目录
引言:K均值算法属于无监督学习中一种,我们通过无监督学习的思路来引出K均值算法。
机器学习中有监督学习和无监督学习,什么是无监督学习?
????????无监督学习就是在不知道样本的类别标签的情况下,通过对样本集的学习,来分析样本集中的潜在联系和内部结构特征。
如何去对样本集进行无监督学习?
???????聚类
什么是聚类?
????????’物以类聚,人以群分‘,相似的放到一起,不相似的不放在一起。聚类就是通过衡量样本之间的相似度,将样本集划分为若干个不相交的子样本集,其子样本集的交集又组成了原始的样本集。其每个子样本集都称作一个簇,而这个簇具体的类别或属性则需我们来定义。
如何去衡量样本之间的相似度?
???????通常来讲,可以通过计算样本之间的距离来衡量相似度。我们知道每一个样本x,它是由若干个属性组成,即x={x1,x2,...,xn}。如果我们有两个样本,那么我们就可以通过其两者之间的属性值来计算距离,比较常用的有欧式距离,当然欧氏距离不是唯一的,也有闵可夫斯基距离。由距离的计算方法,引出了K-均值算法。
什么是K-均值?
???????K的意思是我们想要把样本集划分成的簇的个数,也就是我们想要把样本集划分成几个子集。均值的意思就是每个簇的质心更新法则是取该簇中所有点的平均值。
??该算法步骤:
(1)首先随机选取k个点作为初始质心
(2)计算样本集中每个样本点到这k个点的距离
(3)将每个样本点划分给离它最近的那个质心,此时所有的样本点都划分给了距离它最近的质心,形成了k个簇(子集)
(4)更新每个簇的质心,其更新为该簇中所有样本点的平均值
(5)依次执行第(2)、(3)步,如果所有样本点所属的簇都没有发生改变,则停止质心的更新;或者是更新迭代指定的次数之后,停止执行;如果某些样本点所属的簇发生了改变,那就继续执行第(4)步,再执行第(5)步,直到所有样本点所属的簇都没有发生改变,则停止质心的更新。
举个例子:
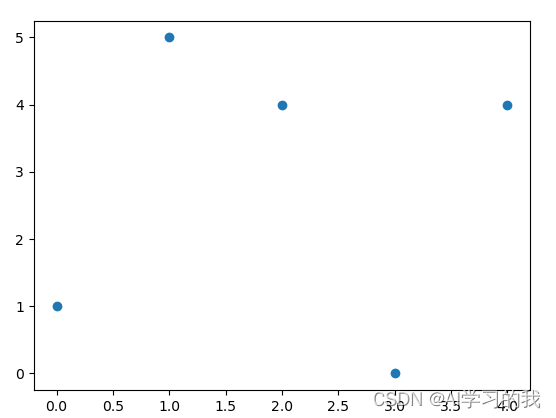
???????现在我有五个样本点,每个样本点有两个属性,x1(0, 1), x2(1, 5),x3(2, 4), x4(3, 0),x5(4, 4)。
将这五个点可视化如下图所示。
???????首先,我设置k取2,即随机选取2个点作为初始质心z1(2, 1),z2(3, 1)如下图红圈所示。
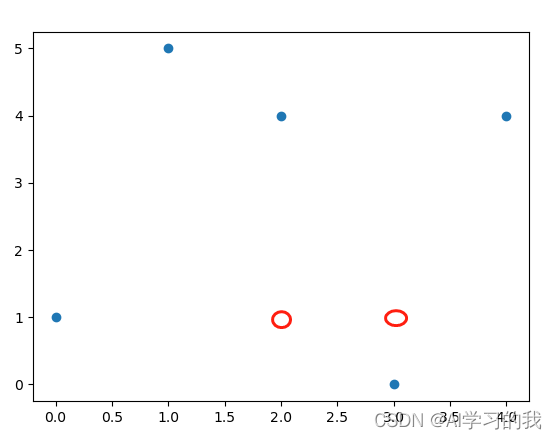
???????然后计算每一个点到这两个质心的距离,将其每个点划分给离它最近的质心,划分结果如下图所示,可自行计算验证。

????????然后更新质心,其更新规则为,新的质心为该簇所有样本点的均值。更新之后的两个质心为
z1(1, 10/3),z2(3.5, 2),如下图红圈所示。
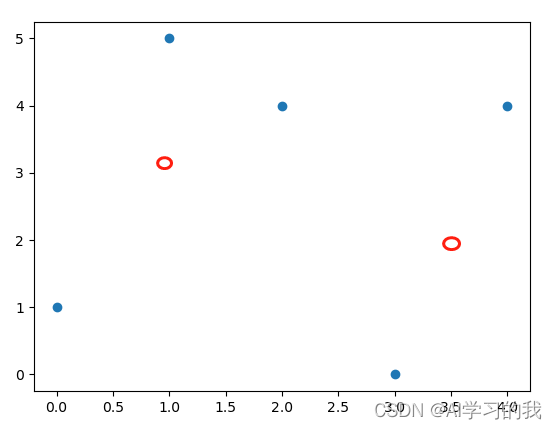
???????接着计算每一个样本点到这个两个质心的距离,将其分配给离它最近的质心,计算完之后,其每个样本点所属的簇没有发生改变,如下图所示。
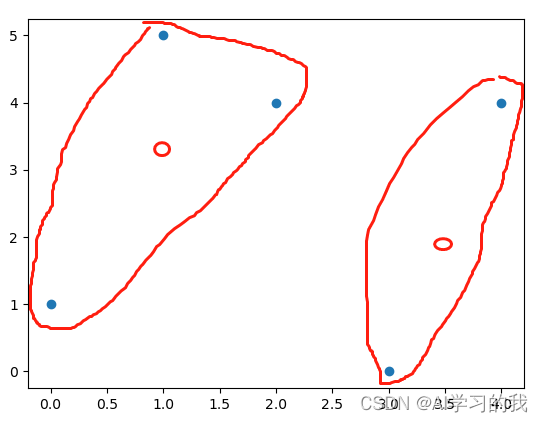
? ? ? ? 由于每个样本点所属的簇没有发生改变,所以暂停质心的更新,将每个样本点所属的簇进行标记返回结果即可。
总结:以上就是K均值算法的思想,该算法不需要训练,算法就是通过给定的样本,然后找出其中的相似度,将相似的尽可能地划分为一个簇中。运用到实际中,可能一个样本有不止两个属性,并且样本集也不止几个样本,多的有成千上万个样本,那么这是就要考虑到其计算性能,因为我们每一次都需要计算每一个样本点到所有质心的距离。还有一点需要注意的是,k的取值是我们自行设置的,那如何才能取到一个合适的k值,这就需要一个评价指标来衡量执行k均值算法之后划分数据集的质量,一般用来度量聚类质量指标的是SSE(误差平方和),即每一个样本点到它所属质心的距离的平方和,如果增加k取值,能降低SSE,那效果会更好;如果增加k取值,不能降低SSE,则无需增加K的值。当然除了这种衡量之外,还有一种叫做二分K-均值算法,它的聚类效果要好于K-均值算法。所谓二分就是每一个将一个簇一分为二,一直分到能够最大程度降低SSE的值。
?
?