什么是数据挖掘
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
听起来比较抽象,我们举个例子。
傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞,嗯,明天又是一个好天气。走到水果摊旁,挑了个根蒂蜷缩、敲起来声音浊响的青绿西瓜,心里期待着享受这个好瓜。
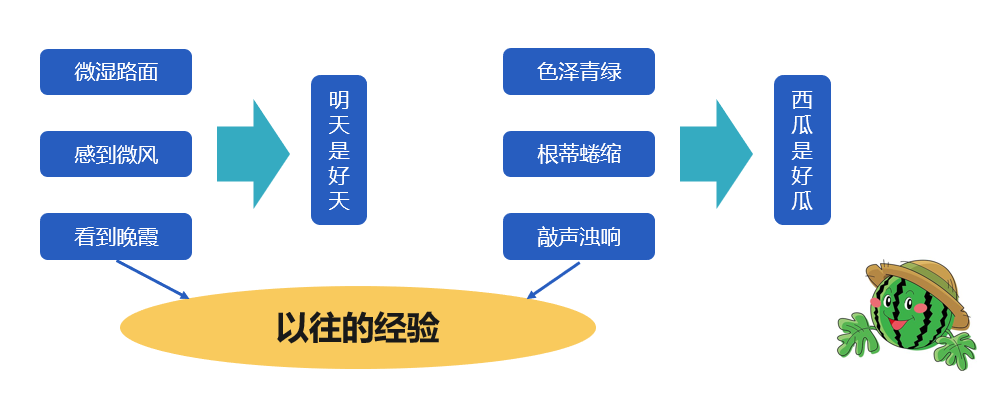
由路面微湿、微风、晚霞得出明天是个好天气。根蒂蜷缩、敲声浊响、色泽青绿推断出这是个好瓜,显然,我们是根据以往的经验来对未来或未知的事物做出预测。
人可以根据经验对未来进行预测,那么机器能帮我们做这些吗?
能,这就是数据挖掘。
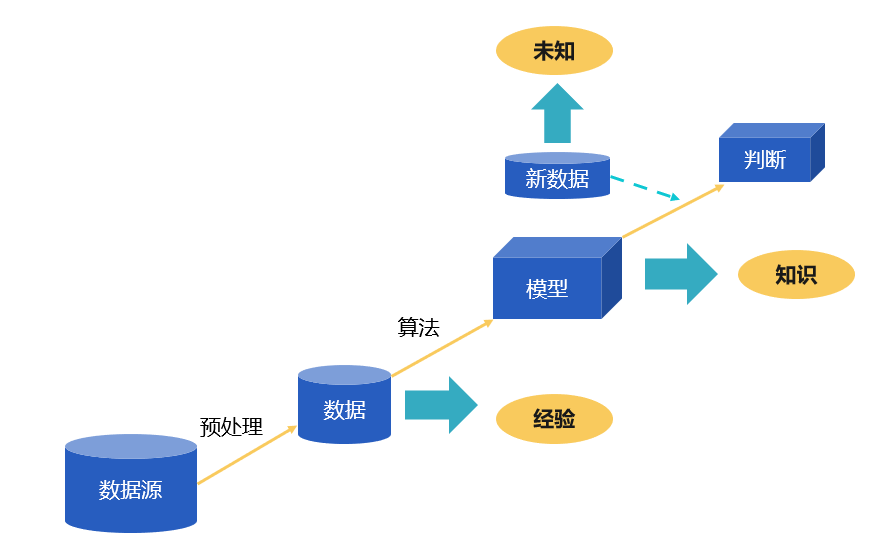
“经验”通常以“数据”的形式存在,数据挖掘的任务就是从历史数据(之前挑瓜的经历,注意是经历还不是经验)中挖掘出有用的“知识”,也就是所谓“模型”(现在就形成经验了),在面对新情况时(未抛开的瓜)模型就可以用来预测(是不是好瓜)。
用高中生能理解的数学语言来讲,数据挖掘建模任务的本质就是,根据一些历史已有的、从输入空间 X(如 {[色泽青绿;根蒂蜷缩;敲声浊响],[色泽乌黑;根蒂蜷缩;敲声沉闷],[色泽浅白;根蒂硬挺;敲声清脆]} )到输出空间 Y(如 {好瓜,坏瓜,坏瓜})的对应,找出一个函数 f,来描述这个对应关系,这个函数就是我们要的模型。
有了模型之后再做预测就简单了,也就是拿一套新 x,用这个函数算一个 y 出来就完了。

那么,模型又是怎么建立出来,也就是这个函数是怎么找出来的呢?
想想如何让一个人拥有判断瓜好坏的能力呢?
需要用一批瓜来练习,获取剖开前的特征(色泽、根蒂、敲声等),然后再剖开它看好坏。久而久之,这个人就能学会用剖开前瓜的特征来判断瓜的好坏了。朴素地想,用来练习的瓜越多,能够获得的经验也就越丰富,以后的判断也就会越准确。
用机器做数据挖掘是一样的道理,我们需要使用历史数据(用来练习的瓜)来建立模型,而建模过程也被称为训练或学习,这些历史数据称为训练数据集。训练好了模型后,好像发现了数据的某种规律,就可以拿来做预测了。
也就是说,数据挖掘是用来做预测的,而要做到这种预测,需要有足够多已经有结果的历史数据为基础。

数据挖掘能干什么
那么,这种预测技术如何应用在我们的生产销售过程中呢?
以贷款业务为例,金融机构要做风险控制,防止坏帐,就要在放贷前知道这个贷款人将来不能按时还款的风险,从而决定是否放贷以及贷款利率。
要做到这件事,我们要有一定数量的历史数据,也就是以前贷款人及贷款业务的各种信息,比如贷款人的收入水平、受教育程度、居住地区、信用历史、负债率等等可能会影响违约率的因素,还有贷款本身的金额、期限、利率等等。
然后就可以使用数据挖掘技术建立模型来寻找用户及贷款的各种信息 X 和是否会发生违约 Y 之间的关系。
建好的模型可以用来预测,及时发现高风险用户。

需要说明的,数据挖掘模型的预测并不能保证 100%准确(比如再有经验的瓜农也有选错瓜的时候),如果只有一例目标(比如只有一笔贷款)需要预测时,那就没有意义了。但通常,我们都会需要预测很多例目标,这样即使不是每一例都能预测正确,但能保证一定的准确率,这仍然是很有意义的。
对于贷款业务,模型找出来的高风险客户未必都是真的,但准确率只要足够高,仍然能够有效的防范风险。
数据挖掘技术的应用非常广泛,比如工业领域中可以根据历史生产数据来预测良品情况,从而改进工艺参数降低不良率;畜牧业可以使用数据挖掘技术根据测量牲畜体温来预测牲畜是否生病,从而提前防治;医院也可以使用历史医疗记录基于数据挖掘技术找出关联规律,帮助医生更好地诊断疾病。
总之,只要是有数据有场景几乎都会考虑用数据挖掘解决某些问题。

数据挖掘需要哪些流程
通常一个完整的数据挖掘项目包含业务理解、数据理解、数据准备、数据预处理和建模、模型评估、模型部署应用。

业务理解的主要工作有需求调研,了解商务背景;明确业务目标和成功的标准。数据理解和业务理解一般是同时进行的,主要内容包括确定建模所需要的数据,描述数据,探索数据,检验数据质量,明确数据挖掘目标和成功标准。这两个阶段的主要任务就是明确挖掘目标和建模数据,目标和数据都明确以后就可以开始着手准备数据。
数据准备的主要工作包括选择数据、清洗数据、构造数据、整合数据、格式化数据等等。如果企业的数据仓库建设比较完善,那么这个步骤的工作就非常简单,只需要做一些数据筛选,表间关联工作即可。反之,如果数据都是一些非常原始的数据比如日志数据、流水数据,数据准备这部分就比较耗费时间和精力了,需要做很多数据汇总,特征提取的工作。
数据预处理和建模,这个环节是整个项目中技术难度最大的部分,通常必须由专业的挖掘工程师来完成。虽然,通俗地看,建模就是我们前面说过的在挑瓜过程中积累经验的事情,但实际上针对大量数据时仍然非常复杂。不同类型的数据和不同的预测目标会有不同的积累经验方案,也就是不同的算法。业界有数十种数据挖掘的算法,各有各的适应场景和数据要求以及参数,都需要根据实际情况来选择使用和准备数据并调整参数。这个阶段的主要工作有:样本选取,确定训练样本和测试样本、数据预处理、模型算法技术选型、筛选变量、模型训练、模型测试等。
需要理解的是:(1)数据预处理是非常有必要的,好的预处理往往比单纯的调参更能提高模型性能;(2)预处理和建模过程并非一次性执行完毕就大功告成了,需要不断的迭代优化,才能获得比较理想的结果。
模型评估,是对模型进行较为全面的评价的过程,计算模型的各种指标,比如 AUC,Gini,KS,Lift,模型稳定性等等,这样才能判断出建出来的模型是不是足够好。然后再进行模型的业务应用测试,判断是否能实现商业目标。模型合格后,就可以部署应用,即把数据挖掘的成果部署到商业环境,应用于生产活动。

普通人能用数据挖掘做预测吗?
既然,数据挖掘是一项很实用的技能,那么普通人能学会吗?
从数据挖掘的流程来看,最难掌握的就是数据预处理和建模部分,而其他部分看起来专业术语也不少,但只要稍加学习都能掌握,没什么技术难度。
为什么说预处理和建模部分难学。因为这部分对数学能力的要求较高,一般只有统计学或数学相关专业的人士才具备相关的能力,普通人要想掌握,需要学习很多数学相关的课程,比如,概率论,数理统计,线性代数,随机过程……,这些知识是难以速成的。

虽然在 Python 里有很多现成的算法包,通过调包也能建出模型,但不懂得数学原理模型效果又如何保证呢?比如精确度不好,或者不稳定。如果没有充分的数学知识就不知道如何改进,只能无方向的随机尝试,如同大海捞针。
例如,5% 的顾客没有指定年龄,是整体忽略该变量,还是忽略这部分有缺失的样本,又或者是将缺失值补充完整(使用平均值填充还是中位数填充又或者更复杂的方法的填充),或者是训练一个带这个特征的模型,再训练一个不带这个特征的模型。同样是缺失值处理,当缺失率为 90% 时,是否还采用相同的处理方法呢。
再例如,高基数变量如何处理,数据噪音如何处理,不平衡样本,高偏数据,各种模型参数……
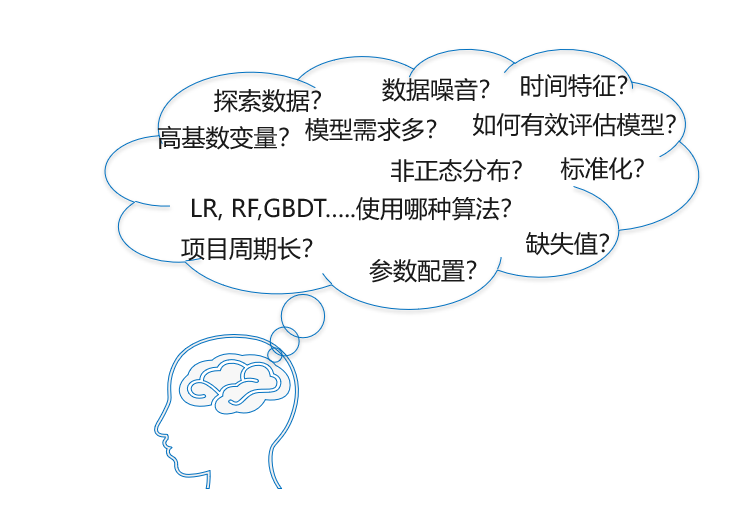
这些都需要建模师结合自己的知识和经验反复的去调试。要知道,有专业知识的选手其实也会用这些现成的函数包,但建一个好模型通常仍然要几天甚至数周时间,其中大部分时间都是在不断地调整优化。并不是把数据往算法里一丢就完事的。
虽然有了封装好的算法,要学会数据挖掘,也还是要学数学,学算法。这事在培训班中速成是没有戏的。

那么,对于普通人来说还有没有什么办法不学这些晦涩难懂的知识也能做数据挖掘呢?
答案是,有的。那就是利用工具,自动数据挖掘工具。自动数据挖掘工具将建模所需要知识和流程整合起来,这样就可以利用前人的知识自动建模和预测了。借助自动建模工具,我们只需要完成业务理解,数据准备过程,剩下的难度较大,并且需要反复迭代进行的建模过程尽可交给工具来完成。
这样解决掉最难的部分,剩下的环节就容易多了,只要熟悉业务,了解一些基本概念,就能够用数据挖掘做预测了。

有哪些简单易用的数据挖掘工具?
既然工具可以帮助我们解决技术难度最大的部分,那么有哪些好用的自动建模工具可以供大家使用呢?
实际上市面上已经有不少很受欢迎数据挖掘工具,比如 weka,rapidminer,knime 等,不过大部分的工具还是比较沉重,安装使用都比较复杂。这里向大家推荐一款无基础人士也能用的简单工具:由国内著名数据软件公司润乾出品的易明建模。
易明建模采用的是全自动化的建模流程,只需一键式的操作就能够自动进行预处理和模型搭建。什么缺失值,异常值,高基数变量,时间特征……统统不用担心,还有算法选择,参数寻优等,易明建模都会自动帮你搞定。

在算法种类方面易明建模涵盖了常用的机器学习算法,比如线性回归,逻辑回归,树类算法,集成算法,pca 等,能够解决分类问题,回归问题和时间序列问题,大部分的商业场景问题都能用。
在模型质量方面,易明建模拥有顶级科学家的经验和理论,并且经过了大量的实践验证。远超培训班选手,能够达到中上等数据挖掘师的水平。当然作为一个通用的数据挖掘软件,和苦读 N 年的专业选手精心调出来的模型可能还会稍差一些,但对于大多数的场合已经足够用了。
易明建模还有一大亮点,就是耗费资源少,建模速度快。百万级的样本量,PC 机也能跑,万级的样本量,更是几分钟就搞定。当然巧妇难为无米之炊,如果数据量太少也是不行的。
借助易明自动建模,普通人也能做数据挖掘,重要的是,这么好用的软件竟然还是免费的,免费的羊毛不薅白不薅。直接到润乾的官网上就可以下载。

虽然借助自动建模可以省去学习算法原理的过程,但是数据挖掘流程的其它部分也还是需要了解一些基本的知识,起码要学会评估模型,知道我们建出的模型到底好不好。
比如模型质量,因为是用于预测,我们很容易简单地想像可以用准确率来评估,然而并不是。数据挖掘模型的质量通常会用一个叫做 AUC 的指标来评估,比单纯一个准确率复杂得多。不同的场景侧重的指标也不相同,比如还有查全率,提升度等。如果是回归问题则需要用 mse, rmse, ……来评估。如果这些都不懂,那样就算能建出模型也是一头雾水。

好在,这些东西虽然听起来有点复杂,但其实学起来并不难,只要有高中数学基础,花一两周时间就能理解学会了,这属于可速成的知识。和学数学,学算法相比,相当于打了一个粉碎性折扣。
这里有一套课程可以看http://www.raqsoft.com.cn/wx/course-data-mining.html,从零开始,深入浅出讲解数据挖掘的基础概念和实用知识,特别偏重从应用的角度教大家如何做数据挖掘,课程中的一些案例也来源于真实业务场景,很适合没什么基础的人看。
