聚类(Clustering):按照某个特定标准(如:距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,不在同一个簇中的数据对象的差异性也尽可能地大;聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
聚类一般过程:
- 数据准备:特征标准化、降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如
距离误差和(SSE)等
数值型数据相似度度量:
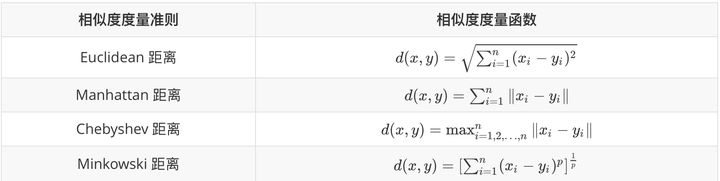
Minkowski?就是LP范数(P >= 1),而?Manhattan?、Euclidean、Chebyshev对应 P = 1、2、无穷
簇间距离度量:Ci 和 Cj 为两个簇

Single-link:两个簇间的距离为两个簇间距离最近的两个点之间的距离,会在聚类过程中产生链式效应,可能会出现非常大的clusterComplete-link:两个簇间的距离为两个簇间距离最远的两个点之间的距离,可以避免链式效应`,对异常样本点非常敏感,容易产生不合理的聚类。UPGMA:Single-link和Complete-link的折中,两个簇间的距离为两个簇间所有点距离均值WPGMA:两个簇间的距离的加权平均值,加权是为了使两个簇对距离的计算的影响在同一层次上,而不受簇大小的影响,具体公式和采用的权重方案有关。
聚类方法
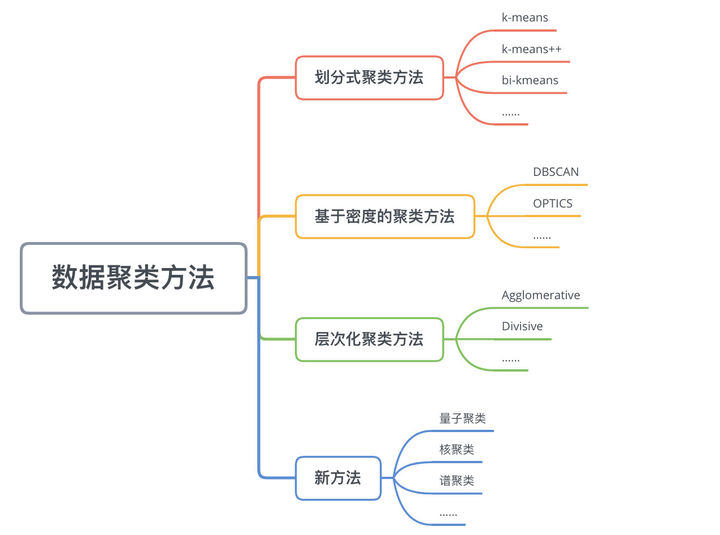
划分式聚类:需要事先指定簇类的数目或者聚类中心,反复迭代达到 簇内的点足够近,簇间的点足够远 的目标;如:k-means、k-means++、bi-kmeans、kernel k-means等;对于凸性数据具有良好的效果。

k-means 特定:需要提前确定 k 值、对初始质心点敏感、对异常数据敏感。
k-mean++:

bi-kmeans:针对kmeans算法会陷入局部最优的缺陷进行的改进算法。基于SSE最小化的原理,首先将所有的数据点视为一个簇,然后将该簇一分为二,之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否能最大程度的降低SSE的值。SSE(Sum of Squared Error),一种度量聚类效果的指标,表示聚类后离该簇的聚类中心距离的平方和,SSE越小,聚类效果越好。

bi-kmeans 是全局最优的方法,所以每次计算出来的SSE值基本是一样的。
密度聚类方法:需要定义两个参数,邻域半径和邻域密度阈值。


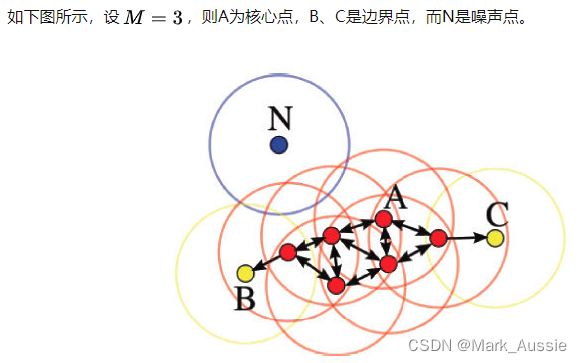

构建邻域半径可使用 kd-tree 优化;
DBSACN 密度聚类特点:
- 需要提前确定邻域半径和邻域密度阈值
- 不需要提前设置聚类的个数
- 对初值选取敏感,对噪声不敏感
- 对密度不均的数据聚合效果不好
OPTICS 聚类:DBSCAN算法使用了统一的邻域半径,当数据密度不均匀的时候,如果设置了较小的值,则较稀疏的簇中的节点密度会小于邻域密度阈值,会被认为是边界点而不被用于进一步的扩展;如果设置了较大的值,则密度较大且离的比较近的簇易被划为同一个簇。
核心距离:给定邻域半径和邻域密度,在邻域半径内能达到邻域密度的最小半径值。
可达距离:给定的领域半径和密度内,在核心距离外同时在领域半径内的点的距离。

insert_list() 算法过程:

算法最终获取知识是一个输出序列,该序列按照密度不同将相近密度的点聚合在一起,而不是输出该点所属的具体类别,获取该点所属类型,需要再设置参数![]() 提取出具体的类别。
提取出具体的类别。
?
层次聚类方法:?将数据集分为一层一层的簇,后一层簇是基于前面一层的结果。
前面的算法可以在较小复杂度内获取较好的结果,但却存在链式效应,如:A与B相似,B与C相似,聚类时会将A、B、C聚合到一起,但如果A与C不相似,就会造成聚类误差,误差可能一直传下去。层次聚类可解决链式效应问题。
- Agglomerative 层次聚类:自底向上(bottom-up)的层次聚类,每一个对象开始都是一个 簇,每次按一定的准则将最相近的两个簇合并生成新簇,直至最终所有的对象都属于一个簇。
- Divisive 层次聚类: 自顶向下(top-down)的层次聚类,开始所有对象均属于一个簇,每次按一定的准则将某个簇划分为多个簇,直至每个对象均是一个簇。
层次聚类是贪心算法(greedy algorithm),其每一次合并或划分都是基于某种局部最优的选择。
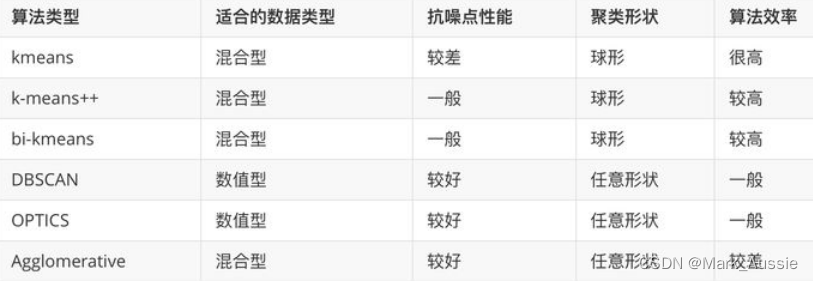
聚类方法比较
?
参考: