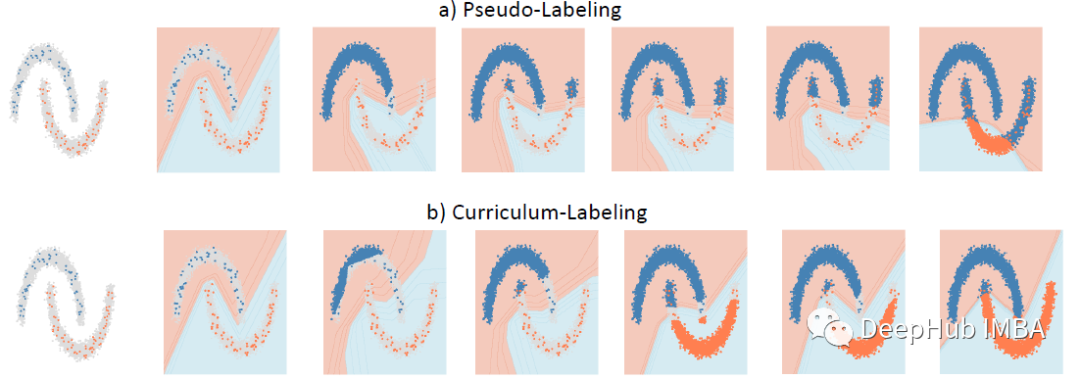
Curriculum Labeling (CL),在每个自训练周期之前重新启动模型参数,优于伪标签 (PL)
Pseudo-Labeling (PL) 通过将伪标签应用于未标记集中的样本以在自训练周期中进行模型训练。Curriculum Labeling (CL)中,应用类似课程学习的原则,通过在每个自学习周期之前重新启动模型参数来避免概念漂移。该论文发布在2021 AAAI 。
伪标签 (PL) 简要回顾
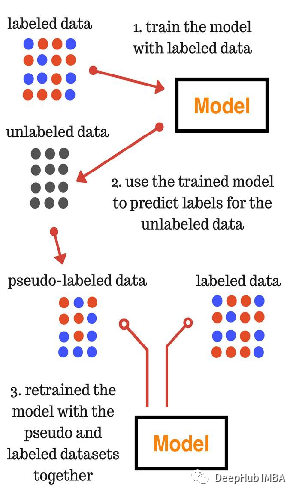
伪标签可以认为是未标记数据的目标类,就好像它们是真正的标签一样。伪标签是通过选取网络为每个未标记样本预测的最大预测概率的类来实现的。伪标签使用带有 Dropout 的微调阶段,可以将预训练的网络以有监督的方式同时使用标记和未标记的数据进行训练。
Curriculum Labeling (CL)
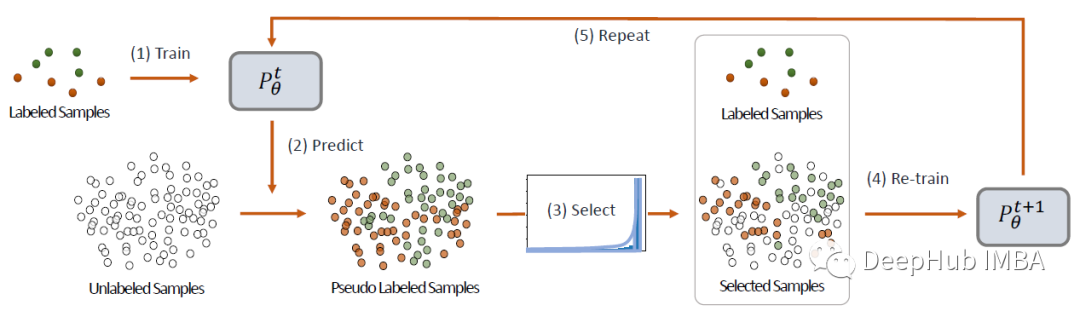
模型在标记样本上进行训练。然后该模型用于预测和分配未标记样本的伪标签。预测概率分数的分布用于选择伪标记样本的子集。使用标记和伪标记样本重新训练新模型。通过使用这个新模型重新标记未标记的样本来重复这个过程。当训练期间使用数据集中的所有样本时,该过程停止。

具体来说,百分位分数用于决定添加哪些样本。上面的算法显示了模型的完整流程,其中percentile (X, Tr)返回第r个百分位的值。r的值从0%到100%以20为单位递增。当伪标记集包含整个训练数据样本(r=100%)时,重复过程终止。
数据由N个有标记的样例(Xi, Yi)和M个无标记的样例Xj组成。设H是一组假设H θ,其中H θ∈H,其中H θ∈H表示一个映射X到Y的函数。设Lθ(Xi)表示给定例子Xi的损失。为了选择具有最低可能误差的最佳预测器,公式可以用正则化经验风险最小化(ERM)框架解释。
下面,L(θ)定义为伪标记正则化经验损失:
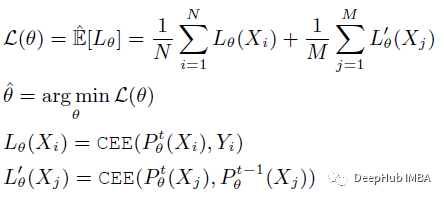
上图的cee为交叉熵 cross entropy
实验结果
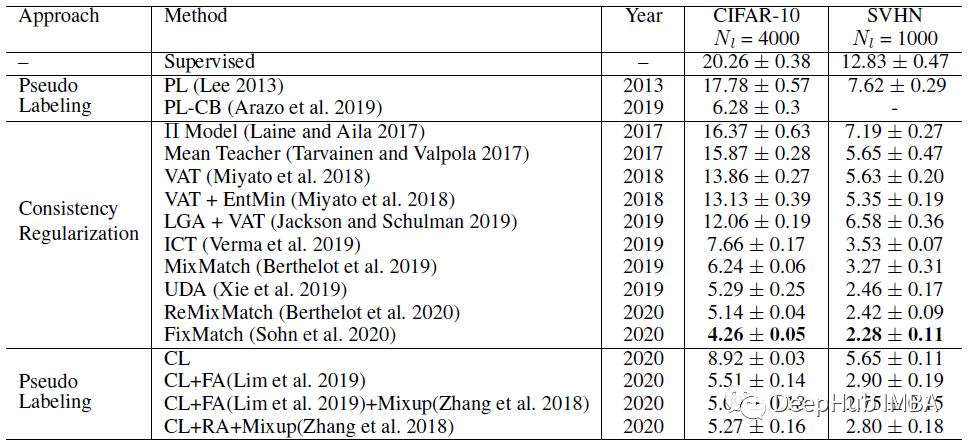
下图为基于WideResNet-28在CIFAR-10和SVHN上的测试错误率
下图为使用CNN-13在CIFAR-10和SVHN上的测试错误率
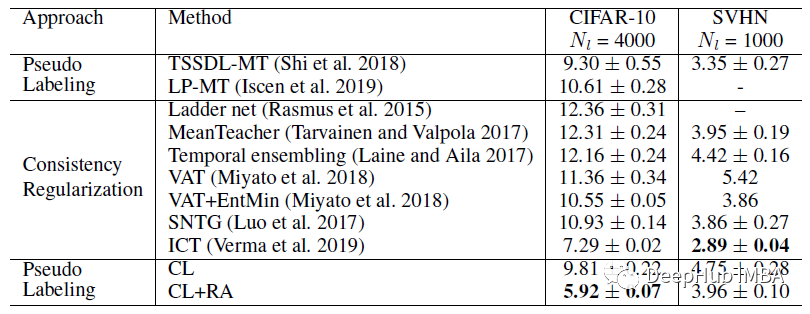
CL在CIFAR-10上出人意料地超过了之前基于伪标记的方法和一致性正则化方法。
CL的数据增强是以完全随机的方式进行的转换,称为随机增强(RA)。在SVHN上,CL方法与以前所有依赖中高度数据增强的方法相比,具有竞争性的测试误差。
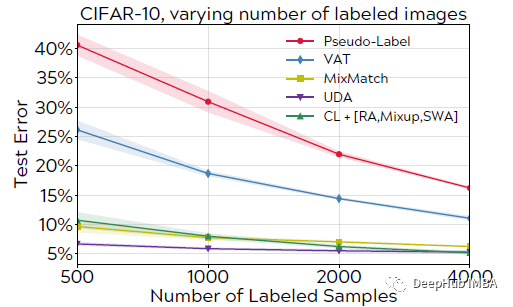
测试SSL算法的一种常见做法是,使用每个类的50、100和200个样本来改变标记数据的大小。当处理较小的标签集时CL也不会显著降低。

在ImageNet上,CL以最先进的技术取得了具有竞争力的结果,得分非常接近目前的顶级表现方法。模型为 ResNet-50,使用已标记/未标记数据的10%/90%的训练分割。
对于标记样本分布外的真实评估结果如下:
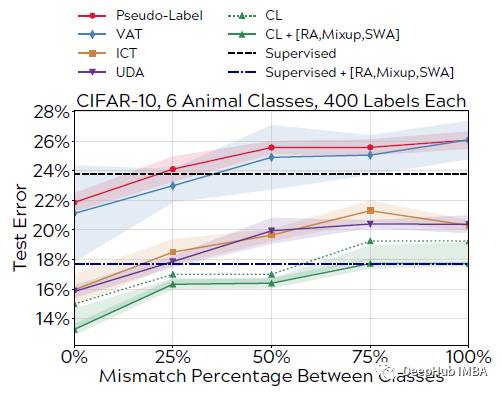
在 Oliver NeurIPS’18 更现实的 SSL 设置中,未标记数据可能与标记数据不共享同一类集。该实验是通过综合改变 CIFAR-10 上的类重叠来复制的,这里只选择动物类来执行分类(鸟、猫、鹿、狗、青蛙、马)。
CL 对分布外的类具有鲁棒性,而以前方法的性能显着下降。据推测,所提出的自定进度是CL中表现良好的关键,其中自适应阈值方案可以帮助在训练期间过滤分布外的未标记样本。
消融研究
标签的有效性
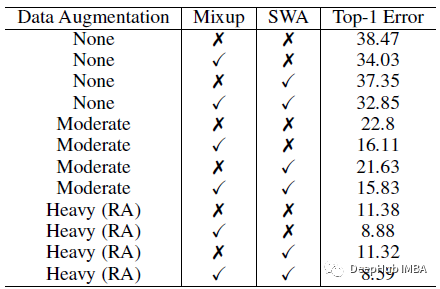
不同的数据增强,如混淆和SWA,在应用传统的伪标记时,没有进度,也没有特定的阈值(即0.0)。只有在对伪标注进行重数据增强时,该方法才能在不使用任何数据扩充的情况下匹配所提出的进度设计。
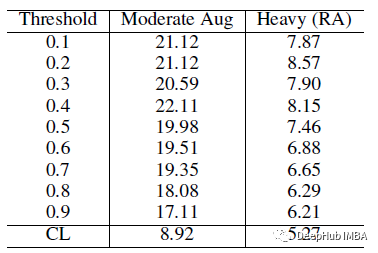
在伪标记 (PL) 中使用的固定阈值,这些阈值用于包含伪标记的未标记数据。CL能够产生比传统的伪标记方法,即使在应用重数据增强时使用固定阈值显著的收益。
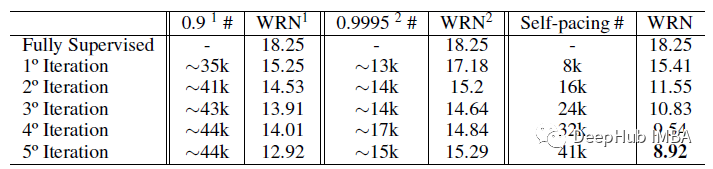
只有最有把握的样本在 CL 中被重新标记。置信阈值为 0.9 和 0.9995。使用精心挑选的阈值是次优的。
重新初始化与微调的有效性结果如下:
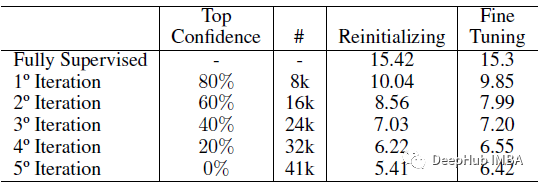
重新初始化模型会产生至少 1% 的提升,并且不会给建议的自定进度方法增加显着的开销。与微调相反,重新初始化模型确实显着提高了准确性,展示了一种替代且可能更简单的解决方案来缓解确认偏差问题。
论文地址:
https://avoid.overfit.cn/post/29b1087f7bc145f691ad8ea907717136
作者:Sik-Ho Tsang