����������˹��������Ȳв�ĵ�Ŀ��ȹ���
?
Monocular Depth Estimation UsingLaplacian Pyramid-Based Depth ResidualsӢ��ע��:
����������˹��������Ȳв�ĵ�Ŀ��ȹ���Ӣ��ע��-��ҵ�����ĵ�����Դ-CSDN����
Monocular Depth Estimation UsingLaplacian Pyramid-Based Depth Residualsȫ�ķ���PDF:
����������˹��������Ȳв�ĵ�Ŀ��ȹ�����һƪ�����CVPR����-��ҵ�����ĵ�����Դ-CSDN����
Monocular Depth Estimation UsingLaplacian Pyramid-Based Depth Residualsȫ�ķ���:
����������˹��������Ȳв�ĵ�Ŀ��ȹ�����һƪ�����CVPR����-��ҵ�����ĵ�����Դ-CSDN����
ժҪ:�����������������ģ�͵ijɹ�,��Ŀ��ȹ��Ʊ��㷺Ӧ���ڸ��ֱ��������������ṹ�С�Ȼ��,��������������Ľ�������ظ��˼��ϲ�������,����������������ñ��������ĵײ����Խ��е�Ŀ��ȹ��ơ�Ϊ�˽����һ����,���������һ�ּ���Ч�ķ�����������˹����������������ܹ��������˵,�������������벻ͬ�����ж���Ȳв���н���,��Ȳв�ͨ���ֽⶨ�岢����Ӧ����������,�ؽ����ɴֵ�ϸ���������ͼ������ھ�ȷ�ع�����ȱ߽��Լ�ȫ�ֲ������൱��ȡ�ġ����ǻ������Ȩֵ����Ӧ���ڽ������ṹ��Ԥ���������,��Ը����ݶ����кܴ����,�Ӷ�ʹ�Ż������ס��ڸ������ں�������¹����ı����ݼ��ϵ�ʵ��������,������ģ�����,�÷����Ե�Ŀ��ȹ�������Ч�ġ������ģ�Ϳ�����: https://github.com/tjqansthd/LapDepth-release��
ָ����-��Ŀ��ȹ���,��Ȳв�,��ȱ߽�,������˹������,Ȩ�ر�����
����ʵ���������Ӧ����,�ӵ�Ŀͼ�������ȹ���һֱ��һ���ؼ�����������,���������Ϣ��ͳ�ƿ�����Ч�ع�����ʧ���ˮƽ�߽��λ��,����ڿ���������������dz����á���Щ�����ڽ�����ά���β���ʱ������������������,����ƶ������Ϣ���Զ���ʻϵͳ�����ѱ��������Ҫ���������ַḻ�Ŀ�����,�����о���Ͷ���˴�����Ŭ���������Ŀ��ȹ��Ƶ����⡣
������,���������֪���������㷺���á�����,��Ե��������ƺ�Ƶ��ϵ���ķֲ����֪��������������,�Ӹ���ͼ��[1]�ľֲ�������оۺϡ�ȷ�ش���Щ��������ȡͳ����Ϣ,ͨ������ͼ��ָ���ΪԤ��������[2],[3]����һ����,ȫ�ֺ������ļ��ɷ����ڳ���ʶ��[4]��[5]����ȹ����ж��õ������ӡ�����,�м����о���ͼ���ݸ����IJ�ɫͼ������������������;ֲ��ṹ��������ѡ����ʵ����ֵ,Ȼ������Ż�����,��ϸ����ȹ���ͼ��[6],[7]�Ŀɼ��ԡ��������������Щ������Ƶ������ķ����ڹ��������Ϣ����ȡ�����ش��չ,��������Ȼȱ����ƾһ��ͼ���Ԥ����ɫ�����ֵ֮�临�ӹ�ϵ��������
�����������������ģ��(deep neural network, DNN)�ľ�ɹ�,�����о��߿�ʼ����ȹ����������Ϊͼ��ƽ������,���Ӳ�ɫͼ�����ͼ���ƽ�����⡣Ϊ����ȡ�������Ϣ��صĵײ�����,����������(CNN)���㷺������Ϊ����ģ�͵����ɼܹ������ڰ���������ʵ�����Ĵ��ģ���ݼ�,��KITTI�Զ���ʻ���ݼ�[8]��NYU������ݼ�[9],ͨ����ȶѵ��ܹ����Ժܺõر�����ɫ�����ֵ֮��Ĺ�ϵ��һ�������,�����Ϣ��ͨ����ά����������ɨ���(��LiDAR, Kinect��)�������ලѧϰ�����Ļ�������һ����,Ҳ��һЩ�������������������ල�ķ�ʽ���е�Ŀ��ȹ���[10],[11]�� ���ܻ���DNN�ķ�����û���κ�����֪ʶ���������ʾ���˽�ʾ��Ȳ��ֵ�ǿ������,��������Ȼ����ȱ߽����ģ����������˵,���еķ�����������˴�֪������������ȡ������,��VGG��ResNet�ȡ���ЩDZ������ͨ���Գƽṹ�Ľ�����̱������ϲ�������ԭʼ��С,���ת��Ϊ���ͼ������ת�����̺��ѿ��Dz�ͬ�߶Ȳ���϶������ȱ߽�,��˿��ܻ��ڶ���߽�֮�������ȷ�����ֵ��
Ϊ�˽����Щ����,���������һ����ӱ���ĵ�Ŀ��ȹ��Ʒ������÷����ĺ���˼�������û���������˹�������Ľ������ṹ,��ȷ���ͱ����������������֮��Ĺ�ϵ,���ڵ�Ŀ��ȹ��ơ�������˹�������䱣����������[12]�ľֲ���Ϣ�����������㷺Ӧ���ڳ�������ĸ����������ǵ��뷨�ܵ���������˹������������,���ɹ���ǿ���˲�ͬ�߶ȿռ�IJ���,��������߽�߶���ء������˵,��������������ѵ��ľ�����,��ÿ��������������Ӵ���Ȳв���ÿ�������������Ȳв�,�Ӵֵ�ϸ�ij߶��ָ����ͼ���ûָ����������������ȱ߽��Ԥ�����ܡ����Dz�ֻ���ظ��ϲ����������ָ���ԭʼ�ֱ���,���ǽ���������IJ�ɫͼ��IJв���ָ���������,��Щ�в�������������˹�������IJ�ͬ���,�����Ԥ����(����Ȳв�)�ɴֵ�ϸ,���ؽ����յ����ͼ�����ڶ����Ȳв���뷽��,���ǿ��Ը���Ч�����ñ������������Ƹ��ӳ����е������Ϣ������,���ǻ�����˽�Ȩֵ����Ӧ����Ԥ���������,����ڸ����ݶ�����ʹ�����ȶ�������ʧ�����Ƿdz���Ч�ġ�ͼ1��ʾΪ�ñ��ķ���������ȹ��Ƶ�ʵ����������ķ�������Ҫ���ɹ�������:

ͼ1��ʾ:���ϵ���:�����ɫͼ������ʵֵ�ͱ������Ĺ��ƽ����ע��,��ߵ�����ʾ������KITTI���ݼ�[8],���ұߵ�����NYU Depth V2���ݼ�[9]��
?���ǽ������������˹���������������Ŀ��ȹ��Ƶ����⡣�÷���ͨ����������˹��������ͬ��εı�������������Ȳв�ָ�,������Ԥ����,�ɹ��ػָ�����ȱ߽�Ⱦֲ�ϸ���Լ�ȫ�ֲ��֡�
?ͨ����Ԥ����ľ�����(���ǵĽ������ܹ��Ļ���ģ��)����Ȩֵ����,������Ч������ݶ���,�Ӷ������ȶ���ѵ�����������ƴ�ֵΪ�����Ȳв�,��ϡ�����Ȳв
?����չʾ���ڸ��ӵ����ں�������¹����Ļ����ݼ��ϵĸ���ʵ����,��չʾ�������з������,������ķ�����Ч�ʺ�³���ԡ�
���ĵ����ಿ����֯���¡��ڶ����ּ�Ҫ�ع�����ع�����������ķ������ڵ������н��͡��ڻ����ݼ��ϵ�ʵ�����������о������ڵ��Ľڡ������ڵ����֮��
II.��ع���
�ڱ�����,���Ƕ������ĵ�Ŀ��ȹ����о������˱Ƚϻع�,�ɷ�Ϊ������,���ֹ����������ͻ������ѧϰ�ķ�����
A.�ֹ���������
���ڵĹ�����Ҫ�����ôӸ����IJ�ɫͼ���л�ȡ��ͳ���������е�����ȹ��ơ���Ϊ��һ��,Torralba��Oliva[1]������ȱ仯̽���˹������������ʡ�Saxena��[3]����ƽ�沼��(������άλ�úͷ���)Ԥ�����ֵ,��ƽ�沼�ֻ��������ɷ������(MRF),��ϱ�Ե����ɫֵ�ȼ������������������ֵ��Chun����[13]���õ��������λ����Ϣ,���絽��ߴ�¥�����Ծ���,��һ�����ڳ����������ͼ������ķ���������ͨ�����������������Ľṹ���������ҵ�����ͼ����ʵ����ֵ,��Щ�����Ѿ����������������Ϣ��Karsch����[6]���ͨ��������ϵ������������Ѱ�Һ�ѡ���,��ʹ����������(��SIFT flow[14])�������ϸ������[15]��,����רע������ݶ�,Ӧ���ڻ��ڲ��ɵ�����ؽ�,������ֱ����ѵ��������Ѱ����Ѻ�ѡ(����������ͼ��)��Herrera��[16]���û��ڴص�ѧϰ����,��ͼ�����ѵ�������ֵ�ϸѡ��������ȵ����⡣Ȼ��,����patch�ľۺϲ�����������������Ť�����ӳ����ļ��νṹ,���¹��ƽ��ģ����
B.�������ѧϰ�ķ���
�ڳ�ʼ��,Eigen����[17]���������һ������DNN������ģ�͡�������˵,�������Ȼ�����ȵ��Ӿ���������(CNN)Ԥ�����ͼ��Ĵֽ��,�����ֽ����ԭʼ��ɫͼ����Ϊ�ڶ�CNN��������,�Ծֲ�ϸ�ڽ���ϸ������Ȼ�ڱ�����������ڳػ������Ķ���ظ����¹��ƽ��ģ��,������ʾ�˻���DNN�ĵ�Ŀ��ȹ��Ʒ�������[17]�����ܹ���֮��,���ǿ����˸��ֱ�����-�������ܹ�,�Ը�ȷ���ƶϸ���ͼ������ɫ�����ֵ֮��Ĺ�ϵ���ر������������(CRF),�����ֲ�����֮����ͳɶԵķ�ʽ,�ѱ������볬���صķָ��,����߹��ƽ��[18],[19]�Ŀɼ��ԡ�Gan����[20]�����Ͳ�Ƕ�뵽������-�������ܹ���,�Ա����Ч�ؿ��Ǿֲ���ȫ�������ġ�Xu����[21]�����һ����ȼܹ�,ͨ�����ɶ��CRF����,�ں����Զ�߶�CNN����Ļ�����Ϣ����һ����,һЩ�о���Ա̽�����ල���ලѧϰ�����ĵ�Ŀ��ȹ���,ʹ�û��ڲ����һ����,����ͨ�������ؽ���ʧ[11],[10],[22]���㡣�����˵,Garg����[11]Ԥ����ͨ����ȵ��Ӳ�ͼȻ������һ���ӽǽ��м�������,�����ؽ���ʧ��Godard����[10]�����ʹ�ô�Ԥ�����Ť��������ͼ�����һ������ʧ�Ľ��顣Kuznietsov����[22]��ͼͨ��ʹ��ֱ�ӵ�ͼ�������ʧ���Ľ����ƽ��,��ʹ���ڵ�����ʵ���ϡ�������¡����,Fu����[23]��������ع������ȱ߽��������ܼ���ȡ�����ɫ�ռ�������ػ�(ASPP)����[24]��Cao����[25]������������ֵ��ɢ��,����ȹ���������з���,���Ը��ʷֲ�����ʽ�õ�Ԥ�����ͼ�����Ŷȡ���[26]��,���������һ��ѧϰ����,��ʹ������ƥ���㷨���������������ݼ���Ԥѵ���������,Ȼ���õ�����ʵ��ȶ�ģ�ͽ�������Mohaghegh����[27]������һ�����������ķ���,�÷�����Ԥѵ����ģ������ȡ���ͼ��ȫ����ʽ,��ͨ����ͼ���ӳ�䵽���ֵ��ϸ�����ͼ��Zuo����[28]����߶�ǿ������Ӧ�õ�ȫ�ֺ;ֲ��в�ѧϰ�����н��������ǿ�����˴Ӹ����Ķ�άͼ��Ԥ�����ͼ��һϵ�з�����,��ά�����ֱ���ؽ�Ҳ�õ��˻������о���Ma��[29]����˴�ע��ģ���ͨ��-�ռ�������,����Ӧ�ں�ͨ����Ϣ�Ϳռ���Ϣ,��ȡĿ��ķḻ��ʾ��
���ܻ���DNN������ģ���ڵ�Ŀ��ȹ�����ȡ������������������,�����ڽ��뷽��Ч�ʵ���,������ȱ߽紦��αӰģ��,�������ģ����Ȼ���ܳ�����ñ������õ������ĵײ����ԡ���Щ������Ҫ�Dz��ø��ַ����������Ϣ���дӴֵ�ϸ��Ԥ�⡣Ȼ��,�������ͼ���������յĿռ�ֱ��ʹ���,���������Ȼ���������ر�����ͬ����������������ȱ߽硣����Щ������ͬ����,���ǽ����ڽ��������Ӧ��������˹������,ͨ����ͬ�ij߶ȿռ��ָ���ȱ߽硣
III.���᷽��
��������ķ���ּ��ͨ���ڽ��������Ӧ�û���������˹�������ķֽ⼼��,�ɹ��ػָ��ֲ�ϸ��(����ȱ߽�)�Լ���ȵ�ͼ��ȫ�ֲ��֡�����,�����ɫͼ��������˹�в�����������ɰ����ֲ�ϸ�ڵ���Ȳв�,�����ʵ��ر�ʾ��ͬ�߶ȿռ��������ԡ�Ϊ����߽���Ч��,���ǻ���Ԥ��������������Ȩֵ����,�����Ȳв�Ĺ����ṩ�˺ܴ�İ���,��Ȳв��ֵ���Ϊ�㡣�ڱ�����,�������Ƚ�������������ڵ�Ŀ��ȹ��ƵĽ�����������ܹ���Ȼ��,��ϸ��������Ȩ�ر����������µ�����������̡����,���ǽ���������ѵ�����������ϵ�ṹ����ʧ������
- ģ��ϸ��
�÷���������ṹ��ͼ2��ʾ�����ǵ�������Ԥѵ���ı���������������ڻָ���Ȳв�Ľ�������ɡ����������ֿ���ʹ���κμܹ�������,��:VGG [30], ResNet [31], DenseNet[32]�ȡ������ǵ�ʵ����,���Dz�����ResNext101[33],���������Ԥѵ��,����ͼ����ࡣ�ڱ�������,����IJ�ɫͼ��ͨ����ȵ��ӵľ����鱻�߶�ѹ��ΪDZ����������Щ�����Ŀռ��С��÷dz�С(�����ǵ�ʵ������ԭʼ�ֱ��ʵ�1/16),Ȼ��,��Щ�������յذ�����Ƕ��ռ�����ɫ�����ֵ֮��Ĺ�ϵ,���ǴӲ�ͬ�ij���������ѧϰ�ġ�Ϊ�˸��ܼ��ػ�ȡ��������Ϣ,���Dz���DenseASPP����[34],�������ľ��������3��6��12��18�����������ʡ�
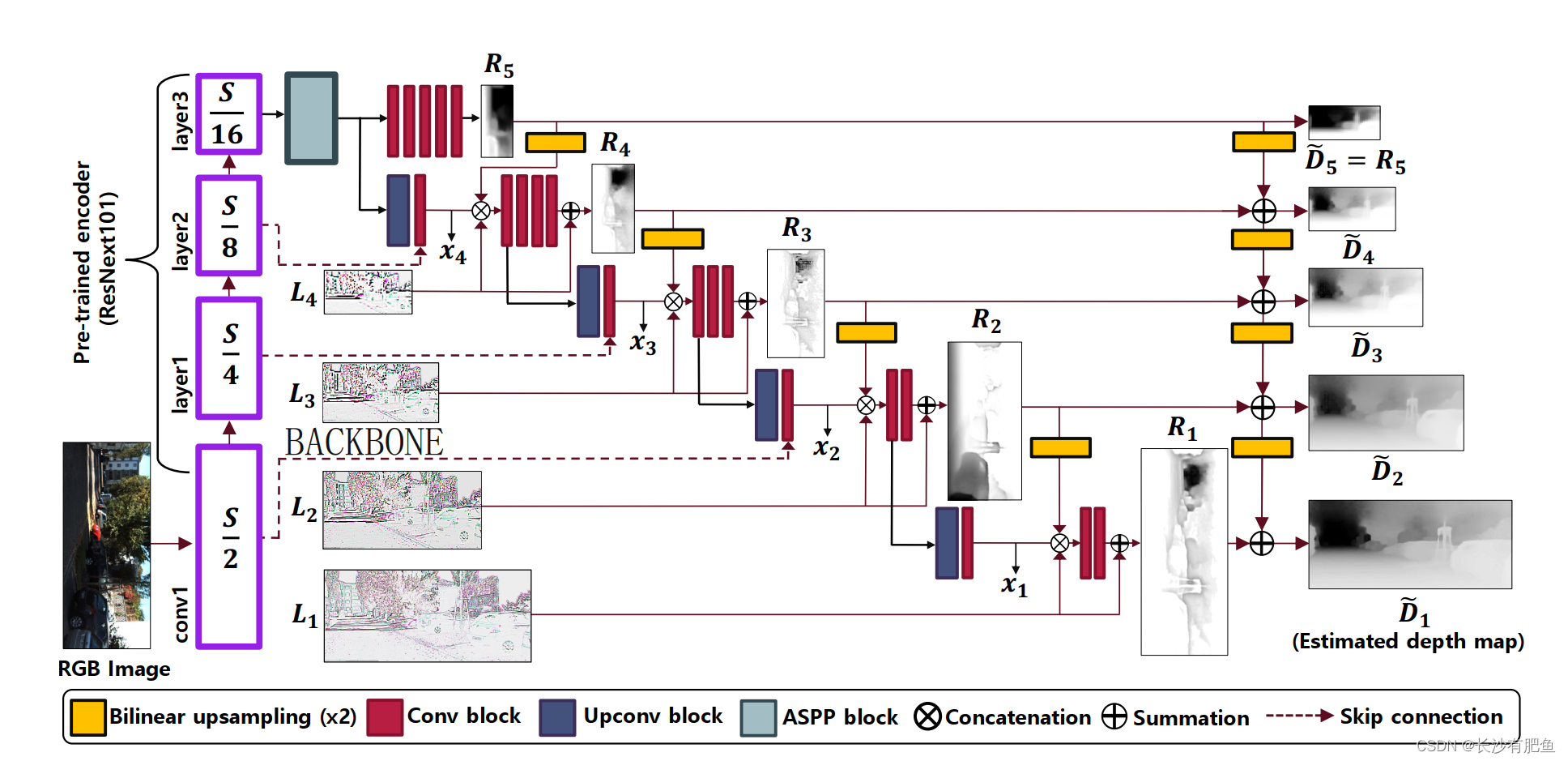
ͼ2��ʾ.����ĵ�Ŀ��ȹ��Ʒ���������ṹ��S��ʾ����ͼ��Ŀռ�ֱ��ʡ���Laplacian����������߲�μ�R5�ָ�����Ȳв�ϲ���(��2),���ʹ�����ӷ����ϸ�߶ȵ���Ȳв����ϡ���ע��,Ϊ�˸��õ���ʾ,��������IJ�ɫͼ����,����ͼ���ֵ�����ͼ�ж��ǵ��õġ�
��������������Ϊ������˹�������Ķ����֧��һ����֧,������߲�ε�������˹������(�μ�ͼ2�е�Layer4) ִ�н�������ָ����ͼ��ȫ�ֲ��֡�������֧������Ȳв�(ͼ2�д�R4��R1),DZ�����������ɫͼ���Ӧ�߶ȵ�������˹�в�(ͼ2�д�L4��L1)����������Ȳв����м����ͼ���,�м����ͼ���������ӷ���������˹�������ĸ��߲�λ�õ��������ͼ2��ʾ,�����������������˹���������н�����̡������������о�������˲�����С��Ϊ3 �� 3�����᷽���Ľṹϸ��Ҳ���һ��ʾ������������̽�����һС���н��н��͡�
TABLE I
(UP:�ϲ�������,CHANNEL:ÿ������������ͨ����,IN��OUT:��������Ŀռ�ֱ���,INPUT:ÿ���������,LEV:������˹��������ˮƽָ��)
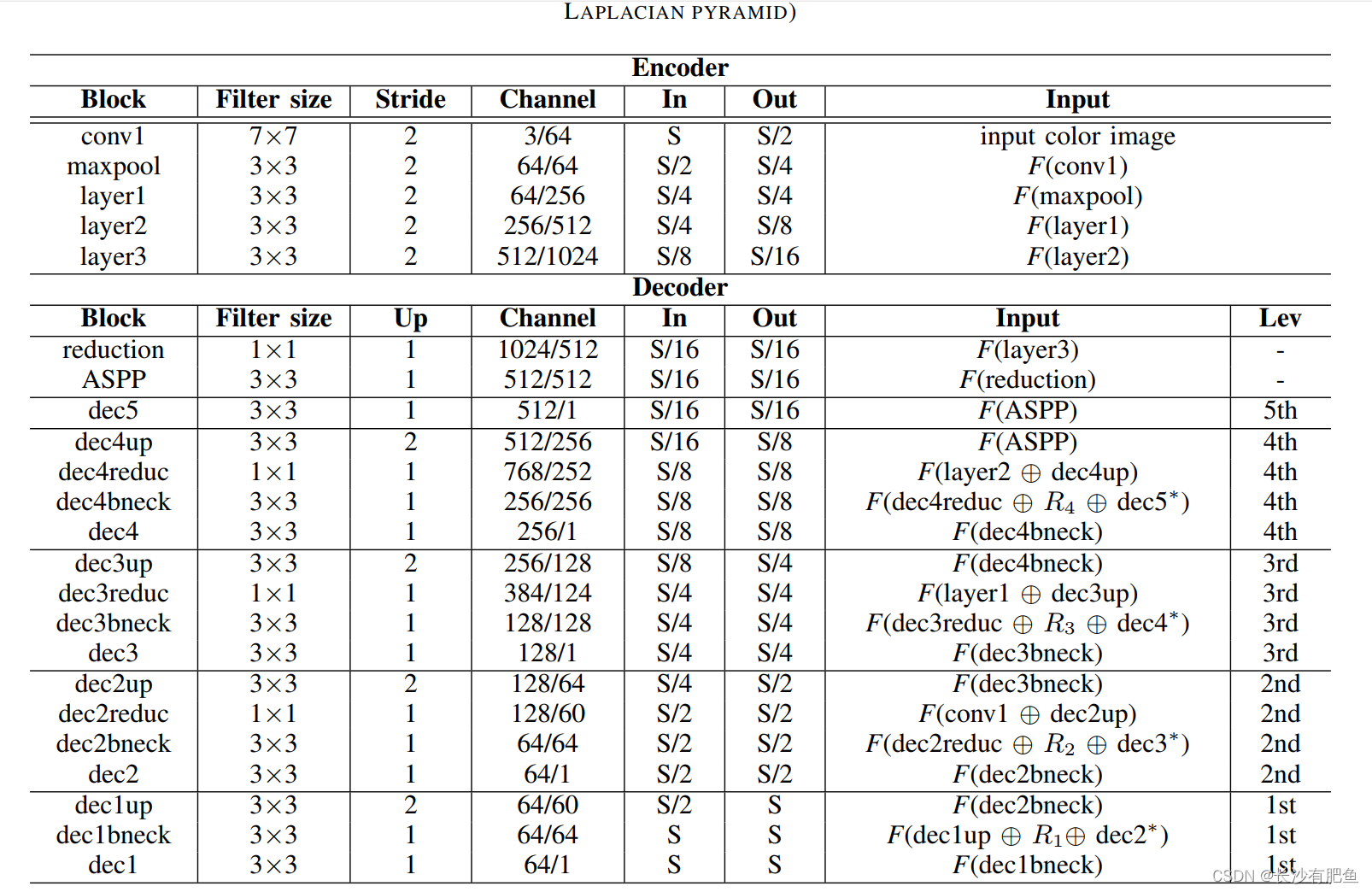
ע:����*�ֱ��ʾƴ�Ӻ��ϲ���(��2)��S��ʾԭʼͼ��Ŀռ�ֱ��ʡ�F(B)��ʾ��Ӧ��B�������
- ��Ȳв����
����,���Ǽ�������IJ�ɫͼ���������˹�в�,��Lk,����:
Lk = Ik - Up(Ik+1); k = 1; 2; 3; 4; (1)
����k��ʾ������˹��������ˮƽָ��. Ik�Ƕ�ԭʼ����ͼ������1/2k-1�����õ��ġ�Up(��)��ʾ�ϲ�������(��2),���Ƕ����᷽���е����е�����С���̶�����˫���Բ�ֵ������,��RkΪ��k��������õ�����Ȳв�,����Ȳв�����ɷ�������: ����,��DZ������xk����Ȳв���ϲ����汾Lkƴ��,��������˹�������ĵ�(k + 1)���õ�(��ͼ2)�����,��Щƴ�ӵ�����������ѵ��ľ�������,��Ӧ����������ؼ����ٴ����ӵ�Lk�С�������̿��Ա�������:
Rk = Bk([xk; Lk; Up(Rk+1)]) + Lk; k = 1; 2; 3; 4; (2)
����[xk; Lk;Up(Rk+1)]��ʾxk��Lk��Up(Rk+1)��ƴ�ӡ�Bk�ɵ��ӵľ��������,�����ĵ�ͨ������Ŀռ�ֱ�����Lk��ͬ��ֵ��ע�����,Lk�����������ȷ��ԭ���ֳ߶ȿռ�ľֲ�ϸ��,�Ӷ��ڲ�ģ������������¶Խ�ʾ��ȱ߽��кܴ���������,��������˹����������߲�����ؽ����ͼ,������ʾ:
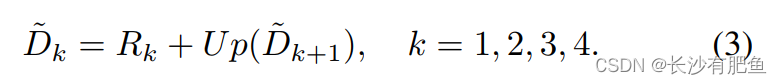
ע��,D~5����ΪR5, R5���������ͼ����߽��������ȫ�ֲ���,��ͼ2��ʾ��ͨ����������(3),��Ϊk =4-->3 -->2 -->1, D~1����Ϊ���յ����ͼ��ͼ3��ʾ���ڵ�k����������κ��������ͼ�����ɵ���Ȳв�����ӡ����Կ���,�ڲ�ͬ�߶���Ԥ�����Ȳв�ܺõؽ�ʾ�˸��ݳ������ε�������ԡ�

Ϊ��ʹ��Ŀ��ȹ��ƵĽ�����̸���Ч,���ǻ������Ԥ����������н��м�Ȩ����,�������������������Ļ���ģ��,��ͼ4 (c) ��ʾ���������ͼ�ǻ�����Ȳв�ĵ�������ؽ���(��(3)),���Ԥ�����Ȳв�Ӧƽ�������ֵ����ֵ,���ȶ���ȷ�ع��������Ϣ�������͵ľ�����,����convolution--->normalization--->activation,��ͼ4(a)��ʾ,�����һ�����������Ե�Ԫ(ReLU)����ķ�����������,�����˴ָ�ֵ�����ܲ�����Ԥ���������[35]��������һ����(��ͼ4(b)),������Ȳв���ϡ���(������Ȳв�Ϊ��,��ͼ3��ʾ),�����˲�����Ȩֵ�ڱ仯��С���������Ȼ�����㡣����ܻᵼ��ѵ�������г����ݶ���ʧ���⡣
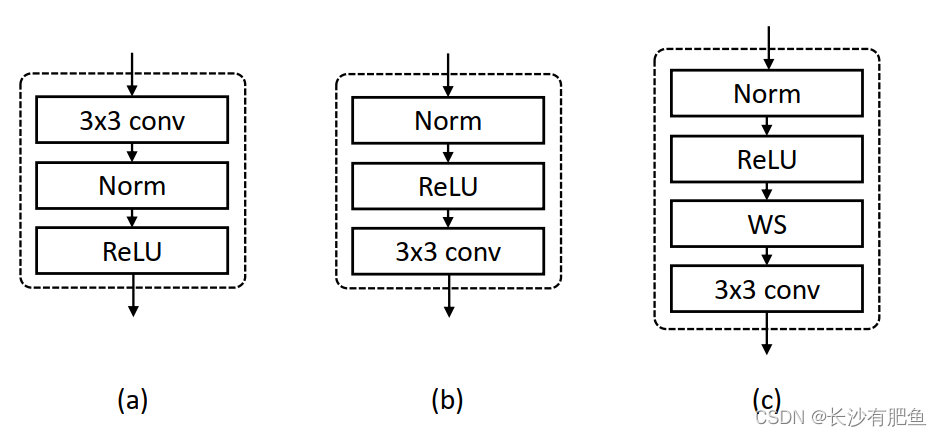
ͼ4��ʾ.(a)���͵ľ����顣(b)Ԥ���������[35]��(c)��Ȩ������Ԥ��������顣ע��,WS��ʾȨ�ر�����
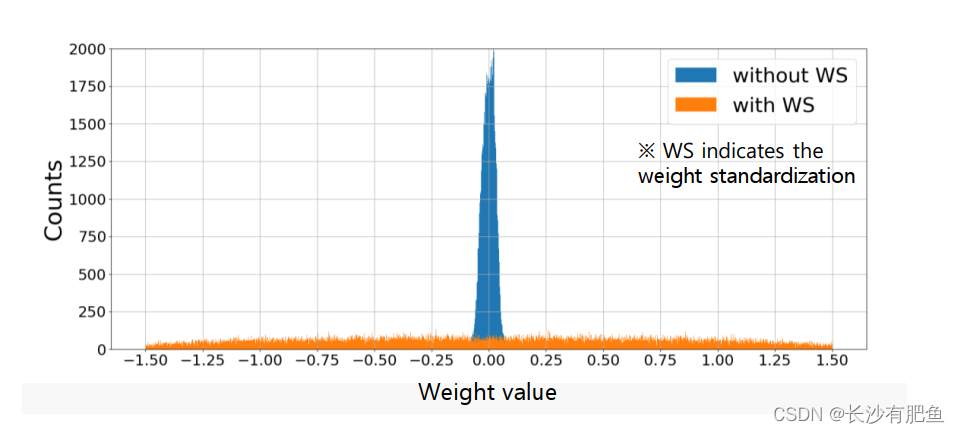
ͼ5��ʾ.���һ�����ڹ���R1�ľ������е�Ȩ�طֲ���ͼ2��ʾ��ע��,����conv(��deconv)����ʾ�����Ƶ�Ȩֵ�ֲ���
ͨ���ڽ��о�������֮ǰ�ط���Ȩ�ر���[36]ģ��(��ͼ4(c)),��������Ľ���������ͨ�����������еĹ�һ�����ɹ�������ݶȵ�����,�������̴�������˹��������ÿһ������õ��ݶȡ�����ڱ��ֻ��ڲв���Ϣ����ɫ-���ת�����ȶ������൱��ȡ�ġ�ͼ5��ʾ��Ȩ�ر����Ե�Ŀ��ȹ��Ƶ�Ӱ�졣��������,��������ķ�����,Ȩֵ�ֲ��㷺������,�������Ȩֵ��û��Ȩֵ����������±������㸽����ͬ��,��ǰ�ľ��������ⷽ��ͨ���Թ�����Ȳв�û�а�����ͨ��������һ���ƺͻ���������˹�������ķֽⷽ��,��Ϊ����ķ������Գɹ���ѧϰ��ɫ�����ֵ֮��ĸ��ӹ�ϵ��
C .��ʧ����
�������ǵ���ʧ����Lt������Ŀ�ѵ�����������Ż�,����ʧ������������ʧLd���ݶ���ʧLg���������,������ʾ:
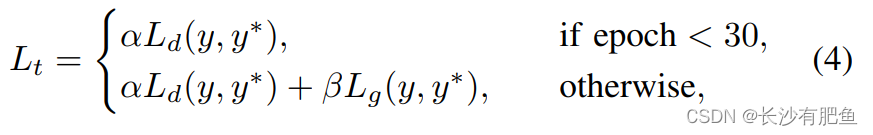
����y��y?�ֱ��ʾԤ������ӳ��͵�����ʵֵ����������ʾLd�͵�ƽ������L g,ͨ������ʵ��ֱ�����Ϊ10��0.1��ע��,�ݶ���ʧ����30��epoch֮������,��Ϊ��ѵ����ʼʱ,���ڵ�����ֵ��ϡ����,ͬʱʹ�����ݺ��ݶ���ʧʱ,KITTI���ݼ��е�ѵ���������ȶ���������˵,�ɲ�ֵ���ͼ���������ݶ���ԭʼ���ͼ���в�ͬ,������������ʧ��������Ϊ�˻�����һ����,ֻʹ��������ʧ�����ʵ������ͼ�ָ���,�ٶ�������ݶ���ʧ��
1)���ݶ�ʧ:һ�������,����3D������������,������ɼ���������ݱȽ��ܼ�,�������Զ��������ݱȽ�ϡ�衣Ϊ�˻��ⲻƽ�������,���Dz���[17]���������ʧ������ƽ������Ϊ������ʧLd,������Ԥ�����ֵ�������ʵֵ����־�ռ��еIJ�ֵ,����:
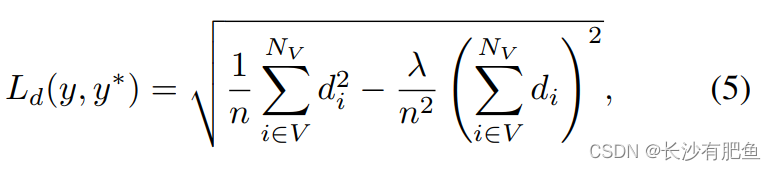
����di = logyi?logyi *, V�����ͼ�е�һ����Ч���ء�NV��ʾ��Ч���ص�������������[37]��ͬ�ķ�����ƽ������������Ϊ0.85��
2) �ݶ���ʧ:Ϊ����ǿ�ֲ�ϸ��,�ر�������ȱ߽�,�����������ͼ���ݶ���Ϊ��ʧ���������ڵ�����ֵ��ϡ���������,��ˮƽ����ʹ�ֱ�����ϵ��ݶȶ����Ծ�ȷ����,��˵��ֵ���������������г��õ�[9]�ṩ��Matlab���߰����ݶ���ʧ��ʽΪ:

ʽ��m(��)Ϊ[9]��ʹ�õIJ�ֵ������yh,i��m(y?)h,i�ֱ��ʾ�������ͼ�ĵ�i���ݶ�ֵ����ˮƽ�����ϲ�ֵ�ĵ�����ֵ����֮����,yv,i��m(y?)v,i�ڴ�ֱ�����϶�����NΪ�������ͼ�а���������������ֵ��ע�����,���ǵ��ݶ���ʧ��һ��Ӱ��,��ʹ�ֲ���Ե�ڶ��ν�������ȷ����,�Ӷ�ʹ��ȱ߽��������ʾ�����յ����ͼ�����Կ���,�����ݶ���ʧԤ������ͼ�ɹ��ؽ�ʾ��Զ���������ȱ߽硣

ͼ6��ʾ�����ݲ�ͬ����ʧ�������,��ȹ��ƽ�����Ӿ��Ƚϡ�(a)�����ɫͼ��(b) Ld. (c) Ld + Lg��(d)������ʵֵ��ע��,�ݶ���ʧ����������ȱ߽��ϵõ����ɿ��Ľ����
IV.ʵ����
�ڱ�����,����ͨ���������㷺ʹ�õĻ����ݼ��Ͻ��еĸ���ʵ�����������᷽��������,��KITTI[8]��NYU DepthV2[9]���ݼ�,�ֱ��ڲ�ͬ�����ں�������¹�����
- ѵ��
�÷�����PyTorch���[38]��ʵ�֡�������Ľ����������в���(������Ȩֵ)����[39]������IJ��Խ��г�ʼ��������Ľ�������ÿһ�㶼�������һ��,������֪�Ķ���������С����������СΪ16��50��epoch,ʹ��AdamW�Ż���[40],ֵ�Ͷ�������Ϊ�ֱ�Ϊ0.9��0.999����������Ȩ˥��������Ϊ0.0005,�����������Ȩ˥��������Ϊ�㡣ѧϰ����������Ϊ10?4,Ȼ��ͨ������ʽ˥��0.5����ֱ��10?5��ʹ��4��NVIDIA GeForce Titan Xp GPU��������������ѵ����Ҫ16��Сʱ����������ResNext101[33]��Ϊ������ȡ�ı�����,����ILSVRC[41]���ݼ�,ͨ��Ԥѵ��ģ�ͳ�ʼ����������������������ǰ����IJ���,��Ϊ��Щ�㾭�����õ�ѵ��,����ͨ��ʹ�ò�ͬ����Ȼͼ������ȡ�ײ�����(����,��Ե,�����)����������������������һ����IJ���Ҳ�̶�ΪԤѵ��ֵ���������ͽ������IJ�����С�ֱ�Ϊ58M��15M��
��ѵ����,�����ݽ���������ǿ�Ա����������⡣������˵,����KITTI���ݼ�,ѵ������������ü�Ϊ704 �� 352����,����NYU Depth V2���ݼ�,ѵ������������ü�Ϊ512 �� 416����,Ȼ����[- 3,3]�ȷ�Χ�������ת���ǡ�����ͼ��Ҳ��0.5�ĸ���ˮƽ��ת������,�����ɫͼ������ȡ���ɫ��gammaֵ�����������,��������ѡ����[0.9,1.1]��Χ�ڡ�
- �����ݼ�
1) KITTI: KITTI���ݼ�[8]�����Զ���ʻ������ȡ�ĸ��ֵ�·��������õ�ͼ��ֱ���Ϊ1242 �� 375���ء�Ϊ�˽������ܱȽ�,���Dz�����Eigen��������IJ�ֲ��ԡ����ݸ÷���,���Լ�������29��������697��ͼ�����,��ѵ��������������32��������23488��ͼ����ɡ�����Ԥ����������ֵ�ڲ��Խ�������80������,��KITTI���ݼ�˵���н��͵����������ǻ�������[11]�в��õ����IJü����������������ۡ�
2) NYU Depth V2: NYU Depth V2���ݼ�[9]��120K��RGB�����ͼ�����,��Щͼ����ʹ��Microsoft Kinect��������464�����ڳ����²����,�ֱ���Ϊ640 �� 480���ء�����Ӧ����֮ǰ��ѵ��/���Էָ�,���а���249������ѵ���ij�������������215��������654�����ڲ��Ե�ͼ��,����[17]�н��ܵ�����������RGBͼ��Ͷ�Ӧ�����ͼû����ȫͬ��,���Ǵ�249�������д���ѡ��36253����������ѵ�����ø÷���Ԥ������ͼ�������IJü�561 �� 427����(��[8]�������)�����з������бȽϡ�
C.��������
Ϊ��֤���÷�������Ч�Ժ�³����,���������������ݼ��Ͻ�������������,��KITTI[8]��NYU Depth V2[9]���ݼ�������,�����Ƚ��ķ������ж��ԱȽϵļ��������ͼ7��8��ʾ���������,�����ķ��������ȷ����ϸ����ı߽�,��ͼ7�еĽ�ͨ��־�����е��ϵ����ӵȡ���ijЩ������,��������״��������ģ��,[22],[23]��������[37]������߽���Ƶúܺ�,���÷�����Ȼ������Խϸߵ�λ�ó���ģ��(��ͼ7�е�����ʾ���Ľ��)�����֮��,�÷����ܹ��ɿ����ṩ���ֵ�·�����¾���������ȱ߽�����ͼ�������ڻ�����,�ڽ϶̵ľ���������϶�,�����ȱ߽�������߽�Ĺ�ϵ��ǿ,��ͼ8��ʾ�������ķ���������������벻������ȱ仯,�ڸ������帴�ӵı߽���ʹ���ƽ��ģ�����ر�����ͼ8�ĵ�1�͵�3��������,������ģ�Ͷ����ܱ������ֵ��ͬһƽ���ڵľ����ԡ�����,�����ĸ����������������ķ���Ԥ�����(��ͼ8���һ�������еĵ�������)��
�ڶ������۷���,���Dz�����Eigen����[17]�����6��ָ��,��6��ָ���ڵ�����ȹ��Ƶ�����������Ӧ����Ϊ�㷺,��������:
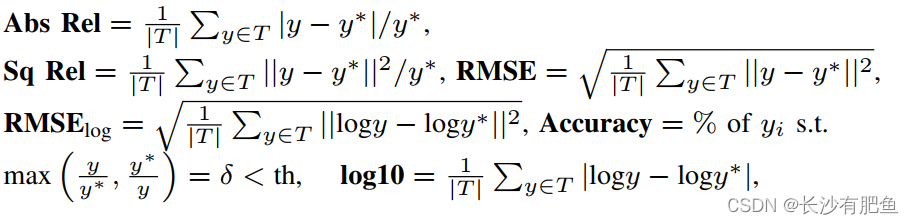
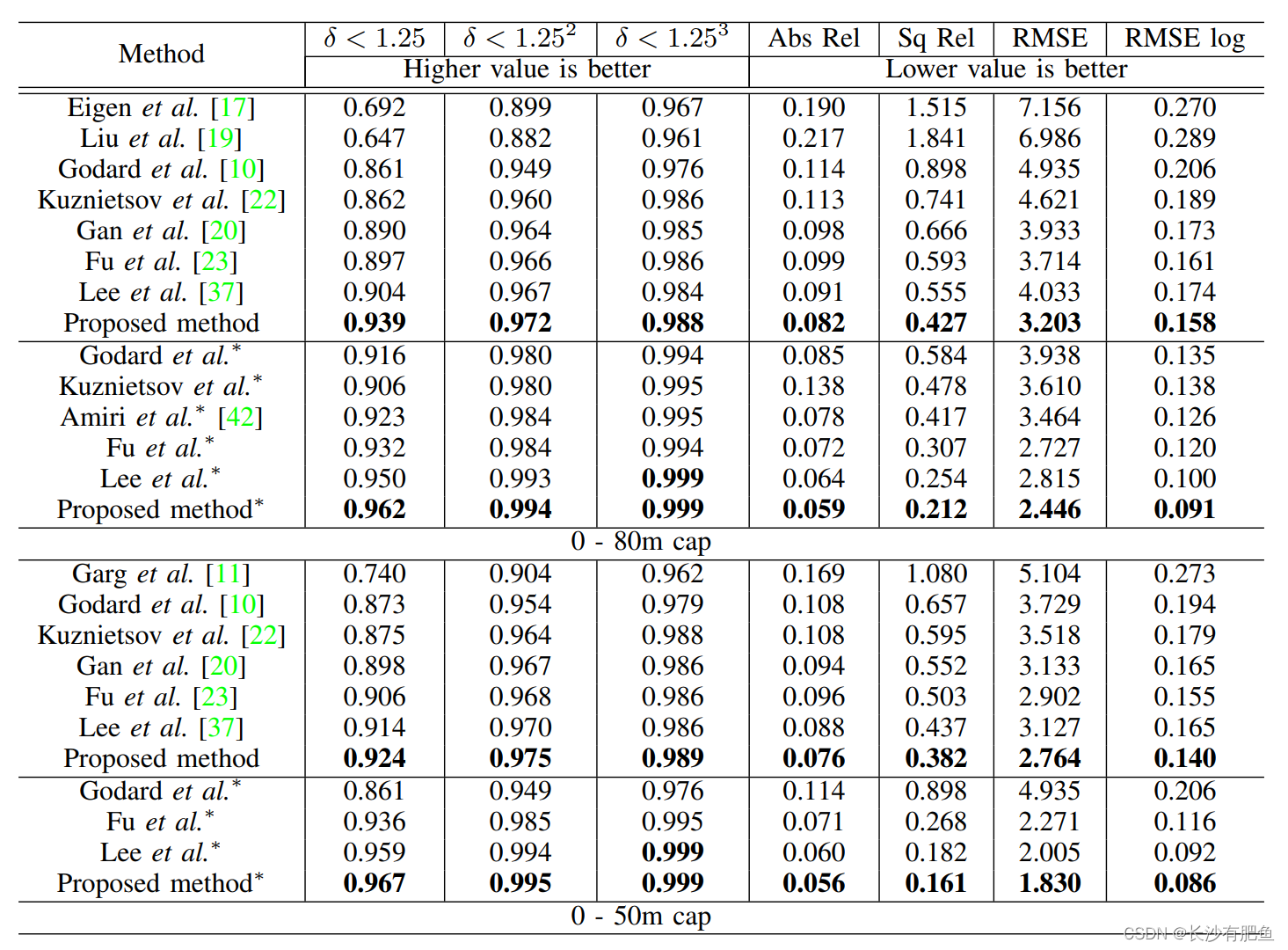
����y��y?�ֱ��ʾԤ������ֵ�͵�����ʵֵ��T��������ʵֵ����Ч���ص�������������Щָ��,������KITTI[8]��NYU Depth V2[9]���ݼ��������µķ��������˱Ƚ�,��Ӧ�Ľ���ֱ����II�ͱ�III��ʾ��ע��,��������ķ��������������ԭʼvelodyne���ݺ�KITTI���ݼ�����������Ĵ���ע�ĵ�����ʵ���ݽ��������ġ�����ʹ��652�Ų���ͼ����������ע���ground truth(��45�Ų��߱���Ӧground truth��ͼ����в���)����������,���ǵĽ����50m��80m��������ȡ������õ�����,���II��ʾ������,���ķ�������NYU Depth V2���ݼ����ṩ�˿����Ĺ��ƽ��(����III)�����,������Ϊ����������˹����������Ȳв���ڴӸ������ں�������л�ȡ�IJ�ɫͼ����ȷ���������Ϣ����Ч�ġ�����,�÷����Ĵ����ֱ���Ϊ1242��375�������ٶ�ԼΪ32 fps,��˿���Ӧ���ڸ���ʵʱӦ�á�

ͼ7��ʾ.��KITTI���ݼ�[8]�ϵ���ȹ��ƽ������1��8��:�����ɫͼ��2�к͵�9��:������ʵֵ����3��10��:Godard et al. [10]���������4�к͵�11��:Kuznietsov���˵Ľ������5��12��:Fu���˵Ľ������6��13��:Lee���˵Ľ������7��14��:���ķ����Ľ����

ͼ8��ʾ.��NYU depth V2���ݼ�[9]�ϵ���ȹ��ƽ������һ��:�����ɫͼ�ڶ���:������ʵֵ��������:Laina et al.[45]��������:Fu��[23]�ⶨ�������5��:Lee���˵Ľ����������:���ķ����Ľ����
��II
��KITTI���ݼ�[8]��ʹ��EIGEN����[17]�IJ��Էָ�Բ�ͬ��CAPS���ж������ۡ�?��ʾʹ�ùٷ���ע�ĵ�����ʵֵ(Ĭ��ֵ:ʹ��ԭʼvelodyne����)���������ܡ�ע������ʹ��GARG���˽��ܵIJü�����
ע��:�Դ����ı�ͻ����ʾ������ܡ�
��II
ŦԼ��ѧ���v2���ݼ�[9]�Ķ�������

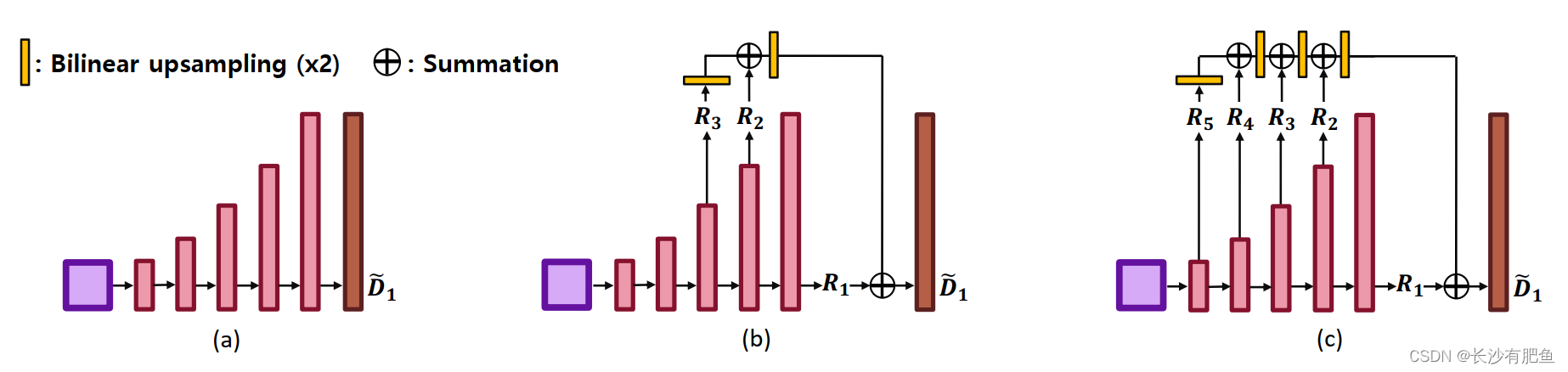
ͼ9��ʾ�����ݽ�����������Ľ������ṹ�ı仯��(a)������ (b)����(c)�弶(���᷽��)��ע��,D~1��ʾ���յ����ͼ��
D. ����ʵ��
���ڽ���KITTI���ݼ��Ͻ��жԱ�ʵ��,��֤�����ܵ���Ч��,������������˹�������Ľ������ͻ���Ȩֵ������Ԥ��������顣ͼ9��ʾΪ�������ṹ���ݲ�ͬ������������ı仯��ע��,�ǽ�������������ͼ9�ͱ�4û����������˹���������������в���4��ʾ,ʹ�ø���IJ����������ֽ�Ϊ������˹������,�����ھ�ȷ�ָ��ֲ�ϸ��,Ҳ���������ͼ��ȫ�ֲ��֡�Ϊ������ͬ�������½���ʵ��,����6����7��������˹�������������GPU�ڴ������,���еļܹ����Խ�С������С(16��>8)����ѵ�����ӱ��ĵĵ����͵����п��Կ���,�������и���,Ȼ��,���Ž������������ӳ���5��,�����Ѿ��ӽ����������������Ϊ���ͼ��ȫ�ֲ������弶������˹�������ϵõ��˳�ֵĻ�ԭ������6����������7��������,�������IJ�����С�ֱ��5������������10M��18M,������������С������,���ǶԾ�����ı�ʽ�����˲���,�����ͼ10�ͱ�5��ʾ��ͨ����Ԥ����ľ��������Ȩֵ����,�����������ʧ�����Ժ��ƾ��ȷ��涼�������Ե���ߡ����ǿ��Կ���,�ݶ����ĸĽ�������ȷԤ����Ȳв��Ǻ���Ҫ��,��Ȳв����൱ϡ���(������)���������,ͨ��ʹ�����ǵľ�����(��Ԥ����+��Ȩ����),������Ļ���������˹�������Ľ�������ѵ����ʧ�����ȶ�����,�����������������,��ͼ10��ʾ����ͼ11��ʾ,������ĺͲ��Ծ���Ҳ����ѵ�������Ƶ�����������ע��,���Ծ����������� < 1:25��������²�����,�������ڶ�KITTI���ݼ��Ķ������������ǻ���6���������(��MobileNetV2��VGG19��Ineptionv3��ResNet-101��DenseNet-161��ResNext-101),�������ñ��ֲ���,��Ӧ�Ľ�����7��ʾ�����Կ���,����Ľ�������ʾ�ɿ��Ľ��,���۱������ṹ���ر���,����MobileNetV2��ģ����ʾֻ��2.4%�ľ����½����� < 1.25��,��������20%�IJ�������,����ʾ6֡/����ٶȱȻ���ResNext-101��ģ�͡��ý������IJ�����Сȷ����15M����,�ɹ㷺Ӧ���ڸ��ֹǸɱ����������,��������ṹ�ı仯,�����������ͽ������ܷ��������ڸ�˹�������Ľ��������Իָ����ͼ��ÿ����Ӧ�������ϵIJ��֡���Ƚ������ڲ�ʹ�ý������ṹ�������,����ԭʼ���������������յ����ͼ��ʾ�˸��õ����ܡ�Ȼ��,���ֽṹȱ�����ӳ߶ȿռ�֮���Ƶ��Ϣ��������������������������(FPN)[48]�Ľ�����ͨ����ȡ��������ǿ�����͵ײ�����������ͼ,�����ڸ���ȷ��Ԥ�����ֵ����Ȼ����FPN�Ľ������Ȼ��ڸ�˹�ķ��������Ԥ������,���������ͼ�ij߶ȿռ�֮��ȱ��ֱ�ӵ���ͨ��,����Ȼ���ܷ�ӳ�߶ȷ������Щ������ͬ����,�ý�������������˹��������ÿһ�������Ȳв�,�����ÿ�߶ȿռ�IJ���,��������߽�߶���ء�ʵ��������,��������Ļ��ڲ�ͬ�������ṹ����Ȳв��㷨�����������ڲ�ͬ�������ṹ�ķ���,������6��ʾ��ʵ��������,��������Ļ���������˹����������Ȳв��㷨Ϊ��Ŀ��ȹ��Ƶ춨�˻�����
��V
�Ը÷�����kitti���ݼ��ϸ��ݾ�����ı仯�������ܷ���

��VI
���ݽ������ṹ�ı仯,�Ը÷�����kitti���ݼ��ϵ����ܽ����˷���

ע��:���������ṹ����������ö�����ͬ��(����,�Ǹɱ�����,ѵ������,��������)��
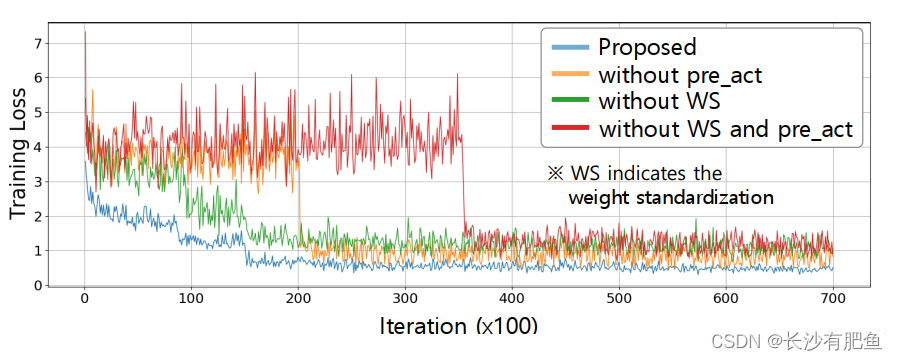
ͼ10��ʾ.����������Ľ������о�����ĸ������õ���ʧ�����Ƚ�(��ɫ�����ͼ)��

ͼ11��ʾ.����������Ľ������о�����ĸ������õIJ�����ʧ�;��ȵ�����(��ɫ�����ͼ)
V.����
���������һ�ֻ��ڵ�Ŀͼ�����ȹ����·������÷����Ĺؼ�˼����ͨ������������˹���������ֽ�������,����������ñ��������ĵײ����ԡ�����,Ϊ�����������̵�Ч��,�����������������Ԥ����������ϲ��ü�Ȩ����,��������ݶȵ�����,�Ӷ����������ɾ���������ȱ߽�Ŀɿ����ͼ���ڸ������ں�������¹����Ļ����ݼ��ϵ�ʵ��������,�÷����Ե�Ŀ��ȹ�������Ч�ġ�