ǰ��
����CVС��ѡ�ֻ�ȡScanNet���ݼ����������,��������ȡ�ɹ���!���ォ�������ȡ���ݼ�����ϸ���̼�¼һ��,ϣ���ܹ�������������,һ��ѧϰ����!(o( ̄�� ̄)��)
1.���ݼ�����
ScanNet��һ��RGB-D��Ƶ���ݼ�,��������1500��ɨ���250�����ͼ,ʹ��3D������ơ������ؽ���ʵ��������ָ����ע�͡�
����:https://github.com/ScanNet/ScanNet
2.���ݼ���ȡ
�������ݼ�,���뷽ʽ:ScanNet Terms of Use to scannet@googlegroups.com
����֮��������ݴ��롣����Ϊ���ܹ���ʡ��ҵ�����ʱ��,���Ծͽ�������������
download_scannet.py
#!/usr/bin/env python
# Downloads ScanNet public data release
# Run with ./download-scannet.py (or python download-scannet.py on Windows)
# -*- coding: utf-8 -*-
import argparse
import os
# import urllib.request (for python3)
import urllib
import tempfile
BASE_URL = 'http://kaldir.vc.in.tum.de/scannet/'
TOS_URL = BASE_URL + 'ScanNet_TOS.pdf'
FILETYPES = ['.aggregation.json', '.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.0.010000.segs.json', '_vh_clean_2.ply', '_vh_clean.segs.json', '_vh_clean.aggregation.json', '_vh_clean_2.labels.ply', '_2d-instance.zip', '_2d-instance-filt.zip', '_2d-label.zip', '_2d-label-filt.zip']
FILETYPES_TEST = ['.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.ply']
PREPROCESSED_FRAMES_FILE = ['scannet_frames_25k.zip', '5.6GB']
TEST_FRAMES_FILE = ['scannet_frames_test.zip', '610MB']
LABEL_MAP_FILES = ['scannetv2-labels.combined.tsv', 'scannet-labels.combined.tsv']
RELEASES = ['v2/scans', 'v1/scans']
RELEASES_TASKS = ['v2/tasks', 'v1/tasks']
RELEASES_NAMES = ['v2', 'v1']
RELEASE = RELEASES[0]
RELEASE_TASKS = RELEASES_TASKS[0]
RELEASE_NAME = RELEASES_NAMES[0]
LABEL_MAP_FILE = LABEL_MAP_FILES[0]
RELEASE_SIZE = '1.2TB'
V1_IDX = 1
def get_release_scans(release_file):
#scan_lines = urllib.request.urlopen(release_file)
scan_lines = urllib.urlopen(release_file)
scans = []
for scan_line in scan_lines:
scan_id = scan_line.decode('utf8').rstrip('\n')
scans.append(scan_id)
return scans
def download_release(release_scans, out_dir, file_types, use_v1_sens):
if len(release_scans) == 0:
return
print('Downloading ScanNet ' + RELEASE_NAME + ' release to ' + out_dir + '...')
for scan_id in release_scans:
scan_out_dir = os.path.join(out_dir, scan_id)
download_scan(scan_id, scan_out_dir, file_types, use_v1_sens)
print('Downloaded ScanNet ' + RELEASE_NAME + ' release.')
def download_file(url, out_file):
out_dir = os.path.dirname(out_file)
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
if not os.path.isfile(out_file):
print('\t' + url + ' > ' + out_file)
fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)
f = os.fdopen(fh, 'w')
f.close()
#urllib.request.urlretrieve(url, out_file_tmp)
urllib.urlretrieve(url, out_file_tmp)
os.rename(out_file_tmp, out_file)
else:
print('WARNING: skipping download of existing file ' + out_file)
def download_scan(scan_id, out_dir, file_types, use_v1_sens):
print('Downloading ScanNet ' + RELEASE_NAME + ' scan ' + scan_id + ' ...')
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
for ft in file_types:
v1_sens = use_v1_sens and ft == '.sens'
url = BASE_URL + RELEASE + '/' + scan_id + '/' + scan_id + ft if not v1_sens else BASE_URL + RELEASES[V1_IDX] + '/' + scan_id + '/' + scan_id + ft
out_file = out_dir + '/' + scan_id + ft
download_file(url, out_file)
print('Downloaded scan ' + scan_id)
def download_task_data(out_dir):
print('Downloading ScanNet v1 task data...')
files = [
LABEL_MAP_FILES[V1_IDX], 'obj_classification/data.zip',
'obj_classification/trained_models.zip', 'voxel_labeling/data.zip',
'voxel_labeling/trained_models.zip'
]
for file in files:
url = BASE_URL + RELEASES_TASKS[V1_IDX] + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded task data.')
def download_label_map(out_dir):
print('Downloading ScanNet ' + RELEASE_NAME + ' label mapping file...')
files = [ LABEL_MAP_FILE ]
for file in files:
url = BASE_URL + RELEASE_TASKS + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded ScanNet ' + RELEASE_NAME + ' label mapping file.')
def main():
parser = argparse.ArgumentParser(description='Downloads ScanNet public data release.')
parser.add_argument('-o', '--out_dir', required=True, help='directory in which to download')
parser.add_argument('--task_data', action='store_true', help='download task data (v1)')
parser.add_argument('--label_map', action='store_true', help='download label map file')
parser.add_argument('--v1', action='store_true', help='download ScanNet v1 instead of v2')
parser.add_argument('--id', help='specific scan id to download')
parser.add_argument('--preprocessed_frames', action='store_true', help='download preprocessed subset of ScanNet frames (' + PREPROCESSED_FRAMES_FILE[1] + ')')
parser.add_argument('--test_frames_2d', action='store_true', help='download 2D test frames (' + TEST_FRAMES_FILE[1] + '; also included with whole dataset download)')
parser.add_argument('--type', help='specific file type to download (.aggregation.json, .sens, .txt, _vh_clean.ply, _vh_clean_2.0.010000.segs.json, _vh_clean_2.ply, _vh_clean.segs.json, _vh_clean.aggregation.json, _vh_clean_2.labels.ply, _2d-instance.zip, _2d-instance-filt.zip, _2d-label.zip, _2d-label-filt.zip)')
args = parser.parse_args()
print('By pressing any key to continue you confirm that you have agreed to the ScanNet terms of use as described at:')
print(TOS_URL)
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = raw_input('')
if args.v1:
global RELEASE
global RELEASE_TASKS
global RELEASE_NAME
global LABEL_MAP_FILE
RELEASE = RELEASES[V1_IDX]
RELEASE_TASKS = RELEASES_TASKS[V1_IDX]
RELEASE_NAME = RELEASES_NAMES[V1_IDX]
LABEL_MAP_FILE = LABEL_MAP_FILES[V1_IDX]
release_file = BASE_URL + RELEASE + '.txt'
release_scans = get_release_scans(release_file)
file_types = FILETYPES;
release_test_file = BASE_URL + RELEASE + '_test.txt'
release_test_scans = get_release_scans(release_test_file)
file_types_test = FILETYPES_TEST;
out_dir_scans = os.path.join(args.out_dir, 'scans')
out_dir_test_scans = os.path.join(args.out_dir, 'scans_test')
out_dir_tasks = os.path.join(args.out_dir, 'tasks')
if args.type: # download file type
file_type = args.type
if file_type not in FILETYPES:
print('ERROR: Invalid file type: ' + file_type)
return
file_types = [file_type]
if file_type in FILETYPES_TEST:
file_types_test = [file_type]
else:
file_types_test = []
if args.task_data: # download task data
download_task_data(out_dir_tasks)
elif args.label_map: # download label map file
download_label_map(args.out_dir)
elif args.preprocessed_frames: # download preprocessed scannet_frames_25k.zip file
if args.v1:
print('ERROR: Preprocessed frames only available for ScanNet v2')
print('You are downloading the preprocessed subset of frames ' + PREPROCESSED_FRAMES_FILE[0] + ' which requires ' + PREPROCESSED_FRAMES_FILE[1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, PREPROCESSED_FRAMES_FILE[0]), os.path.join(out_dir_tasks, PREPROCESSED_FRAMES_FILE[0]))
elif args.test_frames_2d: # download test scannet_frames_test.zip file
if args.v1:
print('ERROR: 2D test frames only available for ScanNet v2')
print('You are downloading the 2D test set ' + TEST_FRAMES_FILE[0] + ' which requires ' + TEST_FRAMES_FILE[1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]), os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
elif args.id: # download single scan
scan_id = args.id
is_test_scan = scan_id in release_test_scans
if scan_id not in release_scans and (not is_test_scan or args.v1):
print('ERROR: Invalid scan id: ' + scan_id)
else:
out_dir = os.path.join(out_dir_scans, scan_id) if not is_test_scan else os.path.join(out_dir_test_scans, scan_id)
scan_file_types = file_types if not is_test_scan else file_types_test
use_v1_sens = not is_test_scan
if not is_test_scan and not args.v1 and '.sens' in scan_file_types:
print('Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = raw_input('')
if key.strip().lower() == 'n':
scan_file_types.remove('.sens')
download_scan(scan_id, out_dir, scan_file_types, use_v1_sens)
else: # download entire release
if len(file_types) == len(FILETYPES):
print('WARNING: You are downloading the entire ScanNet ' + RELEASE_NAME + ' release which requires ' + RELEASE_SIZE + ' of space.')
else:
print('WARNING: You are downloading all ScanNet ' + RELEASE_NAME + ' scans of type ' + file_types[0])
print('Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.')
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = raw_input('')
if not args.v1 and '.sens' in file_types:
print('Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = raw_input('')
if key.strip().lower() == 'n':
file_types.remove('.sens')
download_release(release_scans, out_dir_scans, file_types, use_v1_sens=True)
if not args.v1:
download_label_map(args.out_dir)
download_release(release_test_scans, out_dir_test_scans, file_types_test, use_v1_sens=False)
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]), os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
if __name__ == "__main__": main()
download_scannetv2.py
#coding:utf-8
#!/usr/bin/env python
# Downloads ScanNet public data release
# Run with ./download-scannet.py (or python download-scannet.py on Windows)
# -*- coding: utf-8 -*-
import argparse
import os
import urllib.request #(for python3)
# import urllib
import tempfile
BASE_URL = 'http://kaldir.vc.in.tum.de/scannet/'
TOS_URL = BASE_URL + 'ScanNet_TOS.pdf'
FILETYPES = ['.sens', '.txt',
'_vh_clean.ply', '_vh_clean_2.ply',
'_vh_clean.segs.json', '_vh_clean_2.0.010000.segs.json',
'.aggregation.json', '_vh_clean.aggregation.json',
'_vh_clean_2.labels.ply',
'_2d-instance.zip', '_2d-instance-filt.zip',
'_2d-label.zip', '_2d-label-filt.zip']
FILETYPES_TEST = ['.sens', '.txt', '_vh_clean.ply', '_vh_clean_2.ply']
PREPROCESSED_FRAMES_FILE = ['scannet_frames_25k.zip', '5.6GB']
TEST_FRAMES_FILE = ['scannet_frames_test.zip', '610MB']
LABEL_MAP_FILES = ['scannetv2-labels.combined.tsv', 'scannet-labels.combined.tsv']
RELEASES = ['v2/scans', 'v1/scans']
RELEASES_TASKS = ['v2/tasks', 'v1/tasks']
RELEASES_NAMES = ['v2', 'v1']
RELEASE = RELEASES[0]
RELEASE_TASKS = RELEASES_TASKS[0]
RELEASE_NAME = RELEASES_NAMES[0]
LABEL_MAP_FILE = LABEL_MAP_FILES[0]
RELEASE_SIZE = '1.2TB'
V1_IDX = 1
def get_release_scans(release_file):
scan_lines = urllib.request.urlopen(release_file)
# scan_lines = urllib.urlopen(release_file)
scans = []
for scan_line in scan_lines:
scan_id = scan_line.decode('utf8').rstrip('\n')
scans.append(scan_id)
return scans
def download_release(release_scans, out_dir, file_types, use_v1_sens):
if len(release_scans) == 0:
return
print('Downloading ScanNet ' + RELEASE_NAME + ' release to ' + out_dir + '...')
for scan_id in release_scans:
scan_out_dir = os.path.join(out_dir, scan_id)
download_scan(scan_id, scan_out_dir, file_types, use_v1_sens)
print('Downloaded ScanNet ' + RELEASE_NAME + ' release.')
def download_file(url, out_file):
out_dir = os.path.dirname(out_file)
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
if not os.path.isfile(out_file):
print('\t' + url + ' > ' + out_file)
fh, out_file_tmp = tempfile.mkstemp(dir=out_dir)
f = os.fdopen(fh, 'w')
f.close()
urllib.request.urlretrieve(url, out_file_tmp)
# urllib.urlretrieve(url, out_file_tmp)
os.rename(out_file_tmp, out_file)
else:
print('WARNING: skipping download of existing file ' + out_file)
def download_scan(scan_id, out_dir, file_types, use_v1_sens):
print('Downloading ScanNet ' + RELEASE_NAME + ' scan ' + scan_id + ' ...')
if not os.path.isdir(out_dir):
os.makedirs(out_dir)
for ft in file_types:
v1_sens = use_v1_sens and ft == '.sens'
url = BASE_URL + RELEASE + '/' + scan_id + '/' + scan_id + ft if not v1_sens else BASE_URL + RELEASES[
V1_IDX] + '/' + scan_id + '/' + scan_id + ft
out_file = out_dir + '/' + scan_id + ft
download_file(url, out_file)
print('Downloaded scan ' + scan_id)
def download_task_data(out_dir):
print('Downloading ScanNet v1 task data...')
files = [
LABEL_MAP_FILES[V1_IDX], 'obj_classification/data.zip',
'obj_classification/trained_models.zip', 'voxel_labeling/data.zip',
'voxel_labeling/trained_models.zip'
]
for file in files:
url = BASE_URL + RELEASES_TASKS[V1_IDX] + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded task data.')
def download_label_map(out_dir):
print('Downloading ScanNet ' + RELEASE_NAME + ' label mapping file...')
files = [LABEL_MAP_FILE]
for file in files:
url = BASE_URL + RELEASE_TASKS + '/' + file
localpath = os.path.join(out_dir, file)
localdir = os.path.dirname(localpath)
if not os.path.isdir(localdir):
os.makedirs(localdir)
download_file(url, localpath)
print('Downloaded ScanNet ' + RELEASE_NAME + ' label mapping file.')
def main():
parser = argparse.ArgumentParser(description='Downloads ScanNet public data release.')
parser.add_argument('-o', '--out_dir', required=True, help='directory in which to download')
parser.add_argument('--task_data', action='store_true', help='download task data (v1)')
parser.add_argument('--label_map', action='store_true', help='download label map file')
parser.add_argument('--v1', action='store_true', help='download ScanNet v1 instead of v2')
parser.add_argument('--id', help='specific scan id to download')
parser.add_argument('--preprocessed_frames', action='store_true',
help='download preprocessed subset of ScanNet frames (' + PREPROCESSED_FRAMES_FILE[1] + ')')
parser.add_argument('--test_frames_2d', action='store_true', help='download 2D test frames (' + TEST_FRAMES_FILE[
1] + '; also included with whole dataset download)')
parser.add_argument('--type',
help='specific file type to download (.aggregation.json, .sens, .txt, _vh_clean.ply, _vh_clean_2.0.010000.segs.json, _vh_clean_2.ply, _vh_clean.segs.json, _vh_clean.aggregation.json, _vh_clean_2.labels.ply, _2d-instance.zip, _2d-instance-filt.zip, _2d-label.zip, _2d-label-filt.zip)')
args = parser.parse_args()
print(
'By pressing any key to continue you confirm that you have agreed to the ScanNet terms of use as described at:')
print(TOS_URL)
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = input('')
if args.v1:
global RELEASE
global RELEASE_TASKS
global RELEASE_NAME
global LABEL_MAP_FILE
RELEASE = RELEASES[V1_IDX]
RELEASE_TASKS = RELEASES_TASKS[V1_IDX]
RELEASE_NAME = RELEASES_NAMES[V1_IDX]
LABEL_MAP_FILE = LABEL_MAP_FILES[V1_IDX]
release_file = BASE_URL + RELEASE + '.txt' # ��ų���ID���ļ�
release_scans = get_release_scans(release_file) # �������ID
file_types = FILETYPES; # �����ļ��ĺ���
release_test_file = BASE_URL + RELEASE + '_test.txt' # ��Ų��Գ���ID���ļ�
release_test_scans = get_release_scans(release_test_file) # ���Գ�����ID
file_types_test = FILETYPES_TEST; # ��������ļ��ĺ���
out_dir_scans = os.path.join(args.out_dir, 'scans') # �����ļ������ļ���
out_dir_test_scans = os.path.join(args.out_dir, 'scans_test') # �����ļ������ļ���
out_dir_tasks = os.path.join(args.out_dir, 'tasks') # �����ļ������ļ���
# ָ�����ص��ļ�����
if args.type: # download file type
file_type = args.type
if file_type not in FILETYPES:
print('ERROR: Invalid file type: ' + file_type)
return
file_types = [file_type]
if file_type in FILETYPES_TEST:
file_types_test = [file_type]
else:
file_types_test = []
if args.task_data: # download task data
download_task_data(out_dir_tasks)
elif args.label_map: # download label map file
download_label_map(args.out_dir)
elif args.preprocessed_frames: # download preprocessed scannet_frames_25k.zip file
if args.v1:
print('ERROR: Preprocessed frames only available for ScanNet v2')
print('You are downloading the preprocessed subset of frames ' + PREPROCESSED_FRAMES_FILE[
0] + ' which requires ' + PREPROCESSED_FRAMES_FILE[1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, PREPROCESSED_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, PREPROCESSED_FRAMES_FILE[0]))
elif args.test_frames_2d: # download test scannet_frames_test.zip file
if args.v1:
print('ERROR: 2D test frames only available for ScanNet v2')
print('You are downloading the 2D test set ' + TEST_FRAMES_FILE[0] + ' which requires ' + TEST_FRAMES_FILE[
1] + ' of space.')
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
elif args.id: # download single scan
scan_id = args.id
is_test_scan = scan_id in release_test_scans
if scan_id not in release_scans and (not is_test_scan or args.v1):
print('ERROR: Invalid scan id: ' + scan_id)
else:
out_dir = os.path.join(out_dir_scans, scan_id) if not is_test_scan else os.path.join(out_dir_test_scans,
scan_id)
scan_file_types = file_types if not is_test_scan else file_types_test
use_v1_sens = not is_test_scan
if not is_test_scan and not args.v1 and '.sens' in scan_file_types:
print(
'Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = input('')
if key.strip().lower() == 'n':
scan_file_types.remove('.sens')
download_scan(scan_id, out_dir, scan_file_types, use_v1_sens)
else: # download entire release
if len(file_types) == len(FILETYPES):
print(
'WARNING: You are downloading the entire ScanNet ' + RELEASE_NAME + ' release which requires ' + RELEASE_SIZE + ' of space.')
else:
print('WARNING: You are downloading all ScanNet ' + RELEASE_NAME + ' scans of type ' + file_types[0])
print(
'Note that existing scan directories will be skipped. Delete partially downloaded directories to re-download.')
print('***')
print('Press any key to continue, or CTRL-C to exit.')
key = input('')
if not args.v1 and '.sens' in file_types:
print(
'Note: ScanNet v2 uses the same .sens files as ScanNet v1: Press \'n\' to exclude downloading .sens files for each scan')
key = input('')
if key.strip().lower() == 'n':
file_types.remove('.sens')
download_release(release_scans, out_dir_scans, file_types, use_v1_sens=True)
if not args.v1:
download_label_map(args.out_dir)
download_release(release_test_scans, out_dir_test_scans, file_types_test, use_v1_sens=False)
download_file(os.path.join(BASE_URL, RELEASE_TASKS, TEST_FRAMES_FILE[0]),
os.path.join(out_dir_tasks, TEST_FRAMES_FILE[0]))
if __name__ == "__main__": main()
�������ݴ�����Ը����Լ��������ƴ��롣
��ʼ�������ݼ�
#-o �����ļ�·��
python download_scannet.py -o data
�����������ݽϴ�,����Ҳ�ṩ�˽�С�Ӽ���ѡ��scannet_frames_25k��
#����scannet_frames_25k
python download-scannet.py -o data --preprocessed_frames
���ݴ�������Լ�ʵ������ѡȡ���ء�(�����������ص���ȫ����)
ע��python������
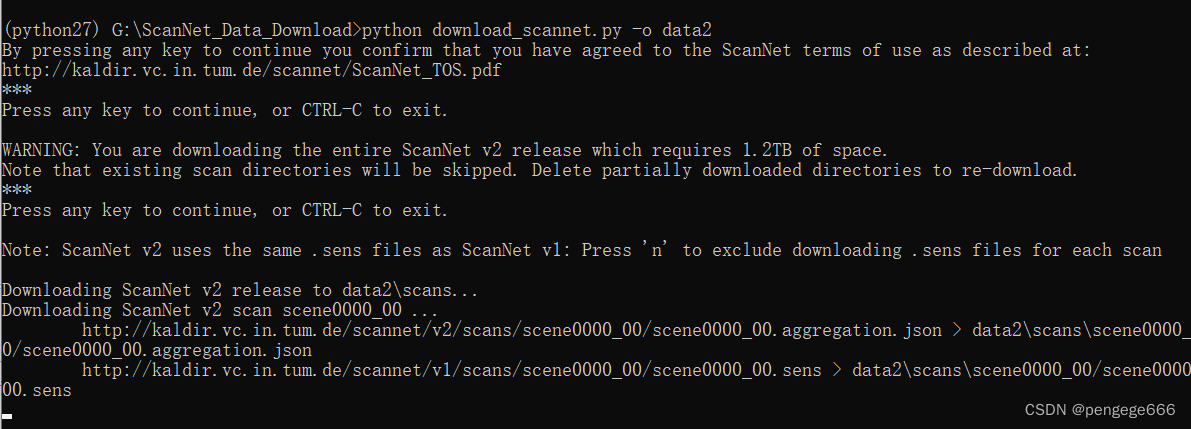
������ص��ٶȺ����Ļ�,Ҳ���Ը����·��ṩ����ַ���ƽ����������,�����Ļ��ܿ�һЩ��
3.�������ݼ�
���������������ļ���.sens��ʽ,�����Ҫ��һ���������ݡ��ٷ��ṩ�ĵ�������:https://github.com/ScanNet/ScanNet/tree/master/SensReader/python
�ļ�Ŀ¼
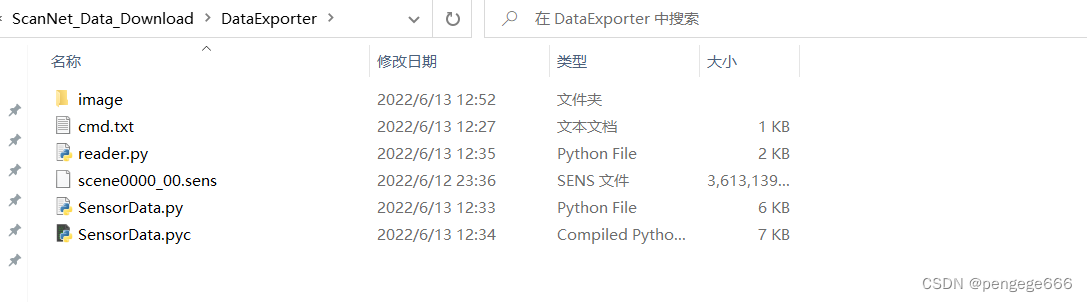
��ʼ����
python reader.py --filename scene0000_00.sens --output_path image
1.ע��:�����赼�����ļ���False����ΪTrue
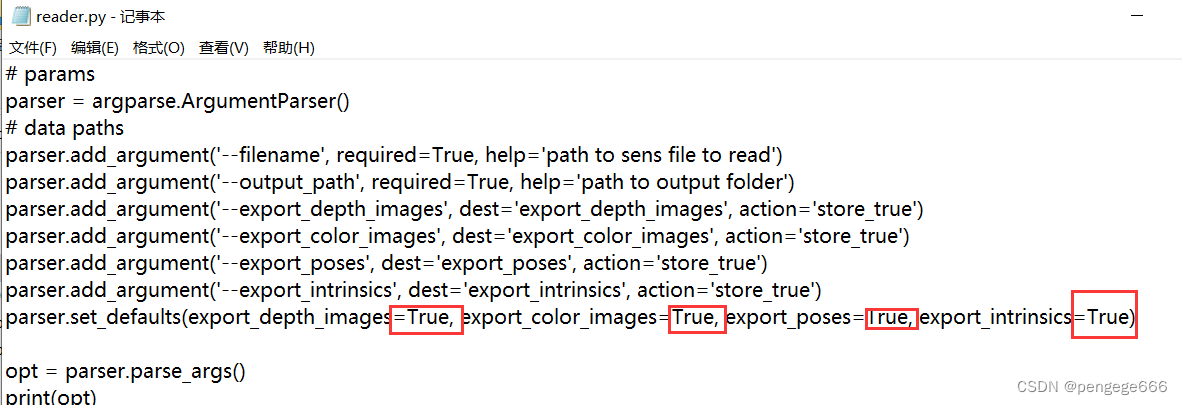
2.Ϊ�˸���ֱ�۵IJ鿴�����Ľ���,����ο�RGB-D���ݼ�:ScanNet
����SensorData.py���ִ���
from tqdm import tqdm
#����71�д���:for i in range(num_frames): Ϊ:
for i in tqdm(range(num_frames),ncols=80):
#��Ӧ��81�С�93�� Ҳ������Ӧ����Ϊ:
for f in tqdm(range(0, len(self.frames), frame_skip),ncols=80):
for f in tqdm(range(0, len(self.frames), frame_skip),ncols=80):
�������ļ�Ŀ¼
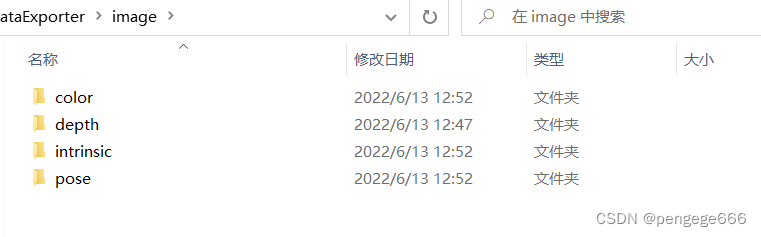
�����
RGB-D���ݼ�:ScanNet
����ScanNet���ݼ�