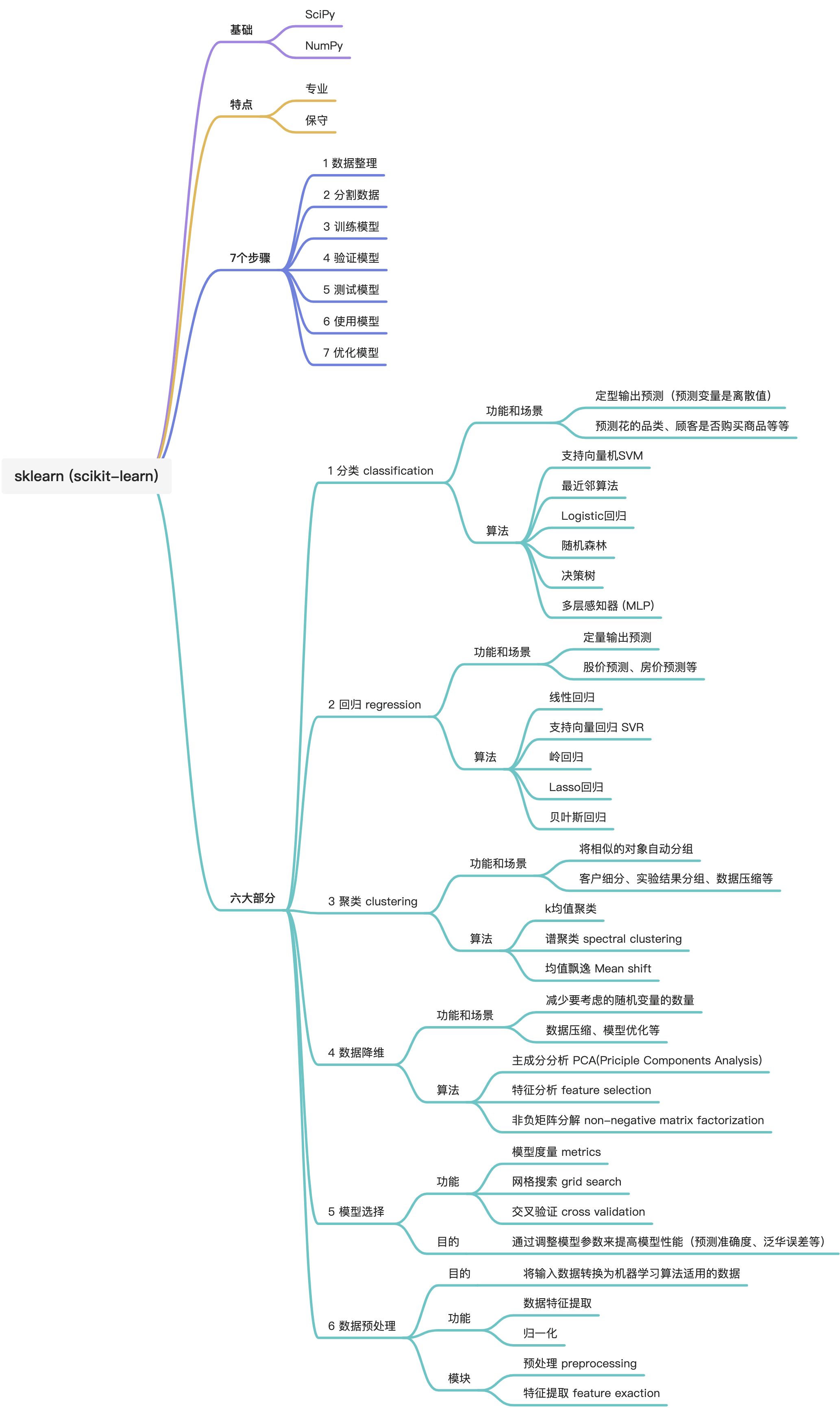
�����ص�ѧϰһ�»ع��㷨
����ѧϰ����
����ѧϰ vs. ��ͳ���

�������
����ʹ�ó�����ͬ,�п��Ի���Ϊ������
�ලѧϰ
�ලѧϰ�Ǹ�����֪�ķ�������,�����������з����Ԥ�⡣
�ලѧϰ�ͺñ�ѧ����ѧУѧϰ����֪ʶ�����۵Ĺ��̡���������������ʦ�ļල�����,��ѧ֪ʶ��Ӧ��������ƽʱ�IJ�����,���ҿ���ͨ���Աȡ������������ϸĽ�����ѧϰ�ɹ�,����һ�εIJ�����ȡ�ø��õijɼ�(Ԥ��Ч��)������Ŀ�IJ�ͬ,�����з���ͻع�(Ԥ��)����:
- ���� ���� ���������������仮�ֵ���֪�����
- �������������,��������������(������)���ൽ��֪��ij�����
- �ع�(Ԥ��)���� ���������������Ԥ�⽫���ķ�չ���ơ�
- ��������������ͷ�չ����,Ԥ�⽫���ķ�չ���ơ�
�Ǽලѧϰ
�Ǽලѧϰ��ලѧϰ�����෴,�ڹ����в����������Щ������ǩ,����ͨ���������Ĺ۲졢�������ܽ�,ȥ�������е�����,�ӿ����������µ������з��ֹ��ԡ�Ȼ������������й��ࡣ
����/����(clustering)���� �Դ����������������������з��ࡣ
������˵�Ǽලѧϰ�ǹ�������(clustering)������ͬ,�����ڻ���֮ǰ����֪������Щ���,�Լ���������,����ͨ���������ĸ����������з���,�����Ƶ���������Ϊһ��,���С�������ۡ��Ļ��֡���һ�������еķ��ֹ��̡�
��ලѧϰ
���ڼල�ͷǼලѧϰ֮�䡣�ǻ��ڼලѧϰ������ۺ�֪ʶ,�ԷǼලѧϰ������(��������ǩ)���з��ࡣ��������Ϊ�����߳�ѧУ�Ժ�����ڿ�����ѧ����֪ʶ������,��������������������з����Ԥ�⡣
Python sklearn (scikit-learn)
Scikit-learn��һ������Python����ѿ�Դ����ѧϰ�⡣
����ѧϰ������
����ѧϰ�ı��ʾ����û���ʹ���ض����㷨���������ݽ��������˵�����ѧϰ(�ҹ���),����ͬ����ģ�Ͷ����������н���Ԥ�⡣���嵽python�е�sklearn,��ͨ��һ��������ʵ�ֵġ�
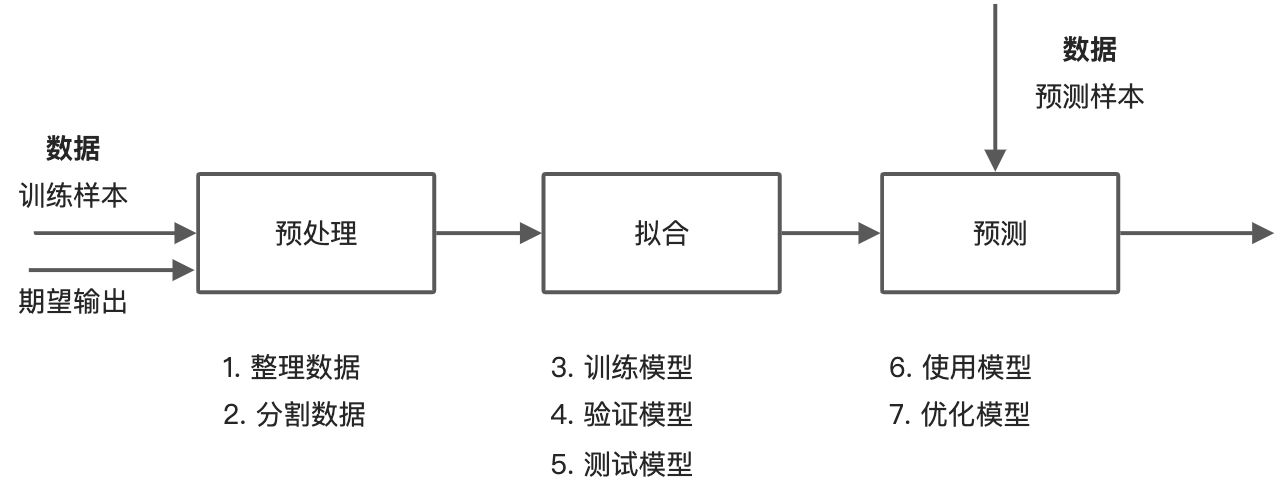
- �����ݡ������������ݽ���Ԥ����
- ѡ��ѵ���Ͳ���ģ�͡���ʹ�ô��������������,����ض�ģ�ͽ�����ϡ�ѵ��
- ģ�͵�ѡ��,���Ը���Ҫ����������ʹ�ó���,scikit-learn�ṩ��һ��ͼ(ѡ����ȷ�Ĺ�����)����ϸ����ģ��ѡ�������,����ָ�����ѧϰ�ļ�����Ҫʹ�ó���,�ع顢����������,�Լ�scikit-learn�ṩ�����ݽ�ά������

- ʹ��ģ��Ԥ�⡪��ʹ��ѵ�����ģ�Ͷ�����������Ԥ��,������Ԥ��������һ���Ż�
scikit-learn (sklearn) ʵ��
sklearn�������˳��õĻ���ѧϰ�㷨��ģ��,�Լ�������Ԥ�����������ֱ���**Ԥ��(����)��(estimator)��Ԥ������(preprocessing)**ʵ��,�������Ǽ̳���ͬһ������Ԥ������
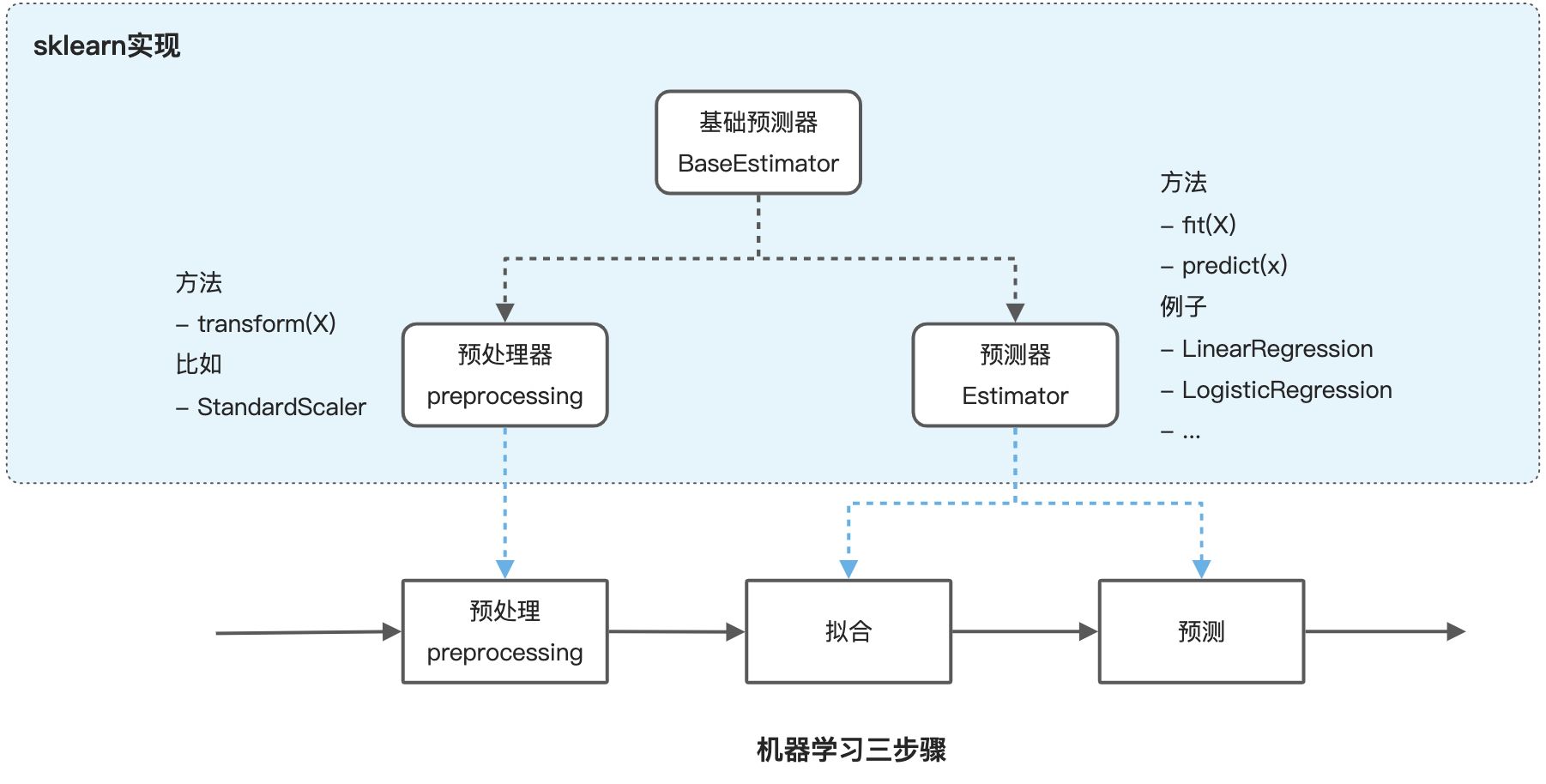
ת������Ԥ������
Ԥ��������ת������Ҫ�����ԭʼ���ݵ�Ԥ������ת��,�Ӷ�������ͬ����֮��ľ��Բ��졣
from sklearn.preprocessing import StandardScaler
# ...
# X = [...]
StandardScaler().fit().transform(X)
Ԥ����
sklearn���ṩ����ʮ�����û���ѧϰ�㷨��ģ��,��ͨ���������ṩ������ͨ��������Ӧ�Ĺ�������ʹ�ö�Ӧ��ģ�͡�
from sklearn.ensemble import RandomForestClassifier
# ��ʼ��������
clf = RandomForestClassifier(random_state=0)
# ʹ��ѵ�����ݽ���ģ�����
clf.fit(X, y)
# Ԥ��
clf.predict(...) #
�ܵ�
�ܵ�������ת������Ԥ������ϳ�һ��ͬһ�Ķ���,��ʾһ����������������������(�ܵ�)��Ȼ��ʹ�ùܵ���fit��predict������ѵ����Ԥ�⡣ͬʱ,ʹ�ùܵ������Է�ֹ����й¶��
from sklearn.preprocessing import StandardScaler # Ԥ������
from sklearn.linear_model import LogisticRegression # Ԥ����
from sklearn.pipeline import make_pipeline # �ܵ�
# �����ܵ�
pipe = make_pipeline(
StandardScaler(),
LogisticRegression(random_state=0)
)
#������...
# ��ʹ��Ԥ����һ��ʹ�ùܵ�
# 1) ѵ������pipeline
pipe.fit(X_train, y_train)
# 2) ʹ�ùܵ�Ԥ��
pipe.predict(X_test)
# ...
ģ������
��Բ�ͬ���͵��㷨��ģ��,��Ӧ����ָ��Ҳ����ͬ��
�ع��㷨ָ��
�ع��㷨�ĺ���˼��������Ԥ��ֵ�۲�ֵ֮���������ԭʼ�IJв�(residual)�����ڲв�ĸ��ֱ���,�Ա��������ѧ����ʹ�����
- Mean Absolute Error ƽ���������:�Բв�������ֵ����,����в��������µ��������
- Mean Squared Error �������:Ϊ�˱�����,��ƽ������������ƽ����
- Root Mean Squared Error ���������:���Ŀ����������ٱ���һ��,���ԶԾ��������п��š�
- Coefficient of determination ����ϵ��:��һ��ȥ�������ٵ�������
�����㷨ָ��
��Ƚϻع��㷨�ĸ��ֲв�ָ��,�����㷨��������ǹ�ע����ľ���,��Ԥ����ȷ����������ռ��Ԥ�������ı�����Ȼ��,Ԥ�Ʋ�ͬ�ij���,�Ӳ�ͬ�Ƕ��������ȶԽ����Ӱ�졣
- Accuracy ����:ÿһ��������Ԥ����ȷ��������ռ�������ı�����
- �������� Confusion Matrix
- ȷ��(����) Precision
- �ٻ���(��ȫ��)Recall
- F�� Score
- AUC Area Under Curve
- KS Kolmogorov-Smirnov
���ڸ���ָ�����ϸ˵��,���Բο�֪����������ѧϰ����ָ����
��������
����Ԥ�������п��Ե����IJ���,Ҳ��������������ָ����ͨ��ѧϰ�õ��IJ�������ʹ�ø��ֲ�ͬģ��ʱ,��Ҫ����������Ϊ�������ݸ�Ԥ������
sklearn���ṩ���ڲ�������������ѳ������ķ���,��������������֤(CV, Cross-Validation)������ȡ��Ӧ�ij�������sklearn����ķ����ǵ���cross_val_score������
�������е��������������ͨ�����������������Ѳ�����
���������Ļ���Ҫ��
- ������������
- ��������
sklearn�����ֳ���������Ѳ����ķ���:
GridSearchCV ������������
��������������в�������ϡ�GridSearchCVͨ��ʹ��param_grid������ָ��������ѡֵ��
�����±ߵ�����ָ����������������ѡֵ��ͨ��GridSearchCV��fitting�ӿ���Ϻ�,������к�ѡ������������,�������Ų�����ϡ�
# ѡ��ģ��
clf = ...
# ָ�����������IJ���
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
# ������������
grid_search = GridSearchCV(clf, param_grid=param_grid)
# ...
grid_search.fit(X, y)
RandomizedSearchCV �����������
�Ӿ����ƶ��ֲ��IJ����ռ��г����������IJ�����ѡ��RandomizedSearchCV����ָ����Χ��,ʹ��ij���ض��ֲ���ȡ����ֵ�������������ֵ���ʽ��ָ�������ľ��������Χ,���ÿһ������,����ָ��
- ����IJ���
- �����ֲ���������ʹ��scipy.statsģ��,���а����˺ܶ�����ֲ�,��expon,gamma,uniform����randint��
- ��ɢѡ���б�
����
# ѡ��ģ��
clf = ...
# RandomizedSearchCV ��������ʾ��
param_dist = {
'C': scipy.stats.expon(scale=100), # ȡֵ�ֲ�
'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], # ��ɢ�б�
'class_weight':['balanced', None] # ��ɢ�б�
}
# �����������
n_iter_search = 20
random_search = RandomizedSearchCV(clf, param_distributions=param_dist,
n_iter=n_iter_search)
# ...
random_search.fit(X, y)
��������(ָ��)
��������Ĭ��ʹ�ù�������score�������������������á�Ĭ��Ϊ
- sklearn.metrics.accuracy_score ���ڷ���
- sklearn.metrics.r2_score Ӧ���ڻع�
��Ȼ,sklearn���ṩ������һЩ���������ɹ����ӳ���ʹ�á�ͬʱ,Ҳ���Խ���������ָ��������ʹ�á�
�ع��㷨
��sklearnģ�����̿��Ժ�����ÿ����ع��㷨��ʹ�ó�����

ʹ�ó���
- ����������50
- ��ҪԤ�⽫����ij����������(�����Ƕ����ݷ���)
Ȼ����������������ݺ�������ǩ���ص�ѡ���Ӧ���㷨
- ����������100Kʱ,�Ƽ�ʹ��SGDRegressor
- ������С��100Kʱ,���Ƽ�ʹ��Ridge, Lasso, ����ElasticNet��;Ȼ�������������������ǩ��Ȩ��,���н�һ��ѡ��
- ����������ݵ�������ǩͬ����Ҫ,����ѡ��RidgeRegression��SVR;
- ����������ݵ�ijЩ��������Ҫ,�Խ��Ӱ�����,����ʹ��Lasso��ElasticNet;
�ع����(Regression Analysis)
�ڸ�������Իع�֮ǰ,��������ҪŪ����ʲô���ع��������ͳ��ѧ��,��ָȷ�����ֻ��������ϱ�����������Ķ�����ϵ��һ��ͳ�Ʒ���������
�����漰�ı�������,���Է�ΪһԪ�ع�����Ԫ�ع�;����������Ķ���,�ɷ�Ϊ�ع���������ػع����;�����Ա����������֮��Ĺ�ϵ����,�ɷ�Ϊ���Իع�����������Իع������
���Իع�(Liner Regression)����
���Իع����Ŀ��ֵ(�����)������ֵ(�Ա���)��������ϡ����Իع�ʹ����ѵ����ֱ���������(
Y
Y
Y)��һ�������Ա���(
X
X
X)֮�佨��һ�ֹ�ϵ���������������,�Ա���������������Ҳ��������ɢ��,�ع��ߵ����������Եġ�
����ѧ��,��Ϊ������ֵ��ɵĶ�Ԫһ�η��̡�
Y
=
b
+
w
1
x
1
+
.
.
.
+
w
p
x
p
+
?
Y=b+w_1x_1+...+w_px_p+\epsilon
Y=b+w1?x1?+...+wp?xp?+?
������Ա�����ʾΪ
X
=
(
x
1
,
.
.
.
x
p
)
X=(x_1,...x_p)
X=(x1?,...xp?),ϵ����ʾΪ
W
=
(
w
1
,
.
.
.
,
w
p
)
W=(w_1, ..., w_p)
W=(w1?,...,wp?),��������Ϊʲô�������Իع��ˡ�
Y
=
b
+
W
T
X
+
?
Y=b+W^TX+\epsilon
Y=b+WTX+?
����
W
W
W�ǻع��ߵ�б��,
w
0
w_0
w0?���ʾ�ع�����Y���ϵĽؾ�,
?
\epsilon
?��ʾ����
�ϱߵı�ʾ��,����Ĭ���Ա�������������Ƕ�Ԫ�ġ�������������������ĸ���Ϊһ��,�����ֱ�ӱ�ʾΪ
y
=
b
+
W
T
X
+
?
y=b+W^TX+\epsilon
y=b+WTX+?
���Իع����ͨ�������㷨ȥ�ҵ�����һ����Ԫһ�η���
y
^
(
x
)
=
b
+
w
X
\hat{y}(x)=b+wX
y^?(x)=b+wX,ʹ�価���ӽ�����ʵֵ
y
y
y(�в�
?
\epsilon
?����С)������ϵĹ���,����ȥ�����Ż����Ʒ��̵�б��ϵ��,����Ҳ�С��ع�ϵ��(coefficient)����
����Ҫע��ģ��ƫ��bias��**�в�(����)**������
- ƫ�� b b b����ָ�ų�����Ӱ����,Ԥ��������ʵֵ֮��IJ��졣����Ҫ����ģ�͵���϶Ȳ������µ�(���������,���ҿ�ͨ��һ�����������̽���Ԥ��)��
- �в� ? \epsilon ?����Ԥ��������ʵֵ֮��IJ��졣��ģ����ȫ��ϵ������,����ʵֵ֮��IJ���,��˿�������Ϊ����(���������Ԥ���)��
Ԥ��ֵ����ʵֵ�ľ���
��ô,��κ���Ԥ���ȷ��,������Ԥ��ֵ
y
^
(
x
)
\hat{y}(x)
y^?(x)����ʵֵ
y
y
y֮��IJ�����?��ֱ�۵ķ������ǿ���ʵֵ��Ԥ��ֵ֮��IJ�(�в�)���ع�ģ�͵�Ŀ�ľ���ʹģ��Ԥ�������ֵ���ӽ���ʵֵ(����ֵ)��
?
^
=
y
?
y
^
(
x
)
\hat{\epsilon} = y - \hat{y}(x)
?^=y?y^?(x)
������ʵ��Ԥ����,�в�ֵ�����и�,������ֱ��ʹ�òв�֮����С�ķ�ʽ������һ�ַ����ĺû���
���,�����ع�����ı���,����ʹ�þ������,��ʹ
D
D
D��Сʱ��
W
W
W��
d
d
d��
D
=
E
(
y
?
y
^
(
x
)
)
2
D=E(y-\hat{y}(x))^2
D=E(y?y^?(x))2
1. �в�ƽ����SSE
���ڲв�������и�,�ʿ���ʹ��ƽ���������������������⡣
d
i
s
t
(
P
i
,
P
j
)
=
��
k
=
1
n
(
P
i
k
?
P
j
k
)
2
dist(P_i, P_j) = \sum_{k=1}^n(P_ik-P_jk)^2
dist(Pi?,Pj?)=��k=1n?(Pi?k?Pj?k)2
����:
- ʹ��ƽ�����Ŵ�(��>1)���ֵ����,ͬʱ��С(-1<��<1)���ֵ����;
- ����ͬά�ȵĶ�������ܴ�ʱ������;
2. ŷ�Ͼ���
Ϊ�˽�����ƽ���͵�����,���ǿ���ʹ��ŷʽ���롣
d
i
s
t
(
P
i
,
P
j
)
=
��
k
=
1
n
(
P
i
k
?
P
j
k
)
2
dist(P_i, P_j) = \sqrt{\sum_{k=1}^n(P_ik-P_jk)^2}
dist(Pi?,Pj?)=��k=1n?(Pi?k?Pj?k)2?
����:
- ����鷳;
- ��ͬ����Ķ�������ܴ�ʱ������;
3. �����پ���
�����پ���ֱ��ʹ�þ���ֵ���������ſ���������鷳���⡣
d
i
s
t
(
P
i
,
P
j
)
=
��
k
=
1
n
�O
P
i
k
?
P
j
k
�O
dist(P_i, P_j) = \sum_{k=1}^n\vert P_ik-P_jk\vert
dist(Pi?,Pj?)=��k=1n?�OPi?k?Pj?k�O
����:
- ������������,�����鷳,���㲻����,ֻ�ܼ��㴹ֱ��ˮƽ����
�ʺϳ���:����ϡ��(�Դ���һ������)
4. ���Ͼ���(Mahalanobis Distance)
���Ͼ����Ƕ�ŷʽ���������һ������,������ŷ�Ͼ����и���ά�ȳ߶Ȳ�һ������ص����⡣
d
i
s
t
(
P
i
,
P
j
)
=
(
P
i
k
?
P
j
k
)
T
��
?
1
(
P
i
k
?
P
j
k
)
dist(P_i, P_j) = \sqrt{(P_ik-P_jk)^T\Sigma^{-1}(P_ik-P_jk)}
dist(Pi?,Pj?)=(Pi?k?Pj?k)T��?1(Pi?k?Pj?k)?
���Ͼ����Ѿ�����ǰ�ߵļ�����ô������,�����Ƶ����̿��Բο����Ͼ�������֮,��ϺõĽ���˲�ͬά�ȳ߶Ȳ�һ������ص����⡣
5. ����
��������һЩ�����纺������(Hamming Distance)���༭����(Levenshtein Distance)��,���ﲻ��һһ˵����
��ͨ��С���˷�(Ordinary Least Square, OLS)
��С���˷�ֱ��ʹ�òв��ƽ������Ϊ������,ͨ�����
W
W
Wʹ�в�
?
\epsilon
?��ƽ������С����ѧ�ϱ�ʾΪ�±ߵ���ʽ:
m
i
n
��
X
w
?
y
��
2
2
min{\Vert Xw-y\Vert _2^2}
min��Xw?y��22?

��sklearn�����Իع�ģ��LinearRegression��,ʹ��
f
i
t
(
)
fit()
fit()�������ģ��,����ģ�͵�coef_�д洢��Ϻ�����ϵ��
w
w
w��
import numpy as np
from sklearn import datasets, linear_model
# ...������,ѡ��������,���ѵ�����������ݼ�..
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# The coefficients
print("Coefficients: \n", regr.coef_)
# The mean squared error
print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))
# The coefficient of determination: 1 is perfect prediction
print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred))
�Ǹ���С����
����С���˷������ص�ϵ����,Ĭ���Dz����ϵ���������������Ƶġ�������ʵ��������,�ܶ�ʱ��������Ҫ���е����ϵ���Ǹ�,����Ƶ�Ρ���Ʒ�۸�ȡ���ʱ�����ֱ������LinearRegression��positive����ΪTrue���������ϵ����������
from sklearn.linear_model import LinearRegression
reg_nnls = LinearRegression(positive=True)
y_pred_nnls = reg_nnls.fit(X_train, y_train).predict(X_test)
r2_score_nnls = r2_score(y_test, y_pred_nnls)
print("NNLS R2 score", r2_score_nnls)
����
��ͨ��С���˵�ϵ�����������������Ķ����ԡ��������������ƾ������֮����н������������ʱ, ��ƾ��������������,��С���˹��ƶԹ۲�Ŀ���������߶�����,���ܲ����ܴ�ķ������,��û��ʵ����Ƶ�������ռ�����ʱ,�Ϳ��ܻ�������ֶ��ع����Ե������
�����(Overfitting)��Ƿ���(Underfitting)
����Ϻ�Ƿ�����ʹ��ʵ�����ݽ��з���ʱ���ܻ����������ֻ������⡣

- Ƿ�������ָģ����ѵ�����еı��־ͺܲ���,�������ܴ�
Ƿ��ϳ��ֵ�ԭ����ģ���Ӷ�̫��,�����Ա���̫�ٵȡ����Ƿ���,Ҫ���ľ�������ģ���Ӷ�,�����Ա���,���߸ı�ģ��(���Ե�������)�ȡ�
- ���������ָģ����ѵ�����б�������,�����Լ��б��ֺܲ�,�������������˾������,��Ϲ���,ģ�ͷ�����������,ֻ�ܹ�������ѵ����,ͨ���Բ�ǿ��
����ϵ�ԭ����ģ���Ӷ�̫��,����ѵ�����ݼ�̫��,�����Ա�������ȡ���Թ����,��������ѵ����������,�����dz��õ�һ�ִ���������
����
- ����(Regularization) �ǻ���ѧϰ�ж�ԭʼ��ʧ�������������Ϣ,�Ա��ֹ����Ϻ����ģ�ͷ������ܵ�һ�����ͳ�ơ�Ҳ����Ŀ�꺯�������ԭʼ��ʧ����+������,���õĶ�����һ��������,Ӣ�ij���?1?𝑛𝑜𝑟𝑚?1?norm��?2?𝑛𝑜𝑟𝑚?2?norm,���ij���L1������L2����,����L1������L2����(ʵ����L2������ƽ��)��
- L1����L2�����Կ�������ʧ�����ijͷ�������ν�ͷ���ָ����ʧ�����е�ijЩ������һЩ�������������Իع�ģ��,ʹ��L1����ģ�ͽ���Lasso�ع�,ʹ��L2����ģ�ͽ���Ridge�ع�(��ع�)��
�������ĸ�����ϸ������Բο���������L1��L2����,�Լ�����ѧϰ��������L1��L2��ֱ��������
��(Ridge)�ع�(L2����)
�����С���˷����ڵ�һ������,��ع������һ�����ͷ���IJв�ƽ������
m
i
n
��
X
w
?
y
��
2
2
+
��
��
w
��
2
2
min{\Vert Xw-y\Vert _2^2}+\alpha\Vert w \Vert _2^2
min��Xw?y��22?+����w��22?
����
��
w
��
2
2
\Vert w \Vert _2^2
��w��22?Ϊ�ع�ϵ��������L2����(���в�����ƽ����)��ʹ�ø��ӶȲ���
��
��
0
\alpha \ge0
����0�����������̶�:ֵԽ��,�����̶�Խ��,��Ӧ�Ļع�ϵ���Թ����Ե����̶̳�Ҳ��Խ������ΪʲôL2�����ܷ�ֹ�����,���Բο���������L1��L2������

��sklearn��,����ͨ��ָ��alpha�������趨
��
\alpha
����
from sklearn import linear_model
# ָ��alpha����ع�
reg = linear_model.Ridge(alpha=.5)
# ���
reg.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1])
# ...
Lasso�ع�(L1����)
Lasso�ع���Ridge��ع�����,��������ͨ��С���˷������ϵ���������Ŀ�꺯������ѧ�ϱ�ʾΪ
m
i
n
1
2
n
s
a
m
p
l
e
��
X
w
?
y
��
2
2
+
��
��
w
��
1
min{\frac1{2n_{sample}}\Vert Xw-y\Vert _2^2}+\alpha\Vert w \Vert_1
min2nsample?1?��Xw?y��22?+����w��1?
����
��
w
��
1
\Vert w \Vert _1
��w��1?Ϊ�ع�ϵ��������L1����(���в�������ֵ֮��)��
����ѡȡ��ѹ����֪
����ѡȡ���Ƕ���������ϡ���ʾ�Ĺ��̡���Lasso���þ��ǹ���ϡ��ϵ��������ģ��,��Ϊ�������ڸ�������ϵ�����ٵĽ�,�Ӷ���Ч�ؼ����˸�������������������������ΪʲôL1�����ܼ��ٸ�������������������,���Բο���������L1��L2������
����˵,Lasso ���������ѹ����֪����Ļ���������ϡ���ʾ,�ο� ����ѧϰ��������ϡ���ʾ��
ϡ���ʾ
����һ���źŶ�������һ�����걸�ֵ���ϡ�����Ա���������,һ���źű��ֽ�Ϊ�����źŵ�������ϵ���ʽ���dz�֮Ϊϡ���ʾ������Ϊ��ʽΪ:
y = D_��_ s.t.||��||0 < ��
Elastic-Net��������ع�(L1+L2����)
��������ع���һ���ۺ���Ridge�ع��Lasso�ع����ֳͷ������ĵ�һģ��:һ��������L1�����ɱ���,����һ��������L2�����ɱ�������Ŀ�꺯����ʾΪ
m
i
n
1
2
n
s
a
m
p
l
e
��
X
w
?
y
��
2
2
+
��
��
��
w
��
1
+
��
(
1
?
��
)
2
��
w
��
2
2
min{\frac1{2n_{sample}}\Vert Xw-y\Vert _2^2}+\alpha\beta\Vert w \Vert_1+\frac{\alpha(1-\beta)}{2} \Vert w \Vert_2^2
min2nsample?1?��Xw?y��22?+������w��1?+2��(1?��)?��w��22?
���ϱߵĹ�ʽ���Կ���,ElasticNetʹ��ʱ��Ҫ�ṩ
��
\alpha
����
��
\beta
����������������
��
\beta
���IJ�������Ϊl1_ratio��
����������������ʱ,�������Ǻ����õġ�Lasso�ܿ��������ѡ����֮һ,������������ܼ����֮��
Ԥ��������������Ҷ˹�ع�
��Ҫ����Ԥ��������:����������Ӧ�����ϵ�����,���Ǹ������ݽ��е�����
��Ҷ˹��ع�
�Զ������ж�-ARD
��ά���ݵ����Իع�
����ѡ��
��ʵ��Ӧ����,�������������dz���,���м�������������Ҫ����Ŀ����ص�����,Ҳ��һЩ��ȫ����ص�����,��������֮��Ҳ���ܴ������������ᵼ�¶�Ӧ��ģ�;�Խ����,ģ��ѵ����Ԥ����Ҫ�ļ�������Խ��,ͬʱҲ��Ӱ���㷨��Ԥ��������
����ѡȡ���ǴӴ�����������ѡȡһ�������Ӽ�,��������õ�ģ��(��в���С)��
����ѡ���Ϊ��������������֤������,����ͼ��

����ѡ��Ĺ��� ( M. Dash and H. Liu 1997 )
1. ��������
�����������������������ӿռ�Ĺ��̡���Ϊһ��3����
- ��ȫ����
��ȫ�����ַ�Ϊ�������(Exhaustive)�ͷ����(Non-Exhaustive)���ࡣ
- �����������
- ��֧��������
- ��������
- ������������
- ����ʽ����
- ����ǰ��ѡ��
- ���к���ѡ��
- ˫������
- ��LȥRѡ���㷨
- ���и���ѡ��
- ������
- �������
- �����������ѡ���㷨
- ģ���˻��㷨
- �Ŵ��㷨
2. ��������
���ۺ���
- �����
- ����
- ��Ϣ����
- һ����
- ������������
3. ������֤
��С�ǻع�(Least-angle Regression, LARS)
��Ը�λ����,��С�ǻع�LARS�㷨������һ������ǰ�ع顣������ǰ��ÿһ����,�������ҵ���Ŀ������ص�������������������ȵ������ʱ,������������ͬ��������������,������������֮��Ƚǵķ�����С�
�ο�LeastAngle_2002.pdf�˽������С�ǻع��㷨�ĸ���ϸ�ڡ�
LARS Lasso
LarsLasso������LARS�㷨ʵ�ֵ�LASSOģ��,����������½���LASSOģ�Ͳ�ͬ,���õ����Ƿֶ����Եľ�ȷ��,��������ϵ�������ĺ�����

����ƥ����(OMP)
һ����������С�ǻع��ǰ������ѡ��,����ƥ���ٿ����ù̶���Ŀ�ķ���Ԫ�رƽ����Ž�����������,����ƥ���ٿ�������ض������,�������ض���Ŀ�ķ���ϵ����
�ο� KSVD-OMP-v2.pdf��
����ݶ��½�(SGD)
����ݶ��½���һ�ּ��ַdz���Ч���������ģ�͵ķ���������������(����������)�dz���ʱ,���ر����á�
��֪�� (Perceptron)
Perceptron ����һ�������ڴ��ģѧϰ�ļ����㷨��������Ĭ��:
- ������Ҫ����ѧϰ��
- ������Ҫ������
- ��ֻ�ô�����������ģ��
���һ���ص���ζ��Perceptron��ѵ���ٶ��Կ��ڴ��к�ҳ��ʧ(hinge loss)��SGD,��˵õ���ģ��ϡ����
������֪�㷨(Passive Aggressive Algorithms)
������֪�㷨��һ�ִ��ģѧϰ���㷨����֪������,��Ϊ���Dz���Ҫ����ѧϰ�ʡ�Ȼ��,���֪����ͬ����,���ǰ��������� C ��
�������Իع�(GLM)
��������ģ��(GLM)�����ַ�ʽ��չ������ģ�͡�
- �������Ӻ���
������Ԥ��ֵ
y
^
\hat y
y^?�Ƿ�ͨ���������Ӻ���
h
h
h���ӵ��������
X
X
X��������ϡ�
y
^
(
w
,
X
)
=
h
(
X
w
)
\hat y(w, X) = h(Xw)
y^?(w,X)=h(Xw)
- ��ʧ����
���,ƽ����ʧ������һ��ָ���ֲ��ĵ�λƫ��
d
d
d������ (��ȷ��˵,һ������ָ����ɢģ��(EDM) )����С��������
min
?
w
1
2
n
s
a
m
p
l
e
s
��
i
d
(
y
i
,
y
i
^
)
+
��
2
��
w
��
2
\min_w \frac{1}{2n_{samples}} \sum_i d(y_i, \hat{y_i}) + \frac{\alpha}{2}\|w\|_2
minw?2nsamples?1?��i?d(yi?,yi?^?)+2��?��w��2?
��
\alpha
����L2���ͷ���ṩ����Ȩ�غ�,ƽ��ֵ��Ϊ��Ȩƽ��ֵ��
����ָ����ɢģ��(EDM)

TweedieRegressor
TweedieRegressorΪTweedie�ֲ�ʵ����һ����������ģ��,��ģ������ʹ���ʵ��� p o w e r power power�����������κηֲ����н�ģ��
- power = 0: ��̬�ֲ��������������,���� Ridge, ElasticNet ���ض��Ĺ�����ͨ�������ʡ�
- power = 1: ���ɷֲ��������������ʹ�� PoissonRegressor ��Ȼ��,����ȫ��ͬ�� TweedieRegressor(power=1, link=��log��).
- power = 2: ٤���ֲ��������������ʹ��GammaRegressor ��Ȼ��,����ȫ��ͬ�� TweedieRegressor(power=2, link=��log��).
- power = 3: ���˹�ֲ���
���䷽ʽѡ��
���䷽ʽ��ѡ��ȡ������ͷ������:
- ���Ŀ��ֵ �Ǽ���(�Ǹ�����ֵ)�����Ƶ��(�Ǹ�),�����ʹ�ô���log-link�IJ���ƫ�
- ���Ŀ��ֵ������,��������б��,�����Գ��Դ���log-link��Gammaƫ�
- ���Ŀ��ֵ�ƺ���٤���ֲ���β������,��ô�����Գ���ʹ�����˹ƫ��(���߸��ߵ�Tweedie�巽��)��
�ο�
- ��SVR�ع���������̡̳�https://zhuanlan.zhihu.com/p/33692660
- ��scikit-learn֧��������/�ع顿http://scikit-learn.org.cn/view/83.html#
- ��SVR֧�������ع顿https://scikit-learn.org.cn/view/782.html
- ��ʹ������������Ժ˵�֧���������ع顿http://scikit-learn.org.cn/view/342.html
- ��ͳ��ѧ�����ع������https://zhuanlan.zhihu.com/p/352694434
- �������ŵ������������Իع顿https://zhuanlan.zhihu.com/p/147297924
- ���ع�ģ��ƫ�����Ͳвhttps://zhuanlan.zhihu.com/p/50214504
- �����Ͼ��롿https://zhuanlan.zhihu.com/p/46626607
- ��Lasso�ع��Ridge�ع������https://cloud.tencent.com/developer/article/1556213
- ����������L1��L2����https://www.cnblogs.com/zingp/p/10375691.html#_label0
- ������ѧϰ��������L1��L2��ֱ�����⡿https://blog.csdn.net/jinping_shi/article/details/52433975

