本系列深入Pytorch官方Faster R-CNN源代码,博主会尽可能详尽地解释每一处代码,如果对你有帮助可以点点关注点点赞,有问题在评论区指出,博主会尽可能地解答。
Faster R-CNN论文链接
Pytorch官方Faster R-CNN的代码文档链接。
Pytorch官方使用的示例代码如下:
import torch
import torchvision
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# For training
images, boxes = torch.rand(4, 3, 600, 1200), torch.rand(4, 11, 4)
boxes[:, :, 2:4] = boxes[:, :, 0:2] + boxes[:, :, 2:4]
labels = torch.randint(1, 91, (4, 11))
images = list(image for image in images)
targets = []
for i in range(len(images)):
d = {'boxes': boxes[i], 'labels': labels[i]}
targets.append(d)
output = model(images, targets)
# For inference
model.eval()
x = [torch.rand(3, 300, 400), torch.rand(3, 500, 400)]
predictions = model(x)
# optionally, if you want to export the model to ONNX:
torch.onnx.export(model, x, "faster_rcnn.onnx", opset_version = 11)
下面主要就示例代码进行详细说明。
首先,初始化 Faster R-CNN 模型。
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
可以看出,这里使用的是主干网络 Resnet-50-FPN 的 Faster R-CNN。接下来 Debug 进内部代码。
def fasterrcnn_resnet50_fpn(pretrained=False, progress=True,
num_classes=91, pretrained_backbone=True, trainable_backbone_layers=3, **kwargs):
"""
Constructs a Faster R-CNN model with a ResNet-50-FPN backbone.
构建一个主干网络为 ResNet-50-FPN 的 Faster R-CNN 模型。
The input to the model is expected to be a list of tensors, each of shape ``[C, H, W]``, one for each
image, and should be in ``0-1`` range. Different images can have different sizes.
模型的输入应该为一个由tensors组成的列表,每个tensor的形状为[C,H,W],对于每一个图像的元素值都应该在[0,1]的范围内,不同的图像有着不同的尺寸。
The behavior of the model changes depending if it is in training or evaluation mode.
模型有训练与评估两种模式,模型的表现取决于模型所处的模式。
During training, the model expects both the input tensors, as well as a targets (list of dictionary),
containing:
- boxes (``FloatTensor[N, 4]``): the ground-truth boxes in ``[x1, y1, x2, y2]`` format, with values of ``x``
between ``0`` and ``W`` and values of ``y`` between ``0`` and ``H``
- labels (``Int64Tensor[N]``): the class label for each ground-truth box
在训练过程中,模型需要输入图像的tensor,以及目标(字典组成的列表),其包含:
- 边框(FloatTensor[N,4]):真实框为[x1,y1,x2,y2]的形式,x 的值在 0~W 之间,y 的值在 0-H 之间。
- 标签(Int64Tensor[N]):每个真实框的类别标签。
The model returns a ``Dict[Tensor]`` during training, containing the classification and regression
losses for both the RPN and the R-CNN.
在训练期间,模型返回一个 ”Dict[Tensor]“,包含 RPN 与 R-CNN 阶段的分类与回归损失。
During inference, the model requires only the input tensors, and returns the post-processed
predictions as a ``List[Dict[Tensor]]``, one for each input image. The fields of the ``Dict`` are as
follows:
- boxes (``FloatTensor[N, 4]``): the predicted boxes in ``[x1, y1, x2, y2]`` format, with values of ``x``
between ``0`` and ``W`` and values of ``y`` between ``0`` and ``H``
- labels (``Int64Tensor[N]``): the predicted labels for each image
- scores (``Tensor[N]``): the scores or each prediction
在推理过程中,模型仅需要输入图像的tensor,然后返回经过后处理的预测结果以 "List[Dict[Tensor]]" 的形式,对于每一个输入图像,其 "Dict" 域如下:
- 边框(FloatTensor[N,4]):预测框为[x1,y1,x2,y2]的形式,x 的值在 0~W 之间,y 的值在 0~H 之间。
- 标签(Int64Tensor[N]):每个图像的预测标签。
- 分数(Tensor[N]):每个预测的分数。
Faster R-CNN is exportable to ONNX for a fixed batch size with inputs images of fixed size.
Faster R―CNN 可以被导出为一个固定批大小域固定尺寸输入图像的 ONNX 格式。
Arguments:
pretrained (bool): If True, returns a model pre-trained on COCO train2017
progress (bool): If True, displays a progress bar of the download to stderr
pretrained_backbone (bool): If True, returns a model with backbone pre-trained on Imagenet
num_classes (int): number of output classes of the model (including the background)
trainable_backbone_layers (int): number of trainable (not frozen) resnet layers starting from final block.
Valid values are between 0 and 5, with 5 meaning all backbone layers are trainable.
参数:
pretrianed(bool):如果为真,返回一个在 COCO train2017 上的预训练模型。
progress(bool):如果为真,将下载进度条展示在屏幕。
pretrained_backbone(bool):如果为真,返回一个在 Imagenet 上的主干网络预训练模型。
num_classes(int):模型输出的种类数量(包括背景)。
trainable_backbone_layers(int):从最后一个块开始可训练 ResNet 层的数量(未被冻结)。合法的值在 0~5 之间,5 意味着所有主干网络的层都是可训练的。
"""
# 使用 assert 判断 trainable_backbone_layers 的值是否合法
assert trainable_backbone_layers <= 5 and trainable_backbone_layers >= 0
# dont freeze any layers if pretrained model or backbone is not used
# 如果预训练模型或者预训练主干网络未被使用,不要冻结任何层。
if not (pretrained or pretrained_backbone):
trainable_backbone_layers = 5
if pretrained:
# no need to download the backbone if pretrained is set
# 如果预训练模型被使用,就不需要下载预训练主干网络
pretrained_backbone = False
# 获取 ResNet_FPN 主干网络
backbone = resnet_fpn_backbone('resnet50', pretrained_backbone, trainable_layers=trainable_backbone_layers)
# 获取 Faster R-CNN 模型
model = FasterRCNN(backbone, num_classes, **kwargs)
if pretrained:
# 如果使用预训练模型,就下载相关的预训练模型配置
state_dict = load_state_dict_from_url(model_urls['fasterrcnn_resnet50_fpn_coco'],
progress=progress)
# 加载模型配置到模型中
model.load_state_dict(state_dict)
return model # 返回模型
Debug 进获取 ResNet_FPN 主干网络对应代码。
def resnet_fpn_backbone(
backbone_name,
pretrained,
norm_layer=misc_nn_ops.FrozenBatchNorm2d,
trainable_layers=3,
returned_layers=None,
extra_blocks=None
):
"""
Constructs a specified ResNet backbone with FPN on top. Freezes the specified number of layers in the backbone.
构建一个在顶端加入FPN的ResNet主干网络。冻结主干网络中指定数量的层。
Examples::
>>> from torchvision.models.detection.backbone_utils import resnet_fpn_backbone
>>> backbone = resnet_fpn_backbone('resnet50', pretrained=True, trainable_layers=3)
>>> # get some dummy image
>>> x = torch.rand(1,3,64,64)
>>> # compute the output
>>> output = backbone(x)
>>> print([(k, v.shape) for k, v in output.items()])
>>> # returns
>>> [('0', torch.Size([1, 256, 16, 16])),
>>> ('1', torch.Size([1, 256, 8, 8])),
>>> ('2', torch.Size([1, 256, 4, 4])),
>>> ('3', torch.Size([1, 256, 2, 2])),
>>> ('pool', torch.Size([1, 256, 1, 1]))]
Arguments:
backbone_name (string): resnet architecture. Possible values are 'ResNet', 'resnet18', 'resnet34', 'resnet50',
'resnet101', 'resnet152', 'resnext50_32x4d', 'resnext101_32x8d', 'wide_resnet50_2', 'wide_resnet101_2'
norm_layer (torchvision.ops): it is recommended to use the default value. For details visit:
(https://github.com/facebookresearch/maskrcnn-benchmark/issues/267)
pretrained (bool): If True, returns a model with backbone pre-trained on Imagenet
trainable_layers (int): number of trainable (not frozen) resnet layers starting from final block.
Valid values are between 0 and 5, with 5 meaning all backbone layers are trainable.
参数:
backbone_name (string):resnet 架构。可能的值为 'ResNet','resnet18','resnet34','resnet50','resnet101','resnet152',
'resnext50_32x4d','resnet101_32x8d','wide_resnet50_2','wide_resnet101_2'
norm_layer (torchivision.ops):建议使用默认值。相关细节请访问:
(https://github.com/facebookresearch/maskrcnn-benchmark/issues/267)
pretrained (bool):如果为真,返回一个在 Imagenet 上的预训练主干网络模型
trainable_layers (int):从最后一个块开始可训练 ResNet 层的数量(未被冻结)。合法的值在 0~5 之间,5 意味着所有主干网络的层都是可训练的。
"""
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained,
norm_layer=norm_layer) # 获取resnet-50主干网络
# select layers that wont be frozen
# 选择被冻结的层(不参与训练)
assert trainable_layers <= 5 and trainable_layers >= 0
layers_to_train = ['layer4', 'layer3', 'layer2', 'layer1', 'conv1'][:trainable_layers]
# freeze layers only if pretrained backbone is used
# 仅仅当预训练主干网络被使用才冻结层
for name, parameter in backbone.named_parameters():
if all([not name.startswith(layer) for layer in layers_to_train]):
parameter.requires_grad_(False)
if extra_blocks is None:
extra_blocks = LastLevelMaxPool()
if returned_layers is None:
returned_layers = [1, 2, 3, 4]
assert min(returned_layers) > 0 and max(returned_layers) < 5
return_layers = {f'layer{k}': str(v) for v, k in enumerate(returned_layers)}
in_channels_stage2 = backbone.inplanes // 8
in_channels_list = [in_channels_stage2 * 2 ** (i - 1) for i in returned_layers]
out_channels = 256
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels, extra_blocks=extra_blocks)
Debug进获取 ResNet-50 主干网络的代码。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
ResNet-50 的网络结构如下图所示。
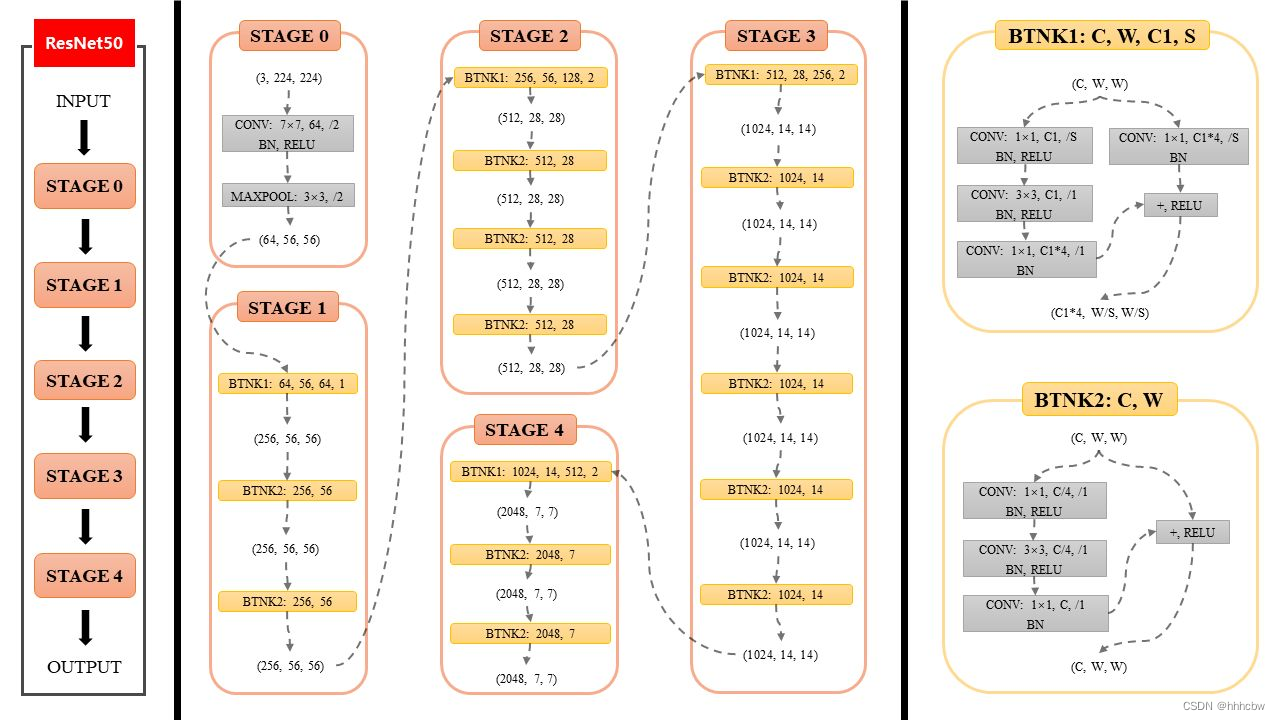
ResNet-50 采用了 BottleNeck 结构,其比 BasicNeck 更省参数。代码如下:
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
最后我们获得到 ResNet-50 的网络结构:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d(64)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d(256)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(64)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(64)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(256)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(512)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(128)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(128)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(512)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(1024)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(256)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(256)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(1024)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d(2048)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d(512)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d(512)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d(2048)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
之后还加如了FPN。
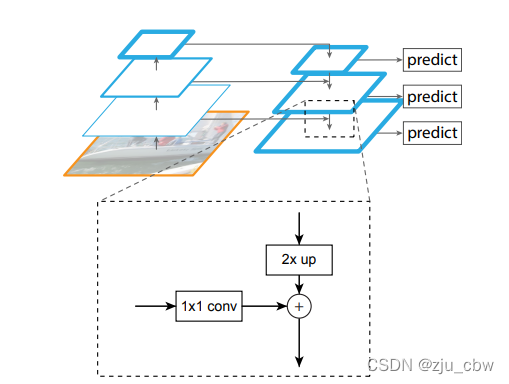
如上图所示,FPN 可以建立各种尺度都是强语义的特征金字塔,具体原理可以看这篇博客。FPN 在这里获取 ResNet-50 每个阶段提取的特征图加上最大池化最后一层特征图共五层特征图。其代码如下:
def forward(self, x: Dict[str, Tensor]) -> Dict[str, Tensor]:
"""
Computes the FPN for a set of feature maps.
Arguments:
x (OrderedDict[Tensor]): feature maps for each feature level.
Returns:
results (OrderedDict[Tensor]): feature maps after FPN layers.
They are ordered from highest resolution first.
"""
# unpack OrderedDict into two lists for easier handling
names = list(x.keys())
x = list(x.values())
last_inner = self.get_result_from_inner_blocks(x[-1], -1)
results = []
results.append(self.get_result_from_layer_blocks(last_inner, -1))
for idx in range(len(x) - 2, -1, -1):
inner_lateral = self.get_result_from_inner_blocks(x[idx], idx) # 1x1 卷积减少通道数量至256
feat_shape = inner_lateral.shape[-2:]
inner_top_down = F.interpolate(last_inner, size=feat_shape, mode="nearest") # 上采样
last_inner = inner_lateral + inner_top_down # 横向连接
results.insert(0, self.get_result_from_layer_blocks(last_inner, idx)) # 3x3 卷积消除混叠效应
if self.extra_blocks is not None:
results, names = self.extra_blocks(results, x, names) # 最大池化获得第五层特征图
# make it back an OrderedDict
out = OrderedDict([(k, v) for k, v in zip(names, results)])
return out
至此,特征图的提取已全部完成,下面将进行 RPN(感兴趣区域的生成)。