Ϊʲô����թ����ѶȺܸ�?
����թ��Ŀ�ܶ�����¾��ǿͻ�������֪��ʲô����թ,ʲô���ǡ����仰˵,թƭ�Ķ����ģ����
��С��˵,��թƭ�ƺ���һ������������(binary classification),������ϸ�����ᷢ����ʵ���Ǹ����������(multi-class classification),��Ϊ����ÿ�ֲ�ͬ��թƭ������һ�ֵ��������͡�������թ�ֶζ����ҳ����仯,��թ���һ�㻹������������:
- �������������û�б�ǩ(label)��,���ֳ���ļලѧϰ(supervised learning)û������֮�ء�
- ��������(noise)���쳣��(anomaly)ʱ�ѶȺܴ�,������Ҫ����һ�����������ֱ����
- ������թƭ���ݻ����һ��,���ֲ�ͬ��թƭ�����ѡ�����ԭ������Ϊ���Dz����˽�ÿһ��թƭ���塣
- ��ʹ���������թƭ����ʷ����,�����б�ǩ��������üලѧϰ,Ҳ���ںܴ�ķ��ա�����������ʷ����ѧ����ģ��ֻ�ܼ���������ֹ�����ʷթƭ���Ƶ�թƭ,�����ڱ��ֵ�թƭ�ʹ�δ������թƭ,���ǵ�ģ�ͽ�������Ϊ����
���,��ʵ�������,�Ҳ�����ֱ�����κμලѧϰ,���ٲ��ܵ�������һ���ලѧϰģ������������е�թƭ��
���������һ����ѭ��,��Ϊû����ʷ��ǩ�Ͷ�թƭ������,�����������ܶ�թƭϸ�ֵ�ģ�͡��������һ��ʹ���ලѧϰ(unsupervised learning),����Ҫ����ר��(domain experts)Ҳ���Ƕ������ҵ�dz��˽��������֤���ǵ�Ԥ��,�ṩ����,�Ա��ڼ�ʱ�ĵ���ģ�͡�
�õ�������թ�����ݺ����Ǹ���Щʲô?
- ��ؾ���(Correlation Matrix)
- ��ά�߶ȱ任(Multidimensional Scaling)
from IPython.display import Image
Image(filename='./image/12.png', width=400)
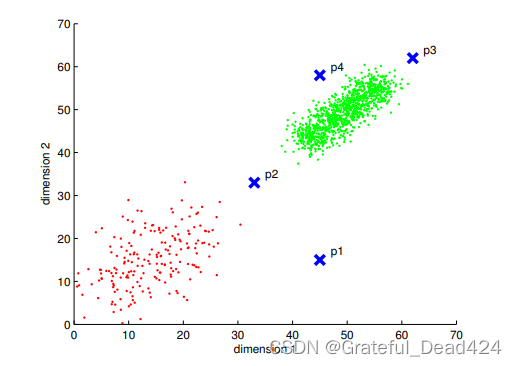
����˼��,��������һ��������Ҫ��Ԥ�е�ʱ��,����ȫû�б�ǩ,��������ʲô?
- Ǩ��ѧϰ
- ר��ģ��
- �ල�㷨
Ǩ��ѧϰ
Դ��������Ŀ���������ֲ�������,Ŀ�����������ֲ�����ͨ���㷨��С��Ե�ֲ�֮��������ֲ��µIJ��졣
- ����ʵ��Ǩ��
- ����������Ǩ��
- ����ģ�͵�Ǩ��
ȱ��:��Ҫӵ���뵱ǰĿ�곡����ص�Դ�����ݡ�
ר��ģ��
�Ҿ����ж��Ǹ����Ŵ�ר�Ҷ����ҵ������ж����жϡ������dz��õ�ģ�Ͳ�ͬ,���Ǹ������۾�����д��,�����Ǹ���ͳ�Ʒ�������ģ���㷨�����п۵ļ��㡣
����:
- ƾ�����ж�������Ҫ��
- ƾ����Ϊ������Ȩ
ȱ��:��Ҫ��������ҵ�������,��ʱ����������ŷ���
�ල�㷨
ȱ���㹻������֪ʶ,�������ݽ��б��ʱ,ʹ�õ�һ�ֻ���ѧϰ�����������о��ࡢ��ά�ȡ��ڷ��������������Ҫʹ�õ����������ල�쳣������������Ƿ����������������,�쳣������Ƿ���������������ԡ�
����
- K-Means
- ��ֵƯ��
- DBSCAN
- EM
- ���۲��
- ��������
���൱����һ��ʱ��������Ҫ���Ը���������,�����ǵ����ڿ�Ⱥ��������թ���������÷��������֡����������㷨Ҳ�ǵ�ǰʶ���Ż���թ����Ҫ�ֶ�֮һ,��Ҫ˼����ͨ��֪ʶͼ��С����ɸѡ�������ڽ�������,�ۼ���ζ�ŷ��������ס��仰,�⽫��֪ʶͼ��Ӧ��ʱ��ĺ���˼��֮һ��
�쳣���
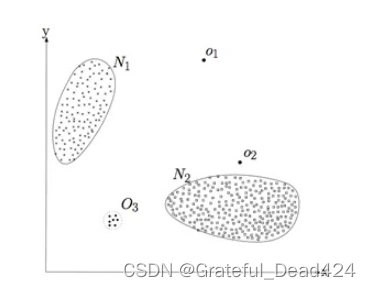
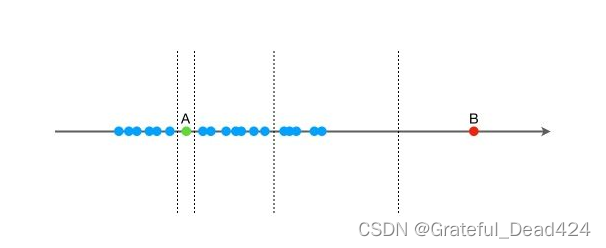
�쳣����(Outlier detection),�ֳ�Ϊ��Ⱥ����,���ҳ���Ԥ�ڶ������Ϊ����ϴ�Ķ����һ�������̡���Щ�������Ķ���Ϊ�쳣�������Ⱥ�㡣�쳣�������������������Ź㷺Ӧ��,�������ÿ�����թ����ҵ��ټ�⡢����������ȡ��쳣��(outlier)��һ�����ݶ���,�����Բ�ͬ�����������ݶ�������ͼ1��ʾ,N1��N2�����ڵĵ����������ݡ�����N1��N2��Զ��O1��O2��O3�����ڵĵ����쳣�㡣
Image(filename='./image/6.png', width=300)
�Ͳ�����ѧϰ��ͬ�����쳣���һ�����ල��,����ͨ�Ķ���������Ҳ������ͬ,��Ϊ�쳣������������Ƕ�����,����ʵ�Ƕ����(����쳣��ԭ�������ͬ)��
�㷨����
- �쳣���ݸ������д�������ݲ�̫һ����
- �쳣��������������������ռ�ȱȽ�С��
��Ҫ˼��
�����쳣��ⷽ�����ǻ�������(СȺ��)������ƶ�(proximity)
- ����
- �ܶ�
- �Ƕ�
- ����������Ѷ�
- ��
ΪʲôҪ���ල�쳣��ⷽ��?
- ����Ⱥ�����칹�ɷ�,���Զ�������ɸѡ
- �ܶೡ��û�б�ǩ���߱�ǩ����,����ѵ���ලģ��(������������Ŀ����թģ��)
- ���������ڷ����任,ֻ�ܴ�һ��СȺ���ڲ������쳣(������թ���,�ֶζ��,�Ż���թͨ��������ij��ʱ����)
- �쳣�������쳣����ռ�Ⱥ���,���Ҵ�ij�ֶ�����Զ����������,��������Ǹ�����թ������֪ʶ��������������թ����оͲ�̫������
������ڿ���Ҫ�漰�ĸ������㷨:
- Z-score����
- KNN�㷨
- Local Outlier Factor
- ����ɭ��
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import numpy as np
import random
import math
data = pd.read_csv('Acard.txt')
data.head()

train = data[data.obs_mth != '2018-11-30'].reset_index().copy()
val = data[data.obs_mth == '2018-11-30'].reset_index().copy()
feature_lst = ['person_info','finance_info','credit_info','act_info']
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
#train_ks : 0.4482453222991063
#val_ks : 0.4198642457760936
z-score�쳣���
��������������̬�ֲ�,������������ƫ����̬�ֲ��ij̶ȡ�
ͨ������ �� \mu ���� �� \sigma ���õ���ǰ���������ڵ���̬�ֲ��ı���ʽ,Ȼ��ֱ����ÿ����������������ܶȺ����±����ɵĸ���,������С��ijһ��ֵ������Ϊ��������Dz���������ֲ���,��˶���Ϊ�쳣ֵ��
���㹫ʽ:
�� = 1 m �� i = 0 m x ( i ) \mu=\frac{1}{m} \sum_{i=0}^{m} x^{(i)} ��=m1?i=0��m?x(i)
�� 2 = 1 m �� i = 1 m ( x ( i ) ? �� ) 2 \sigma^{2}=\frac{1}{m} \sum_{i=1}^{m}\left(x^{(i)}-\mu\right)^{2} ��2=m1?i=1��m?(x(i)?��)2
һ�����ǻ����ƽ��ֵ�ͷ���Ĺ���ֵ,�������µ�һ��ѵ��ʵ��,����ģ�ͼ���p(x) p(x)p(x):
p
(
x
)
=
��
j
=
1
n
p
(
x
j
;
��
j
,
��
j
2
)
=
��
j
=
1
1
1
2
��
��
exp
?
(
?
(
x
?
��
)
2
2
��
2
)
p(x)=\prod_{j=1}^{n} p\left(x_{j} ; \mu_{j}, \sigma_{j}^{2}\right)=\prod_{j=1}^{1} \frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right)
p(x)=j=1��n?p(xj?;��j?,��j2?)=j=1��1?2��?��1?exp(?2��2(x?��)2?)
��p(x)<�� p(x)<\varepsilonp(x)<��ʱ,����Ϊ�쳣��
ȱ��:��Ҫ��������������̬�ֲ�,�����Ǵֳ��������������ּ���������
KNN�쳣���
KNN�㷨רע��ȫ���쳣���,���������ֲ��쳣��
����,�������ݼ��е�ÿ����¼,�����ҵ�k��������ھӡ�Ȼ��ʹ����K���ھӼ����쳣������
���������ַ���
- ���:ʹ�õ���k���ھӵľ�����Ϊ��Ⱥֵ�÷�
- ƽ��ֵ:ʹ������k���ھӵ�ƽ��ֵ��Ϊ��Ⱥֵ�÷�
- ��λ��:ʹ�õ�k���ھӵľ������ֵ��Ϊ��Ⱥֵ�÷�
��ʵ�ʷ����к����ֵ�Ӧ�öȽϸߡ�Ȼ��,�����ľ���ֵ�ںܴ�̶���ȡ�������ݼ�������ά�����淶����
����k��ѡ��Ȼ�Խ������Ҫ�����ѡ�����,��¼���ܶȹ��ƿ��ܲ��ɿ���(�������)��һ����,�����̫��,�ܶȹ��ƿ���̫���ԡ�Kֵ��ѡ��ͨ����10<k<50�����Χ�ڡ������ڷ������,ѡ��һ�����ʵ�Kֵ,�����ý�����֤����
����,��ʵ�ϻ���KNN���㷨���Dz���������թ����,��Ϊ���DZ����Ͷ������Ƚ����С�
Local Outlier Factor
LOF�ǻ����ܶȵľ����㷨(Breuning et. al. 2000), ���·����� SIGMOD 2000, ��Ŀǰ�Ѿ��� 3000+ �����á��� LOF ֮ǰ���쳣����㷨����ǻ���ͳ�Ʒ�����,�����ǽ�����һЩ�����㷨�����쳣���ʶ��(���� ,DBSCAN,OPTICS)������,����ͳ�Ƶ��쳣����㷨ͨ����Ҫ�������ݷ����ض��ĸ��ʷֲ�,������������Dz������ġ�������ķ���ͨ��ֻ�ܸ��� 0/1 ���ж�(��:�Dz����쳣��),��������ÿ�����ݵ���쳣�̶ȡ���Ƚ϶���,�����ܶȵ�LOF�㷨Ҫ����ֱ�ۡ�������Ҫ�����ݵķֲ���̫��Ҫ��,��������ÿ�����ݵ���쳣�̶�(outlierness)��
�㷨����
LOF �ǻ����ܶȵ��㷨,������ĵIJ����ǹ������ݵ��ܶȵĿ̻�������� distanced-based ���� density-based �ľ����㷨��Щӡ��,��ᷢ�� LOF �����������ܶȵ�һЩ����������ʶ���˽�����Щ���ĸ���,�����㷨Ҳ���Զ����ˡ��������㷨,����Ҫ���������ĸ�����:
1)K-�ڽ�����(k-distance):�ھ������ݵ� p ����ļ�������,�� k ������ĵ���� p ֮��ľ����Ϊ�� p �� K-�ڽ�����,��Ϊ k-distance �� ��
2)�ɴ����(rechability distance):�ɴ����Ķ����K-�ڽ���������ص�,��������kʱ, ���ݵ� p �� ���ݵ� o �Ŀɴ���� reach-dist(p, o)Ϊ���ݵ� o ��K-�ڽ����� �� ���ݵ�p���o֮���ֱ�Ӿ�������ֵ����:
r
e
a
c
h
d
i
s
t
k
(
p
,
o
)
=
max
?
{
k
?
?distance?
(
o
)
,
d
(
p
,
o
)
}
reachdist_{k}(p, o)=\max \{k-\text { distance }(o), d(p, o)\}
reachdistk?(p,o)=max{k??distance?(o),d(p,o)}3)�ֲ��ɴ��ܶ�(local rechability density):�ֲ��ɴ��ܶȵĶ����ǻ��ڿɴ�����,�������ݵ� p,��Щ����p�ľ���С�ڵ��� k-distance(p)�����ݵ��Ϊ���� k-nearest-neighbor,��Ϊ
N
k
(
p
)
N_k(p)
Nk?(p),���ݵ� p �ľֲ��ɴ��ܶ�Ϊ�����ڽ������ݵ��ƽ���ɴ����ĵ���,��:
lr
?
d
k
(
p
)
=
1
��
o
��
N
k
(
p
)
reach
?dist?
k
(
p
,
o
)
�O
N
k
(
p
)
�O
\operatorname{lr} d_{k}(p)=\frac{1}{\frac{\sum_{o \in N_{k}(p)} \text {reach} \text { dist }_{k}(p, o)}{\left|N_{k}(p)\right|}}
lrdk?(p)=�ONk?(p)�O��o��Nk?(p)?reach?dist?k?(p,o)?1?4)�ֲ��쳣����(local outlier factor):���ݾֲ��ɴ��ܶȵĶ���,���һ�����ݵ��������Ƚ���Զ�Ļ�,��ô��Ȼ���ľֲ��ɴ��ܶȾ�С����LOF�㷨����һ�����ݵ���쳣�̶�,�����ǿ����ľ��Ծֲ��ܶ�,���ǿ�������Χ�ڽ������ݵ������ܶȡ��������ĺô��ǿ����������ݷֲ������ȡ��ܶȲ�ͬ��������ֲ��쳣���Ӽ����þֲ�����ܶ�������ġ����ݵ� p �ľֲ�����ܶ�(�ֲ��쳣����)Ϊ��p���ھ��ǵ�ƽ���ֲ��ɴ��ܶȸ����ݵ�p�ľֲ��ɴ��ܶȵı�ֵ,��:
L
O
F
k
(
p
)
=
��
o
��
N
k
(
p
)
l
r
d
(
o
)
l
r
d
(
p
)
�O
N
k
(
p
)
�O
=
��
o
��
N
k
(
p
)
lr
?
d
(
o
)
�O
N
k
(
p
)
�O
/
lr
?
d
(
p
)
L O F_{k}(p)=\frac{\sum_{o \in N_{k}(p)} \frac{l r d(o)}{l r d(p)}}{\left|N_{k}(p)\right|}=\frac{\sum_{o \in N_{k}(p)} \operatorname{lr} d(o)}{\left|N_{k}(p)\right|} / \operatorname{lr} d(p)
LOFk?(p)=�ONk?(p)�O��o��Nk?(p)?lrd(p)lrd(o)??=�ONk?(p)�O��o��Nk?(p)?lrd(o)?/lrd(p)���ݾֲ��쳣���ӵĶ���,������ݵ� p �� LOF �÷���1����,�������ݵ�p�ľֲ��ܶȸ������ھ��Dz��;������ݵ� p �� LOF �÷�С��1,�������ݵ�p����һ������ܼ�������,������һ���쳣��;������ݵ� p �� LOF �÷�Զ����1,�������ݵ�p��������Ƚ���Զ,���п�����һ���쳣�㡣�������ͼ���� Wikipedia �� LOF ����,չʾ��һ����ά�����ӡ���������ֱ�������Ӧ���LOF�÷�,�������˶�LOF��һ��ֱ�۵�ӡ��
Image(filename='./image/11.png', width=600)
�˽��� LOF �Ķ���,�����㷨Ҳ���Զ�����:
-
����ÿ�����ݵ�,���������������е�ľ���,�����ӽ���Զ����;
-
����ÿ�����ݵ�,�ҵ����� k-nearest-neighbor,���� LOF �÷֡�
from pyod.models.lof import LOF
clf = LOF(n_neighbors=20, algorithm='auto', leaf_size=30, metric='minkowski', p=2,
metric_params=None, contamination=0.1, n_jobs=1)
clf.fit(x)
#LOF(algorithm='auto', contamination=0.1, leaf_size=30, metric='minkowski',
# metric_params=None, n_jobs=1, n_neighbors=20, p=2)
�㷨Ӧ��
LOF�㷨�й��ھֲ��ɴ��ܶȵĶ�����ʵ������һ������,��:�����ڴ��ڵ��� k ���ظ��ĵ㡣���������ظ�����ڵ�ʱ��,��Щ���ƽ���ɴ����Ϊ��,�ֲ��ɴ��ܶȾͱ�Ϊ�����,����������һЩ�鷳����ʵ��Ӧ��ʱ,Ϊ�˱����������������,���� k-distance ��Ϊ k-distinct-distance,�������ظ������������,�����Կ��Ǹ��ɴ���붼��һ����С��ֵ,����ɴ��������㡣
LOF �㷨��Ҫ�������ݵ�����֮��ľ���,��������㷨ʱ�临�Ӷ�Ϊ O ( n 2 ) O(n^2) O(n2) ��Ϊ������㷨Ч��,�������㷨���ԸĽ���
FastLOF (Goldstein,2012)�Ƚ�������������ķֳɶ���Ӽ�,Ȼ����ÿ���Ӽ������ LOF ֵ��������Щ LOF �쳣�÷�С�ڵ��� 1 ��,�����ݼ�����,ʣ�µ�����һ��Ѱ�Ҹ����ʵ� nearest-neighbor,������ LOF ֵ��
�����Ƚ����ݴ��Էֳɶ������,Ȼ����ݾֲ������������ݹ��������ټ��������뷨,��������������,Ϊ�˸Ľ� K-means �ļ���Ч��, Canopy Clustering �㷨Ҳ���ù��Ƚ����Ƶ�������
Isolation Forest
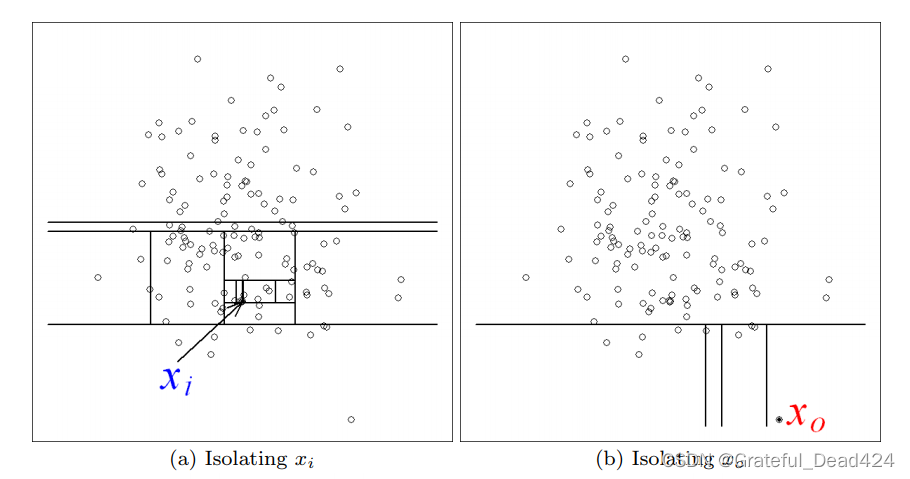
��������һ����������˵�� Isolation Forest �Ļ����뷨������������һ��һά����(����ͼ��ʾ),����Ҫ���������ݽ�������з�,ϣ�����ѵ� A �͵� B �����зֳ����������,�����������ֵ����Сֵ֮�����ѡ��һ��ֵ x,Ȼ���� <x �� >=x �������ݷֳ��������顣Ȼ��,�������������зֱ��ظ��������,ֱ�����ݲ����ٷ֡���Ȼ,�� B ���������ݱȽ�����,�����ú��ٵĴ����Ϳ������зֳ���;�� A ���������ݵ����һ��,������Ҫ����Ĵ������ܰ����зֳ�����
Image(filename='./image/1.png', width=600)
���ǰ����ݴ�һά��չ����ά��ͬ����,�������������������������з�,������ͼ�еĵ�A���͵�B���ֱ��зֳ��������������ѡ��һ������ά��,��������������ֵ����Сֵ֮�����ѡ��һ��ֵ,���ո�����ֵ�Ĵ�С��ϵ�����ݽ��������з֡�Ȼ��,����������������,�����ظ���������,������İ�ij������ά�ȵ�ȡֵ�����ݽ���ϸ��,ֱ����ϸ��,��:ֻʣ��һ�����ݵ�,����ʣ�µ�����ȫ����ͬ������ǰ����������,ֱ����,��B�����������ݵ�Ƚ�����,����ֻ��Ҫ���ٵļ��β����Ϳ��Խ���ϸ�ֳ���;��A����Ҫ���зִ������ܻ����һЩ��
Image(filename='./image/2.png', width=600)
������ǰ�ᵽ�Ĺ��ڡ��쳣������������,һ�������,�������������,��B�͵�B�� ���ڸ��������ݸ��ıȽ�Զ,�ᱻ��Ϊ���쳣����,����A�͵�A�� �ᱻ��Ϊ���������ݡ�ֱ����,�쳣�������ڸ��������ݵ��Ϊ����,������Ҫ���ټ����з־Ϳ��Խ����ǵ������ֳ���,����������ǡǡ�෴������ʵ����Isolation Forest(IF)�ĺ��ĸ��IF���ö�����ȥ�����ݽ����з�,���ݵ��ڶ���������������ȷ�Ӧ�˸������ݵġ����롱�̶ȡ������㷨���¿��Է�Ϊ����:
- ѵ��:��ȡ�������,������ö�����(Isolation Tree,�� iTree);
- Ԥ��:�ۺ϶�ö������Ľ��,����ÿ�����ݵ���쳣��ֵ��
ѵ��:����һ�� iTree ʱ,�ȴ�ȫ�������г�ȡһ������,Ȼ�����ѡ��һ��������Ϊ��ʼ�ڵ�,���ڸ����������ֵ����Сֵ֮�����ѡ��һ��ֵ,��������С�ڸ�ȡֵ�����ݻ������֧,���ڵ��ڸ�ȡֵ�Ļ����ҷ�֧��Ȼ��,������������֧������,�ظ���������,ֱ��������������:
- ���ݲ����ٷ�,��:ֻ����һ������,����ȫ��������ͬ��
- �������ﵽ���������ȡ�
Ԥ��:�������� x ���쳣��ֵʱ,��Ҫ��������ÿ�� iTree �е�·������(Ҳ���Խ����)�������,������һ�� iTree,�Ӹ��ڵ㿪ʼ����ͬ������ȡֵ��������,ֱ������ijҶ�ӽڵ㡣���� iTree ��ѵ��������ͬ������ x ����Ҷ�ӽڵ��������Ϊ T.size,������ x ����� iTree �ϵ�·������ h(x),���������������ʽ����:
h
(
x
)
=
e
+
C
(
T
.
size
)
h(x)=e+C(T . \text {size})
h(x)=e+C(T.size)Ԥ��:�������� x ���쳣��ֵʱ,��Ҫ��������ÿ�� iTree �е�·������(Ҳ���Խ����)�������,������һ�� iTree,�Ӹ��ڵ㿪ʼ����ͬ������ȡֵ��������,ֱ������ijҶ�ӽڵ㡣���� iTree ��ѵ��������ͬ������ x ����Ҷ�ӽڵ��������Ϊ T.size,������ x ����� iTree �ϵ�·������ h(x),���������������ʽ����:
h
(
x
)
=
e
+
C
(
T
.
size
)
h(x)=e+C(T . \text {size})
h(x)=e+C(T.size)��ʽ��,e ��ʾ���� x �� iTree �ĸ��ڵ㵽Ҷ�ڵ�����о����ıߵ���Ŀ,C(T.size) ������Ϊ��һ������ֵ,����ʾ��һ���� T.size ���������ݹ����Ķ�������ƽ��·�����ȡ�һ���,C(n) �ļ��㹫ʽ����:
C
(
n
)
=
2
H
(
n
?
1
)
?
2
(
n
?
1
)
n
C(n)=2 H(n-1)-\frac{2(n-1)}{n}
C(n)=2H(n?1)?n2(n?1)?����,H(n-1) ���� ln(n-1)+0.5772156649 ����,����ij�����ŷ������������ x ���յ��쳣��ֵ Score(x) �ۺ��˶�� iTree �Ľ��:
S
core
?
(
x
)
=
2
?
E
(
h
(
x
)
)
C
(
��
)
S \operatorname{core}(x)=2^{-\frac{E(h(x))}{C(��)}}
Score(x)=2?C(��)E(h(x))?��ʽ��,E(h(x)) ��ʾ���� x �ڶ�� iTree ��·�����ȵľ�ֵ,
��
��
����ʾ���� iTree ��ѵ��������������,
C
(
��
)
C(��)
C(��)��ʾ��
��
��
�������ݹ����Ķ�������ƽ��·������,����������Ҫ��������һ����
���쳣��ֵ�Ĺ�ʽ��,������� x �ڶ�� iTree �е�ƽ��·������Խ��,�÷�Խ�ӽ� 1,�������� x Խ�쳣;������� x �ڶ�� iTree �е�ƽ��·������Խ��,�÷�Խ�ӽ� 0,��ʾ���� x Խ����;������� x �ڶ�� iTree �е�ƽ��·�����Ƚӽ������ֵ,���ֻ��� 0.5 ������
Image(filename='./image/7.png', width=650)
Ӧ�ð���
1.��ϴ��ģ���ݼ�,���쳣����ͨ���ල�㷨����ɸѡ
from pyod.models.iforest import IForest
clf = IForest(behaviour='new', bootstrap=False, contamination=0.1, max_features=1.0,
max_samples='auto', n_estimators=500, n_jobs=-1, random_state=None,verbose=0)
clf.fit(x)
# IForest(behaviour='new', bootstrap=False, contamination=0.1, max_features=1.0,
# max_samples='auto', n_estimators=500, n_jobs=-1, random_state=None,
# verbose=0)
out_pred = clf.predict_proba(x,method ='linear')[:,1]
train['out_pred'] = out_pred
x = train[train.out_pred< 0.7][feature_lst]
y = train[train.out_pred < 0.7]['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
#train_ks : 0.4243417677672226
#val_ks : 0.4303193786076034

2.ͨ�������쳣�̶Ƚ��з���
train.out_pred.groupby(train.obs_mth).mean()
#obs_mth
#2018-06-30 0.192853
#2018-07-31 0.188666
#2018-09-30 0.240877
#2018-10-31 0.230139
#Name: out_pred, dtype: float64
train.out_pred.groupby(train.obs_mth).max()
#obs_mth
#2018-06-30 0.998090
#2018-07-31 0.994864
#2018-09-30 1.000000
#2018-10-31 0.968593
#Name: out_pred, dtype: float64
train.out_pred.groupby(train.obs_mth).var()
#obs_mth
#2018-06-30 0.025732
#2018-07-31 0.022533
#2018-09-30 0.037034
#2018-10-31 0.035351
#Name: out_pred, dtype: float64
train['for_pred'] = np.where(train.out_pred>0.7,1,0)
train.for_pred.groupby(train.obs_mth).sum()/train.for_pred.groupby(train.obs_mth).count()
#obs_mth
#2018-06-30 0.016825
#2018-07-31 0.010785
#2018-09-30 0.035111
#2018-10-31 0.028017
#Name: for_pred, dtype: float64
3.preAģ��
- �������ǽ����潨ģ�Ĺ���ɭ��ģ����ΪpreA
#��һ��badrate
train.bad_ind.groupby(train.for_pred).sum()/train.bad_ind.groupby(train.for_pred).count()
#for_pred
#0 0.016417
#1 0.122995
#Name: bad_ind, dtype: float64
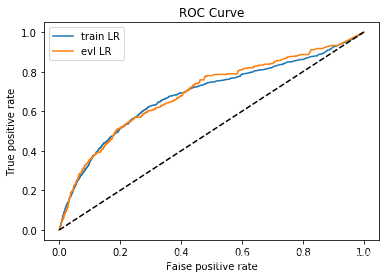
��Ҳ�����쳣ֵ����0.7�Ŀ�Ⱥbadrate�ﵽ��12%,����һ�����˾ܾ���ʹ���ǵ�����������ߡ�
4.��������Ŀ/����թģ��
- ����ǰ���A��û�б�ǩ,��������һ��ֱ���ල��ģ��ģ��ʵ��Ч��������ô��
y_pred = clf.predict_proba(x,method ='linear')[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = clf.predict_proba(val_x,method ='linear')[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
#train_ks : 0.3302166460813136
#val_ks : 0.3233653844655018
model = clf
row_num, col_num = 0, 0
bins = 20
Y_predict = [s[1] for s in model.predict_proba(val_x)]
Y = val_y
nrows = Y.shape[0]
lis = [(Y_predict[i], Y[i]) for i in range(nrows)]
ks_lis = sorted(lis, key=lambda x: x[0], reverse=True)
bin_num = int(nrows/bins+1)
bad = sum([1 for (p, y) in ks_lis if y > 0.5])
good = sum([1 for (p, y) in ks_lis if y <= 0.5])
bad_cnt, good_cnt = 0, 0
KS = []
BAD = []
GOOD = []
BAD_CNT = []
GOOD_CNT = []
BAD_PCTG = []
BADRATE = []
dct_report = {}
for j in range(bins):
ds = ks_lis[j*bin_num: min((j+1)*bin_num, nrows)]
bad1 = sum([1 for (p, y) in ds if y > 0.5])
good1 = sum([1 for (p, y) in ds if y <= 0.5])
bad_cnt += bad1
good_cnt += good1
bad_pctg = round(bad_cnt/sum(val_y),3)
badrate = round(bad1/(bad1+good1),3)
ks = round(math.fabs((bad_cnt / bad) - (good_cnt / good)),3)
KS.append(ks)
BAD.append(bad1)
GOOD.append(good1)
BAD_CNT.append(bad_cnt)
GOOD_CNT.append(good_cnt)
BAD_PCTG.append(bad_pctg)
BADRATE.append(badrate)
dct_report['KS'] = KS
dct_report['BAD'] = BAD
dct_report['GOOD'] = GOOD
dct_report['BAD_CNT'] = BAD_CNT
dct_report['GOOD_CNT'] = GOOD_CNT
dct_report['BAD_PCTG'] = BAD_PCTG
dct_report['BADRATE'] = BADRATE
val_repot = pd.DataFrame(dct_report)
val_repot

��������ع��мල�����ֿ�����Ч�������Բ�һЩ��,���Ƕ����ලѧϰ��˵Ч���Ƿdz������ġ���Ȼʵ�ʳ�������û����ô��,�Ͼ�������ı�����ͨ���мල�ķ�ʽɸѡ������,ȱʧֵҲ�����BIVARͼ��ÿ������ӡ�