����Ŀ¼
ժҪ
The diffusion model is a generative model of the Encoder-Decoder architecture, which is divided into a diffusion stage and an inverse diffusion stage. In the diffusion stage, by continuously adding noise to the original data, the data is changed from the original distribution to the distribution we expect, for example, the original data distribution is changed to a normal distribution by continuously adding Gaussian noise. During the inverse diffusion stage, a neural network is used to restore the data from a normal distribution to the original data distribution. Its advantage is that each point on the normal distribution is a mapping of the real data, and the model has better interpretability. The disadvantage is that iterative sampling is slow, resulting in low model training and prediction efficiency.
��ɢģ����Encoder-Decoder�ܹ�������ģ��,��Ϊ��ɢ�κ�����ɢ�Ρ� ����ɢ��,ͨ�����϶�ԭʼ������������,ʹ���ݴ�ԭʼ�ֲ���Ϊ���������ķֲ�,����ͨ���������Ӹ�˹������ԭʼ���ݷֲ���Ϊ��̬�ֲ��� ������ɢ��,ʹ�������罫���ݴ���̬�ֲ��ָ���ԭʼ���ݷֲ��� �����ŵ�����̬�ֲ��ϵ�ÿ���㶼����ʵ���ݵ�ӳ��,ģ�;��и��õĿɽ����ԡ� ȱ���ǵ��������ٶ���,����ģ��ѵ����Ԥ��Ч�ʵ͡�
һ�����
Diffusion modelģ�ͷ�Ϊ��ɢ���̺�����ɢ����,��ɢ����ͨ����ԭʼ���ݲ��ϼ����˹����,ʹԭʼ���ݱ�Ϊ��˹�ֲ�������,����
X
0
X_0
X0?
?
>
->
?>
X
T
X_T
XT?������ɢ����ͨ����˹������ԭ��ͼƬ,����
X
T
X_T
XT?
?
>
->
?>
X
0
X_0
X0?��

������ɢ����
2.1 ������ɢ����
���趨��ɢ������һ�������ɷ�����������,��ԭʼ��Ϣ�в������Ӹ�˹����,ÿһ�����Ӹ�˹�����Ĺ����Ǵ�
X
t
?
1
?
>
X
t
X_{t-1} -> X_t
Xt?1??>Xt?,���Ƕ��幫ʽ:
q
(
x
t
�O
x
t
?
1
)
=
N
(
x
t
;
1
?
��
t
x
t
?
1
,
��
t
I
)
q(x_t|x_{t-1}) = N(x_t;\sqrt{1-\beta_t}x_{t-1} ,\beta_tI)
q(xt?�Oxt?1?)=N(xt?;1?��t??xt?1?,��t?I)
�ù�ʽ��ʾ�� x t ? 1 ? > x t x_{t-1}->x_t xt?1??>xt?��һ���� 1 ? �� t x t ? 1 \sqrt{1-\beta_t}x_{t-1} 1?��t??xt?1?Ϊ��ֵ �� t \beta_t ��t?Ϊ����ĸ�˹�ֲ��任��
2.2 �ز������ɵõ�������ʽ
�����ز��������õ�ÿһ�����Ӹ�˹�����Ĺ�ʽ����:
X
t
=
1
?
��
t
X
t
?
1
+
��
t
Z
t
X_t = \sqrt{1-\beta_t}X_{t-1} + \sqrt{\beta}_tZ_t
Xt?=1?��t??Xt?1?+��?t?Zt?
- X t X_t Xt?��ʾ t ʱ�̵����ݷֲ�
- Z t Z_t Zt?��ʾ t ʱ�����ӵĸ�˹����,һ��̶��Ǿ�ֵΪ0����Ϊ1�ĸ�˹�ֲ�
- 1 ? �� t X t ? 1 \sqrt{1-\beta_t}X_{t-1} 1?��t??Xt?1? ��ʾ��ǰʱ�̷ֲ��ľ�ֵ
- �� t \sqrt{\beta}_t ��?t?��ʾ��ǰʱ�̷ֲ��ı���(����= �� �� \sqrt{����} ����?)
ע��:���� �� t \beta_t ��t?��Ԥ���趨0~1֮��ij���,����ɢ���̲����Ρ�
2.3 �õ�ȫ����ɢ��ʽ
��2.2�ĵ�����ʽ�п�֪,��ɢ������ֻ��һ������
��
\beta
��,��
��
\beta
����Ԥ�����õij���,����ɢ��������δ֪����Ҫѧϰ�IJ���,����ֻ��Ҫ֪����ʼ���ݷֲ�
X
0
X_0
X0?��
��
t
\beta_t
��t?�Ϳ��Եõ�����ʱ�̵ķֲ�
X
t
X_t
Xt?,���幫ʽ����:

- X 0 X_0 X0?Ϊԭʼ���ݵķֲ�
- �� t = 1 ? �� t \alpha_t = 1 - \beta_t ��t?=1?��t?
- �� t �� = �� i = 1 t �� i \bar{\alpha_t} = \prod_{i=1}^{t}\alpha_i ��t?��?=��i=1t?��i?
- ZΪ��ֵΪ0����Ϊ1�ĸ�˹�ֲ�
2.4 ��ɢ����ʵ�ִ���
2.4.1 �ܽ���ɢ��ʽ
��2.3��֪��ɢ���̹�ʽΪ:
X
t
=
��
t
��
X
0
+
1
?
��
��
Z
X_t = \sqrt{\bar{\alpha_t}}X_0 + \sqrt{1 - \bar{\alpha}}Z
Xt?=��t?��??X0?+1?����?Z����:
- X 0 X_0 X0?Ϊԭʼ���ݵķֲ�
- �� t = 1 ? �� t \alpha_t = 1 - \beta_t ��t?=1?��t?
- �� t �� = �� i = 1 t �� i \bar{\alpha_t} = \prod_{i=1}^{t}\alpha_i ��t?��?=��i=1t?��i?
- ZΪ��ֵΪ0����Ϊ1�ĸ�˹�ֲ�
2.4.2 ����
-
��make_s_curve��������Ϊ���õ� X 0 X_0 X0?
# �õ�����X0 s_curve, _ = make_s_curve(10**4, noise=0.1) x_0 = s_curve[:, [0, 2]]/10.0 # �鿴��״ print(np.shape(x_0)) # ��ͼ data = x_0.T fig, ax = plt.subplots() ax.scatter(*data, color='red', edgecolor='white') ax.axis('off') dataset = torch.Tensor(data)
-
�ٶ���100��ʱ������, ����ʱ�̵� �� \beta ��
num_steps = 100 betas = torch.linspace(-6, 6, num_steps) betas = torch.sigmoid(betas)*(0.5e-2 - 1e-5)+1e-5�� \beta ��Ϊ0-1֮ǰ��С����,���ֵΪ0.5e-2,��СֵΪ1e-5
-
�õ� �� \alpha ��( �� = 1 ? �� \alpha = 1 - \beta ��=1?��)
alphas = 1 - betas -
�õ�����ʱ�̵� �� t �� \bar{\alpha_t} ��t?��?( �� t �� = �� i = 1 t �� i \bar{\alpha_t} = \prod_{i=1}^{t}\alpha_i ��t?��?=��i=1t?��i?)
alphas_prod = torch.cumprod(alphas, 0) -
�õ� �� t \sqrt{\alpha_t} ��t??
alphas_bar_sqrt = torch.sqrt(alphas_bar) -
�õ� 1 ? �� t �� \sqrt{1-\bar{\alpha_t}} 1?��t?��??
one_minus_alphas_bar_sqrt = torch.sqrt(1-alphas_bar) -
���� X 0 X_0 X0?��ʱ��t,�õ� X t X_t Xt?,�� X t = �� t �� X 0 + 1 ? �� t �� Z X_t = \sqrt{\bar{\alpha_t}}X_0 + \sqrt{1 - \bar{\alpha_t}}Z Xt?=��t?��??X0?+1?��t?��??Z
def x_t(x_0, t): noise = torch.randn_like(x_0) return (alphas_bar_sqrt[t]*x_0 + one_minus_alphas_bar_sqrt[t]*noise) -
��ɢ������ʾ
num_shows = 20 fig, axs = plt.subplots(2, 10, figsize=(28, 3)) plt.rc('text', color='blue') for i in range(num_shows): j = i//10 k = i%10 num_x_t = x_t(dataset, torch.tensor([i*num_steps//num_shows])) axs[j, k].scatter(*num_x_t, color='red', edgecolor='white') axs[j, k].set_axis_off() axs[j, k].set_title('$q(\mathbf{x}_{'+str(i*num_steps//num_shows)+'})$')
��������ɢ����
3.1 Ŀ�깫ʽ
��ɢ�����ǽ�ԭʼ���ݲ��ϼ���õ���˹����,����ɢ�����ǴӸ�˹�����лָ�ԭʼ����,���Ǽٶ�����ɢ������Ȼ��һ�������ɷ����Ĺ���,Ҫ������
X
T
?
>
X
0
X_T->X_0
XT??>X0?,�ù�ʽ��������:
p
��
(
x
t
?
1
�O
x
t
)
=
N
(
x
t
?
1
;
u
��
(
x
t
,
t
)
,
��
��
(
x
t
,
t
)
)
p_\theta(x_{t-1}|x_t) = N(x_{t-1}; u_\theta(x_t, t),\Sigma_\theta(x_t, t) )
p��?(xt?1?�Oxt?)=N(xt?1?;u��?(xt?,t),����?(xt?,t))
3.2 ������������
�Ƶ��õ�������������
q
(
x
t
?
1
�O
x
t
,
x
0
)
q(x_{t-1}|x_t, x_0)
q(xt?1?�Oxt?,x0?)

�䷽��
��
t
��
\bar{\beta_t}
��t?��?Ϊ:
��
t
��
=
1
?
��
t
?
1
��
1
?
��
t
��
��
t
\bar{\beta_t} = \frac{1-\bar{\alpha_{t-1}}}{1-\bar{\alpha_t}}\beta_t
��t?��?=1?��t?��?1?��t?1?��??��t?
��ֵ
u
��
(
x
t
?
1
,
x
0
)
\bar{u}(x_{t-1}, x_0)
u��(xt?1?,x0?)Ϊ:
u
��
(
x
t
?
1
,
x
0
)
=
��
t
(
1
?
��
��
t
?
1
)
1
?
��
t
��
x
t
+
��
��
t
?
1
��
t
1
?
��
t
��
x
0
\bar{u}(x_{t-1}, x_0)=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha_t}}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha_t}}x_0
u��(xt?1?,x0?)=1?��t?��?��t??(1?����t?1?)?xt?+1?��t?��?����t?1??��t??x0?
����ɢ����ģ�Ͳ�Ӧ������֪��
x
0
x_0
x0?,���轫
x
0
x_0
x0?��
x
t
x_t
xt?����,����2.4�õ�:
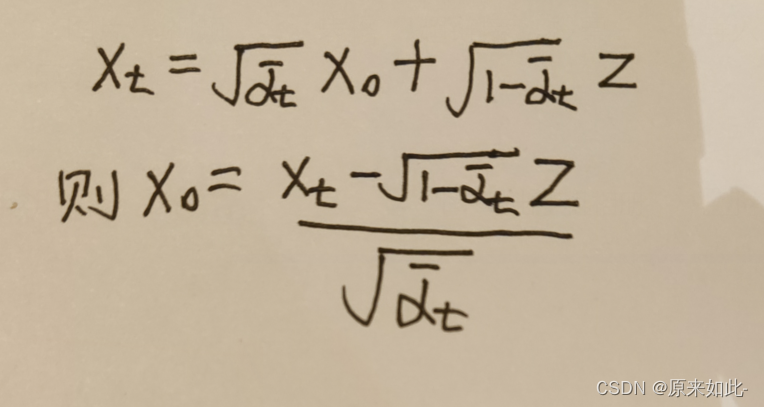
�����ֵ��ʽ��,�����õ�����������ֵ:
u
��
t
=
1
��
t
(
x
t
?
��
t
1
?
��
t
��
z
t
)
\bar{u}_t=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha_t}}}z_t)
u��t?=��t??1?(xt??1?��t?��??��t??zt?)
�ġ��Ż�Ŀ��
4.1 ��ʧ������ʽ�Ƶ�
�õ���ʧ��������:
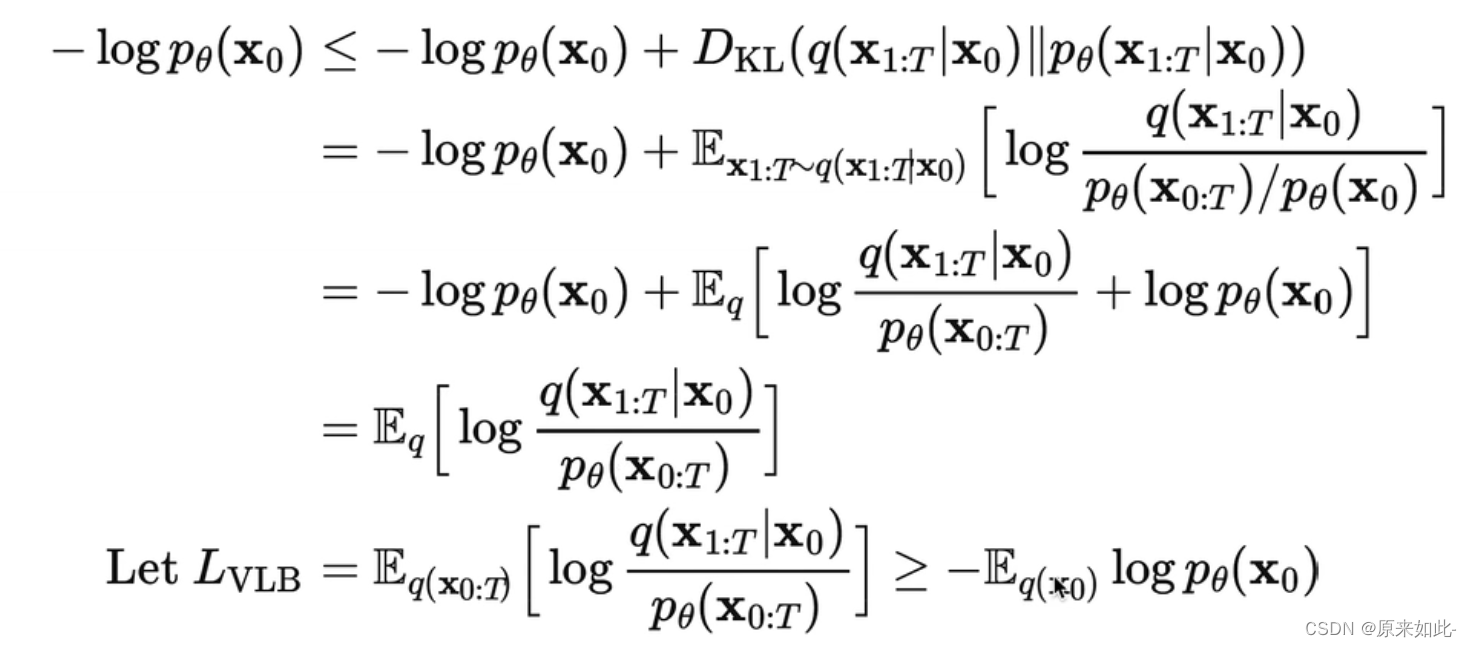


4.2 ��ʧ��������ʵ��
def diffusion_loss_fn(model, x_0, alphas_bar_sqrt, one_minus_alphas_bar_sqrt, n_steps):
batch_size = x_0.shape[0]
# ����ʱ�����ֵ,��С��(batch_size//2)
t = torch.randint(0, n_steps, size=(batch_size//2,))
t = torch.cat([t, num_steps-1-t], dim=0)
t = t.unsqueeze(-1) # t.shapeΪ(batch_size, 1)
a = alphas_bar_sqrt[t].to(device)
aml = one_minus_alphas_bar_sqrt[t].to(device)
e = torch.randn_like(x_0).to(device)
x = x_0 * a + e * aml
output = model(x, t.squeeze(-1).to(device))
return (e - output).square().mean()
�塢�㷨����

5.1 ģ��ѵ������
print('ѵ��ģ��...')
batch_size = 128
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
num_epoch = 4000
plt.rc('text', color='blue')
model = MLPDiffusion(num_steps)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for t in range(num_epoch):
for idx, batch_x in enumerate(dataloader):
batch_x = batch_x.to(device)
loss = diffusion_loss_fn(model,batch_x,alphas_bar_sqrt,one_minus_alphas_bar_sqrt,num_steps)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.)
optimizer.step()
if(t%100==0):
print(loss)
torch.save(model, "model.h5")
5.2 ģ�Ͳ�������
def p_sample_loop(model, shape, n_steps, betas, one_minus_alphas_bar_sqrt):
cur_x = torch.randn(shape).to(device)
x_seq = [cur_x]
for i in reversed(range(n_steps)):
cur_x = p_sample(model, cur_x, i, betas.to(device), one_minus_alphas_bar_sqrt.to(device))
x_seq.append(cur_x)
return x_seq
def p_sample(model, x, t, betas, one_minus_alphas_bar_sqrt):
t = torch.tensor([t]).to(device)
coeff = betas[t]/one_minus_alphas_bar_sqrt[t]
eps_theta = model(x, t)
# �����ֵ
mean = (1 / (1-betas[t]).sqrt())*(x - (coeff*eps_theta))
z = torch.randn_like(x).to(device)
# �������
sigma_t = betas[t].sqrt().to(device)
sample = mean + sigma_t * z
return (sample)
model = torch.load("model.h5")
x_seq = p_sample_loop(model, dataset.shape, num_steps, betas, one_minus_alphas_bar_sqrt)
fig, axs = plt.subplots(1, 10, figsize=(28, 3))
for i in range(1, 11):
cur_x = x_seq[i*10].detach()
axs[i-1].scatter(cur_x[:, 0].cpu(), cur_x[:, 1].cpu(), color='red', edgecolor='white');
axs[i-1].set_axis_off();
axs[i-1].set_title('$q(\mathbf{x}_{'+str(i*10)+'})$')
5.3 ѵ���õ�ģ��Ч��
