1. ПьЫйШыУХ
1.1 diffusionФЃаЭ
diffusionФЃаЭДгдЪМЭМЦЌГіЗЂдіМгдыЩљ,ШЛКѓдйГЂЪджиНЈ
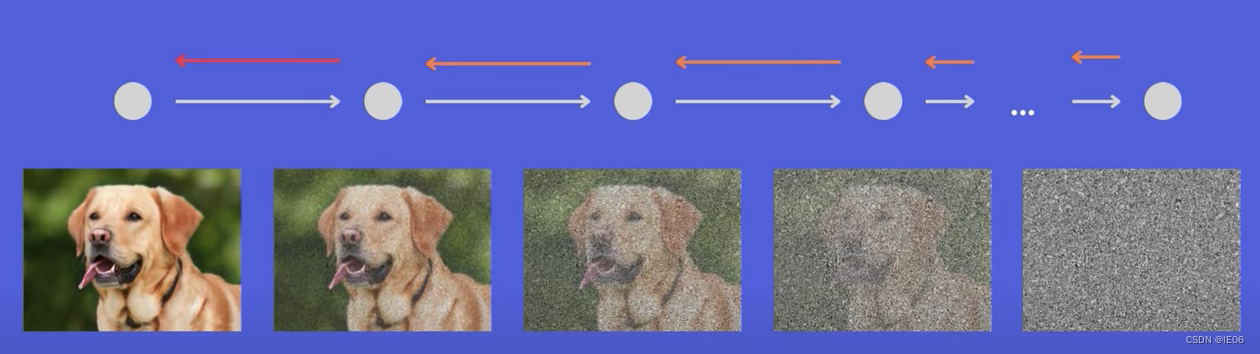
СэЭтЛЙгУGLIDEФЃаЭРДНјааЭМЯёНтТы,гыЦеЭЈdiffusionФЃаЭВЛЭЌЕФЪЧ,ЫќЛЙМгШыСЫtext embeddingКЭclip embedding:
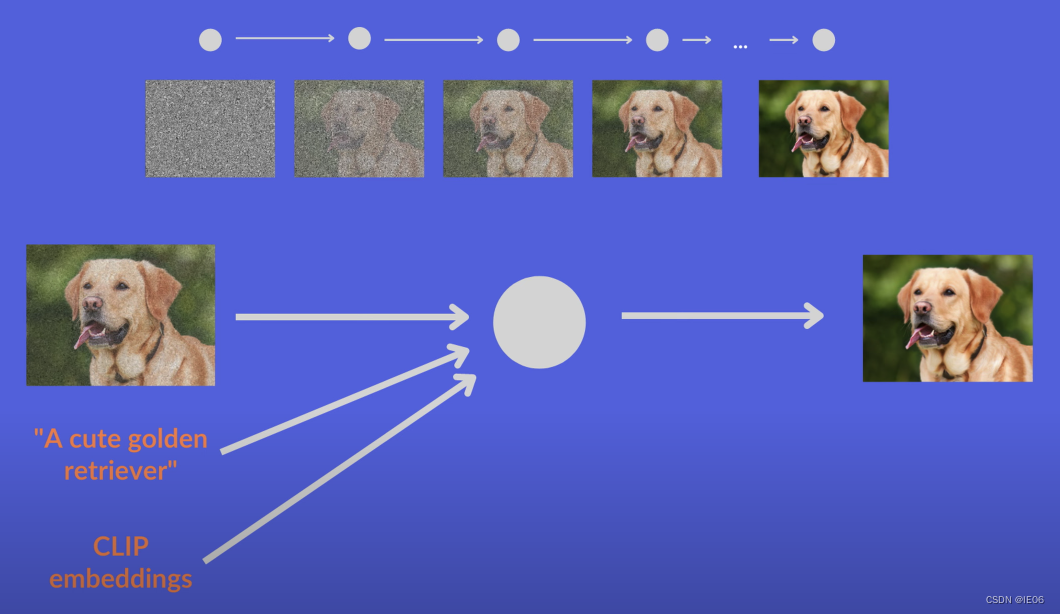
1.2 Dalle2ФЃаЭ
Dalle2ФЃаЭЛљгкCLIPФЃаЭ,СїГЬШчЯТЁЃЦфжаPriorВЩгУdiffusionФЃаЭ
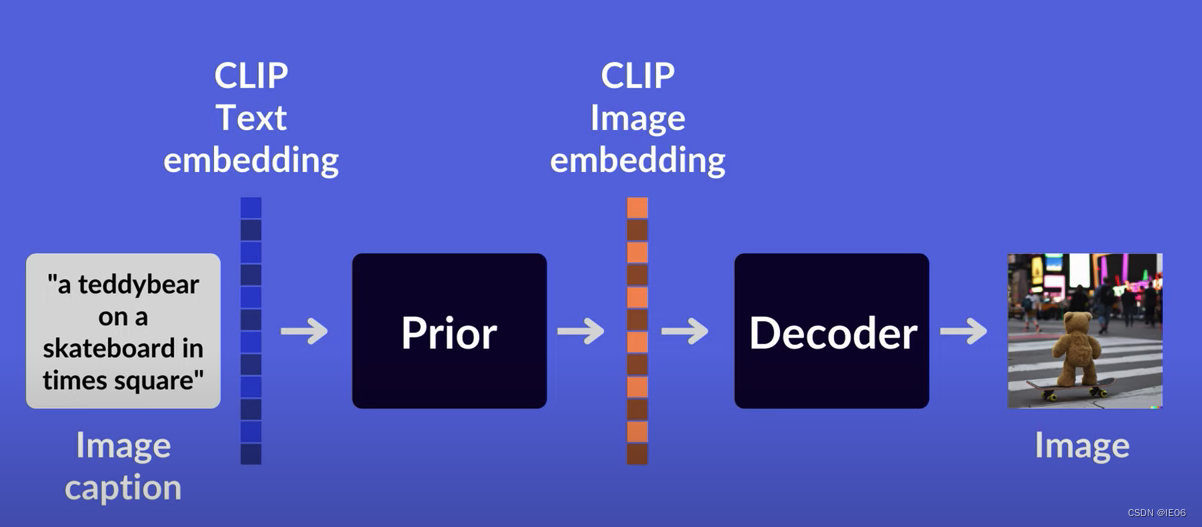
ЮЊЩЖвЊетУДЩшМЦФи?ТлЮФЫЕЪЧГЂЪдГіРДЕФЁЃ
МгШыАбЁАa hedgedog using a calculatorЁБжБНгЪфШыdecoder,ЕУЕНЯТЭМ:

МгЩЯtext embeddingЕФЛАЪЧетбљ:

МгЩЯdiffusionФЃаЭКЭimage embedding,ЕУЕНЯТЭМ:

Delle2ЩњГЩЕФЭМЯёЪЧЗёok,ЪЧШЫЙЄДђБъЕФ,ЮЌЖШАќРЈcaption similarityЁЂphotorealismЁЂsample diversityЁЃ
1.3 Жрбљад
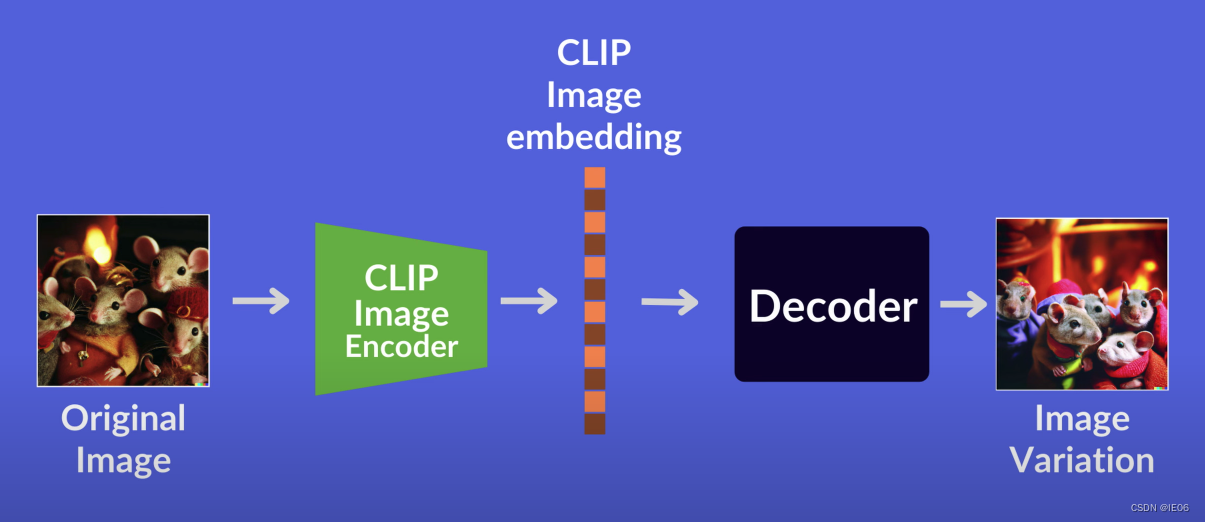
ЪЙгУЯТУцЕФФЃаЭЩњГЩЖржжЭМЦЌ:
2. бЕСЗДњТы
АВзА:pip install dalle2-pytorch
2.1 вЛАуСїГЬ
ЪзЯШвЊбЕСЗclip:
import torch
from dalle2_pytorch import CLIP
clip = CLIP().cuda()
loss = clip(text,images,return_loss = True)
loss.backward()
ШЛКѓбЕСЗНтТыЦї(ЛљгкCLIPЕФimage embedding),етРяЪЙгУвЛИіUnetРДзїЮЊНтТыЦї:
import torch
from dalle2_pytorch import Unet, Decoder, CLIP
unet = Unet().cuda()
decoder = Decoder(unet = unet,clip = clip).cuda()
images = torch.randn(4, 3, 256, 256).cuda()
loss = decoder(images)
loss.backward()
зюКѓбЕСЗprior(ЛљгкCLIPЕФtext embeddingЩњГЩimage embedding),етРяЪЙгУDiffusionФЃаЭ:
import torch
from dalle2_pytorch import DiffusionPriorNetwork, DiffusionPrior, CLIP
prior_network = DiffusionPriorNetwork().cuda()
diffusion_prior = DiffusionPrior(net = prior_network,clip = clip).cuda()
loss = diffusion_prior(text, images)
loss.backward()
2.2 ЩњГЩЭМЦЌ
ашвЊгУЕНбЕСЗКУЕФDiffusionPriorКЭDecoder:
from dalle2_pytorch import DALLE2
dalle2 = DALLE2(
prior = diffusion_prior,
decoder = decoder
)
texts = ['glistening morning dew on a flower petal']
images = dalle2(texts) # (1, 3, 256, 256)
3. ЭјЩЯзЪдД
3.1 ЪЙгУЯжгаCLIP
ЪЙгУOpenAIClipAdapterРр,ВЂНЋЦфДЋИјdiffusion_priorКЭdecoderНјаабЕСЗ:
import torch
from dalle2_pytorch import DALLE2, DiffusionPriorNetwork, DiffusionPrior, Unet, Decoder, OpenAIClipAdapter
# openai pretrained clip - defaults to ViT-B/32
clip = OpenAIClipAdapter()
# mock data
text = torch.randint(0, 49408, (4, 256)).cuda()
images = torch.randn(4, 3, 256, 256).cuda()
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork(
dim = 512,
depth = 6,
dim_head = 64,
heads = 8
).cuda()
diffusion_prior = DiffusionPrior(
net = prior_network,
clip = clip,
timesteps = 100,
cond_drop_prob = 0.2
).cuda()
loss = diffusion_prior(text, images)
loss.backward()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet(
dim = 128,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults=(1, 2, 4, 8)
).cuda()
unet2 = Unet(
dim = 16,
image_embed_dim = 512,
cond_dim = 128,
channels = 3,
dim_mults = (1, 2, 4, 8, 16)
).cuda()
decoder = Decoder(
unet = (unet1, unet2),
image_sizes = (128, 256),
clip = clip,
timesteps = 100,
image_cond_drop_prob = 0.1,
text_cond_drop_prob = 0.5,
condition_on_text_encodings = False # set this to True if you wish to condition on text during training and sampling
).cuda()
for unet_number in (1, 2):
loss = decoder(images, unet_number = unet_number) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss.backward()
# do above for many steps
dalle2 = DALLE2(
prior = diffusion_prior,
decoder = decoder
)
images = dalle2(
['a butterfly trying to escape a tornado'],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)
3.2 ЪЙгУЯжГЩЕФpriorФЃаЭ
ВЮПМетРя:https://huggingface.co/zenglishuci/conditioned-prior,етРягаИїжжГпДчЕФФЃаЭЁЃ
ЯТУцЪЧМгдиpriorФЃаЭЕФДњТы
def load_diffusion_model(dprior_path, device, clip_choice):
loaded_obj = torch.load(str(dprior_path), map_location='cpu')
if clip_choice == "ViT-B/32":
dim = 512
else:
dim = 768
prior_network = DiffusionPriorNetwork(
dim=dim,
depth=12,
dim_head=64,
heads=12,
normformer=True
).to(device)
diffusion_prior = DiffusionPrior(
net=prior_network,
clip=OpenAIClipAdapter(clip_choice),
image_embed_dim=dim,
timesteps=1000,
cond_drop_prob=0.1,
loss_type="l2",
).to(device)
diffusion_prior.load_state_dict(loaded_obj["model"], strict=True)
diffusion_prior = DiffusionPriorTrainer(
diffusion_prior = diffusion_prior,
lr = 1.1e-4,
wd = 6.02e-2,
max_grad_norm = 0.5,
amp = False,
).to(device)
diffusion_prior.optimizer.load_state_dict(loaded_obj['optimizer'])
diffusion_prior.scaler.load_state_dict(loaded_obj['scaler'])
return diffusion_prior