����дĿ¼����
һ��ͼ���������
��20����70�����ʼ,�й�ͼ��������о����ѿ�ʼ,��ʱ��Ҫ�� �����ı���ͼ��������� (Text-based Image Retrieval,��� TBIR),�����ı������ķ�ʽ����ͼ�������,��滭��Ʒ�����ߡ���������ɡ��ߴ�ȡ���90����Ժ�,�����˶�ͼ�����������,��ͼ�����ɫ�����������ֵȽ��з����ͼ�����ͼ���������,�� �������ݵ�ͼ����� (Content-based Image Retrieval,��� CBIR)������
��˰�����ͼ�����ݷ�ʽ�IJ�ͬ���Է�Ϊ����:
�����ı���ͼ�����(TBIR, Text Based Image Retrieval)
�������ݵ�ͼ�����(CBIR, Content Based Image Retrieval)
�����ı���ͼ�����(TBIR)
�����ı���ͼ���������ʼ��������70���,�������ı���ע�ķ�ʽ��ͼ���е����ݽ�������,�Ӷ�Ϊÿ��ͼ���γ��������ͼ�����ݵĹؼ���,����ͼ���е����塢������,���ַ�ʽ�������˹���ע��ʽ,Ҳ����ͨ��ͼ��ʶ�������а��Զ���ע���ڽ��м���ʱ,�û����Ը����Լ�����Ȥ�ṩ��ѯ�ؼ���,����ϵͳ�����û��ṩ�IJ�ѯ�ؼ����ҳ���Щ��ע�иò�ѯ�ؼ��ֶ�Ӧ��ͼƬ,���ѯ�Ľ�����ظ��û���
���ֻ����ı�������ͼ�������ʽ��������ʵ��,���ڱ�עʱ���˹�����,���������Ҳ��Խϸߡ��������ֻ����ı������ķ�ʽ��������ȱ��Ҳ�Ƿdz����Ե�:
���ֻ����ı������ķ�ʽ��Ҫ�˹������ע����,ʹ����ֻ������С��ģ��ͼ������,�ڴ��ģͼ��������Ҫ�����һ������Ҫ�ķѴ��������������
������Ҫ��ȷ�IJ�ѯ,�û���ʱ�����ü�̵Ĺؼ������������Լ�������Ҫ��ȡ��ͼ��
�˹���ע���̲��ɱ���Ļ��ܵ���ע�ߵ���֪ˮƽ������ʹ���Լ������жϵȵ�Ӱ��,��˻������������ͼƬ�IJ���
�������ݵ�ͼ�����(CBIR)
����ͼ�����ݿ�������,��Ի����ı���ͼ��������������ֵ�����,��1992���������ҿ�ѧ������ͼ�����ݿ����ϵͳ�·�չ������һ�¹�ʶ,����ʾ����ͼ����Ϣ������Ч��ʽӦ���ǻ���ͼ�����������ġ��Դ�,�������ݵ�ͼ�������������������,���ڽ�ʮ������õ���Ѹ�ٵķ�չ��
??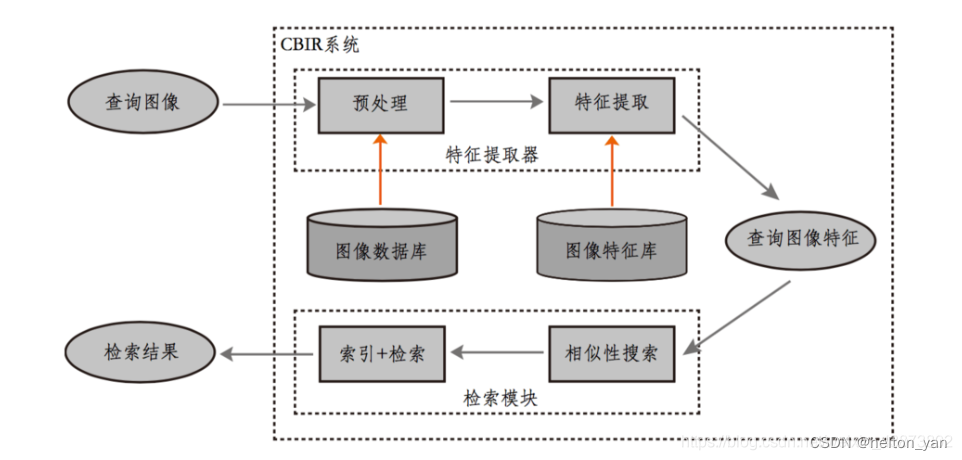
??CBIR ���ü������ͼ����з���,����ͼ������ʸ������(SIFT������ȡ )������ͼ��������,���û�����һ�Ų�ѯͼ��ʱ,����ͬ��������ȡ����(SIFT)��ȡ��ѯͼ��������õ���ѯ����,Ȼ����ij�������Զ������¼����ѯ�������������и��������������Դ�С,��������Դ�С��������˳�������Ӧ��ͼƬ��
�������ݵ�ͼ�����������ͼ�����ݵı���������Զ�����������������Զ��Ĵ���,�˷��˲����ı�����ͼ����������ٵ�ȱ��,���ҳ�ַ����˼�������ڼ��������,�������˼�����Ч��,�Ӷ�Ϊ����ͼ���ļ����������µĴ��š�
ʸ���ռ�ģ��(BOW��ʾģ�͡�Bag of Words)
ʸ���ռ�ģ�� ��һ�����ڱ�ʾ�������ı��ĵ���ģ�͡��������Ͽ���Ӧ�����κζ�������,����ͼ��������Դ����ʸ������ʾ�ı��ĵ�,��Щʸ�������ı���Ƶֱ��ͼ���ɵġ�ʸ��������ÿ�����ʳ��ֵĴ���,������������ĵط������ܶ� 0 Ԫ�ء�����������˵��ʳ��ֵ�˳��λ��,��ģ��Ҳ����Ϊ BOW ��ʾģ��(Bag of Words)��
ͨ�����ʼ����������ĵ�ֱ��ͼ���� v,�Ӷ������ĵ�������ͨ��,�ڵ��ʼ���ʱ����Ե�һЩ���ô�,�� ���⡱ ���͡� ���ǡ� ��,��Щ���ôʳ�Ϊ ͣ�ô� ������ÿƪ�ĵ����Ȳ�ͬ,�ʳ���ֱ��ͼ�ܺͽ�������һ���ɵ�λ���ȡ�����ֱ��ͼ�����е�ÿ��Ԫ��,һ�����ÿ�����ʵ���Ҫ����������Ӧ��Ȩ�ء�ͨ��,���ݼ�(�����Ͽ�)��һ�����ʵ���Ҫ���������ĵ��г��ֵĴ���������,�����������Ͽ��г��ֵĴ����ɷ��ȡ�
��õ�Ȩ���� tf-idf (term frequency-inverse document frequency,��Ƶ-�����ĵ�Ƶ��),���� w ���ĵ� d �еĴ�Ƶ��:
t
f
w
,
d
=
n
w
��
j
n
j
t f_{w, d}=\frac{n_{w}}{\sum_{j} n_{j}}
tfw,d?=��j?nj?nw??
nw�ǵ��� w ���ĵ� d �еij��ֵĴ�����Ϊ�˹�һ��,��n_w���������ĵ��е��ʵ�����
�����ĵ�Ƶ��Ϊ:
i
d
f
w
,
d
=
log
?
�O
(
D
)
�O
�O
{
d
:
w
��
d
}
�O
i d f_{w, d}=\log \frac{|(D)|}{|\{d: w \in d\}|}
idfw,d?=log�O{d:w��d}�O�O(D)�O?
�OD�O�������Ͽ� D DD ���ĵ�����Ŀ,��ĸ�����Ͽ��а������� w ���ĵ��� d ����������˿��Եõ�ʸ�� v �ж�ӦԪ�ص� tf-idfȨ��
�Ӿ�����
Ϊ�˽��ı��ھ���Ӧ�õ�ͼ����,����������Ҫ�����Ӿ���Ч����,ͨ������SIFT�ֲ������Ӽ���������˼���ǽ������ӿռ�������һЩ����ʵ��,����ͼ���е�ÿ��������ָ�ɵ����е�ij��ʵ���С���Щ����ʵ������ͨ������ѵ��ͼ��ȷ��,������Ϊ�Ӿ����ʡ�������Щ�Ӿ����ʹ��ɵļ��ϳ�Ϊ �Ӿ��ʻ� ,��ʱҲ��Ϊ �Ӿ��뱾 �����ڸ��������⡢ͼ������,����ͨ������½���Ҫ�����Ӿ�����,���Դ����ض��Ĵʻ㡣
��һ��ѵ��ͼ����ȡ����������,����һЩ�����㷨���Թ������Ӿ����ʡ������㷨����õ��� KMeans�㷨���Ӿ����ʲ����߶�,ֻ���ڸ������������ӿռ��е�һ��������,�ڲ��� KMeans���о���ʱ�õ����Ӿ������Ǿ������ġ����Ӿ�����ֱ��ͼ����ʾͼ��,���ģ�ͱ��Ϊ BOW ģ�͡�
Bag of featuresԭ��
Bag of Feature ��һ��ͼ��������ȡ����,��������ı������˼·(Bag of Words),��ͼ�������ܶ���д����Եġ��ؼ��ʡ�,�γ�һ���ֵ�,��ͳ��ÿ��ͼƬ�г��ֵġ��ؼ��ʡ�����,�õ�ͼƬ����������
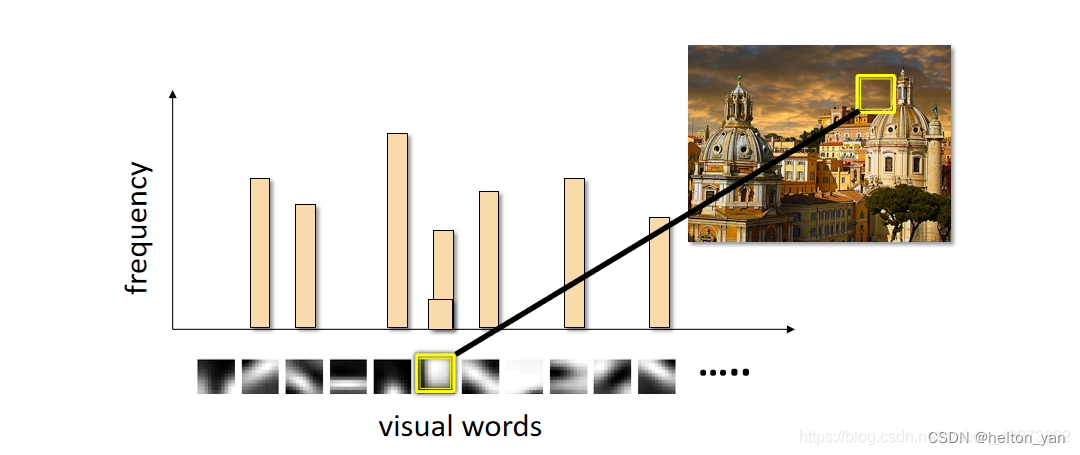
Bag of features ͼ���������
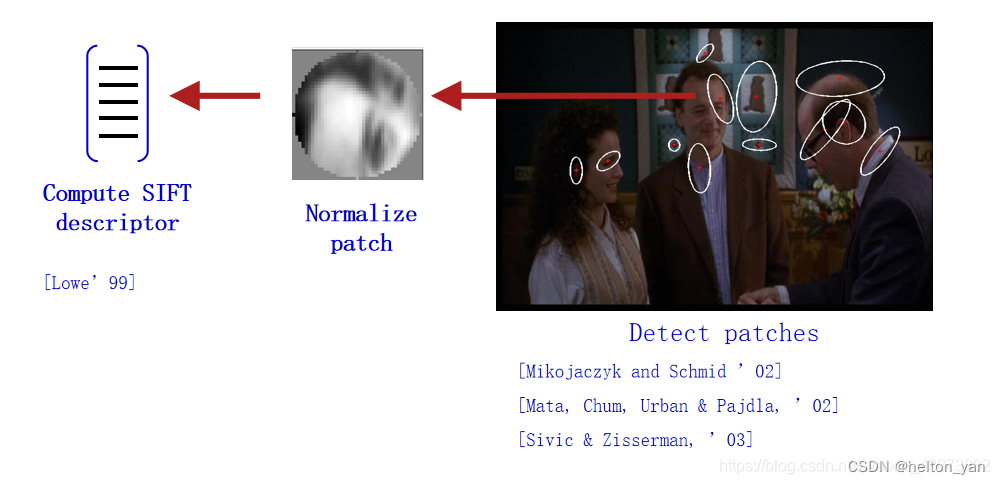
1 ������ȡ
2 ѧϰ ���Ӿ��ʵ�(visual vocabulary)��
3 �������������,�����Ӿ��ʵ��������
4 ������ͼ��ת�����Ӿ�����(visual words)��Ƶ��ֱ��ͼ
5 ����������ͼ��ĵ��ű�,ͨ�����ű������������ͼ��
6 ���������������ֱ��ͼƥ��
������ȡ
������ȡͨ��ʹ�� SIFT�ֲ������Ӽ���,����������������Ӿ�������������
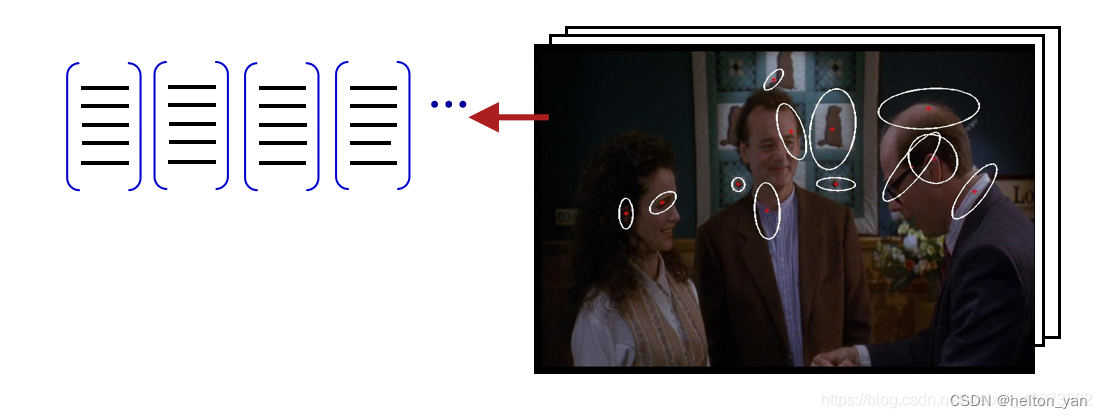
ѧϰ�����ʵ�
����ȡ��ͼ��������,��һ����ѧϰ�����ʵ�,����һЩ�����㷨���Թ������Ӿ�����,�������㷨����õ��� KMeans �㷨��KMeans �㷨���������������Ӿ�����ģ����
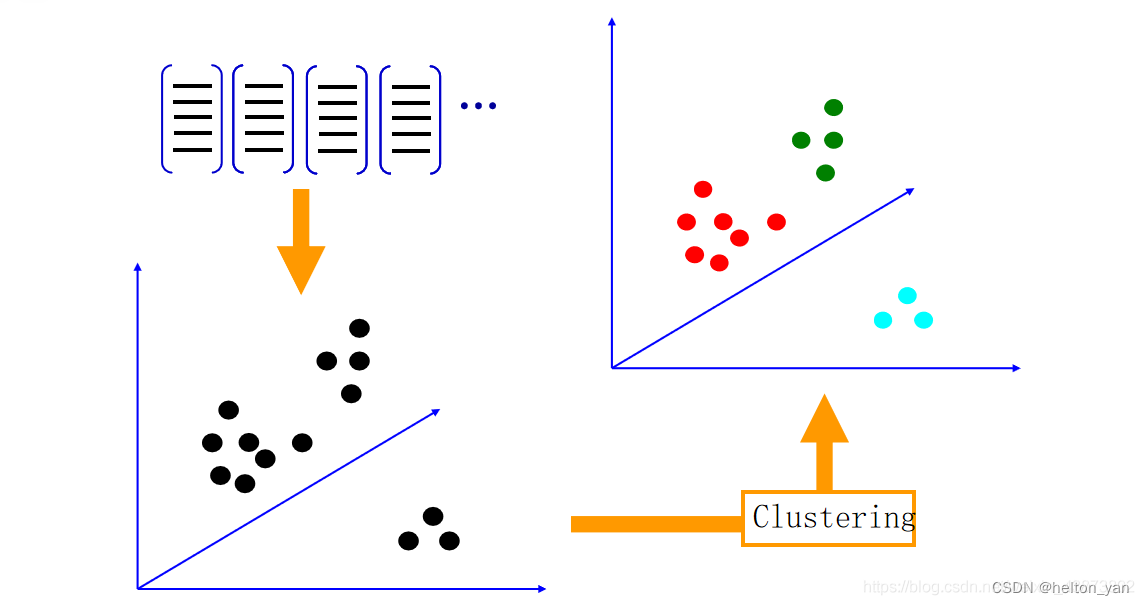
�����,�͵õ����� k kk ��������ɵĴʵ�,��Ϊvisual words(�Ӿ�����)��������Щ�Ӿ����ʹ��ɵļ��ϳ�Ϊ �Ӿ��ʻ�

��������������������
��һ��ѵ���õ����ֵ�,��Ϊ����һ����ͼ��������������������һ��ͼ�����,���ǿ�����ȡ�������ġ�SIFT��������,����Щ��������Ȼ����һ��dz��(low level)�ı���,ȱ�������ԡ����,��һ����Ŀ��,�Ǹ����ֵ�������ȡͼ��ĸ߲�������
����������,����ͼ���е�ÿһ����SIFT������,���������ֵ����ҵ�һ�������Ƶ� visual word,����,���ǿ���ͳ��һ�� k ά��ֱ��ͼ,������ͼ��ġ�SIFT���������ֵ��е����ƶ�Ƶ�ʡ�
����ƥ��ͼƬ�ġ�SIFT���������ֵ��е� visual word,ͳ�Ƴ������Ƶ��������ֵĴ���,���õ����ͼƬ��ֱ��ͼ����
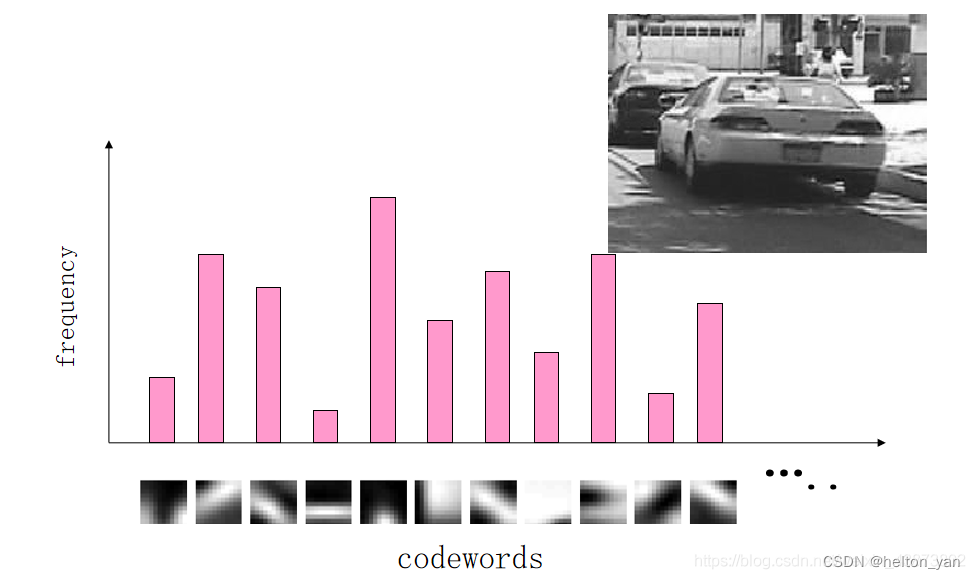
���ʵ�TF-IDFȨ��
������������,��ʸ���ռ�ģ�����ᵽ�˵���Ȩ��,���ı�������,��ͬ���ʶ��ı������Ĺ����в���,�����ڽ�����ͼ��ת��ΪƵ��ֱ��ͼʱ��Ҫ����TF-IDF����Ȩֵ�����������������Ӿ�����ģ�����ἰ��
ijһ�ض��ļ��ڵĸߴ���Ƶ��,�Լ��ô����������ļ������еĵ��ļ�Ƶ��,���Բ�������Ȩ�ص�TF-IDF�����,TF-IDF�����ڹ��˵������Ĵ���,������Ҫ�Ĵ��
���ű�
���ű���һ���������������,���쵹�ű����Կ�������ͼ��������,ͨ������Ҫ��ѯ�Ĺؼ���,��ѯ�����ùؼ�����ص������ĵ������ű����Ի���Ǹ��Ӿ����ʳ�����ͼ������Щͼ���С�
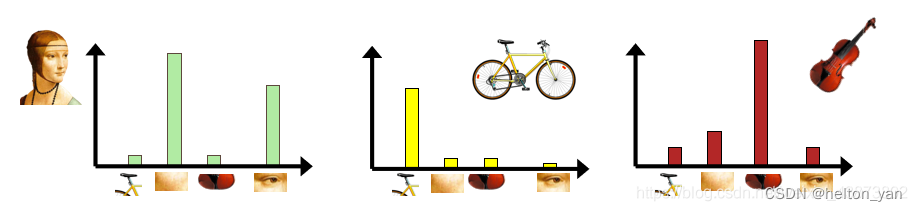
ֱ��ͼƥ��
���,���������Ľ������ֱ��ͼƥ��,�������ͼ��������
��.����ʵ�ֹ���
���ε����ݼ���Ϊ��������
1.64_CASIA-FaceV5�������ݼ�

2.ָ��ʶ�����ݼ�

3.У�������ݼ�

����ʵ��
������ʵ����SIFT��ORB�ļ�ⷽ��:
# ��ȡͼ��ORB����
def extraORBfromImg(ORB, img):
# �ؼ�����(kps), ������������(des
kps, desc = ORB.detectAndCompute(img, mask=None) # �ؼ�����
return desc
# ��ȡͼ��SIFT����
def extraSIFTKeyPoints(sift, img):
# ���� opencv4.4.0 ����汾��˵,SIFT�����Ѿ�����ֱ��ʹ����,
# ���cv2.xfeatures2d.SIFT_create()����ʹ��
# �ؼ�����(kps), ������������(des)
kps, des = sift.detectAndCompute(img, None)
# ����SIFT�ؼ���
# drawSIFTKeyPoints(img, kps)
return des
����KMeans�����������:
# ����
def KMeansClustering(corner, k):
kmeans = MiniBatchKMeans(n_clusters=k, init='k-means++', batch_size=8192, max_iter=200)
kmeans.fit_predict(corner)
# ��������
centroids = kmeans.cluster_centers_
# # ÿ�������������
# labels = kmeans.labels_
return centroids
�������ݼ����ɴʴ�ģ��:
# ���ɴʴ�
def genBOWfromImgs(ORB, root):
# ������
desc = []
for img in tqdm(os.listdir(root)):
image = cv2.imread(root + img)
# img,_,_ = utils.auto_reshape(img, 720)
# ֻ����ȡ�������������
# des = extraSIFTKeyPoints(sift, image)
des = extraORBfromImg(ORB, image)
desc.append(des)
# ���ݼ�������������
descriptors = np.concatenate([_ for _ in desc], axis=0)
print(descriptors.shape)
descriptors = np.load('bdow2.npy')
# ����(ʹ��С��������,ԭ���ѵ��������ʹ��С����������ͬ)
centroids = norm(KMeansClustering(descriptors, 1000))
print(centroids.shape)
np.save('bow_1000.npy', centroids)
return centroids
�������ݼ��������ݼ�ÿ��ͼ��Ĵʴ�����:
# �������ݼ��Ĵʴ�����
def extraBOWFeaturefromImgs(ORB, bow, root):
Vec = []
for img in os.listdir(root):
image = cv2.imread(root + img)
# img,_,_ = utils.auto_reshape(img, 720)
# ֻ����ȡ�������������
# des = extraSIFTKeyPoints(sift, image)
des = norm(extraORBfromImg(ORB, image))
# ������������
sim = np.argmax((bow @ des.T).T, 1)
# ���ɴʴ�����
vec = np.zeros(1000)
for i in sim:vec[i] += 1
Vec.append(vec)
Vec = norm(np.array(Vec))
np.save('./BowVec.npy',Vec)
�����µ�ͼ�����ɴʴ�����:
def img2vec(ORB, bow, bow_vec, img):
# ֻ����ȡ�������������
# des = extraSIFTKeyPoints(sift, img)
des = norm(extraORBfromImg(ORB, img))
# ������������
sim = np.argmax((bow @ des.T).T, 1)
# ���ɴʴ�����
vec = np.zeros(1000)
for i in sim:vec[i] += 1
vec = norm(vec)
sim_vec = bow_vec @ vec
return sim_vec
��������һ��(TF):
# �����ݱ���
def norm(x):
if (len(x.shape) == 1):
return x / np.linalg.norm(x)
return x / np.linalg.norm(x,axis=1).reshape(-1,1)
����
# ����������һ��sift���ʵ��
# sift = cv2.SIFT_create(nfeatures=800)
orb = cv2.ORB_create(1000)
'''train'''
train_set = './jmu/train/'
# ���ɴʴ�
bow = genBOWfromImgs(orb, train_set)
extraBOWFeaturefromImgs(orb, bow, train_set)
'''test'''
train_set = './jmu/train/'
test_set = './jmu/valid/'
img_database = os.listdir('./jmu/train/')
bow = np.load('./bow_1000.npy')
bow_vec = np.load('./BowVec.npy')
sim = []
for img in os.listdir(test_set):
image = cv2.imread(test_set + img)
sim.append(img2vec(orb, bow, bow_vec, image))
sim = np.array(sim)
plt.imshow(sim)
plt.show()
print (img_database[19])
���Խ��:
���ڴʴ�ģ�͵�����ʶ���ָ��ʶ���Ч���dz�һ��,����Ͳ��Ž����,�����ݼ��Ϸ���,һ�����ܵ�ԭ���Ǵʴ�ģ��ʵ��ֻ����ȡͼ���зdz���������������Լ���������,����������ȡ����֮�ϸ����εij�����������,������ʹ�õ����ݼ���ÿ��ͼ��ı������������зdz��ߵ�������(��ɫ����,�����Ĵ�������,��ɫ��ָ������,�Լ���ɫ�ı���)
�������ܵ�ԭ����:���˵Ĵ����в�û�п��Ǵ�������IDF,�Լ�һЩ���ݴ�������,����ĵ�����������,�����kѡ���ȵȡ�
����У���ݼ��ļ���Ч��:


��.�Ľ�
ORBSLAM2���ṩ��һ�ֻ���ORB���������ߴʴ���DBow2(���Ѹ�����DBow3),���ǿ����������е�ORBvoc.txt��Ϊ���ǵĴʴ�ģ��:

�乹��������νṹ:
��һ����10�����ʴ����ķ�֧,6�����������,0,�������ƶ�,0����Ȩ�ء�
�ڶ��е�0�����ڵ�ĸ��ڵ�,�ڶ���0�����Ƿ�Ҷ�ӽ��,�����ʾ��Ҷ�ӽ��,252-43��ʾ����������(����Ϊ32),���һ����ʾȨ��
��ÿһ����Ҷ�ڵ���������Ҷ�ڵ�ľ������ġ�
������Լ�����Ĵʴ�,DBow�ṩ�Ĵʴ�ģ�Ͱ�����Ϊ�ḻ������,��������ڹ���ͼ��Ĵ�����ʱ����ֱ�ӻ���DBoW���ṩ�����ߴʴ�ֱ�ӽ��й��졣