摘要:本文简述了人工智能的重要分支――机器学习的核心算法之一――聚类算法,并用C#实现了一套完全交互式的、可由用户自由发挥的,适用于聚类算法的训练数据集生成软件――Clustering。用户使用鼠标左键(拖动)即可生成任意形状,任意维度,任意簇数及各种数据范围的训练数据集,同时也可以保存该数据集的模拟图形与未来的计算结果进行对照。
一、聚类算法(Clustering Algorithms)
1、概述
聚类方法是最有用的无监督的机器学习(Machine Learning)方法之一。这些方法用于发现数据样本之间的相似性以及关系模式,然后根据特征将这些样本聚类为具有相似性的组。
聚类很重要,因为它决定了当前未标记数据之间的内在分组。他们基本上对数据点进行一些假设,以构成它们的相似性。每个假设将构造不同但同样有效的集群。
聚类算法主要有:
1)基于密度
在这些方法中,簇被形成为密集区域。这些方法的优点是,它们具有良好的准确性以及合并两个集群的良好能力。例如,基于密度的含噪应用程序空间聚类(DBSCAN),确定聚类结构的排序点(光学)等。
2)基于层次结构
在这些方法中,集群根据层次结构形成树状结构。它们有两类,即凝聚(自下而上的方法)和分裂(自上而下的方法)。例如,使用代表进行聚类(CURE),使用层次结构进行平衡迭代减少聚类(BIRCH)等。
3)基于分区
在这些方法中,通过将对象划分为k个簇来形成簇。集群的数量将等于分区的数量。例如,K-means,基于随机搜索对大型应用程序进行聚类(CLARANS)。
4)基于网格
在这些方法中,簇形成网格状结构。这些方法的优点是,在这些网格上进行的所有聚类操作都是快速的,并且与数据对象的数量无关。例如,统计信息网格(STING),聚类搜索(CLIQUE)。
2、衡量群集性能
关于ML模型,最重要的考虑因素之一是评估其性能,或者可以说模型的质量。在有监督学习算法的情况下,评估我们模型的质量很容易,因为我们已经为每个示例添加了标签。
另一方面,对于无监督学习算法,我们并没有那么幸运,因为我们处理的是未标记的数据。但我们仍然有一些指标可以让实践者根据算法洞察集群中发生的变化。
在深入研究这些指标之前,我们必须了解,这些指标只是评估模型之间的比较性能,而不是衡量模型预测的有效性。以下是我们可以在聚类算法上部署的一些度量标准,以衡量模型的质量?
轮廓分析
轮廓分析用于通过测量聚类之间的距离来检查聚类模型的质量。它基本上为我们提供了一种通过轮廓评分来评估参数(如簇数)的方法。该分数衡量一个簇中的每个点与相邻簇中的点的接近程度。
轮廓评分分析
轮廓评分分析? 轮廓评分范围为[-1,1]。
3、ML聚类算法的类型
以下是最重要和最有用的ML聚类算法?
1)K-Means均值聚类法
该聚类算法计算质心并迭代,直到找到最佳质心。它假设集群的数量已经已知。它也称为平面聚类算法。通过算法从数据中识别的聚类数用K均值中的“K”表示。
2)Mean-Shift均值漂移算法
这是另一种用于无监督学习的强大聚类算法。与K-means聚类不同,它不做任何假设,因此是一种非参数算法。
3)Hierarchical层次聚类
它是另一种无监督学习算法,用于将具有类似特征的未标记数据点分组。

?
二、聚类算法的应用
我们可以发现聚类在以下方面很有用?
1、数据摘要和压缩
聚类广泛应用于需要数据摘要、压缩和约简的领域。例如图像处理和矢量量化。比如,中国证监会选用的多可文档管理系统就使用聚类算法提取文档摘要。
2、协作系统和客户细分
由于聚类可以用来发现相似的产品或同类用户,因此它可以用于协作系统和客户细分领域。
作为其他数据挖掘任务的关键中间步骤? 聚类分析可以生成紧凑的数据摘要,用于分类、检验、假设生成;因此,它也是其他数据挖掘任务的关键中间步骤。
3、生物信息学
聚类算法在生物医学研究中的应用,特别是在微阵列基因表达数据分析、基因组序列分析、MRI数据分析和生物医学文档聚类中的应用。聚类理论和算法与生物医学研究实践的结合构成了生物信息学这一新兴和快速发展的多学科领域的重要组成部分。这种整合将大大有利于这两个领域,并促进它们的进步。因此,本章的目标是为生物医学研究人员提供指导,以选择最适合其应用的模型,并更简单地集成这两个领域。
生物医学工程师在其数据分析中严重依赖于几种经典的聚类技术,如标准凝聚层次聚类(单连锁、完全连锁、平均连锁等)、SOFM和标准k-均值,考虑到前两种方法的良好可视化和后一种方法的线性复杂性。软件包的可用性和算法的易实现性是导致其流行的其他主要因素。然而,虽然这些方法有其优点,但也有许多缺点,不适合用于某些生物医学应用。例如,标准凝聚层次聚类的计算复杂性至少是,这使得它们对于大规模数据聚类来说是非常不合适的选择。此外,它们缺乏鲁棒性也限制了它们在噪声环境中的应用。
或者,许多最先进的聚类算法在生物医学实践中的应用,例如,基于核学习的聚类、非线性投影方法、art系列以及许多专门为大规模数据聚类设计的聚类算法(BIRCH、CURE、DBSCAN、OPTICS、STING等)仍然很少,尽管生物医学研究人员已逐渐认识到其有效性。其原因可能是缺乏对算法实现和参数调整的有效指导,或者只是各领域之间缺乏良好的沟通。
为了帮助生物医学工程师更清楚地了解现有的聚类算法及其优缺点,以便更好地应用聚类,本章在下面的项目符号中总结了属性作为评估聚类算法的重要标准。表3.2还根据这些特性对聚类算法进行了分类。这些特性还构成了集群中的主要挑战,下一代集群技术必须解决这些挑战。当然,特定应用程序的详细要求将影响这些属性。
三、训练数据集及生成算法
不同的数据集应该选择不同的算法。

生产环境的聚类算法用于处理真实的生产数据。但是在算法成熟之前,需要大量不同的训练数据用于发现问题、改善算法。
训练数据集可以用一个方便的软件实现。在本文之前可以搜索到信息是,大多依赖于现有的软件比如 Matlab 和一些程序包生成有限类型的数据集合。
本文用纯C#实现了一套完全交互式的,可由用户自由发挥的训练数据集生成软件。
1、软件设计
训练数据的生成不需要太多的技术,主要就是:
1)标准正态分布的随机数
随机数据应该分布于鼠标坐标的周边,并符合标准正态分布。
2)大数据显示(绘图)技术
大量的数据需要实时显示,必须使用一点简要的过滤技术。
3)随机颜色发生器
随机生成具有明显区分的一个颜色集。
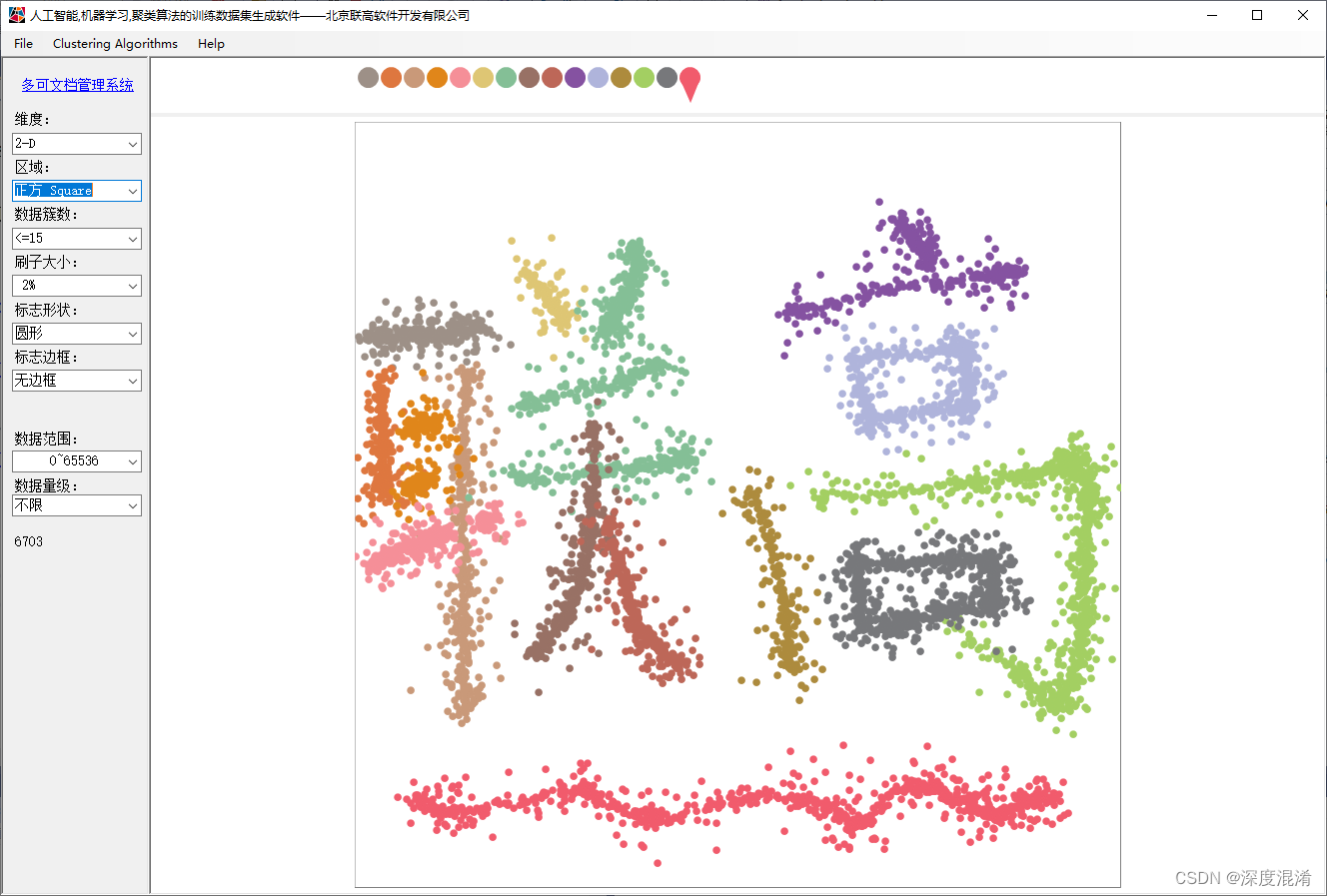
2、Clustering功能简介
(1)设计窗口可任意缩放;
(2)支持2D,3D,...1024D维度的数据;
(3)支持多达15个簇(实际上没有限制);
(4)支持刷子大小调整;小刷子用于绘制更复杂的构型;
(5)支持多种标志的形状;
(6)支持标志是否有边框;
(7)支持多种数据范围;
(8)支持达到 1TB 的数据量级(也可以更大),但无需点击很多次,只需要描绘了形状,软件自动补齐更多的数据。
C#就是好!一天就可以完成这个软件。
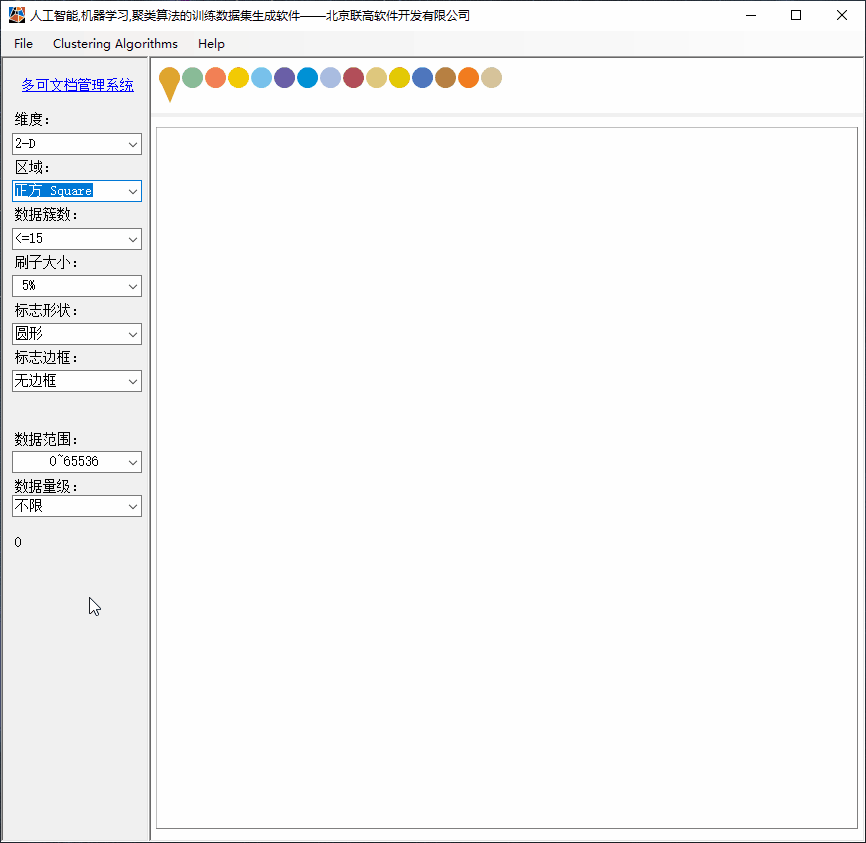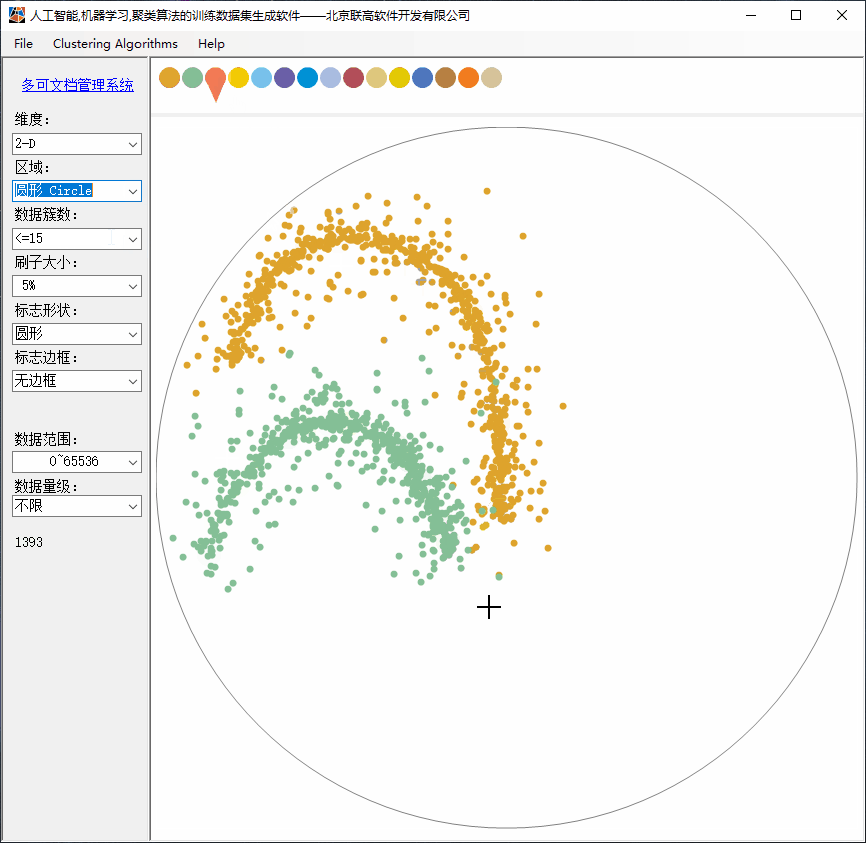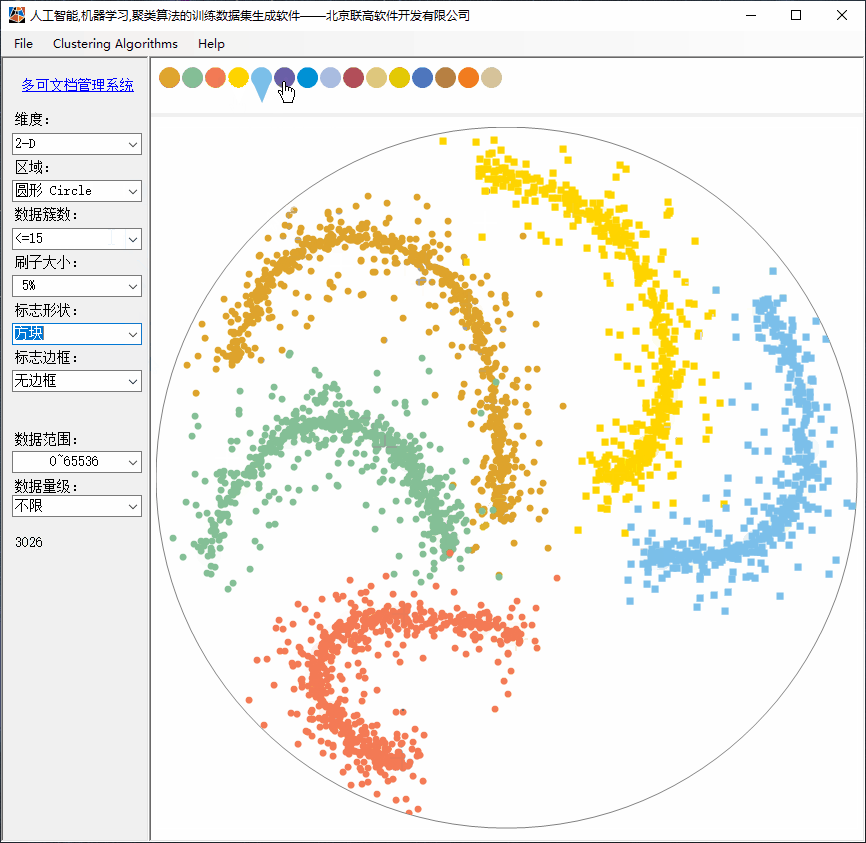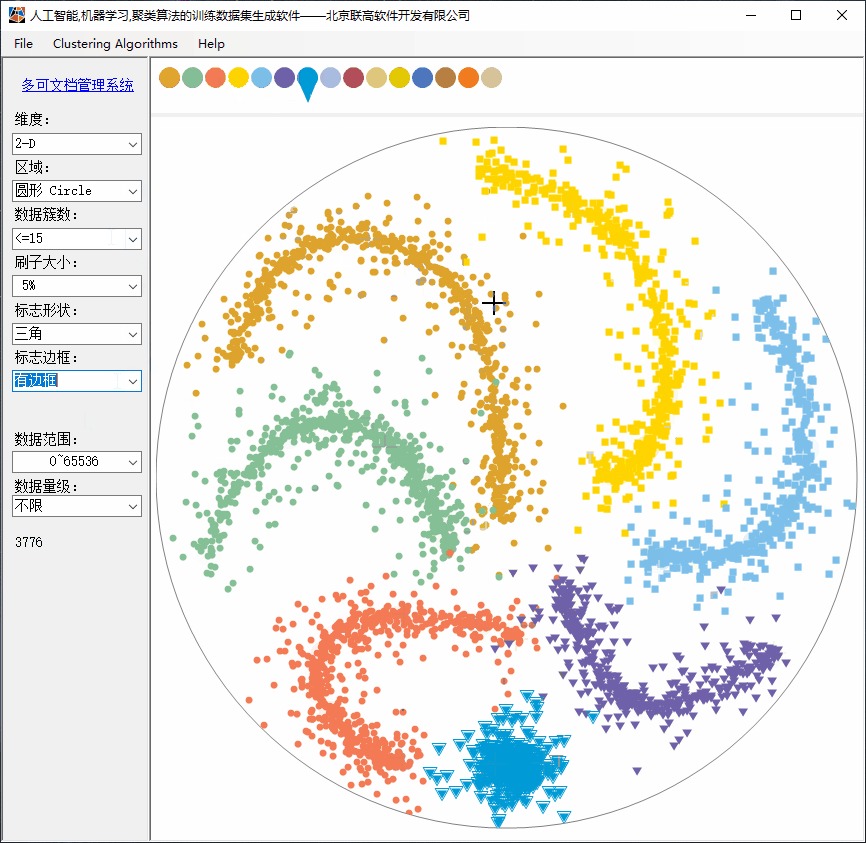
TOY DATASETS for Clustering Algorithm, POWER BY TRUFFER.CN & 315SOFT.COM
需定制?Clustering,请联系。
感谢你读到这里,没有软件?没有源代码?稍等。
有赞与关注就有一切!