大家好,今天和各位分享一下如何使用 TensorFlow 构建 ConvMixer 卷积神经网络模型.
我偶然间找到了这个网络,这是一个实现起来非常简单的模型,但是能够实现较好的精度表现,超过了 Vision Transformer 模型,有种大道至简的感觉。
论文地址:https://openreview.net/forum?id=TVHS5Y4dNvM
1. 引言
近年来 Transformer?模型在 CV 领域中不断挑战卷积神经网络的统治地位,出现了能和 CNN 扳手腕的 VisionTransformer 以及划时代的 SwinTransformer。这篇文章作者主要针对的是 VIT 模型,他提出了一个问题:ViT的性能是由于其强大的Transformer结构产生的,还是由于使用patch作为输入表示产生的。
在论文中,作者证明了PatchEmbedding对VIT的精度影响更大,并提出了一个非常简单的模型ConvMixer,在思想上类似于ViT和MLP-Mixer。模型直接将patch作为输入,分离空间和通道尺寸的混合建模,并在整个网络中保持相同大小的分辨率。
尽管ConvMixer的设计很简单,但是实验证明了ConvMixer在相似的参数计数和数据集大小方面优于ViT、MLP-Mixer及其一些变体,以及经典的视觉模型,如ResNet。
2. 模型构建
我们先导入需要用到的工具包
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers2.1 Patch Embedding
patchembedding 的主要功能是对原始输入图像(h, w)划分图像块。首先指定每个图像块的size为(patch_size, patch_size),将每张图像划分出(h//patch_size, w//patch_size)个图像块。
它的实现方法就是通过一个 kernel_size 和 stride 都等于 patch_size 的卷积层来划分图像块。

代码如下:
# ---------------------------------------------- #
#(1)patchembedding层
'''out_channel代表输出通道数, patch_size代表每个图像块的宽高'''
# ---------------------------------------------- #
def patchembed(inputs, out_channel, patch_size):
# 卷积核大小为patch_size*patch_size,步长为patch_size的标准卷积划分图像块
x = layers.Conv2D(filters = out_channel, # 输出通道数
kernel_size = patch_size, # 卷积核尺寸
strides = patch_size, # 卷积步长
padding = 'same', #
use_bias = False)(inputs)
# GELU激活函数、BN标准化
x = layers.Activation('gelu')(x)
x = layers.BatchNormalization()(x)
return x2.2 特征提取层
这里的特征提取层由三部分组成,深度卷积(depthwise conv)、逐点卷积(pointwise conv)、残差连接(shortcut)。如下图ConvMixer Layer所示。
关于深度可分离卷积的原理,看我这篇博文:https://blog.csdn.net/dgvv4/article/details/123476899

首先输入特征图,经过深度卷积提取特征图长宽方向的信息,其中卷积核的个数和输入特征图的通道数相同,且输入和输出特征图的shape相同;接着残差连接输入和输出;然后经过1*1逐点卷积融合通道方向的信息,其中卷积核的个数和输出特征图的个数相同。
代码如下:
# ---------------------------------------------- #
#(2)单个特征提取模块
'''out_channel代表逐点卷积的输出通道数, kernel_size代表深度卷积的卷积核大小'''
# ---------------------------------------------- #
def layer(inputs, out_channel, kernel_size):
# 9*9深度卷积提取特征
x = layers.DepthwiseConv2D(kernel_size = kernel_size, # 卷积核大小
strides = 1, # 不经过下采样
padding = 'same', # 卷积前后size不变
use_bias = False)(inputs)
# GELU激活、BN标准化
x = layers.Activation('gelu')(x)
x = layers.BatchNormalization()(x)
# 残差连接
x = x + inputs
# 1*1逐点卷积
x = layers.Conv2D(filters = out_channel, # 输出通道数
kernel_size = 1, # 1*1卷积
strides = 1)(x)
# GELU激活、BN标准化
x = layers.Activation('gelu')(x)
x = layers.BatchNormalization()(x)
return x
# ---------------------------------------------- #
#(3)堆叠多个特征提取模块
'''depth代表堆叠的次数'''
# ---------------------------------------------- #
def blocks(x, depth, out_channel, kernel_size):
# 堆叠多个特征提取模块
for _ in range(depth):
x = layer(x, out_channel, kernel_size)
return x2.3 主干网络
ConvMixer的网络结构非常简单。首先图像经过 PatchEmbedding 划分图像块,然后经过12个特征提取模块,最后经过一个全连接层得到输出结果。
这里构建 ConvMixer-1536/20 网络模型,其中 1536 代表patchembedding 层的输出通道数,20 代表堆叠20个特征提取模块,每个图像块patch_size的大小为7*7,特征提取模块中深度卷积的卷积核尺寸为 9*9
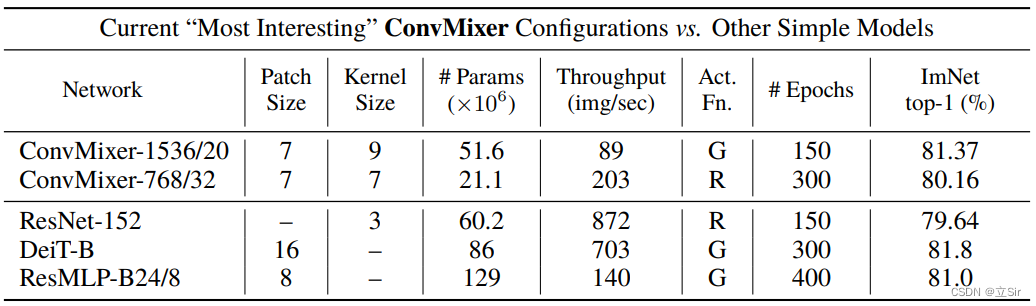
代码如下:
# ---------------------------------------------- #
#(4)主干网络
'''input_shape代表输入图像的尺寸(不包含batch维度), num_classes代表分类数'''
# ---------------------------------------------- #
def convmixer(input_shape, num_classes):
# 构造输入层[b,224,224,3]
inputs = keras.Input(shape=input_shape)
# patchembedding层[b,224//7,224//7,1536]
x = patchembed(inputs, out_channel=1536, patch_size=7)
# 经过20个特征提取层[b,224//7,224//7,1536]
x = blocks(x, depth=20, out_channel=1536, kernel_size=9)
# 全局平均池化[b,1536]
x = layers.GlobalAveragePooling2D()(x)
# 全连接分类[b,num_classes]
outputs = layers.Dense(num_classes)(x)
# 构造网络
model = keras.Model(inputs, outputs)
return model2.4 查看网络架构
以1000分类为例查看网络结构
# ---------------------------------------------- #
#(5)查看网络结构
# ---------------------------------------------- #
if __name__ == '__main__':
# 接受模型
model = convmixer(input_shape=[224,224,3],num_classes=1000)
# 查看网络结构
model.summary()网络结构如下:
conv2d_20 (Conv2D) (None, 32, 32, 1536 2360832 ['tf.__operators__.add_19[0][0]']
)
activation_40 (Activation) (None, 32, 32, 1536 0 ['conv2d_20[0][0]']
)
batch_normalization_40 (BatchN (None, 32, 32, 1536 6144 ['activation_40[0][0]']
ormalization) )
global_average_pooling2d (Glob (None, 1536) 0 ['batch_normalization_40[0][0]']
alAveragePooling2D)
dense (Dense) (None, 1000) 1537000 ['global_average_pooling2d[0][0]'
]
==================================================================================================
Total params: 51,719,656
Trainable params: 51,593,704
Non-trainable params: 125,952
__________________________________________________________________________________________________