开篇寄语
修炼一途,乃窃阴阳,夺造化,转涅槃,握生死,掌轮回。武之极,破苍穹,动乾坤!!
——《武动乾坤》
由魔方智能CV空间调研、整理、创作或转载,如有侵权,请联系后台作相应处理!!
目录
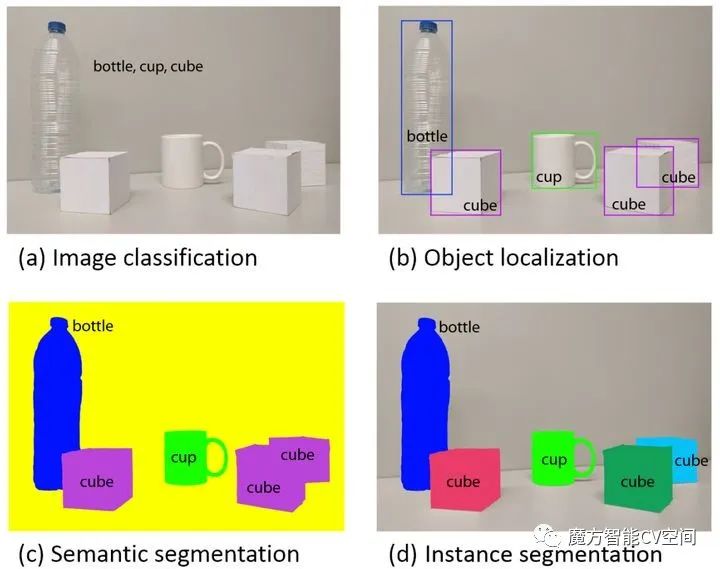
????????计算机视觉(Computer Vision,CV)是一门研究如何使机器“看”的学科,换句话说,就是用计算机实现人的视觉功能——对客观世界的三维场景的感知、识别和理解!!!计算机视觉涵盖的内容丰富,需要完成的任务也非常多,但其中最基本的任务包含四项:分类、定位、检测和分割;可以说其他关键任务都是在四项基本任务的基础上延伸开来的。
1、【分类】
????????分类-Classification:解决“是什么?”的问题,即给定一张图或一段视频,判断里面包含什么类别的目标。
????????图像分类经典网络结构:
????????在图像分类任务中,最流行的网络架构是卷积神经网络(CNN),但Transformer很可能会作为一个例外,本来在NLP领域的常用网络结构,却在近几年被广泛应用到CV领域,并且表现SOTA,大杀四方,颇有取代CNN之势。在这里先不过多介绍,在之后文章中会详细介绍Transformer的精彩战绩!
????????CNN网络结构基本是由卷积层、池化层以及全连接层组成。通过卷积层进行特征提取,之后通过池化层过滤细节(一般采用最大池化、平均池化),最后在全连接层进行特征展开,再送入到相应的分类器得到最终的分类结果。
????????2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过CNN构建的深度学习网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引了众多研究者的注意。在其之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩。同时,也是在2012这一年,以AlexNet为分界线,在之前为传统算法,之后则为深度学习算法。
????????总结图像分类任务经典的网络结构如下:
????????· LeNet-5:60k参数。一般作为广大计算机视觉从业者的Hello world入门级网络结构。当时,被成功用于ATM以对支票中的手写数字进行识别。
????????· AlexNet:60M参数,ILSVRC2012年的冠军网络。
????????· VGG-16/VGG-19:138M参数,ILSVRC2014的亚军网络。由于VGG-16网络结构十分简单,并且很适合迁移学习,因此VGG-16至今仍在各大关键任务中被广泛使用。
????????· GoogLeNet:5M参数,ILSVRC2014的冠军网络。
????????· Inception-v3/v4:在GoogLeNet的基础上进一步降低参数。
????????· ResNet:ILSVRC2015年的冠军网络。ResNet旨在解决网络加深后训练难度增大的现象。
????????· preResNet:基于ResNet的改进。
????????· ResNeXt:基于ResNet的另一种改进。
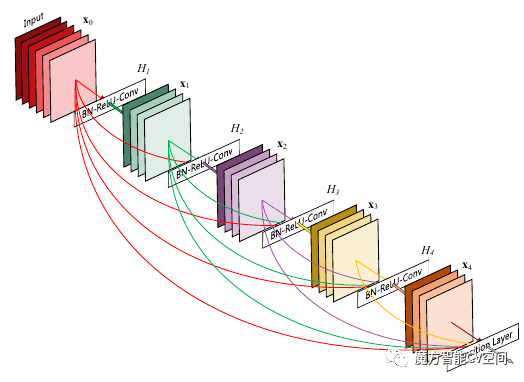
????????· DenseNet:其目的也是避免梯度消失。与残差(residual)模块不同,dense模块中任意两层之间均有短路连接。
????????· SENet:ILSVRC2017的冠军网络。
????????......
2、【定位】
????????定位-Location:解决“在哪里?”的问题,即定位出这个目标的位置。通常以包围盒(bounding box)的形式进行。

????????基本思路:多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接层+softmax层判断目标类别,与单纯图像分类区别在于这里还需要另一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出bounding box坐标。目标定位一般针对图像中只有一个或固定目标类别。
3、【检测】
????????检测-Detection:解决“是什么?在哪里?”的问题,即定位出这个目标的位置并且知道目标物是什么。
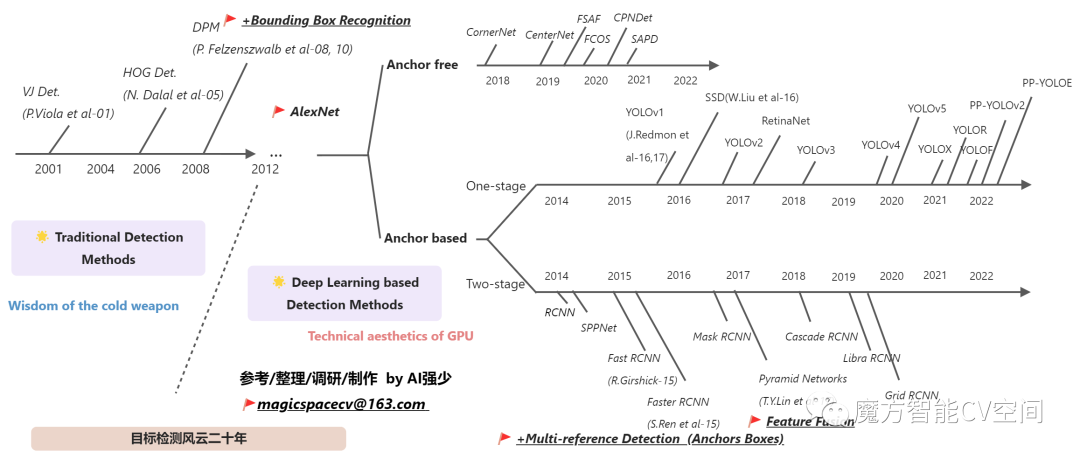
????????下面,以一张图来概括目标检测的风云二十年,在后续文章中也会展开介绍里面的经典算法:
4、【分割】
????????分割-Segmentation:解决“每一个像素属于哪个目标物或场景”的问题,分为语义分割和实例分割。
????????语义分割(semantic segmentation):是比目标检测更进阶的任务,目标检测只需要框出每个目标的bounding box,语义分割需要进一步判断图像中哪些像素属于哪个目标。
????????实例分割(instance segmentation):语义分割不需要区分相同类别目标的不同实例。例如,一张图像中有两只猫,语义分割会将两只猫整体的像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫,即目标检测+语义分割。例如经典的Mask R-CNN网络。

