ѭ������������
���÷���:������ѧ���ѧϰ��
һ���ݹ�������
��n-gramģ����,����wt��λ��t����������ֻȡ����֮ǰ��n-1�����ʡ�������������t-(n-1)����Ĵʶ�wt���ܲ�����Ӱ��,������Ҫ����n��Ȼ��,ģ�Ͳ���������Ҳ����֮��ָ��������,��Ϊ������ҪΪһ���ʻ��V�洢|V|n�����֡����,���佨��p(wt|wt-1;. . ;wt-n+1)ģ��,����ʹ��DZ����ģ��,����������
𝑝(𝑥𝑡|𝑥𝑡-1,��𝑥1)��𝑝(𝑥𝑡|𝑥𝑡-1,?𝑡) ��
����һ���㹻ǿ��ĺ���ht��˵,�Ⲣ����һ������ֵ���Ͼ�,ht���Լش洢����ĿǰΪֹ�۲쵽���������ݡ�������������Ϊʲô����������ģ�ͱȼ��Իع�ģ��Ҫ����һЩ,����
?𝑡=𝑓(𝑥𝑡-1, ?𝑡-1)��
��Ϊ����,���ǽ��ع˺��ߵ���ɢ�����n=2�����,��һ�������ɷ�ģ�͡�Ϊ�˽�һ��������,���������RNNʱʹ�õ��㡣�Ժ����ǽ����������Ч�����ӿ���ı���������
����û������״̬�ĵݹ�����
�����ǿ�һ�¾��е�һ���ز�Ķ���֪��������һ��С�����ε�ʵ��X Rn * d,������СΪn,����Ϊd(���������������ߴ�)�������ز�ļ����Ϊj�����,���ز�����HRn * h������Ϊ
H = ? ( X W x h + b h ) . \mathbf{H} = \phi(\mathbf{X} \mathbf{W}_{xh} + \mathbf{b}_h). H=?(XWxh?+bh?).
����,������Ȩ�ز���Wxh ~ Rd * h,ƫ�ò���bh ~ R1 * h,�Լ����ص�Ԫ������h,�������ز㡣�ع�һ��,bhֻ��һ�������C����ֵ��ʹ�ù㲥���Ƹ��Ƶ�,��ƥ�����-����˻���ֵ��
��Ҫע��,����״̬�����ز�ָ���������dz���ͬ�ĸ�����������͵�����,���ز����ڴ����뵽�����·���ϱ����������IJ㡣�ϸ���˵,����״̬�Ƕ�������ijһ�����������κ���������롣�෴,����ֻ��ͨ���鿴��ǰ���������������㡣�����������,������ͳ��ѧ�е�DZ����ģ���к֮ܶͬ��,������������ģ��,���о���ID��Ӱ�����,������ֱ�ӹ۲쵽��
���ر���H���������������롣���ڷ����Ŀ��,����Ԥ����һ���ַ�,���ά��q��������������е����������ƥ�䡣���,���������
O = H W h q + b q . \mathbf{O} = \mathbf{H} \mathbf{W}_{hq} + \mathbf{b}_q. O=HWhq?+bq?.
����,O ~ Rn * q���������,Whq ~ Rh * q��Ȩ�ز���,bq ~ R1 * q��������ƫ�ò���������Ƿ�������,���ǿ�����softmax(O)������������ĸ��ʷֲ������ǿ��������ѡ(wt;wt-1)��,ͨ��autograd������ݶ��½�������������IJ���W��b��
������������״̬�ĵݹ�����
������������״̬ʱ,�������ȫ��ͬ�ˡ������Ǹ���ϸ�ؿ�һ������ṹ������Xt ~ Rn * d��С��������,Ht ~ Rn * h��������ʱ�䲽��t�����ر����������֪����ͬ,�������DZ�����ǰһ��ʱ�䲽������ر���Ht-1,������һ���µ�Ȩ�ز���Whh ~ Rh * h,����������ڵ�ǰʱ�䲽����ʹ��ǰһ��ʱ�䲽������ر�����������˵,��ǰʱ�䲽������ر����ļ������ɵ�ǰʱ�䲽���������ǰһʱ�䲽������ر�����ͬ�����ġ�
H t = ? ( X t W x h + H t ? 1 W h h + b h ) . \mathbf{H}t = \phi(\mathbf{X}t \mathbf{W}{xh} + \mathbf{H}{t-1} \mathbf{W}_{hh} + \mathbf{b}_h). Ht=?(XtWxh+Ht?1Whh?+bh?).
�����֪�����,��������������һ��Ht-1Whh��������ʱ�䲽������ر���Ht��Ht-1֮��Ĺ�ϵ����,����֪����Щ�����������������е���ʷ��Ϣ,ֱ����ǰʱ�䲽��,���������統ǰʱ�䲽���״̬����䡣���,���������ر���Ҳ����Ϊ����״̬����������״̬�ڵ�ǰʱ�䲽����ʹ����ǰһ��ʱ�䲽�����ͬ����,�����������̵ļ����ǵݹ��,��˱���Ϊ�ݹ�������(RNN)��
�����ͬ��RNN�����������������������̶��������״̬��RNN�Ƿdz������ġ�����ʱ�䲽��t,��������������֪���еļ������ơ�
O t = H t W h q + b q \mathbf{O}_t = \mathbf{H}t \mathbf{W}{hq} + \mathbf{b}_q Ot?=HtWhq+bq?
RNN�IJ����������ز��Ȩ��Wxh ~ Rd * h; Whh ~ Rh * h ,ƫ��bh ~ R1 * h,�Լ�������Ȩ��Whq ~ Rh * q,ƫ��bq ~ R1 * q��ֵ��һ�����,RNN����ʹ����Щģ�Ͳ���,��ʹ�Dz�ͬ��ʱ�䲽�衣���,RNNģ�Ͳ�����������������ʱ�䲽�������Ӷ�������
��ͼ��ʾ��һ��RNN����������ʱ�䲽���ļ���������ʱ�䲽��t��,����״̬�ļ�����Ա������ǽ�����Xt��ǰһ��ʱ�䲽��������״̬Ht-1������,���м����j��ȫ���Ӳ��һ����ڡ�ȫ���Ӳ������ǵ�ǰʱ�䲽�������״̬Ht����ģ�Ͳ�����Wxh��Whh�Ĵ���,ƫ��Ϊbh����ǰʱ�䲽��t������״̬Ht�����������һ��ʱ�䲽��t+1������״̬Ht+1,��������Ϊ��ǰʱ�䲽���ȫ�������������롣
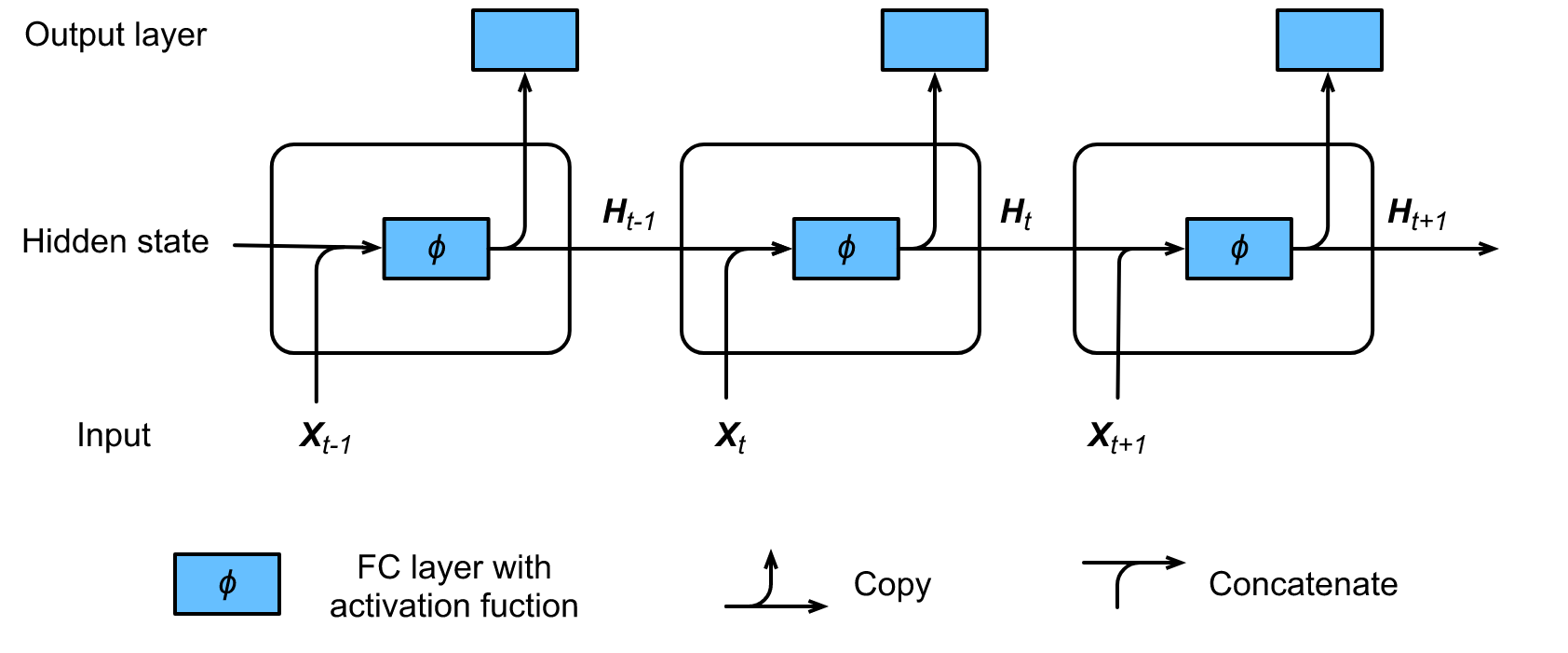
?
��ǰ����,����״̬�µļ���ʹ��Ht = XtWxh + Ht-1Whh ��������ά������Ht-1��ƥ��Ķ�����,����ʹ��Ht���������Ot = HtWhq.��
import torch
import torch.nn as nn
X=torch.randn(3,1)
H=torch.randn(3,2)
W_xh=torch.randn(1,2)
W_hh=torch.randn(2,2)
W_hq=torch.randn(2,3)
def net(X, H):
H = (torch.mm(X, W_xh) + torch.mm(H, W_hh))
O = (torch.mm(H, W_hq))
return H, O
���涨��ĵݹ����罫�۲���X������״̬H��Ϊ����,��ʹ����������������״̬���������O��
��������������ܻ�����ܳ���ʱ��,��Backpropѵ��ģ���Dz����ܵ�(����û��һЩ����ֵ)��
�Ͼ�,�����һ���dz�����������,Ҫȷ�����������Ǻ����ѵ�:�鼮ͨ���г���100,000���ַ�,����������ı��������ֵ��������з��������,
����,�ڹ�ȥ��10,000���ַ�,�Dz������ġ���BPTT�ͳ���ʱ���������ĽضϷ��������Ը���ԭ��ķ�ʽ��������������á�����,�����ǿ���״̬��������ι����ġ�
(H, O) = net(X,H)
print(H)
print(O)
tensor([[-0.1791, -1.1110],
[ 1.8311, -4.8133],
[ 0.1405, 2.0094]])
tensor([[ 1.4982, -0.4124, 0.5771],
[ 2.0720, -1.2001, 2.6391],
[-2.3988, 0.7046, -1.0535]])
�ġ�����ģ�͵IJ���
�ڱ��ڵ����,���ǽ�˵��RNN������ڽ�������ģ�͡�Ϊ�˼����,����ʹ�õ��ʶ������ַ�,��Ϊǰ�߸��������⡣��С�������ӵ�����Ϊ1,�ı����������������ݼ��Ŀ�ʼ,�� ��h.g.wellls��ʱ�����������ͼ˵������θ������ں���ǰ���ַ���������һ���ַ�����ѵ��������,���Ƕ�ÿ��ʱ�䲽�����������������softmax����,Ȼ��ʹ�ý�������ʧ�������������ͱ�ǩ֮������������ز�������״̬��ѭ������,ʱ�䲽��3 O3����������ı����� ��the��, ��time��, "machine "����������ѵ�����������е���һ������ ��by��,ʱ�䲽��3����ʧ��ȡ���ڻ������� ��the������time����"machine "�����ʱ�䲽��ı�ǩ "by "��������һ���ʵĸ��ʷֲ���
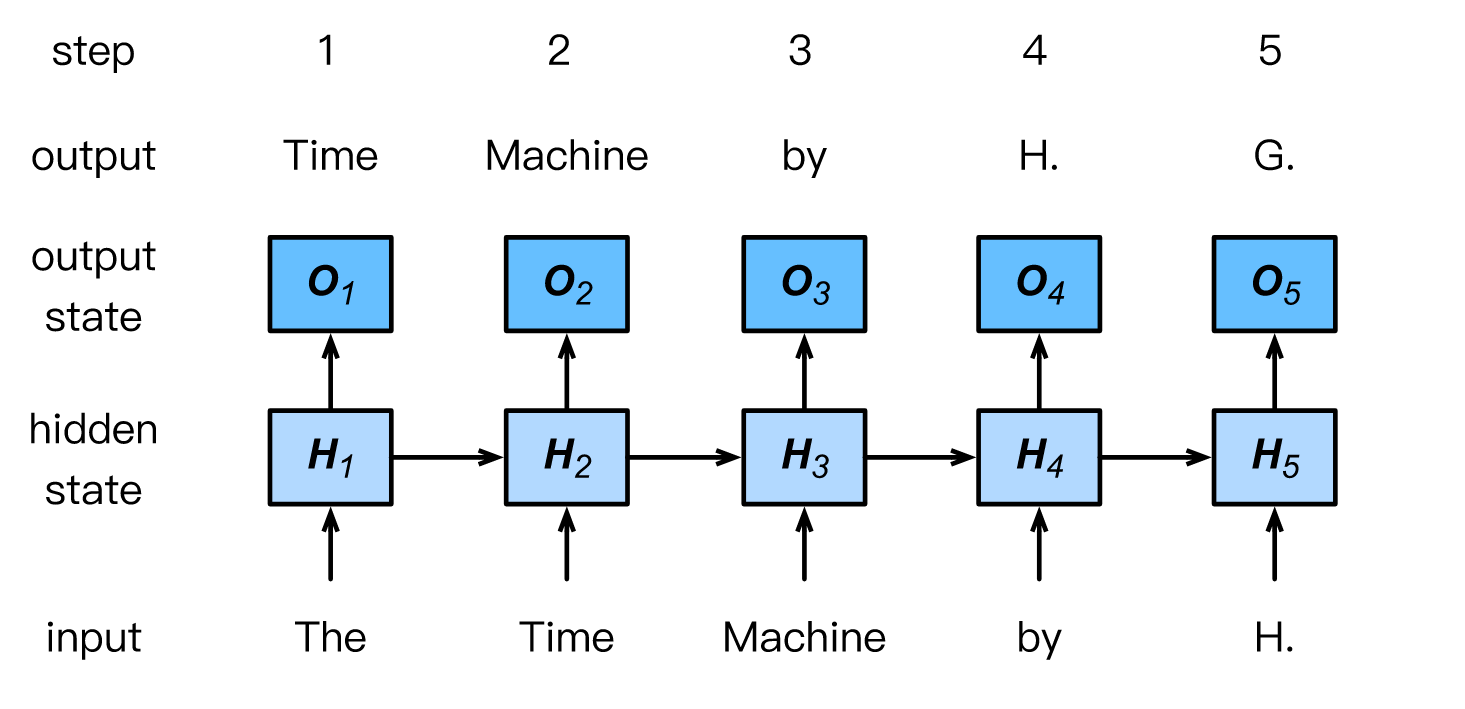
?
�ʼ�RNN����ģ�͡�����ͱ�ǩ���зֱ���The Time Machine by H.��Time Machine by H. G.��
���ַ����������,���ʵ������Ǿ�ġ������Ϊʲô�ܶ�ʱ�����ǻ�ʹ��һ���ַ�����RNN�����档�ڽ������ļ�����,���ǽ�������ʵ�֡�
�塢ժҪ
-
һ��ʹ�õݹ��������类��Ϊ�ݹ�������(RNN)��
-
RNN������״̬���Բ���ֱ����ǰʱ�䲽�������е���ʷ��Ϣ��
-
RNNģ�Ͳ�����������������ʱ�䲽�������Ӷ�������
-
����ʹ��һ���ַ�����RNN����������ģ�͡�
������ϰ��
1�������һ��RNN��Ԥ��һ���ı������е���һ���ַ�,��Ҫ���ٸ����ά��?
2�����һ��ӳ��,�������ӳ��,��������״̬��RNN�Ǿ�ȷ����?��ʾ�C��������������ô��?
3�����ͨ��һ�������н��з���,�ݶȻᷢ��ʲô�仯?
4��������������ģ���йص���������Щ?