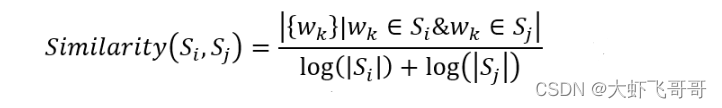NLP - 关键词提取 - TextRank
一、TextRank介绍
TextRank算法则可以脱离语料库的基础,仅对单篇文档进行分析就可以提取该文档的关键词。这也是TextRank算法的重要特点。TextRank算法的基本思想源于Google的PageRank算法。
二、PageRank介绍
PageRank 算法是一种网页排名算法,其基本思想有两条:
链接数量: 一个网页被越多的其他网页链接,说明这个网页越重要。
链接质量: 一个网页被一个越高权值的网页链接,也能表明这个网页越重要。
PageRank 考虑到不同网页之间,一般会通过超链接相连,B网页 链接越多,说明 B网页 的价值也就越大;权重是从某个网页链接出去的数量的倒数,数量越多,权重越小,好比是投票,某个人投出的票越多,说明这个人的票越没有含金量。


三、PageRank计算过程
假设:以下几个网页有这样的链接关系,给定每个网页相同的初始价值:
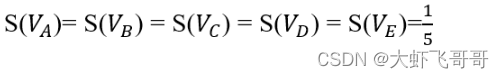

依次如下计算
S
(
V
A
)
,
S
(
V
B
)
,
S
(
V
C
)
,
S
(
V
D
)
,
S
(
V
E
)
S(V_{A}), S(V_{B}),S(V_{C}),S(V_{D}),S(V_{E})
S(VA?),S(VB?),S(VC?),S(VD?),S(VE?),迭代N次,得到网页的稳定价值,即网页排名。

上述计算过程比较复杂,用邻接矩阵表示图,简化运算:
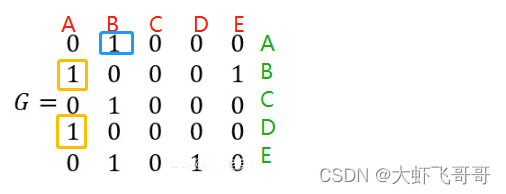
G 就是表示上面图的邻接矩阵,列表示从网页链接出去的,行表示从网页链接进来的。例如:第一列表示,A 链接到 B 和 D ,第一行表示,B 链接到 A 。
通过标准化,我们可以计算出概率转移矩阵:

初始化:
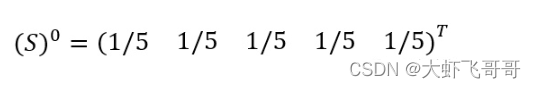
每次的迭代公式转换为以下计算:

迭代过程中,由于 D 节点不存在外链,使得最终结果都趋于0, 因此加入阻尼,认为用户浏览到任何一个页面,都有可能以一个极小的概率转移到另外一个页面。
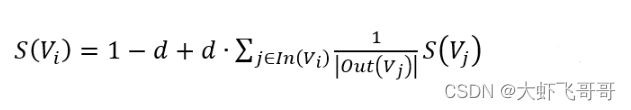
同理得到矩阵形式:
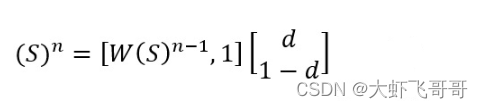
迭代100轮,基本收敛:

在 0.85 的阻尼系数下,大约 100 多次迭代就能收敛到一个稳定的值,而当阻尼系数接近 1 时,需要的迭代次数会陡然增加很多,且排序不稳定。
四、关键词提取任务
在这个任务中,词就是Graph中的节点,而词与词之间的边,则利用 “共现” 关系来确定。所谓“共现”,就是共同出现,即在一个给定大小的滑动窗口内的词,认为是共同出现的,而这些单词间也就存在着边。
举例:
淡黄的长裙,蓬松的头发 牵着我的手看最新展出的油画。
分词后:淡黄 长裙 蓬松 头发 牵 我 手 看 最新 展出 油画
给定窗口为2,则 “淡黄” 和 “长裙” 两个节点间存在边:

计算公式和 PageRank一样:

文本摘要提取关键句,使用以下公式:

其中相似度计算如下: