
撰文|赵露阳
算子即Operator,这里简称op。op是深度学习的基础操作,任意深度学习框架中都包含了数百个op,这些op用于各种类型的数值、tensor运算。
在深度学习中,通过nn.Module这样搭积木的方式搭建网络,而op就是更基础的,用于制作积木的配方和原材料。
譬如如下的一个demo网络:
import oneflow as torch
class TinyModel(torch.nn.Module):
def __init__(self):
super(TinyModel, self).__init__()
self.linear1 = torch.nn.Linear(100, 200)
self.activation = torch.nn.ReLU()
self.linear2 = torch.nn.Linear(200, 10)
self.softmax = torch.nn.Softmax()
def forward(self, x):
x = self.linear1(x)
x = self.activation(x)
x = self.linear2(x)
x = self.softmax(x)
return xtinymodel = TinyModel()print('The model:')print(tinymodel)从结构来看,这个网络是由各种nn.Module如Linear、ReLU、Softmax搭建而成,但从本质上,这些nn.Module则是由一个个基础op拼接,从而完成功能的。这其中就包含了Matmul、Relu、Softmax等op。?在OneFlow中,对于一个已有op,是如何完成从Python层->C++层的调用、流转和执行过程?本文将以
output = flow.relu(input)为例,梳理一个op从Python -> C++执行的完整过程。首先,这里给出一个流程示意图:
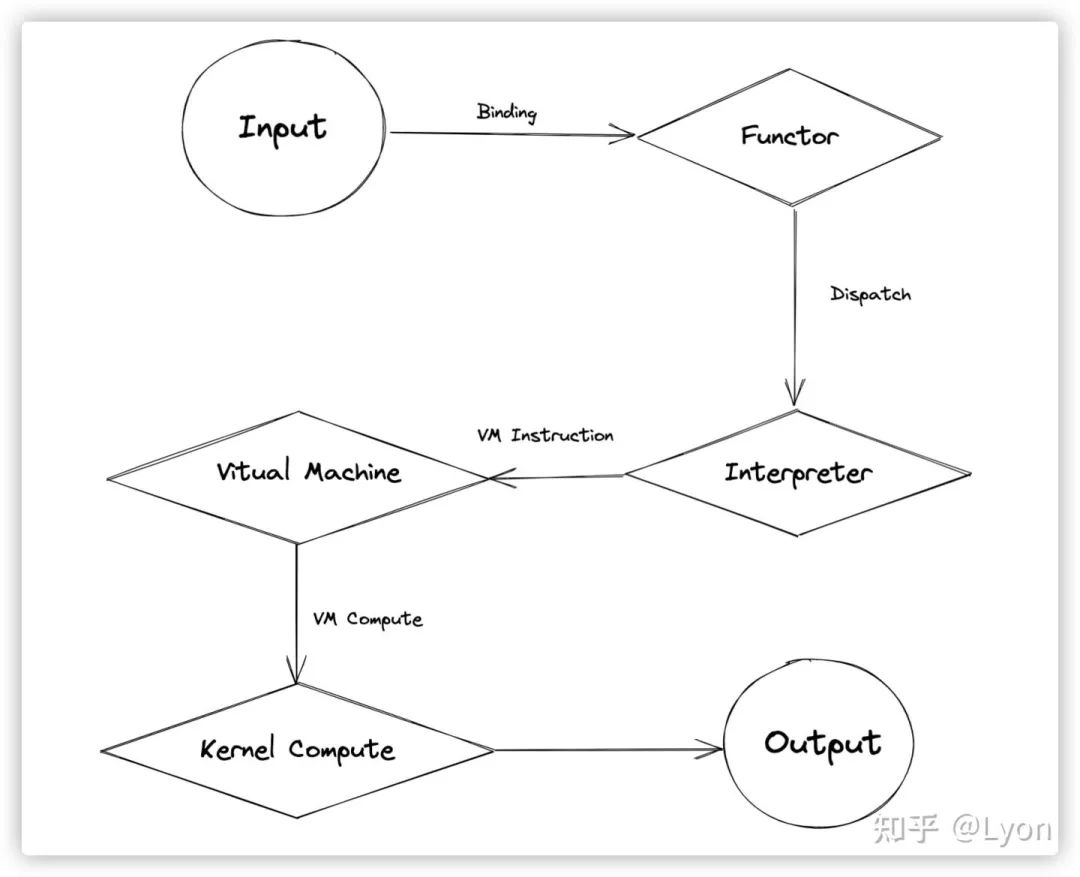
下面,将分别详细从源码角度跟踪其各个环节。
1
Binding
这里,binding是指Python和C++代码的绑定。通常,我们用Python搭建网络,训练模型,调用函数完成各种操作。实际上,这些函数通常在Python层只是一层wrapper,底层实现还是通过C++代码完成的,那么Python -> C++是如何调用的?这就需要用到Python和C++的绑定。
在深度学习框架的实现中,即可以用Python原生的C?API,也可以通过pybind11来完成函数绑定,在OneFlow中,二者均有使用,譬如:
-
oneflow/api/python/framework/tensor.cpp
-
oneflow/api/python/framework/tensor_functions.cpp
中涉及到的 tensor.xxx 方法都是通过Python C?API完成了函数绑定;
-
oneflow/core/functional/functional_api.yaml
中定义的诸多 flow.xxx 方法则是通过pybind实现的绑定。这里关于Python C?API和pybind不做过多介绍,具体用法可以参考相应文档:
-
https://docs.python.org/zh-cn/3.8/c-api/index.html
-
https://pybind11.readthedocs.io/en/stable/index.html
下面我们回到flow.relu方法,我们在Python层调用的flow.relu实际是调用了在
python/oneflow/__init__.py中定义的oneflow._C.relu。?_C表示其实现位于底层C++。和PyTorch类似,我们也基于.yaml定义了一套接口导出及code gen的规则,譬如在 functional_api.yaml 中,我们可以看到Relu的导出接口的函数签名:
- name: "relu"
signature: "Tensor (Tensor x, Bool inplace=False) => Relu"
bind_python: True从yaml定义可以看出,flow._C.relu 接收两个参数,tensor和一个bool值,其绑定了C++的Relu方法,函数返回值也是tensor。实际上,在OneFlow编译时,会通过执行
tools/functional/generate_functional_api.py这个文件,对 functional_api.yaml 进行解析和代码生成,动态生成C++的.h和.cpp文件。
-
build/oneflow/core/functional/functional_api.yaml.h
-
build/oneflow/core/functional/functional_api.yaml.cpp
并在.cpp文件中调用相应的functor完成C++层面的函数调用。这里,还是以flow._C.relu为例,其对应的functor定义位于oneflow/core/functional/impl/activation_functor.cpp:
class ReluFunctor {
public:
ReluFunctor() { op_ = CHECK_JUST(one::OpBuilder("relu").Input("x", 1).Output("y", 1).Build()); }
Maybe<Tensor> operator()(const std::shared_ptr<Tensor>& x, bool inplace) const {
...
}
private:
std::shared_ptr<OpExpr> op_;
};?
ReluFunctor通过
ONEFLOW_FUNCTION_LIBRARY(m) {
m.add_functor<impl::ReluFunctor>("Relu");
...
}?
完成functor的注册,注册成functional接口后,在Python层flow._C.relu就完成了和“Relu”的绑定。同时,这个函数在C++中也可以通过functional::Relu直接调用。
2
Functor
Functor不仅是Python -> C++交互的核心,也是op调用、输入参数推导和检查的第一站。通常,各种op在functor层需要完成对输入tensor的shape、dtype、维度、元素个数等各种check,以及对op特有的逻辑进行解析和处理。Relu Functor代码如下:
class ReluFunctor {
public:
ReluFunctor() { op_ = CHECK_JUST(one::OpBuilder("relu").Input("x", 1).Output("y", 1).Build()); }
Maybe<Tensor> operator()(const std::shared_ptr<Tensor>& x, bool inplace) const {
if (inplace) {
JUST(CheckInplaceValid(x));
std::shared_ptr<TensorTuple> outputs = std::make_shared<TensorTuple>(1);
outputs->at(0) = x;
JUST(OpInterpUtil::Dispatch(*op_, {x}, outputs.get(), AttrMap{}));
return outputs->at(0);
} else {
return OpInterpUtil::Dispatch<Tensor>(*op_, {x});
}
}
private:
std::shared_ptr<OpExpr> op_;
};可以看见,ReluFunctor是比较简单的,其定义了一个私有变量
std::shared_ptr<OpExpr> op_;这个op_即需要执行的Relu op,通过OpBuilder进行构建;functor的operator()内部,根据是否inplace走到2个不同分支,并最终通过OpInterpUtil::Dispatch()将op、输入tensor和参数派发至Interpreter处理。
3
Dispatch
各种op在functor中完成check和逻辑处理后,大多需要通过OpInterpUtil::Dispatch()?进行派发,其目的地是Interpreter。在Interpreter中,将会对op进行更进一步的处理。在oneflow/core/framework/op_interpreter/op_interpreter_util.h?中,我们可以看见多种重载的Dispatch模板代码:
class OpInterpUtil {
public:
template<typename T>
static Maybe<T> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs, const AttrMap& attrs) {
return Dispatch<T>(op_expr, inputs, OpExprInterpContext(attrs));
}
template<typename T>
static Maybe<T> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs) {
return Dispatch<T>(op_expr, inputs, OpExprInterpContext(AttrMap{}));
}
template<typename T>
static Maybe<T> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs,
const OpExprInterpContext& ctx);
static Maybe<void> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs, const AttrMap& attrs) {
return Dispatch(op_expr, inputs, outputs, OpExprInterpContext(attrs));
}
static Maybe<void> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs) {
return Dispatch(op_expr, inputs, outputs, OpExprInterpContext(AttrMap{}));
}
static Maybe<void> Dispatch(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs, const OpExprInterpContext& ctx);这些重载,是为了应对不同的输入、输出以及OpExprInterpContext的情况。譬如这个OpExprInterpContext是op在Interpreter中所需的上下文,可能携带op计算所需要的属性(如conv2d op所需要的kernel_size、padding等)、device、sbp、parallel等描述信息。这些重载的Dispatch最终都会走到:
/* static */ Maybe<void> OpInterpUtil::Dispatch(
const OpExpr& op_expr,
const TensorTuple& inputs,
TensorTuple* outputs,
const OpExprInterpContext& ctx) {
return JUST(GetInterpreter(inputs, ctx, op_expr))->Apply(op_expr, inputs, outputs, ctx);
}Dispatch至此,剩下的就要交给Interpreter了。
4
Interpreter
Get Interpreter
这里先看看GetInterpreter,这里其实就是获取所需的Interpreter,来负责op接下来的执行。省略check相关的逻辑,主要代码如下:oneflow/core/framework/op_interpreter/op_interpreter_util.cpp
Maybe<AutogradInterpreter> GetInterpreter(const TensorTuple& inputs, const OpExprInterpContext& ctx,
const OpExpr& op_expr) {
static const auto& g_lazy_interpreter = BuildLazyInterpreter();
static const auto& g_eager_consistent_interpreter = BuildEagerInterpreter(/*is_mirrored=*/false);
static const auto& g_eager_mirrored_interpreter = BuildEagerInterpreter(/*is_mirrored=*/true);
if (!LazyMode::is_enabled()) {
if (inputs.empty()) {
if (ctx.parallel_desc.has_value()) {
JUST(ctx.nd_sbp);
CHECK_OR_RETURN(!ctx.device.has_value());
return g_eager_consistent_interpreter;
} else {
CHECK_OR_RETURN(!ctx.nd_sbp.has_value());
return g_eager_mirrored_interpreter;
}
} else {
if (inputs.at(0)->is_consistent()) {
...
return g_eager_consistent_interpreter;
} else {
...
return g_eager_mirrored_interpreter;
}
}
UNIMPLEMENTED_THEN_RETURN();
}
return g_lazy_interpreter;
}通过上面的逻辑可以看出,Interpreter大体上分为Eager Interpteter和Lazy Interpreter;其中Eager Interpteter又根据Eager Mirrored和Eager Consistent有所区别。具体就是以下3种子类实现:
-
EagerMirroredInterpreter
-
EagerConsistentInterpreter
-
LazyInterpreter
普通的Eager mode下(无论是单卡还是DDP的情况)都会走到?EagerMirroredInterpreter?的逻辑;在普通Eager Mode之外,为输入tensor设置了sbp、placement则会进入到EagerConsistentInterpreter的逻辑;在Lazy Mode时(使用nn.Graph),则会进入到LazyInterpreter。
下面,我们看下这3种Interpreter的构建:
std::shared_ptr<AutogradInterpreter> BuildEagerInterpreter(const bool& is_mirrored) {
std::shared_ptr<OpExprInterpreter> internal;
if (is_mirrored) {
internal = std::make_shared<EagerMirroredInterpreter>();
} else {
internal = std::make_shared<EagerConsistentInterpreter>();
}
return std::make_shared<AutogradInterpreter>(internal);
}
std::shared_ptr<AutogradInterpreter> BuildLazyInterpreter() {
auto internal = std::make_shared<LazyInterpreter>();
return std::make_shared<AutogradInterpreter>(internal);
}可见,这3种Interpreter构建完成后,都会以私有变量internal的形式,参与AutogradInterpreter的构建,并最终返回AutogradInterpreter。
class AutogradInterpreter {
public:
AutogradInterpreter() = delete;
AutogradInterpreter(const std::shared_ptr<OpExprInterpreter>& internal) : internal_(internal) {}
virtual ~AutogradInterpreter() = default;
Maybe<void> Apply(const OpExpr& op_expr, const TensorTuple& inputs, TensorTuple* outputs,
const AttrMap& attrs) const {
return Apply(op_expr, inputs, outputs, OpExprInterpContext(attrs));
}
Maybe<void> Apply(const OpExpr& op_expr, const TensorTuple& inputs, TensorTuple* outputs) const {
return Apply(op_expr, inputs, outputs, OpExprInterpContext(AttrMap{}));
}
Maybe<void> Apply(const OpExpr& op_expr, const TensorTuple& inputs, TensorTuple* outputs,
const OpExprInterpContext& ctx) const;
private:
std::shared_ptr<OpExprInterpreter> internal_;
};Apply()
通过上面我们知道,EagerMirroredInterpreter、EagerConsistentInterpreter和LazyInterpreter都将为其包裹上AutogradInterpreter的壳,通过AutogradInterpreter触发Apply的调用。顾名思义,AutogradInterpreter的作用主要是和autograd相关,其主要为eager mode下前向的op节点插入对应的用于反向计算grad的节点。
我们看看这部分代码,关键部分的作用在注释里给出:
Maybe<void> AutogradInterpreter::Apply(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs, const OpExprInterpContext& ctx) const {
// 判断是否需要计算梯度,如果处于GradMode的作用域切改op注册时没有禁用梯度
// 则requires_grad的值根据输入tensor的requires_grad属性判断
// any of input tensors requires_grad==True,则表示需要计算梯度
bool requires_grad = false;
if (autograd::GradMode::is_enabled() && !JUST(op_expr.IsGradDisabled())) {
requires_grad =
std::any_of(inputs.begin(), inputs.end(),
[](const std::shared_ptr<Tensor>& tensor) { return tensor->requires_grad(); });
}
// 这一坨逻辑比较丑陋,是因为近期支持了oneflow系统中支持了stride&&view机制
// 而大部分op尚未注册stride推导、尚未支持non-contiguous的输入tensor
// 所以需要在这对这部分op的输入进行强制转换,将其变为contiguous的
// NOTE: if this op not support stride, then need to tensor->contiguous()
#define HANDLE_NON_CONTIGUOUS_INPUT(tensor_tuple_ptr) \
TensorTuple tmp_inputs; \
if (!LazyMode::is_enabled() && !JUST(op_expr.SupportNonContiguous())) { \
tmp_inputs.resize(inputs.size()); \
for (size_t i = 0; i < inputs.size(); i++) { tmp_inputs[i] = inputs[i]->contiguous(); } \
tensor_tuple_ptr = &tmp_inputs; \
}
const TensorTuple* inputs_ptr = &inputs;
HANDLE_NON_CONTIGUOUS_INPUT(inputs_ptr);
// 这里是进行实际Interpreter执行的主要过程
{
autograd::AutoGradMode mode(false);
JUST(internal_->Apply(op_expr, *inputs_ptr, outputs, ctx));
}
// 这里主要是为了eager mode下,且requires_grad==True的op,
// 插入反向节点(AddNode)用于autograd,该节点包含反向梯度计算的方法(backward_fn)
// Lazy mode will construct backward compute graph in passes, so disable autograd if lazy mode.
std::shared_ptr<OpExprGradClosure> grad_closure(nullptr);
if (requires_grad && !LazyMode::is_enabled()) {
grad_closure = JUST(op_expr.GetOrCreateOpGradClosure());
auto backward_fn = std::make_shared<BackwardFunction>();
backward_fn->body = [=](const TensorTuple& out_grads, TensorTuple* in_grads,
bool create_graph) -> Maybe<void> {
autograd::AutoGradMode mode(create_graph);
JUST(grad_closure->Apply(out_grads, in_grads));
return Maybe<void>::Ok();
};
backward_fn->status = [=]() { return grad_closure->state()->SavedTensors().size() > 0; };
JUST(GetThreadLocalAutogradEngine()->AddNode(op_expr.op_type_name() + "_backward", backward_fn,
*inputs_ptr, outputs));
}
// Update outputs autograd meta
// Note: if requires_grad is True, we will create a new autograd meta for each output
// in `AddBackwardFuncPtr` to support inplace operation, so the update should after
// `AddBackwardFuncPtr`
for (auto& output : *outputs) {
output->set_is_leaf(inputs_ptr->size() == 0 || !requires_grad);
...
if (!output->requires_grad()) {
JUST(output->set_requires_grad(
requires_grad && IsSupportRequireGradDataType(output->dtype()->data_type())));
}
}
// 捕获前向的inputs outputs,反向计算时可能用到
if (requires_grad && !LazyMode::is_enabled()) {
// Capture inputs and outputs after `AddBackwardFuncPtr` because of that grad function
// node has been attached to them.
JUST(grad_closure->Capture(*inputs_ptr, *outputs, ctx));
}
return Maybe<void>::Ok();
}上面一坨逻辑有点多,让我们看一下重点,对于简单的Relu op,我们只需关注这部分代码:
// 这里是进行实际Interpreter执行的主要过程
{
autograd::AutoGradMode mode(false);
JUST(internal_->Apply(op_expr, *inputs_ptr, outputs, ctx));
}这里,还是以上面的flow.relu为例,由于是简单的Eager Mode,所以实际会走到EagerInterpreter的Apply方法:
Maybe<void> EagerInterpreter::Apply(const OpExpr& op_expr, const TensorTuple& inputs,
TensorTuple* outputs, const OpExprInterpContext& ctx) const {
#define APPLY_IF(op_type) \
if (const auto* op = dynamic_cast<const op_type##Expr*>(&op_expr)) { \
return ApplyImpl(*op, inputs, outputs, ctx); \
}
APPLY_IF(UserOp);
APPLY_IF(VariableOp);
APPLY_IF(CastToMirroredOp);
APPLY_IF(CastFromMirroredOp);
APPLY_IF(ConsistentToConsistentOp);
APPLY_IF(CastToConsistentOp);
APPLY_IF(CastFromConsistentOp);
APPLY_IF(DistributeSplitOp);
APPLY_IF(DistributeCloneOp);
APPLY_IF(DistributeConcatOp);
APPLY_IF(DistributeAddOp);
APPLY_IF(FunctionOp);
APPLY_IF(SelectTopNOp)
#undef APPLY_IF
OF_UNIMPLEMENTED() << "The type " << op_expr.op_type_name()
<< " has not been supported in EagerInterpreter::Apply.";
}?
这里,通过宏定义APPLY_IF,增加了对不同类型op的分支处理。对于大多数用户来说,用到的op都是UserOp类型,所以这里实际上会走到这个分支中:
if (const auto* op = dynamic_cast<const UserOpExpr*>(&op_expr)) {
return ApplyImpl(*op, inputs, outputs, ctx);
}再看看EagerMirroredInterpreter::ApplyImpl,位于
oneflow/core/framework/op_interpreter/eager_mirrored_op_interpreter.cpp:
Maybe<void> EagerMirroredInterpreter::ApplyImpl(const UserOpExpr& op_expr,
const TensorTuple& inputs, TensorTuple* outputs,
const OpExprInterpContext& ctx) const {
return NaiveInterpret(op_expr, inputs, outputs, ctx);
}其最终实现是NaiveInterpret。
NaiveInterpret
NaiveInterpret简单来说,主要用于做以下几件事:
-
check input tensor的device是否一致
-
生成output tensor
-
为output tensor推导和检查shape/stride/dtype
-
构建op执行指令,并派发至vm
简化版的代码如下:
Maybe<void> NaiveInterpret(const UserOpExpr& user_op_expr, const TensorTuple& inputs,
const Symbol<Device>& default_device, TensorTuple* outputs,
const OpExprInterpContext& ctx) {
const auto& attrs = ctx.attrs;
std::shared_ptr<EagerBlobObjectList> input_eager_blob_objects =
std::make_shared<EagerBlobObjectList>(inputs.size());
// check devices
for (int i = 0; i < inputs.size(); i++) {
const auto& input_device = JUST(inputs.at(i)->device());
if (i > 0) {
CHECK_OR_RETURN(*default_device == *input_device)
<< Error::RuntimeError()
<< "Expected all tensors to be on the same device, but found at least two devices, "
<< default_device->ToString() << " (positional 0) and " << input_device->ToString()
<< " (positional " << i << ")!";
}
input_eager_blob_objects->at(i) = JUST(inputs.at(i)->eager_blob_object());
}
// make output tensors
std::shared_ptr<EagerBlobObjectList> output_eager_blob_objects =
std::make_shared<EagerBlobObjectList>(outputs->size());
auto* output_tensor_metas = ThreadLocalDefaultOutputMutTensorMetas(outputs->size());
for (int i = 0; i < outputs->size(); i++) {
if (!outputs->at(i)) {
const auto& tensor_impl = std::make_shared<EagerMirroredTensorImpl>();
outputs->at(i) = std::make_shared<MirroredTensor>(tensor_impl);
output_tensor_metas->at(i) = tensor_impl->mut_tensor_meta();
} else {
bool has_eager_blob_object = JUST(outputs->at(i)->has_eager_blob_object());
CHECK_OR_RETURN(has_eager_blob_object);
output_eager_blob_objects->at(i) = JUST(outputs->at(i)->eager_blob_object());
}
}
Symbol<Stream> stream;
bool need_check_mem_case = true;
// Infer devices
...
// Infer shapes strides dtype
...
// 构建op执行指令,并派发至vm
JUST(PhysicalRun([&](InstructionsBuilder* builder) -> Maybe<void> {
return builder->LocalCallOpKernel(kernel, input_eager_blob_objects, output_eager_blob_objects,
ctx, stream);
}));
return Maybe<void>::Ok();
}Interpreter的终点是虚拟机(vm)。vm部分,是OneFlow比较独特的设计,内容很多,这里暂不展开了:) 可以简单理解,派发至vm后,此op将进入一个任务执行的队列,将会等待其vm的调度、执行。
5
Compute
在Interpreter将op执行指令派发至vm后,经过调度逻辑处理后,将会在
oneflow/core/eager/opkernel_instruction_type.cpp被触发执行,核心代码如下:
static inline void OpKernelCompute(
LocalCallOpKernelPhyInstrOperand* operand,
DeviceCtx* device_ctx, user_op::OpKernelState* state,
const user_op::OpKernelCache* cache) {
auto* opkernel = operand->mut_opkernel();
auto* compute_ctx =
opkernel->UpdateComputeContext(operand->inputs().get(), operand->outputs().get(),
operand->consistent_tensor_infer_result().get(), device_ctx);
...
operand->user_opkernel()->Compute(compute_ctx, state, cache);
opkernel->UpdateComputeContext(nullptr, nullptr, nullptr, nullptr);
}其中,
operand->user_opkernel()->Compute(compute_ctx, state, cache);将触发op kernel的实际执行。通常来说,op的kernel实现根据device的不同,会派发到不同的实现,其一般都位于:
oneflow/user/kernels/xxx_kernel.cpp或
oneflow/user/kernels/xxx_kernel.cu这里的Relu op相对比较特殊,是用primitive实现的(primitive也是oneflow中一种独特的设计,有着良好的抽象和可组合性),具体这个UnaryPrimitive就是elementwise unary的模板+UnaryFunctor的组合。其调用链如下:

UnaryPrimitiveKernel
class UnaryPrimitiveKernel final : public user_op::OpKernel, public user_op::CudaGraphSupport {
public:
OF_DISALLOW_COPY_AND_MOVE(UnaryPrimitiveKernel);
UnaryPrimitiveKernel() = default;
~UnaryPrimitiveKernel() = default;
using PrimitiveFactoryFuncType = std::function<std::unique_ptr<ep::primitive::ElementwiseUnary>(
user_op::KernelComputeContext*)>;
UnaryPrimitiveKernel(const std::string& output_name, const std::string& input_name,
PrimitiveFactoryFuncType fn)
: output_name_(output_name),
input_name_(input_name),
primitive_factory_func_(std::move(fn)) {}
private:
using user_op::OpKernel::Compute;
void Compute(user_op::KernelComputeContext* ctx) const override {
auto primitive = primitive_factory_func_(ctx);
CHECK(primitive);
const user_op::Tensor* input_tensor = ctx->Tensor4ArgNameAndIndex(input_name_, 0);
...
const int64_t elem_cnt = input_shape.elem_cnt();
if (elem_cnt != 0) {
primitive->Launch(ctx->stream(), input_tensor->dptr(), output_tensor->mut_dptr(), elem_cnt);
}
}
bool AlwaysComputeWhenAllOutputsEmpty() const override { return false; }
std::string output_name_;
std::string input_name_;
PrimitiveFactoryFuncType primitive_factory_func_;
};?
ep::primitive::ElementwiseUnary
template<UnaryOp unary_op, typename Src, typename Dst>
class ElementwiseUnaryImpl : public ElementwiseUnary {
public:
OF_DISALLOW_COPY_AND_MOVE(ElementwiseUnaryImpl);
ElementwiseUnaryImpl(Scalar attr0, Scalar attr1) : attr0(attr0), attr1(attr1) {}
~ElementwiseUnaryImpl() override = default;
void Launch(Stream* stream, const void* src_ptr, void* dst_ptr, size_t count) override {
CpuStream* cpu_stream = stream->As<CpuStream>();
Dst* dst = reinterpret_cast<Dst*>(dst_ptr);
const Src* src = reinterpret_cast<const Src*>(src_ptr);
auto functor = UnaryFunctor<DeviceType::kCPU, unary_op, Dst, Src>(attr0, attr1);
cpu_stream->ParallelFor(0, count, [functor, src, dst](int64_t begin, int64_t end) {
for (int64_t i = begin; i < end; i++) { dst[i] = functor(src[i]); }
});
}
protected:
Scalar attr0, attr1;
};UnaryFunctor
这个UnaryFuntor根据不同的Unaray op类型,特化出不同的具体functor实现,具体到Relu op,其实现位于
oneflow/core/ep/common/primitive/unary_functor.h:
template<DeviceType device, typename Dst, typename Src>
struct UnaryFunctor<device, UnaryOp::kRelu, Dst, Src> {
UnaryFunctor(Scalar attr0, Scalar attr1) {}
OF_DEVICE_FUNC Dst operator()(Src src) const {
const Src zero_val = static_cast<Src>(0.0);
if (src <= zero_val) {
return static_cast<Dst>(zero_val);
} else {
return static_cast<Dst>(src);
}
}
};至此,我们已经完成了一个op的Python -> C++ 之旅。从细节上看,是相对复杂的,但从整体流程上看,其实是比较简单的,排除了binding,vm调度机制等细节,其主要过程其实就4个环节:?Functor -> Dispatch -> Interpreter -> Kernel Compute。
实现/新增一个op,通常也不需要管中间的Dispatch以及Interpreter,我们只需重点关注和该op强相关的部分――Functor层面的参数、op逻辑检查,以及Kernel Compute部分的实际op运算。
(参考代码:
https://github.com/Oneflow-Inc/oneflow/commit/1dbdf8faed988fa7fd1a9034a4d79d5caf18512d)
其他人都在看
 https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/