1.No free lunch theorem
机器学习中存在大量的各类不同模型,想要找到一个最好的模型适用不同的场合和不同的数据,这通常是不可能的,没有一个简单的所谓最好的模型能够适应不同的问题,这就是没有免费的午餐定理(No free lunch theorem)。原因在于不同的模型可能基于一定的假设(或称之inductive bias),而这些假设在特定的domain内表现的很好但在另一些domain可能表现很差。
2.Occam's Razor
? 奥卡姆剃刀(Occam's Razor)原理是指,在各种科学研究任务中,应该优先使用较为简单的公式或原理,而不是复杂的。 应用到机器学习任务中,可以通过减小模型的复杂度来降低过拟合的风险,即模型在能够较好拟合训练集(经验风险)的前提下,尽量减小模型的复杂度(结构风险)。
3.BIC
在机器学习涉及多个模型的选取的问题(model selection)时,除了采用K折交叉验证外,一个更为有效的方法是计算模型的后验分布,具体如下
????????????????????????????????????????????????
通过计算得到,? ? ?,这就是所谓的Bayesian model selection。
如果选择模型的先验分布为均匀分布,,上述
的计算只与
有关,这就等价于最大化
????????????????????????????????????????????????
上述结果称为边缘似然(marginal likelihood)或积分似然(integrated likelihood)或模型 ?的证据(evidence)。通常情况下计算上述边缘似然对应的积分表达式有点困难,一个通行的简化做法是计算Bayesian information criterion(BIC),
????????????????????????????????????????
如果定义模型的自由度??,
?是模型中变量的数量,就能得到:
????????????????????????????????????? ? ? ? ??
BIC方法非常接近于最小描述长度MDL(minimum description length principle),也就是一个模型拟合数据的评分(log-likelihood)减去定义模型的复杂度,可以理解为带有惩罚项的log-likelihood。
4.AIC
与上述BIC/MDL非常相似的一个就是AIC信息准则(Akaike information criterion),定义如下
????????????????????????????????????????
这个所谓的AIC源于频率派视觉得出,不同于贝叶斯派,所以上述不能理解为边缘似然的一个近似,然而这个表示形式与BIC非常相似。通过对比两者可知,AIC的惩罚项小于BIC,这使得AIC通常能选择更为复杂的模型,最终能够得到更好的预测准确性。
5.第一类最大似然
在统计与概率论中,估计统计模型参数的一个常用方法是使用MLE(Maximum likelihood estimation),具体定义如下
????????????????????????????????????????????????????????
上述MLE对应的似然通常称之为第一?类最大似然。
6.第二类最大似然
当使用Bayesian 方法时,为了评价边缘似然的效果,并不局限于采用网格法取有限值进行比较,而是采用数值优化方法,具体如下
????????????????????????????????????????????????????????????????
上述参数 是超参数,这种方法叫做经验贝叶斯方法或者第二类最大似然估计方法,与采用交叉验证评价不同超参数的模型,采用该方法更有效。
7.Simpson's paradox
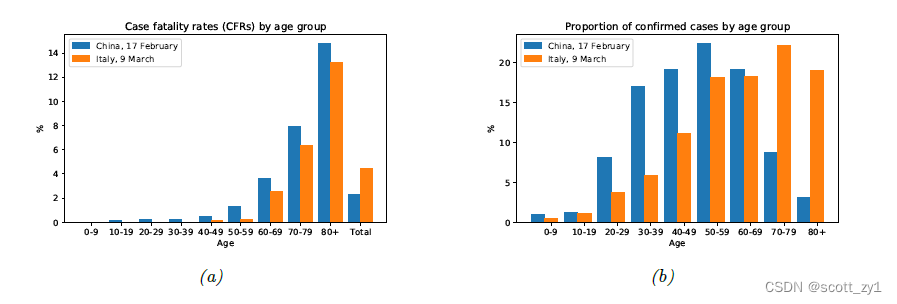
辛普森悖论(Simpson’s paradox)指的是统计上在各个分组中得到的趋势或结论,当各个分组合并到一起统计时得出的结论会出现刚好相反的结果,举例如下。在图a中 统计对比中国和意大利各年龄段感染新冠病毒的致死率,各个年龄段的致死率中国都比意大利高,但是汇总的致死率却是意大利高于中国,原因在于意大利有更高的老龄化(老年人比例)。图a给出的是?,其中
分别表示年龄和国家,
?表示感染新冠致死这一事件。图b给出的是?
?表示在给定国家?
?时在人群在各个年龄组的概率,对比下图a,b主要的差异在于
????????????????
????????????????
8.Berkson's paradox
比如以预测下雨这一事件为例,分别表示下雨和不下雨事件,
?表示下雨的概率,根据先验知识满足?
,?如果看到草地是湿的推测会下雨的概率达到了?
,其中?
?表示草地湿的这一事件,
表示草地是干的,在此基础上如果看到了有洒水器
?这一事件,此时推测下雨的概率为
, 上述一些观察结果的多种原因之间的这种消极相互作用被称为解释效应,也被称为伯克森悖论。
9.black swan paradox
在bayes估计中为了避免zero-count的问题,通过平滑法 add-one smoothing ,比如投掷硬币试验只试验了一次,那么直接基于bayes估计得到头朝上的概率
???????????????????????????????????????????????????????????????,
采用 add-one smoothing(可以通过基于一个先验分布计算后验概率),
??????????????????????????????????????????????????????????????????????
这也就是通过经验数据与先验知识来避免不可能存在的这种推测结果(黑天鹅悖论即不可能出现的情形)。
10.one-standard error rule
对于机器学习的训练任务,训练数据的经验风险 loss-function 定义如下
????????????????????????????????????????????????
通过经验风险最小化来得到需要的模型。当训练样本有限时,通常使用交叉验证方法Cross-validation 训练数据集分为 K-folds 可以得到多个不同的模型对应有不同的超参数 ,
????????????????????????????????????????
其中表示K-fold 数据集,?
???????表示K-fold 数据集外的其它数据?,那么,第n个样本集对应的loss
????????????????????????????????????????
其中的超参数??基于除了第 n 个样本集之外的数据训练得到。计算经验均值与经验方差如下
????????????????????????????????????????
????????????????????????????????????????
假定我们应用交叉验证(cross validation)于一组模型,并计算其估计loss的平均值与标准差
,从这些带噪声估计值中选择模型的一种常见的启发式方法就是,选择与最佳模型的经验风险不超过一个标准误差的最简单模型;这被称为一个标准差准则(one-standard error rule),具体如下:
????????????????????????????????????????????????
上述?分别为最简单模型和最佳模型对应的loss。