����Ŀ¼
һ�������Ʒ���
�ڻ���ѧϰ�㷨��,�����ɷ���(Markov chain)�Ǹ�����Ҫ�ĸ�������ɷ���(Markov chain),�ֳ���ɢʱ�������ɷ���(discrete-time Markov chain),�������ѧ�Ұ����ҡ������ɷ�(����:���ߧէ�֧� ���ߧէ�֧֧ӧڧ� ���ѧ�ܧ��)������

1. ���
�����Ʒ�����Ϊ״̬�ռ��д�һ��״̬����һ��״̬ת�������������

-
�ù���Ҫ��߱���������������:
- ��һ״̬�ĸ��ʷֲ�ֻ���ɵ�ǰ״̬����,��ʱ����������ǰ����¼�����֮���������ض����͵ġ������ԡ����������ɷ����ʡ�
-
�����Ʒ�����Ϊʵ�ʹ��̵�ͳ��ģ�;�������Ӧ�á�
-
�������ɷ�����ÿһ��,ϵͳ���ݸ��ʷֲ�,���Դ�һ��״̬�䵽��һ��״̬,Ҳ���Ա��ֵ�ǰ״̬��
-
״̬�ĸı����ת��,�벻ͬ��״̬�ı���صĸ��ʽ���ת�Ƹ�����
-
�����ɷ�������ѧ��ʾΪ:
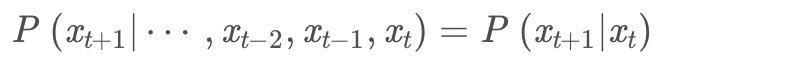
-
��Ȼijһʱ��״̬ת�Ƶĸ���ֻ����ǰһ��״̬,��ôֻҪ���ϵͳ����������״̬֮���ת�Ƹ���,��������Ʒ�����ģ�;Ͷ�����
2. �������
��ͼ�е������Ʒ�����������ʾ����ģ��,��������״̬:ţ��(Bull market), ����(Bear market)�ͺ���(Stagnant market)��
ÿһ��״̬����һ���ĸ���ת������һ��״̬������,ţ����0.025�ĸ���ת�������̵�״̬��
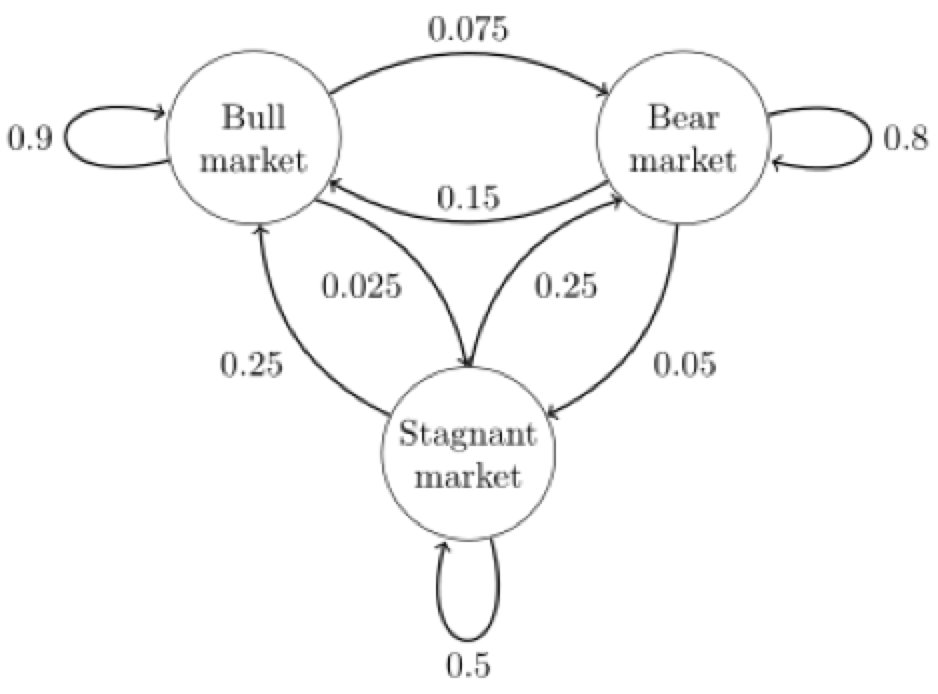
- ���״̬����ת��ͼ�����Ծ������ʽ��ʾ��
- ������Ƕ��������Pijһλ��P(i, j)��ֵΪP(j|i),����״̬i��Ϊ״̬j�ĸ��ʡ�
- ���ⶨ��ţ�С����С����̵�״̬�ֱ�Ϊ0��1��2,�������ǵõ��������Ʒ���ģ�͵�״̬ת�ƾ���Ϊ:
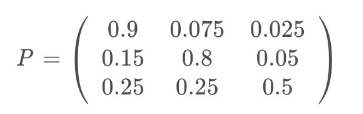
�����״̬ת�ƾ���Pȷ���Ժ�,��������ģ�;��Ѿ�ȷ��!
3. ��
- �����Ʒ�����Ϊ
- ״̬�ռ��д�һ��״̬����һ��״̬ת�������������
- �ù���Ҫ��߱���������������:
- ��һ״̬�ĸ��ʷֲ�ֻ���ɵ�ǰ״̬����,��ʱ����������ǰ����¼�����֮����
����HMM���
�������ɷ�ģ��(Hidden Markov Model,HMM)��ͳ��ģ��,����������һ����������δ֪�����������ɷ������
���ѵ��Ǵӿɹ۲�IJ�����ȷ���ù��̵�����������Ȼ��������Щ����������һ���ķ���,����ģʽʶ����
1. ����
��������һ����һ��������������:
- ������������������ͬ�����ӡ�
- ��һ������������ƽ����������(���������ΪD6),6����,ÿ����(1,2,3,4,5,6)���ֵĸ�����1/6��
- �ڶ��������Ǹ�������(���������ΪD4),ÿ����(1,2,3,4)���ֵĸ�����1/4��
- �����������а˸���(���������ΪD8),ÿ����(1,2,3,4,5,6,7,8)���ֵĸ�����1/8��

- ���ǿ�ʼ������,�����ȴ�������������һ��,����ÿһ�����ӵĸ��ʶ���1/3��
- Ȼ������������,�õ�һ������,1,2,3,4,5,6,7,8�е�һ������ͣ���ظ���������,���ǻ�õ�һ������,ÿ�����ֶ���1,2,3,4,5,6,7,8�е�һ����
- �������ǿ��ܵõ���ôһ������(������10��):1 6 3 5 2 7 3 5 2 4
- ����ֽ����ɼ�״̬����
�������������ɷ�ģ����,���Dz���������ôһ���ɼ�״̬��,����һ������״̬����
- �����������,�����״̬���������õ����ӵ����С�
- ����,����״̬���п�����:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
һ����˵,HMM��˵���������ɷ�����ʵ��ָ����״̬��,��Ϊ����״̬(����)֮�����ת������(transition probability)��
- ���������������,D6����һ��״̬��D4,D6,D8�ĸ��ʶ���1/3��D4,D8����һ��״̬��D4,D6,D8��ת������Ҳ��һ����1/3��
- �����趨��Ϊ���ʼ����˵���,����������ʵ�ǿ��������趨ת�����ʵġ�
- ����,���ǿ�����������,D6���治�ܽ�D4,D6������D6�ĸ�����0.9,��D8�ĸ�����0.1��
- ��������һ���µ�HMM��
ͬ����,���ܿɼ�״̬֮��û��ת������,��������״̬�Ϳɼ�״̬֮����һ�����ʽ����������(emission probability)��
- �����ǵ�������˵,������(D6)����1�����������1/6������2,3,4,5,6�ĸ���Ҳ����1/6��
- ����ͬ�����Զ�������ʽ����������塣����,����һ�����ij������ֽŵ���������,��������1�ĸ��ʸ���,��1/2,��������2,3,4,5,6�ĸ�����1/10��


��ʵ����HMM��˵,�����ǰ֪����������״̬֮���ת�����ʺ���������״̬�����пɼ�״̬֮����������,��ģ�����൱���ġ�����Ӧ��HMMģ��ʱ����,������ȱʧ��һ������Ϣ�ġ�
- ��ʱ����֪�������м���,ÿ��������ʲô,���Dz�֪������������������;
- ��ʱ����ֻ�ǿ����˺ܶ�������ӵĽ��,ʣ�µ�ʲô����֪����
���Ӧ���㷨ȥ������Щȱʧ����Ϣ,�ͳ���һ������Ҫ�����⡣��Щ�㷨�һ��ں�����ϸ����
2. ������������
- ����ģ��,�����Ч��������۲����еĸ���?����֮,�������ģ����۲�����֮���ƥ��̶�?
- ����ģ�ͺ۲�����,����ҵ���˹۲�������ƥ���״̬����?����֮,��θ��ݹ۲������ƶϳ����ص�ģ��״̬?
- �����۲�����,��ε���ģ�Ͳ���ʹ�ø����г��ֵĸ������?����֮,���ѵ��ģ��ʹ������õ������۲�����?
ǰ����������ģʽʶ�������:1) �����������Ʒ�ģ�͵õ�һ���ɹ۲�״̬���еĸ���(����);2) �ҵ�һ������״̬������ʹ��������в���һ���ɹ۲�״̬���еĸ������(����)��������������Ǹ���һ�����Թ۲쵽��״̬���м�����һ���������Ʒ�ģ��(ѧϰ)��
��Ӧ����������ⷨ:
- ��ǰ�㷨(Forward Algorithm)������㷨(Backward Algorithm)
- ά�ر��㷨(Viterbi Algorithm)
- ��ķ-Τ�����㷨(Baum-Welch Algorithm) (Լ����EM�㷨)
����HMMģ�ͻ���
1. ʲô����������ҪHMMģ��
��������������ʲô����������������HMMģ�͡�ʹ��HMMģ��ʱ���ǵ�����һ��������������:
- 1)���ǵ������ǻ������е�,����ʱ������,����״̬���С�
- 2)���ǵ�����������������,
- һ�����������ǿ��Թ۲��,���۲�����;
- ����һ�������Dz��ܹ۲쵽��,������״̬����,���״̬���С�
��������������,��ô�������һ�������HMMģ�������Խ����������������ʵ���������Ǻܶ�ġ�
-
����:�����ڸ����д�μ�,���ڼ������ó�����һϵ���ַ����ǹ۲�����,����ʵ����д��һ�λ���������״̬����,���뷨��������Ǵ������һϵ���ַ������ܵIJ²���Ҫд��һ�λ�,��������ܵĴ��������ǰ������ѡ��,��Ϳ��Կ���һ��HMMģ���ˡ�
-
�پ�һ��,�������Ͽν���,�ҷ�����һ���������������ǹ۲�����,����ʵ��Ҫ�����һ�λ���������״̬����,����Ե�����,���Ǵ���һ���������������жϳ��������Ҫ����Ļ������ݡ�
����Щ������,���ǿ��Է���,HMMģ�Ϳ��������ڡ��������������������ȷ,���������þ�ȷ����ѧ�������������ǵ�HMMģ�͡�
2. HMMģ�͵Ķ���
����HMMģ��,�������Ǽ���Q�����п��ܵ�����״̬�ļ���,V�����п��ܵĹ۲�״̬�ļ���,��:
-
Q
=
q
1
,
q
2
,
.
.
.
,
q
N
Q={q_1,q_2,...,q_N}
Q=q1?,q2?,...,qN?
?? -
V
=
v
1
,
v
2
,
.
.
.
v
M
V={v_1,v_2,...v_M}
V=v1?,v2?,...vM?
??
����,N�ǿ��ܵ�����״̬��,M�����еĿ��ܵĹ۲�״̬����
����һ������ΪT������,i�Ƕ�Ӧ��״̬����, O�Ƕ�Ӧ�Ĺ۲�����,��:
- i = i 1 , i 2 , . . . , i T i={i_1,i_2,...,i_T} i=i1?,i2?,...,iT???
-
O
=
o
1
,
o
2
,
.
.
.
o
T
O={o_1,o_2,...o_T}
O=o1?,o2?,...oT?
??
����,����һ������״̬ i t �� Q i_t \in Q it?��Q, ����һ���۲�״̬ o t �� V o_t\in V ot?��V
HMMģ��������������Ҫ�ļ�������:
1) ��������Ʒ���������
-
������ʱ�̵�����״ֻ̬��������ǰһ������״̬��
-
��Ȼ���������е㼫��,��Ϊ�ܶ�ʱ�����ǵ�ijһ������״̬������ֻ������ǰһ������״̬,������ǰ����������ǰ������
-
������������ĺô�����ģ�ͼ�,������⡣
-
�����ʱ��t������״̬�� i t = q i ? ? i_t=q_i?? it?=qi???,��ʱ�� t + 1 t+1 t+1������״̬�� i t + 1 = q j i_{t+1}=q_j it+1?=qj?, ���ʱ��t��ʱ��t+1��HMM״̬ת�Ƹ��� a i j a_{ij} aij?���Ա�ʾΪ:
- a i j = P ( i t + 1 = q j �O i t = q i ) a_{ij}=P(i_{t+1}= q_j | i_t=q_i) aij?=P(it+1?=qj?�Oit?=qi?)
-
���� a i j a_{ij} aij??? ������������Ʒ�����״̬ת�ƾ���A:
-
A
=
[
a
i
j
]
N
��
N
A=[a_{ij}]_{N \times N}
A=[aij?]N��N?
??
-
A
=
[
a
i
j
]
N
��
N
A=[a_{ij}]_{N \times N}
A=[aij?]N��N?
2) �۲�����Լ�����
-
������ʱ�̵Ĺ۲�״ֻ̬���������ڵ�ǰʱ�̵�����״̬,��Ҳ��һ��Ϊ�˼�ģ�͵ļ��衣
-
�����ʱ��t������״̬�� i t = q j i_t=q_j it?=qj??? , ����Ӧ�Ĺ۲�״̬Ϊ o t = v k o_t=v_k ot?=vk??? , ���ʱ�̹۲�״̬ v k v_k vk??? ������״̬ q j q_j qj??? �����ɵĸ���Ϊ b j ( k ) b_j(k) bj?(k),����:
- b j ( k ) = P ( o t = v k �O i t = q j ) b_j(k)=P(o_t=v_k|i_t=q_j) bj?(k)=P(ot?=vk?�Oit?=qj?)
-
���� b j ( k ) b_j(k) bj?(k)������ɹ۲�״̬���ɵĸ��ʾ���B:
-
B
=
[
b
j
(
k
)
]
N
��
M
B=[b_j(k)]_{N \times M}
B=[bj?(k)]N��M?
??
-
B
=
[
b
j
(
k
)
]
N
��
M
B=[b_j(k)]_{N \times M}
B=[bj?(k)]N��M?
-
����֮��,������Ҫһ����ʱ��t=1������״̬���ʷֲ� �� \Pi �� :
- �� = [ �� i ] N \Pi =[\Pi_i]_N ��=[��i?]N?
-
���� �� i = P ( i 1 = q i ) \Pi _i=P(i_1=q_i) ��i?=P(i1?=qi?)
-
һ��HMMģ��,����������״̬��ʼ���ʷֲ� �� \Pi �� , ״̬ת�Ƹ��ʾ���A�۲�״̬���ʾ���B������
�� \Pi �� ,A����״̬����,B�����۲����С�
���,HMMģ�Ϳ�����һ����Ԫ�� �� \lambda �� ��ʾ����:
- �� = ( A , B , �� ) = \lambda =(A,B, \Pi )= ��=(A,B,��)=(״̬����,�۲�����,��ʼ״̬���ʷֲ�)
3. һ��HMMģ��ʵ��
����������һ����ʵ������������������HMMģ�͡�����һ�����������ģ�͡�
������Դ����ġ�ͳ��ѧϰ��������
����������3������,ÿ�������ﶼ�к�ɫ�Ͱ�ɫ������,��������������������ֱ���:

��������ķ����Ӻ��������,��ʼ��ʱ��,
- �ӵ�һ�����ӳ���ĸ�����0.2,
- �ӵڶ������ӳ���ĸ�����0.4,
- �ӵ��������ӳ���ĸ�����0.4��
��������ʳ�һ�����,����Żء�
Ȼ��ӵ�ǰ����ת�Ƶ���һ�����ӽ��г�������:
- �����ǰ����ĺ����ǵ�һ������,����0.5�ĸ�����Ȼ���ڵ�һ�����Ӽ�������,��0.2�ĸ���ȥ�ڶ������ӳ���,��0.3�ĸ���ȥ���������ӳ���
- �����ǰ����ĺ����ǵڶ�������,����0.5�ĸ�����Ȼ���ڵڶ������Ӽ�������,��0.3�ĸ���ȥ��һ�����ӳ���,��0.2�ĸ���ȥ���������ӳ���
- �����ǰ����ĺ����ǵ���������,����0.5�ĸ�����Ȼ���ڵ��������Ӽ�������,��0.2�ĸ���ȥ��һ�����ӳ���,��0.3�ĸ���ȥ�ڶ������ӳ���
�����ȥ,ֱ���ظ�����,�õ�һ�������ɫ�Ĺ۲�����:
- O={��,��,��}
ע�������������,�۲���ֻ�ܿ��������ɫ����,ȴ���ܿ������Ǵ��ĸ�������ȡ������
��ô��������ǰ��HMMģ�͵Ķ���,���ǵĹ۲�״̬������:
- V={��,��},M=2
���ǵ�����״̬������:
- Q={����1,����2,����3},N=3
���۲����к�״̬���еij���Ϊ3.
��ʼ״̬�ֲ� �� \Pi ��Ϊ:
- �� = ( 0.2 , 0.4 , 0.4 ) T \Pi=(0.2,0.4,0.4)^T ��=(0.2,0.4,0.4)T
??
״̬ת�Ƹ��ʷֲ�A����Ϊ:

�۲�״̬����B����Ϊ:
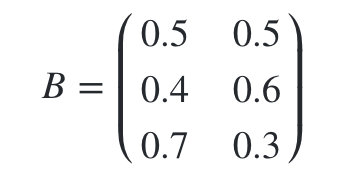
4. HMM�۲����е�����
�����������,����Ҳ���Գ����HMM�۲��������ɵĹ��̡�
-
�������HMM��ģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��),�۲����еij��� T T T
-
����ǹ۲����� O = o 1 , o 2 , . . . o T O={o_1,o_2,...o_T} O=o1?,o2?,...oT?
���ɵĹ�������:
-
1)���ݳ�ʼ״̬���ʷֲ�\Pi����������״̬ i 1 i_1 i1?
-
2)for t from 1 to T
- a. ��������״̬ i t i_t it?�Ĺ۲�״̬�ֲ� b i t ( k ) b_{it}(k) bit?(k)���ɹ۲�״̬ o t o_t ot?
- b. ��������״̬
i
t
i_t
it? ��״̬ת�Ƹ��ʷֲ�
a
i
t
,
i
t
+
1
ai_t, i_{t+1}
ait?,it+1??��������״̬
i
t
+
1
i_{t+1}
it+1?
??
���е� o t o_t ot??? һ���γɹ۲����� O = o 1 , o 2 , . . . o T O={o_1,o_2,...o_T} O=o1?,o2?,...oT?
5. HMMģ�͵�������������
HMMģ��һ�������������������Ҫ���:
1)�����۲����и��� ���� ǰ�����ĸ��ʼ���
- ������ģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��)�۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?},������ģ�� �� \lambda �� ��ijһ���۲�����O���ֵĸ���P(O| �� \lambda �� )��
- �������������Ҫ�õ�ǰ������㷨,��HMMģ��������������ġ�
2)Ԥ������,Ҳ��Ϊ�������� ����ά�ر�(Viterbi)�㷨
- ������ģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��)�۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?},������۲�����������,����ܳ��ֵĶ�Ӧ��״̬���С�
- �������������Ҫ�õ����ڶ�̬�滮��ά�ر��㷨,��HMMģ�����������и��ӶȾ��е��㷨��
3)ģ�Ͳ���ѧϰ���� ���� ��ķ-Τ����(Baum-Welch)�㷨(״̬δ֪) ,����һ��ѧϰ����
- �������۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?},����ģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��)�IJ���,ʹ��ģ���¹۲����е��������� P ( O �O �� ) P(O|\lambda ) P(O�O��)���
- �������������Ҫ�õ�����EM�㷨�ı�ķ-Τ�����㷨,��HMMģ��������������ӵġ�
������������,���ǽ����������������չ�����ۡ�
�ġ�ǰ������㷨�����۲����и���
�������Ǿ�עHMM��һ����������Ľ������,����֪ģ�ͺ۲�����,��۲����г��ֵĸ��ʡ�
1. �ع�HMM����һ:��۲����еĸ���
�������ǻع���HMMģ�͵�����һ����������������ġ�
������֪HMMģ�͵IJ��� �� = ( A , B , �� ) \lambda =(A,B,\Pi) ��=(A,B,��)��
����A������״̬ת�Ƹ��ʵľ���,
B�ǹ۲�״̬���ɸ��ʵľ���,
�� \Pi �� ������״̬�ij�ʼ���ʷֲ���
ͬʱ����Ҳ�Ѿ��õ��˹۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?},
��������Ҫ��۲�����O��ģ�� �� \lambda �� �³��ֵ��������� P ( O �O �� ) P(O|\lambda ) P(O�O��)��
էһ��,�������ܼ���Ϊ����֪�����е�����״̬֮���ת�Ƹ��ʺ����д�����״̬���۲�״̬���ɸ���,��ô�����ǿ��Ա���������
���ǿ����оٳ����п��ܳ��ֵij���ΪT���������� i = { i 1 , i 2 , . . . , i T } i=\{i_1,i_2,...,i_T\} i={i1?,i2?,...,iT?},�ֱ������Щ����������۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?}�����ϸ��ʷֲ� P ( O , i �O �� ) P(O,i|\lambda ) P(O,i�O��),�������ǾͿ��Ժ����������Ե�ֲ� P ( O �O �� ) P(O|\lambda ) P(O�O��)�ˡ�
���屩�����ķ�����������:
-
����,������������ i = i 1 , i 2 , . . . , i T i={i_1,i_2,...,i_T} i=i1?,i2?,...,iT?���ֵĸ�����:
-
P
(
i
�O
��
)
=
��
i
1
a
i
1
,
i
2
a
i
2
,
i
3
.
.
.
a
i
T
?
1
,
i
T
P(i|\lambda )=\Pi _{i1}a_{i1,i2}a_{i2,i3}...a_{iT-1,iT}
P(i�O��)=��i1?ai1,i2?ai2,i3?...aiT?1,iT?
??
-
P
(
i
�O
��
)
=
��
i
1
a
i
1
,
i
2
a
i
2
,
i
3
.
.
.
a
i
T
?
1
,
i
T
P(i|\lambda )=\Pi _{i1}a_{i1,i2}a_{i2,i3}...a_{iT-1,iT}
P(i�O��)=��i1?ai1,i2?ai2,i3?...aiT?1,iT?
-
���ڹ̶���״̬���� i = i 1 , i 2 , . . . , i T i={i_1,i_2,...,i_T} i=i1?,i2?,...,iT??? ,����Ҫ��Ĺ۲����� O = o 1 , o 2 , . . . o T O={o_1,o_2,...o_T} O=o1?,o2?,...oT??? ���ֵĸ�����:
- P ( O �O i , �� ) = b i 1 ( o 1 ) b i 2 ( o 2 ) . . . b i T ( o T ) P(O|i,\lambda )=b_{i1}(o_1)b_{i2}(o_2)...b_{iT}(o_T) P(O�Oi,��)=bi1?(o1?)bi2?(o2?)...biT?(oT?)
-
��O��i���ϳ��ֵĸ�����:

-
Ȼ�����Ե���ʷֲ�,���ɵõ��۲�����O��ģ�� �� \lambda �� �³��ֵ���������P(O| �� \lambda �� ):
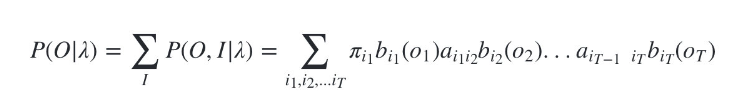
��Ȼ����������Ч,����������ǵ�����״̬��N�dz�����Ǿ��鷳��,��ʱ����Ԥ��״̬�� N T N^T NT�����,�㷨��ʱ�临�Ӷ��� O ( T N T ) O(TN^T) O(TNT)�ġ�
��˶���һЩ����״̬�����ٵ�ģ��,���ǿ����ñ�����ⷨ���õ��۲����г��ֵĸ���,�����������״̬��,�������㷨̫��ʱ,������ҪѰ�����������㷨��
ǰ������㷨���������������ڽϵ͵�ʱ�临�Ӷ����������������ġ�
2. ��ǰ���㷨��HMM�۲����еĸ���
ǰ������㷨��ǰ���㷨�ͺ����㷨��ͳ��,�������㷨������������HMM�۲����еĸ��ʡ�������������ǰ���㷨���������������ġ�
2.1 ��������
ǰ���㷨���������ڶ�̬�滮���㷨,Ҳ��������Ҫͨ���ҵ��ֲ�״̬���ƵĹ�ʽ,����һ�����Ĵ�����������Ž���չ��������������Ž⡣
-
��ǰ���㷨��,ͨ�����塰ǰ����ʡ������嶯̬�滮������ֲ�״̬��
-
ʲô��ǰ�������, ��ʵ����ܼ�:����ʱ��tʱ����״̬Ϊ q i q_i qi?, �۲�״̬������Ϊ o 1 , o 2 , . . . o t o_1,o_2,...o_t o1?,o2?,...ot???�ĸ���Ϊǰ����ʡ���Ϊ:
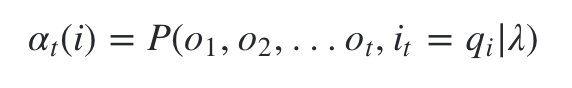
-
��Ȼ�Ƕ�̬�滮,���Ǿ�Ҫ������,���ڼ��������Ѿ��ҵ�����ʱ��tʱ��������״̬��ǰ�����,����������Ҫ���Ƴ�ʱ��t+1ʱ��������״̬��ǰ����ʡ�
-
���ǿ��Ի���ʱ��tʱ��������״̬��ǰ�����,�ٳ��Զ�Ӧ��״̬ת�Ƹ���,�� �� t ( j ) a j i \alpha _t(j)a_{ji} ��t?(j)aji??? ������ʱ��t�۲ o 1 , o 2 , . . . o t o_1,o_2,...o_t o1?,o2?,...ot?,����ʱ��t����״̬ q j q_j qj??? , ʱ��t+1����״̬ q i q_i qi?�ĸ��ʡ�
-
������������е��߶�Ӧ�ĸ������,�� �� j = 1 N �� ( j ) �� j i \sum_{j=1}^{N}\alpha(j)\alpha_{ji} ��j=1N?��(j)��ji?������ʱ��t�۲ o 1 , o 2 , . . . o t o_1,o_2,...o_t o1?,o2?,...ot??? ,����ʱ��t+1����״̬ q i q_i qi??? �ĸ��ʡ�
-
����һ��,���ڹ۲�״̬ o t + 1 o_{t+1} ot+1??? ֻ������t+1ʱ������״̬ q i q_i qi?, ����
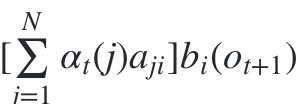 ������ʱ��t+1�۲
o
1
,
o
2
,
.
.
.
o
t
,
o
t
+
1
o_1,o_2,...o_t,o_{t+1}
o1?,o2?,...ot?,ot+1??? ,����ʱ��t+1����״̬
q
i
q_i
qi??? �ĸ��ʡ�
������ʱ��t+1�۲
o
1
,
o
2
,
.
.
.
o
t
,
o
t
+
1
o_1,o_2,...o_t,o_{t+1}
o1?,o2?,...ot?,ot+1??? ,����ʱ��t+1����״̬
q
i
q_i
qi??? �ĸ��ʡ� -
���������,ǡǡ����ʱ��t+1��Ӧ������״̬i��ǰ�����,�������ǵõ���ǰ����ʵĵ��ƹ�ϵʽ����:

���ǵĶ�̬�滮��ʱ��1��ʼ,��ʱ��T����,���� �� T ( i ) \alpha _T(i) ��T?(i)��ʾ��ʱ��T�۲�����Ϊ o 1 , o 2 , . . . o T o_1,o_2,...o_T o1?,o2?,...oT??? ,����ʱ��T����״̬ q i q_i qi?�ĸ���,����ֻҪ����������״̬��Ӧ�ĸ������,�� �� i = 1 N �� T ( i ) \sum_{i=1}^{N}\alpha_T(i) ��i=1N?��T?(i)�͵õ�����ʱ��T�۲�����Ϊ o 1 , o 2 , . . . o t o_1,o_2,...o_t o1?,o2?,...ot?�ĸ��ʡ�
2.2 �㷨�ܽ�
-
����:HMMģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��),�۲����� O = ( o 1 , o 2 , . . . o T ) O=(o_1,o_2,...o_T) O=(o1?,o2?,...oT?)
-
���:�۲����и��� P ( O �O �� ) P(O|\lambda ) P(O�O��)
-
1)����ʱ��1�ĸ�������״̬ǰ�����:

-
2)����ʱ��2,3,�� ��Tʱ�̵�ǰ�����:
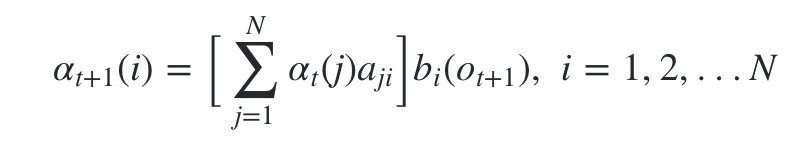
-
3)�������ս��:
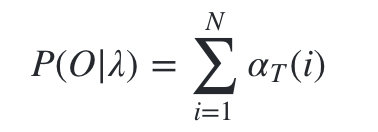
-
�ӵ��ƹ�ʽ���Կ���,���ǵ��㷨ʱ�临�Ӷ��� O ( T N 2 ) O(TN^2) O(TN2),�ȱ����ⷨ��ʱ�临�Ӷ� O ( T N T ) O(TN^T) O(TNT)���˼�����������
3. HMMǰ���㷨���ʵ��
����������ǰ������������������ʾǰ����ʵļ��㡣 ���ǵĹ۲켯����:

���ǵ�״̬������:

���۲����к�״̬���еij���Ϊ3.
��ʼ״̬�ֲ�Ϊ:

״̬ת�Ƹ��ʷֲ�����Ϊ:

�۲�״̬���ʾ���Ϊ:
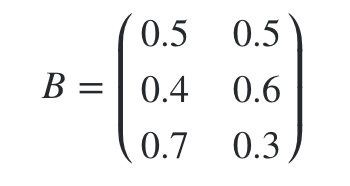
�����ɫ�Ĺ۲�����:
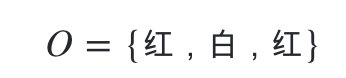
����������һ�ڵ�ǰ���㷨�����ȼ���ʱ��1����״̬��ǰ�����:
ʱ��1�Ǻ�ɫ��,
-
����״̬�Ǻ���1�ĸ���Ϊ:
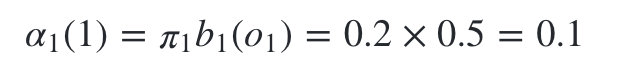
-
����״̬�Ǻ���2�ĸ���Ϊ:
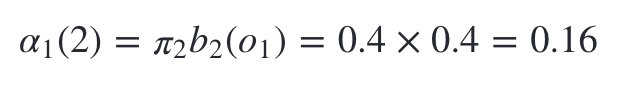
-
����״̬�Ǻ���3�ĸ���Ϊ:
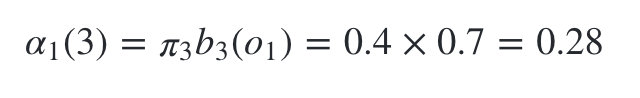
�������ǿ��Կ�ʼ������,���ȵ���ʱ��2����״̬��ǰ�����:
ʱ��2�ǰ�ɫ��,
-
����״̬�Ǻ���1�ĸ���Ϊ:
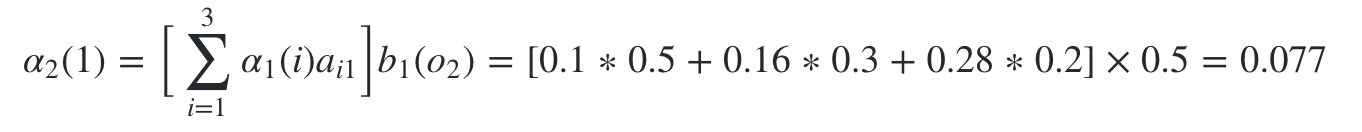
-
����״̬�Ǻ���2�ĸ���Ϊ:
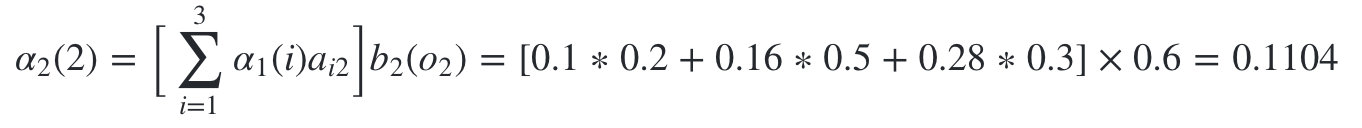
-
����״̬�Ǻ���3�ĸ���Ϊ:

��������,�������ǵ���ʱ��3����״̬��ǰ�����:
ʱ��3�Ǻ�ɫ��,
-
����״̬�Ǻ���1�ĸ���Ϊ:
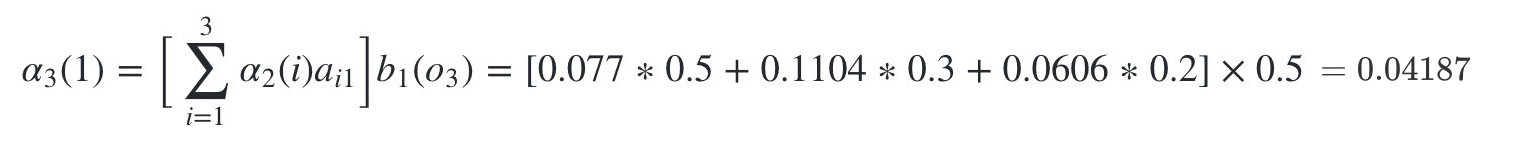
-
����״̬�Ǻ���2�ĸ���Ϊ:
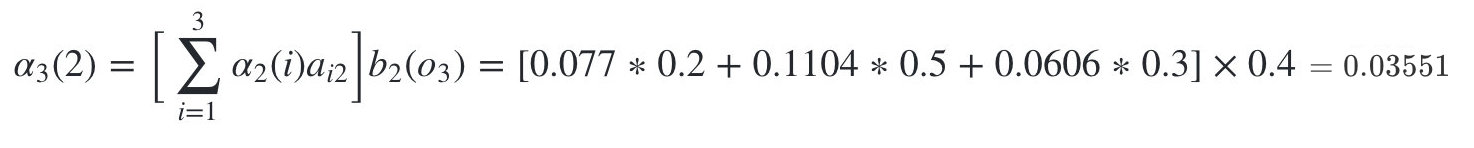
-
����״̬�Ǻ���3�ĸ���Ϊ:
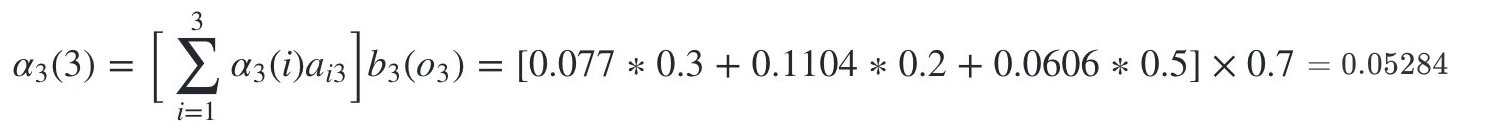
������������۲�����:O=��,��,��ĸ���Ϊ:
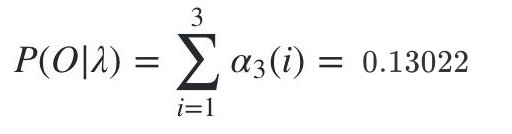
����㷨ԭ�����һ��,�����в�ѯ
�塢ά�ر��㷨��������״̬����
ѧϰĿ��
֪��ά�ر��㷨��������״̬����
�ڱ�ƪ���ǻ�����ά�ر��㷨��������״̬����,������ģ�ͺ۲�����,������۲�����������,����ܳ��ֵĶ�Ӧ������״̬������
HMMģ�͵Ľ���������õ��㷨��ά�ر��㷨,��ȻҲ���������㷨�������������⡣
ͬʱά�ر��㷨��һ��ͨ�õ����������·���Ķ�̬�滮�㷨,Ҳ�������ںܶ��������⡣
1. HMM���������״̬����������
HMMģ�͵Ľ������⼴:
- ����ģ�� �� = ( A , B , �� ) \lambda=(A,B,\Pi) ��=(A,B,��)�۲����� O = o 1 , o 2 , . . . o T O={o_1,o_2,...o_T} O=o1?,o2?,...oT?,������۲�����O������,����ܳ��ֵĶ�Ӧ��״̬���� I ? = i 1 ? , i 2 ? , . . . i T ? I^\ast ={i^\ast _1,i^\ast _2,...i^\ast _T} I?=i1??,i2??,...iT?? ,�� P ( I ? �O O ) P(I^\ast |O) P(I?�OO)�����
һ�����ܵĽ��ƽⷨ������۲�����O��ÿ��ʱ��t����ܵ�����״̬ i t ? i^\ast _t it?? Ȼ��õ�һ�����Ƶ�����״̬���� I ? = i 1 ? , i 2 ? , . . . i T ? I^\ast ={i^\ast _1,i^\ast _2,...i^\ast _T} I?=i1??,i2??,...iT??I��Ҫ����������ⲻ��,����ǰ������㷨�����۲����и��ʵĶ���:
- �ڸ���ģ��
��
\lambda
���۲�����Oʱ,��ʱ��t����״̬
q
i
q_i
qi??? �ĸ�����
��
t
(
i
)
\gamma _t(i)
��t?(i),������ʿ���ͨ��HMM��ǰ���㷨������㷨���㡣����������:
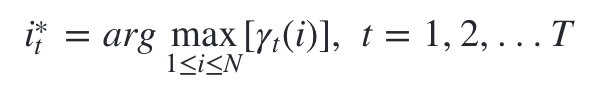
�����㷨�ܼ�,����ȴ���ܱ�֤Ԥ���״̬��������������ܵ�״̬����,��ΪԤ���״̬������ijЩ���ڵ�����״̬���ܴ���ת�Ƹ���Ϊ0�������
��ά�ر��㷨���Խ�HMM��״̬������Ϊһ������������,��������㷨������,��������������ά�ر��㷨����HMM����ķ�����
2. ά�ر��㷨����
ά�ر��㷨��һ��ͨ�õĽ����㷨,�ǻ��ڶ�̬�滮�����������·���ķ�����
��Ȼ�Ƕ�̬�滮�㷨,��ô����Ҫ�ҵ����ʵľֲ�״̬,�Լ��ֲ�״̬�ĵ��ƹ�ʽ����HMM��,ά�ر��㷨�����������ֲ�״̬���ڵ��ơ�
1)��һ���ֲ�״̬����ʱ��t����״̬Ϊ i i i���п��ܵ�״̬ת��·�� i 1 , i 2 , . . . i t i_1,i_2,...i_t i1?,i2?,...it??? �еĸ������ֵ��
- ��Ϊ
��
t
(
i
)
\delta _t(i)
��t?(i):
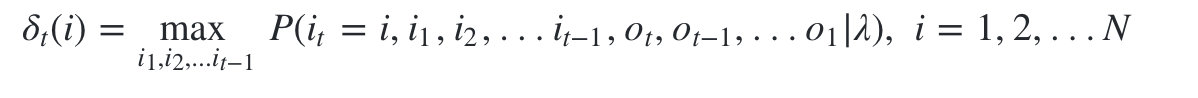
�� �� t ( i ) \delta _t(i) ��t?(i)�Ķ�����Եõ� �� \delta ���ĵ��Ʊ���ʽ:
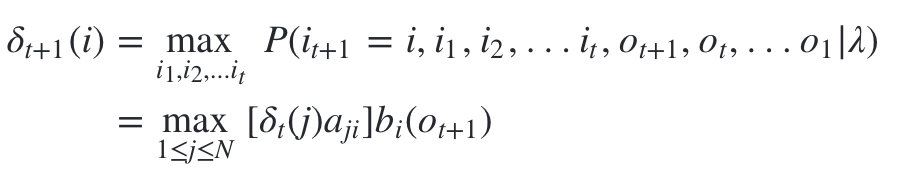
2)�ڶ����ֲ�״̬�ɵ�һ���ֲ�״̬���Ƶõ���
- ���Ƕ�����ʱ��t����״̬Ϊi�����е���״̬ת��·�� ( i 1 , i 2 , . . . , i t ? 1 , i ) (i_1,i_2,...,i_{t-1},i) (i1?,i2?,...,it?1?,i)�и�������ת��·���е�t-1���ڵ������״̬Ϊ �� t ( i ) \psi _t(i) ��t?(i),
- ����Ʊ���ʽ���Ա�ʾΪ:
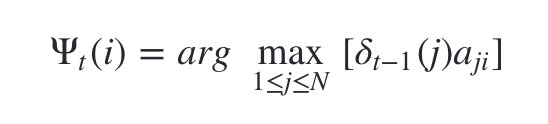
�����������ֲ�״̬,���ǾͿ��Դ�ʱ��0һֱ���Ƶ�ʱ��T,Ȼ������ �� t ( i ) \psi _t(i) ��t?(i)��¼��ǰһ������ܵ�״̬�ڵ����,ֱ���ҵ����ŵ�����״̬���С�
3. ά�ر��㷨�����ܽ�
�����������ܽ���ά�ر��㷨������:
-
����:HMMģ�� �� = ( A , B , �� ) \lambda=(A,B,\Pi) ��=(A,B,��),�۲����� O = ( o 1 , o 2 , . . . o T ) O=(o_1,o_2,...o_T) O=(o1?,o2?,...oT?)
-
���:���п��ܵ�����״̬���� I ? = i 1 ? , i 2 ? , . . . i T ? I^\ast ={i^\ast _1,i^\ast _2,...i^\ast _T} I?=i1??,i2??,...iT??
??
��������:
-
1)��ʼ���ֲ�״̬:
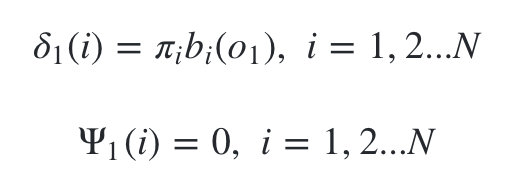
-
2)���ж�̬�滮����ʱ�� t = 2 , 3 , . . . T t=2,3,...T t=2,3,...Tʱ�̵ľֲ�״̬:
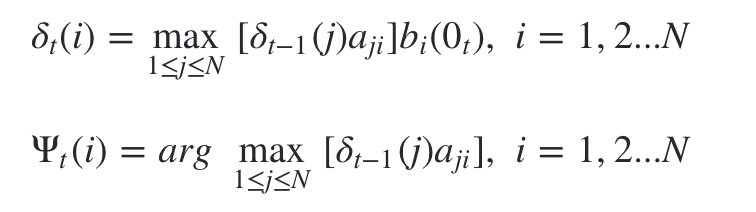
-
3)����ʱ��T���� �� T ( i ) \delta _T(i) ��T?(i),��Ϊ���������״̬���г��ֵĸ��ʡ�����ʱ��T���� �� t ( i ) \psi _t(i) ��t?(i),��Ϊʱ��T����ܵ�����״̬��
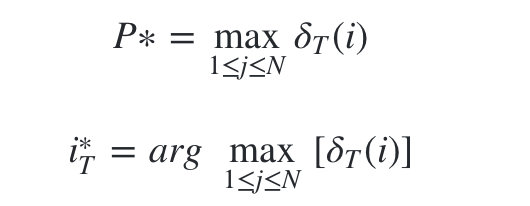
-
4)���þֲ�״̬ �� t ( i ) \psi _t(i) ��t?(i)��ʼ���ݡ����� t = T ? 1 , T ? 2 , . . . , 1 t=T-1,T-2,...,1 t=T?1,T?2,...,1:
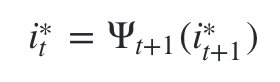
���յõ����п��ܵ�����״̬���� I ? = i 1 ? , i 2 ? , . . . i T ? I^\ast ={i^\ast _1,i^\ast _2,...i^\ast _T} I?=i1??,i2??,...iT??
4. HMMά�ر��㷨���ʵ��
����������Ȼ�ú������������������HMMά�ر��㷨��⡣ ���ǵĹ۲켯����:

���ǵ�״̬������:

���۲����к�״̬���еij���Ϊ3.
��ʼ״̬�ֲ�Ϊ:
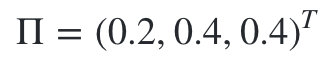
״̬ת�Ƹ��ʷֲ�����Ϊ:

�۲�״̬���ʾ���Ϊ:
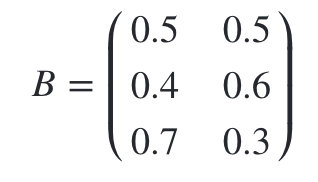
�����ɫ�Ĺ۲�����:

��������ǰ���ά�ر��㷨,������Ҫ�õ���������״̬��ʱ��1ʱ��Ӧ�ĸ��������ֲ�״̬,��ʱ�۲�״̬Ϊ1:
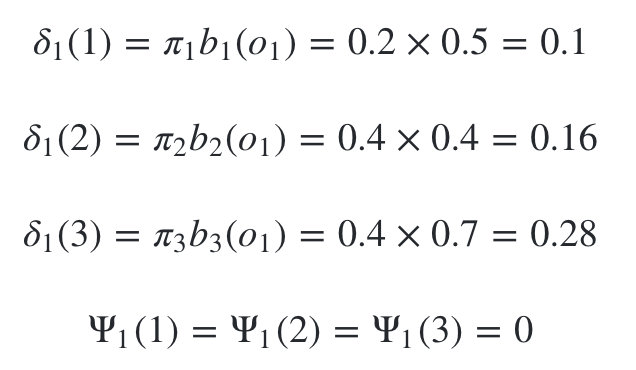
���ڿ�ʼ������������״̬��ʱ��2ʱ��Ӧ�ĸ��������ֲ�״̬,��ʱ�۲�״̬Ϊ2:

����������������״̬��ʱ��3ʱ��Ӧ�ĸ��������ֲ�״̬,��ʱ�۲�״̬Ϊ1:

��ʱ�Ѿ�������ʱ��,���ǿ�ʼ�����ݡ���ʱ������Ϊ
��
3
(
3
)
\delta _3(3)
��3?(3),�Ӷ��õ�
i
3
?
=
3
i^\ast _3=3
i3??=3
���� �� 3 ( 3 ) = 3 \psi _3(3)=3 ��3?(3)=3,���� i 2 ? = 3 i^\ast _2=3 i2??=3 , �������� �� 2 ( 3 ) = 3 \psi _2(3)=3 ��2?(3)=3,���� i 1 ? = 3 i^\ast _1=3 i1??=3���Ӷ��õ����յ�����ܵ�����״̬����Ϊ:(3,3,3)��
������ķ-Τ�����㷨���
1. ���
ģ�Ͳ���ѧϰ���� ���� ��ķ-Τ����(Baum-Welch)�㷨(״̬δ֪) ,
- �������۲����� O = { o 1 , o 2 , . . . o T } O=\{o_1,o_2,...o_T\} O={o1?,o2?,...oT?},����ģ�� �� = ( A , B , �� ) \lambda =(A,B,\Pi ) ��=(A,B,��)�IJ���,ʹ��ģ���¹۲����е��������� P ( O �O �� ) P(O|\lambda ) P(O�O��)���
- ���Ľⷨ��õ��DZ�ķ-Τ�����㷨,��ʵ���ǻ���EM�㷨�����,ֻ������ķ-Τ�����㷨���ֵ�ʱ��,EM�㷨��û�б��������,���Ա���Ϊ��ķ-Τ�����㷨��

2. ��ķ-Τ�����㷨ԭ��
��ķ-Τ�����㷨ԭ����Ȼʹ�õľ���EM�㷨��ԭ��,
- ��ô������Ҫ��E��������Ϸֲ� P ( O , I �O �� ) P(O,I|\lambda) P(O,I�O��)������������ P ( I �O O , �� �� ) P(I|O,\overline{\lambda}) P(I�OO,��)������,���� �� �� \overline{\lambda} ��Ϊ��ǰ��ģ�Ͳ���,
- Ȼ����M������������,�õ����µ�ģ�Ͳ��� �� \lambda ����
���Ų�ͣ�Ľ���EM����,ֱ��ģ�Ͳ�����ֵ����Ϊֹ��
����������E��,��ǰģ�Ͳ���Ϊ �� �� \overline{\lambda} ��??, ���Ϸֲ� P ( O , I �O �� ) P(O,I|\lambda) P(O,I�O��)������������ P ( I �O O , �� �� ) P(I|O,\overline{\lambda}) P(I�OO,��)����������ʽΪ:
- L ( �� , �� �� ) = �� I P ( I �O O , �� �� ) l o g P ( O , I �O �� ) L(\lambda, \overline{\lambda}) = \sum\limits_{I}P(I|O,\overline{\lambda})logP(O,I|\lambda) L(��,��)=I��?P(I�OO,��)logP(O,I�O��)
��M��,���Ǽ�����ʽ,Ȼ��õ����º��ģ�Ͳ�������:
- �� �� = a r g ?? max ? �� �� I P ( I �O O , �� �� ) l o g P ( O , I �O �� ) \overline{\lambda} = arg\;\max_{\lambda}\sum\limits_{I}P(I|O,\overline{\lambda})logP(O,I|\lambda) ��=argmax��?I��?P(I�OO,��)logP(O,I�O��)
ͨ�����ϵ�E����M���ĵ���,ֱ�� �� �� \overline{\lambda} ��������
�ߡ�HMMģ��API����
1. API�İ�װ:
��������:https://hmmlearn.readthedocs.io/en/latest/
pip3 install hmmlearn
2. hmmlearn����
hmmlearnʵ��������HMMģ����,���չ۲�״̬������״̬������ɢ״̬,���Է�Ϊ���ࡣ
GaussianHMM��GMMHMM�������۲�״̬��HMMģ��,��MultinomialHMM����ɢ�۲�״̬��ģ��,Ҳ��������HMMԭ��ϵ��ƪ����ʹ�õ�ģ�͡�
��������Ҫ��������ǰ��һֱ���Ĺ�����ɢ״̬��MultinomialHMMģ�͡�
����MultinomialHMM��ģ��,ʹ�ñȽϼ�,�����м������õIJ���:
- "startprob_"������Ӧ���ǵ�����״̬��ʼ�ֲ�\Pi��,
- "transmat_"��Ӧ���ǵ�״̬ת�ƾ���A,
- "emissionprob_"��Ӧ���ǵĹ۲�״̬���ʾ���B��
3. MultinomialHMMʵ��
����������������ǰ�潲�Ĺ�������Ǹ�����ʹ��MultinomialHMM��һ�顣
import numpy as np
from hmmlearn import hmm
# �趨����״̬�ļ���
states = ["box 1", "box 2", "box3"]
n_states = len(states)
# �趨�۲�״̬�ļ���
observations = ["red", "white"]
n_observations = len(observations)
# �趨��ʼ״̬�ֲ�
start_probability = np.array([0.2, 0.4, 0.4])
# �趨״̬ת�Ƹ��ʷֲ�����
transition_probability = np.array([
[0.5, 0.2, 0.3],
[0.3, 0.5, 0.2],
[0.2, 0.3, 0.5]
])
# �趨�۲�״̬���ʾ���
emission_probability = np.array([
[0.5, 0.5],
[0.4, 0.6],
[0.7, 0.3]
])
# �趨ģ�Ͳ���
model = hmm.MultinomialHMM(n_components=n_states)
model.startprob_=start_probability # ��ʼ״̬�ֲ�
model.transmat_=transition_probability # ״̬ת�Ƹ��ʷֲ�����
model.emissionprob_=emission_probability # �۲�״̬���ʾ���
������������һ��HMM������ά�ر��㷨�Ľ������,ʹ�ú�֮ǰһ���Ĺ۲�����������,��������:
seen = np.array([[0,1,0]]).T # �趨�۲�����
box = model.predict(seen)
print("��Ĺ۲�˳��Ϊ:\n", ", ".join(map(lambda x: observations[x], seen.flatten())))
# ע��:��Ҫʹ��flatten����,��seen�Ӷ�ά���һά
print("����ܵ�����״̬����Ϊ:\n", ", ".join(map(lambda x: states[x], box)))
��������������HMM����һ�Ĺ۲����еĸ��ʵ�����,��������:
print(model.score(seen))
# ��������:-2.03854530992
Ҫע�����score�������ص�������Ȼ����Ϊ�Ķ�������ֵ,������HMM����һ���ֶ�����Ľ����δȡ������ԭʼ������0.13022���Ա�һ��:
import math
math.exp(-2.038545309915233)
# ln0.13022��?2.0385
# ��������:0.13021800000000003