????????2012年Alex Krizhevsky(论文第一作者),Ilya Sutskever(OpenAI研发主管),Geoffrey E. Hinton(深度学习之父)的一篇划时代的论文,英文版地址:ImageNet Classification with Deep ConvolutionalNeural Networks 是深度学习的奠基之作,其中前两位大神都是Hinton的学生,使用的数据集是来自李飞飞创建的ImageNet(这个数据集推动了计算机视觉和机器学习研究进入新的阶段)
????????前面介绍的MXNet使用GPU训练LeNet模型在小数据集上能取得好的成绩,但是在更大的真实数据集上的表现就不怎么好了,比如现在这个ImageNet数据集,120万张高分辨率的图片,以及里面包含6000万个参数和65万个神经元。对于这样的超大数据集,于是AlexNet就横空出世了。
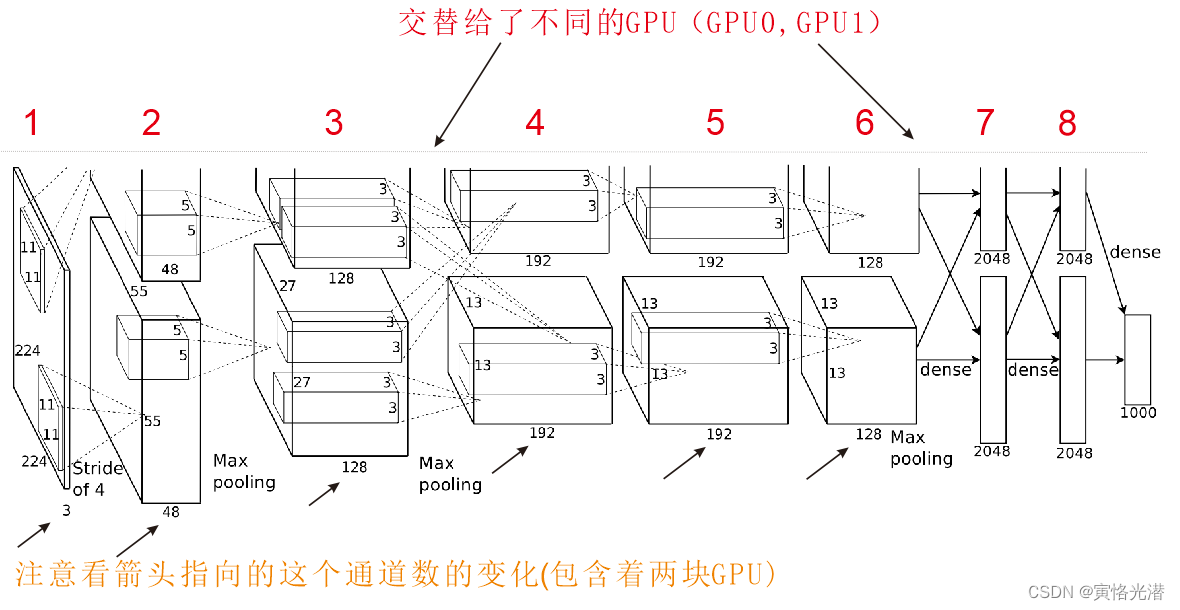
AlexNet与LeNet设计理念非常相似,以下是它的显著区别
1、AlexNet网络层加深了,有8个卷积层(5层卷积层和2层全连接隐藏层,以及1个全连接输出层)
图中可以看出,第一层卷积核尺寸是11*11,因为图像的宽高都比较大,所以卷积核的窗口不能太小,第二层卷积窗口就减小到了5*5,后面的3个卷积层形状都采用3*3,最大池化层的窗口形状为3*3,步幅为2,另外这个AlexNet的卷积通道数也数十倍于LeNet中的卷积通道数。
紧接着最后一个卷积层的是两个输出个数为4096(每块GPU是2048),因为参数接近1GB,所以受限于当时的显存的大小,不过对于这种分割设计,一些超大型的模型还是很有用处的,毕竟一块GPU有时会搞不定
2、AlexNet将sigmoid激活函数修改成了简单的ReLU激活函数,主要是当sigmoid激活函数输出极接近0或1时,这些区域的梯度几乎为0,从而造成反向传播无法继续更新部分模型参数;而RelU激活函数在正区间的梯度恒为1。因此,如果模型参数初始化不当,sigmoid函数可能在正区间得到几乎为0的梯度,从而令模型无法得到有效训练。RelU也被成为非饱和的非线性激活函数,也就是说它没有将输入给挤压,除了小于0的置0之外,其他都是保留输入的,不像sigmoid和tanh这类有挤压(饱和)的激活函数,将输入固定在了0到1或-1到1之间的区间。
3、AlexNet通过丢弃法来控制全连接层的模型复杂度,而LeNet没有采用。这也是一种很好的抑制过拟合的方法
4、AlexNet引入了大量的图像增广,如翻转、裁剪、和颜色变化,从而进一步扩大数据集缓解过拟合,因为前面文章有介绍,数据集小的话很容易产生过拟合。
????????当然这些区别点以及优势,也不是他们第一次提出,论文也可以看到有26处引用,虽然是集合了很多人已做过的方法,但还是提出了很多创新的东西,对以后的深度学习产生了深远地影响,不然也不会说是一篇奠基之作了。由于这个ImageNet数据集太大,本人只有一块2G的GPU,所以还是选择原来的FashionMNIST数据集来演示,也没有用到论文中所说的切割到两块GPU中的做法。
import d2lzh as d2l
from mxnet import gluon,init,nd
from mxnet.gluon import data as gdata,nn
import os
import sys
import mxnet as mx
net=nn.Sequential()
#论文中是两块GPU,所以通道数两块之和的值
net.add(nn.Conv2D(96,kernel_size=11,strides=4,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
nn.Conv2D(256,kernel_size=5,padding=2,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(384,kernel_size=3,padding=1,activation='relu'),
nn.Conv2D(256,kernel_size=3,padding=1,activation='relu'),
nn.MaxPool2D(pool_size=3,strides=2),
#全连接层,接着使用Dropout丢弃层
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
nn.Dense(4096,activation='relu'),nn.Dropout(0.5),
#由于没有使用ImageNet数据集,这里也不是论文中的1000
nn.Dense(10)
)
X=nd.random.uniform(shape=(1,1,224,224))
net.initialize()
for layer in net:
X=layer(X)
print('输出形状:',X.shape)
'''
输出形状: (1, 96, 54, 54)
输出形状: (1, 96, 26, 26)
输出形状: (1, 256, 26, 26)
输出形状: (1, 256, 12, 12)
输出形状: (1, 384, 12, 12)
输出形状: (1, 384, 12, 12)
输出形状: (1, 256, 12, 12)
输出形状: (1, 256, 5, 5)
输出形状: (1, 4096)
输出形状: (1, 4096)
输出形状: (1, 4096)
输出形状: (1, 4096)
输出形状: (1, 10)
'''现在我们来训练模型,在读取数据之前我们做了数据增强,将图像的高和宽扩大到224,通过Resize实例来实现,其中训练的方法在 MXNet使用GPU训练LeNet模型 有出现,也是包含在d2lzh包中,如果是CPU训练,本人是i5-7500直接就爆了,没法训练,于是切换成GPU
#已包含在d2lzh包中
def load_data_fashion_mnist(batch_size,resize=None,root=os.path.join('~','.mxnet','datasets','fashion-mnist')):
root=os.path.expanduser(root)#将~替换成当前用户目录,如C:\Users\Tony\.mxnet\datasets\fashion-mnist
transformer=[]
if resize:
transformer+=[gdata.vision.transforms.Resize(resize)]#[Resize()]
transformer+=[gdata.vision.transforms.ToTensor()]#[Resize(), ToTensor()]
transformer=gdata.vision.transforms.Compose(transformer)#Compose((0): Resize()(1): ToTensor())
mnist_train=gdata.vision.FashionMNIST(root=root,train=True)
mnist_test=gdata.vision.FashionMNIST(root=root,train=False)
num_workers=0 if sys.platform.startswith('win32') else 4
train_iter=gdata.DataLoader(mnist_train.transform_first(transformer),batch_size,shuffle=True,num_workers=num_workers)
test_iter=gdata.DataLoader(mnist_train.transform_first(transformer),batch_size,shuffle=False,num_workers=num_workers)
return train_iter,test_iter
batch_size=50
train_iter,test_iter=load_data_fashion_mnist(batch_size,resize=96)#论文是224
lr,num_epochs,ctx=0.01,5,d2l.try_gpu()
#lr,num_epochs,ctx=0.01,5,mx.cpu()
net.initialize(force_reinit=True,ctx=ctx,init=init.Xavier())
trainer=gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':lr})
d2l.train_ch5(net,train_iter,test_iter,batch_size,trainer,ctx,num_epochs)
[12:21:13] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (set the environment variable MXNET_CUDNN_AUTOTUNE_DEFAULT to 0 to disable)
training on gpu(0)
epoch 1, loss 1.5937, train acc 0.396, test acc 0.577, time 69.4 sec
epoch 2, loss 0.7274, train acc 0.724, test acc 0.774, time 68.6 sec
epoch 3, loss 0.5738, train acc 0.784, test acc 0.798, time 70.7 sec
epoch 4, loss 0.4959, train acc 0.813, test acc 0.825, time 71.0 sec
epoch 5, loss 0.4489, train acc 0.833, test acc 0.847, time 70.2 sec训练时间比较长,显存小了的原因吧,本人是Geforce GTX 1050,2G显存(命令:dxdiag)
上面那个提示可以禁用,在Linux与Windows分别设置如下:
export MXNET_CUDNN_AUTOTUNE_DEFAULT=0
set MXNET_CUDNN_AUTOTUNE_DEFAULT=0
最后我们看到实现的AlexNet只比LeNet好像只多了几层而已,其实里面的新思想的产生以及优秀的实验结果,是需要学术界付出很多年才能有这样的成果的。