论文题目:
Do Vision Transformers See Like Convolutional Neural Networks?
论文链接:
http://arxiv.org/abs/2108.08810
Transformer 处理图像时获取的特征是否和之前主流的 CNN 有所区别?
基于这样的动机,Google用Centered Kernel Alignment (CKA)对ResNet和ViT的一些关键层进行了检验。首先了解一下CKA这种方法。CKA是Google在2019年提出的,用于衡量神经网络中层与层之间相似度的指标 [3]。这个指标的优势在于,它能够确定基于不同随机初始化和不同宽度训练的神经网络的隐藏层之间的对应关系。因此,适合用于寻找ResNet和ViT中是否存在有对应的网络层。
利用CKA,研究者发现ResNet和ViT在最接近输入的网络底层(lower layer)时,表征的内容持有较大的相似度;然而,由于两个网络处理表征的方式有很大区别,在层层传递之后,在接近输出的网络上层(higher layer)两者的表征最终区别很大。
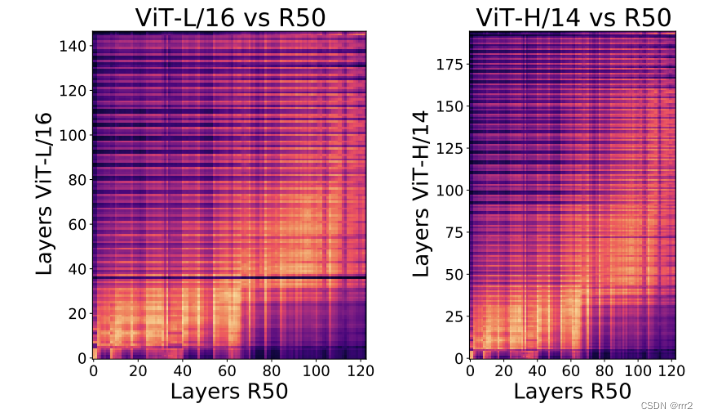
两个在底层表征上有相似之处的网络,居然长着长着发展到了两个方向。
原因1 在整合全局信息的能力上存在差异
因为ResNet在处理输入时,需要经过更多层才能获得类似于ViT底层的表征,由此引发了一个合理的猜想:两个网络在整合全局信息的能力上存在差异。
为了验证这个想法,研究者先是对ViT的不同层中,注意力集中区域的距离进行的计算,他们发现,ViT无论是低层还是高层,都是局部和全局信息混杂的,相比之下,ResNet更为严格地遵守从局部特征提炼全局特征的处理过程。这是导致两个网络中表征的差异逐层增加的一大关键因素。
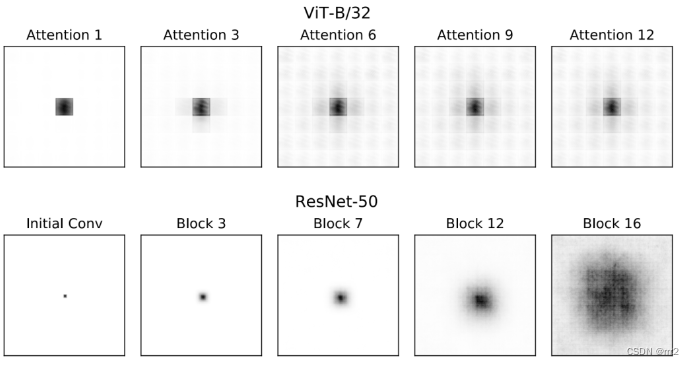
ResNet的有效感受域有一个明确地从局部“生长”到全局的过程,而ViT只是在感知局部和全局信息的权重上发生调整
原因2 ViT从底层到高层的相似度比ResNet高
另一方面,这种差异的原因还可能来自ViT从底层到高层的相似度比ResNet高的这一现象。研究者认为,是ViT中的跳跃连接结构 (skip connection)保护了底层到高层的表征传递,如下图所示,如果撤掉特定块区上的这种连接结构,对应的表征信息就会立刻“失传”。
由于上述在处理信息过程上的差异,最终,ViT的高层表征能够更精细地保留局部空间信息。尤其是到了最后分类的关键时刻,ResNet还进行了一次全局的平均池化,进一步显著地减少了高层中局部信息的精细度。
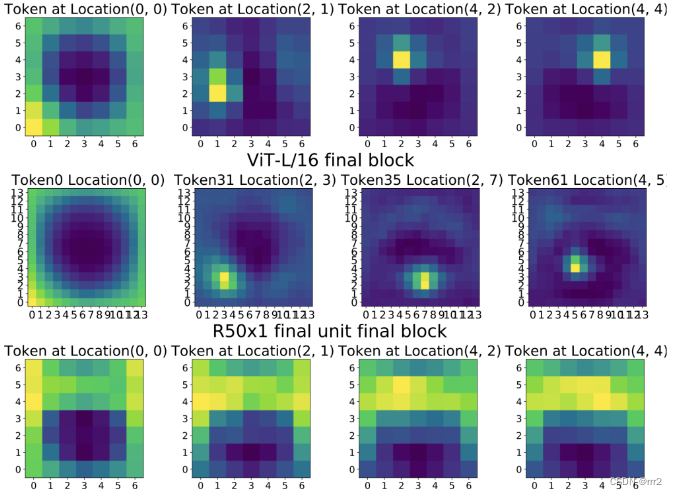
通过全方位的比较,包括将隐藏层揪出来细细观察。最终,研究者下定结论:虽然它们在性能上不相上下,但以ResNet为代表的CNN与ViT在处理信息的工艺原理上大相径庭。
Google这次的工作其实是把大家直觉性经验性的结论用可复现的实验规范地落在了纸上,并且努力夸夸ViT,好吸引更多研究者采用。在整个验证过程中,ViT模型是Google的,JFT-300M数据集是Google的,CKA度量指标也是Google的
ref
https://www.zhuanzhi.ai/document/2e54a4e67814e53b2f72a1dc958cbe69