本文将介绍一个不使用卷积和循环网络层,而是完全基于注意力机制的模型――Transformer。提出这个模型的论文是Attention Is All You Need:

Transformer
自注意力(self-attention)和多头注意力(multi-head attention)
Transformer使用的注意力机制是多头自注意力,即将自注意力和多头注意力结合起来:
图片改自:[1]
下面将以Transformer为例展示多头自注意力,所以这里略过。
Transformer架构
Transformer总体架构如图:
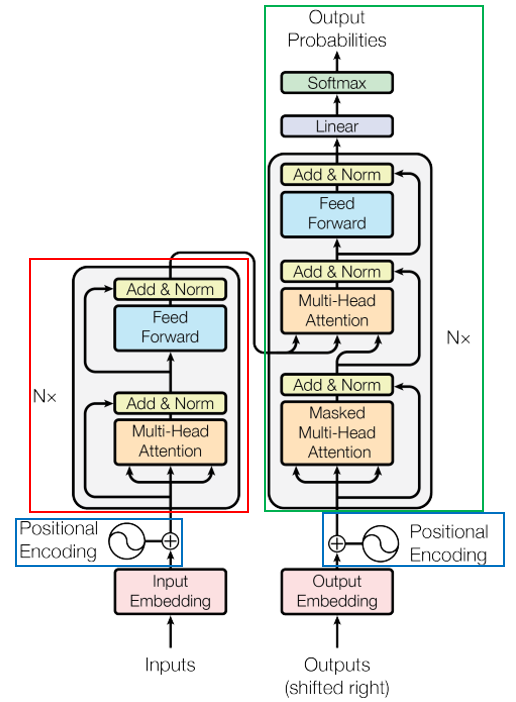
左边为编码器,右边为解码器, N ? × \operatorname{N}× N×表示模块重复N次。
Transformer的编码器将输入 ( x 0 , … , x n ? 1 ) (\boldsymbol{x}_0,\dots,\boldsymbol{x}_{n-1}) (x0?,…,xn?1?)进行编码,得到输入的表示 Z \boldsymbol{Z} Z。
Transformer的解码器则是自回归的,即在生成下一符号时,使用先前生成的所有符号作为输入。给定 Z \boldsymbol{Z} Z,解码器一次生成一个元素 y i \boldsymbol{y}_i yi?直到输出整个序列 ( y 0 , … , y m ? 1 ) (\boldsymbol{y}_0,\dots,\boldsymbol{y}_{m-1}) (y0?,…,ym?1?)。
以机器翻译(中文翻译为英文)为例:

(1)训练时
编码器
输入:生存还是毁灭
输出:编码Z
解码器
输入:BEGIN To be or not to be 和 Z(中间插入,如架构图所示)
目标:To be or not to be END
BEGIN和END为开始和结束的标识符。
(2)测试时
编码器
输入:生存还是毁灭
输出:编码Z
解码器自回归输入输出:
输入:BEGIN和Z(中间插入)
输出:To
输入:BEGIN To 和Z(中间插入)
输出:be
输入:BEGIN To be 和Z(中间插入)
输出:or
输入:BEGIN To be or和Z(中间插入)
输出: not
输入:BEGIN To be or not和Z(中间插入)
输出: to
输入:BEGIN To be or not to和Z(中间插入)
输出: be
输入:BEGIN To be or not to be和Z(中间插入)
输出:END
结束
下面三个小节将分别讲解Transformer的位置编码,编码器和解码器
位置编码
Transformer不包含卷积和循环模块。为了让模型能够利用输入的顺序,我们可以给输入的特征向量添加位置编码,增加一些位置信息。
令 t t t是输入向量 x t \boldsymbol{x}_t xt?的位置, d d d是输入向量的维度, i i i表示输入向量的第 i i i个维度。Transformer使用不同频率的正弦和余弦函数作为位置编码,输入向量 x t \boldsymbol{x}_t xt?的位置编码为:
p t = [ p t , 0 p t , 1 p t , 2 p t , 3 ? p t , d ? 2 p t , d ? 1 ] = [ sin ? ( ω 0 ? t ) cos ? ( ω 0 ? t ) sin ? ( ω 1 ? t ) cos ? ( ω 1 ? t ) ? sin ? ( ω d / 2 ? 1 ? t ) cos ? ( ω d / 2 ? 1 ? t ) ] \boldsymbol{p}_{t}=\left[\begin{array}{c} {p}_{t, 0}\\ {p}_{t, 1} \\ {p}_{t, 2} \\ {p}_{t, 3} \\ \vdots \\ {p}_{t, d-2}\\ {p}_{t, d-1} \end{array}\right]=\left[\begin{array}{c} \sin \left(\omega_{0} \cdot t\right) \\ \cos \left(\omega_{0} \cdot t\right) \\ \sin \left(\omega_{1} \cdot t\right) \\ \cos \left(\omega_{1} \cdot t\right) \\ \vdots \\ \sin \left(\omega_{d / 2-1} \cdot t\right) \\ \cos \left(\omega_{d / 2-1} \cdot t\right) \end{array}\right] pt?=????????????pt,0?pt,1?pt,2?pt,3??pt,d?2?pt,d?1??????????????=????????????sin(ω0??t)cos(ω0??t)sin(ω1??t)cos(ω1??t)?sin(ωd/2?1??t)cos(ωd/2?1??t)?????????????
p t , i = { sin ? ( ω k ? t ) , ?if? i = 2 k cos ? ( ω k ? t ) , ?if? i = 2 k + 1 {p}_{t, i}=\left\{\begin{array}{ll} \sin \left(\omega_{k} \cdot t\right), & \text { if } i=2 k \\ \cos \left(\omega_{k} \cdot t\right), & \text { if } i=2 k+1 \end{array}\right. pt,i?={sin(ωk??t),cos(ωk??t),??if?i=2k?if?i=2k+1?
其中: k = 0 , 1 , 2 , . . . , d / 2 ? 1 k=0,1,2,...,d/2-1 k=0,1,2,...,d/2?1, ω k = 1 1000 0 2 k / d \omega_{k}=\frac{1}{10000^{2 k / d}} ωk?=100002k/d1?
以维度 i i i为横坐标,位置 t t t为纵坐标,画出位置编码图像:
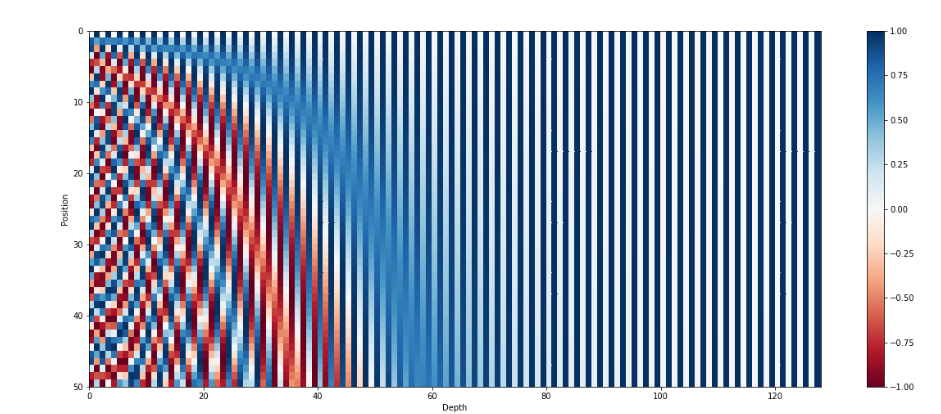
图片来源:[7]
每一行为一个位置编码 p t \boldsymbol{p}_{t} pt?。
这种位置编码除了可以表示向量的绝对位置信息,即不同输入向量有不同的位置编码,还包含相对位置信息:
M . [ sin ? ( ω k . t ) cos ? ( ω k . t ) ] = [ sin ? ( ω k ? ( t + ? ) ) cos ? ( ω k ? ( t + ? ) ) ] M .\left[\begin{array}{l} \sin \left(\omega_{k} . t\right) \\ \cos \left(\omega_{k} . t\right) \end{array}\right]=\left[\begin{array}{l} \sin \left(\omega_{k} \cdot(t+\phi)\right) \\ \cos \left(\omega_{k} \cdot(t+\phi)\right) \end{array}\right] M.[sin(ωk?.t)cos(ωk?.t)?]=[sin(ωk??(t+?))cos(ωk??(t+?))?]
其中
M = [ cos ? ( ω k . ? ) sin ? ( ω k . ? ) ? sin ? ( ω k . ? ) cos ? ( ω k . ? ) ] M=\left[\begin{array}{cc} \cos \left(\omega_{k} . \phi\right) & \sin \left(\omega_{k} . \phi\right) \\ -\sin \left(\omega_{k} . \phi\right) & \cos \left(\omega_{k} . \phi\right) \end{array}\right] M=[cos(ωk?.?)?sin(ωk?.?)?sin(ωk?.?)cos(ωk?.?)?]
即 sin ? ( ω k ? ( t + ? ) ) \sin \left(\omega_{k} \cdot(t+\phi)\right) sin(ωk??(t+?))和 cos ? ( ω k ? ( t + ? ) ) \cos \left(\omega_{k} \cdot(t+\phi)\right) cos(ωk??(t+?))可以由 sin ? ( ω k . t ) \sin \left(\omega_{k} . t\right) sin(ωk?.t)和 cos ? ( ω k . t ) \cos \left(\omega_{k} . t\right) cos(ωk?.t)线性表示。
对于输入 X = [ x 0 , . . . , x t , . . . , x n f ? 1 ] \boldsymbol{X}=[\boldsymbol{x}_{0},...,\boldsymbol{x}_{t},...,\boldsymbol{x}_{nf-1}] X=[x0?,...,xt?,...,xnf?1?],位置编码 p t \boldsymbol{p}_{t} pt?与向量 x t \boldsymbol{x}_t xt?具有相同的维度,所以可以将两者逐元素相加:
F = [ x 0 + p 0 , . . . , x t + p t , . . . x n f ? 1 + p n f ? 1 ] \boldsymbol{F}=[\boldsymbol{x}_{0}+\boldsymbol{p}_{0}, ...,\boldsymbol{x}_{t}+\boldsymbol{p}_{t},...\boldsymbol{x}_{n_{f}-1}+\boldsymbol{p}_{n_f-1}] F=[x0?+p0?,...,xt?+pt?,...xnf??1?+pnf??1?]
编码器
多头自注意力
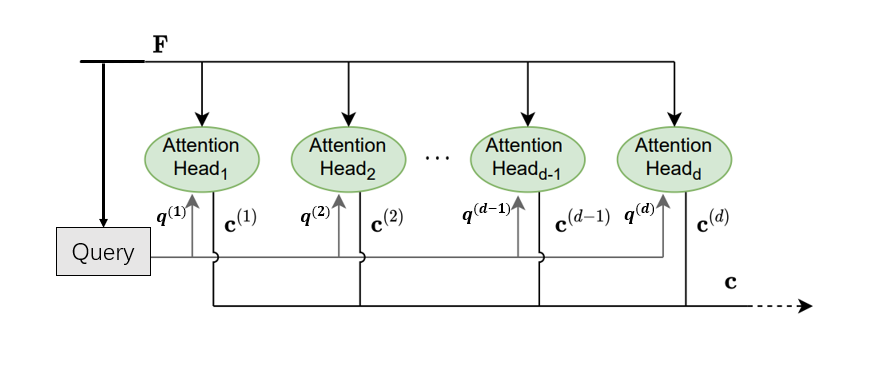
Transformer总共有 h = 8 h=8 h=8个并行的自注意力层/头。每个自注意力头都有自己的可学习权重矩阵 W K ( l ) ∈ R d v × d f \boldsymbol{W}^{(l)}_K∈\mathbb{R}^{d_v×d_f} WK(l)?∈Rdv?×df?和 W V ( l ) ∈ R d q × d f 、 W Q ( l ) ∈ R d q × d f \boldsymbol{W}^{(l)}_V\in \mathbb{R}^{d_{q} \times d_{f}}、\boldsymbol{W}^{(l)}_Q∈\mathbb{R}^{d_q×d_f} WV(l)?∈Rdq?×df?、WQ(l)?∈Rdq?×df?, l = 0 , … , h ? 1 l=0, \ldots, h-1 l=0,…,h?1,自注意力头 ( l ) ^{(l)} (l)的查询、键和值根据特征矩阵 F ( old ) ∈ R d f × n f \boldsymbol{F}^{(\text {old})}\in \mathbb{R}^{d_{f}\times n_f} F(old)∈Rdf?×nf?计算如下:
键(Key)矩阵:
K ( l ) = W K ( l ) × F ( old ) ∈ R d k × n f = [ k 0 ( l ) , … , k n f ? 1 ( l ) ] \begin{aligned} {\boldsymbol{K}^{(l)}}&={\boldsymbol{W}_K^{(l)}} \times{\boldsymbol{F}^{(\text {old})}}\in \mathbb{R}^{d_{k}\times n_f}\\&=\left[\boldsymbol{k}^{(l)}_{0}, \ldots, \boldsymbol{k}^{(l)}_{n_{f}-1}\right] \end{aligned} K(l)?=WK(l)?×F(old)∈Rdk?×nf?=[k0(l)?,…,knf??1(l)?]?
值(Value)矩阵:
V ( l ) = W V ( l ) × F ( old ) ∈ R d v × n f = [ v 0 ( l ) , … , v n f ? 1 ( l ) ] \begin{aligned} {\boldsymbol{V}^{(l)}}&={\boldsymbol{W}_V^{(l)}} \times {\boldsymbol{F}^{(\text {old})}}\in \mathbb{R}^{d_{v}\times n_f}\\&=\left[\boldsymbol{v}^{(l)}_{0}, \ldots, \boldsymbol{v}^{(l)}_{n_{f}-1}\right] \end{aligned} V(l)?=WV(l)?×F(old)∈Rdv?×nf?=[v0(l)?,…,vnf??1(l)?]?
查询(Query)矩阵:
Q ( l ) = W Q ( l ) × F ( old ) ∈ R d q × n f = [ q 0 ( l ) , … , q n f ? 1 ( l ) ] \begin{aligned} {\boldsymbol{Q}^{(l)}}&={\boldsymbol{W}_{Q}^{(l)}} \times{\boldsymbol{F}^{(\text {old})}}\in \mathbb{R}^{d_{q}\times n_f}\\&=\left[\boldsymbol{q}^{(l)}_{0}, \ldots, \boldsymbol{q}^{(l)}_{n_{f}-1}\right] \end{aligned} Q(l)?=WQ(l)?×F(old)∈Rdq?×nf?=[q0(l)?,…,qnf??1(l)?]?
以缩放点乘(Scaled Dot-Product)作为打分函数计算注意力得分:
E ( l ) = [ e 0 ( l ) , e 1 ( l ) , … , e n f ? 1 ( l ) ] = [ e 0 , 0 ( l ) e 1 , 0 ( l ) ? e n f ? 1 , 0 ( l ) e 0 , 1 ( l ) e 1 , 1 ( l ) ? e n f ? 1 , 1 ( l ) ? ? ? ? e 0 , n f ? 1 ( l ) e 1 , n f ? 1 ( l ) ? e n f ? 1 , n f ? 1 ( l ) ] = [ k 0 ( l ) T q 0 k 0 ( l ) T q 1 ? k 0 ( l ) T q n f ? 1 k 1 ( l ) T q 0 k 1 ( l ) T q 1 ? k 1 ( l ) T q n f ? 1 ? ? ? ? k n f ? 1 ( l ) T q 0 k n f ? 1 ( l ) T q 1 ? k n f ? 1 ( l ) T q n f ? 1 ] / d k = [ k 0 ( l ) T k 1 ( l ) T ? k n f ? 1 ( l ) T ] ? [ q 0 ( l ) , q 1 ( l ) , … , q n f ? 1 ( l ) ] / d k = K ( l ) T Q ( l ) d k \begin{aligned} \boldsymbol{E}^{(l)}&=\begin{bmatrix}\boldsymbol{e}^{(l)}_{0}, \boldsymbol{e}^{(l)}_{1},\ldots, \boldsymbol{e}^{(l)}_{n_{f}-1}\end{bmatrix} \\&=\begin{bmatrix}e^{(l)}_{0,0}&e^{(l)}_{1,0}&\cdots&e^{(l)}_{n_f-1,0} \\e^{(l)}_{0,1} &e^{(l)}_{1,1} &\cdots&e^{(l)}_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\e^{(l)}_{0,n_f-1} &e^{(l)}_{1,n_f-1} &\cdots&e^{(l)}_{n_f-1,n_f-1} \\\end{bmatrix} \\&=\begin{bmatrix}\boldsymbol{k}^{{(l)}^T}_{0}\boldsymbol{q}_{0}&\boldsymbol{k}^{{(l)}^T}_{0}\boldsymbol{q}_{1}&\cdots&\boldsymbol{k}^{{(l)}^T}_{0}\boldsymbol{q}_{n_f-1}\\\boldsymbol{k}^{{(l)}^T}_{1}\boldsymbol{q}_{0}&\boldsymbol{k}^{{(l)}^T}_{1}\boldsymbol{q}_{1}&\cdots&\boldsymbol{k}^{{(l)}^T}_{1}\boldsymbol{q}_{n_f-1}\\\vdots&\vdots&\ddots&\vdots\\\boldsymbol{k}^{{(l)}^T}_{n_f-1}\boldsymbol{q}_{0}&\boldsymbol{k}^{{(l)}^T}_{n_f-1}\boldsymbol{q}_{1}&\cdots&\boldsymbol{k}^{{(l)}^T}_{n_f-1}\boldsymbol{q}_{n_f-1}\\\end{bmatrix}/\sqrt{d_k} \\&= \begin{bmatrix} \boldsymbol{k}^{{(l)}^T}_{0}\\ \boldsymbol{k}^{{(l)}^T}_{1}\\ \vdots\\ \boldsymbol{k}^{{(l)}^T}_{n_f-1} \end{bmatrix}\cdot\begin{bmatrix}\boldsymbol{q}^{(l)}_{0}, \boldsymbol{q}^{(l)}_{1},\ldots, \boldsymbol{q}^{(l)}_{n_{f}-1}\end{bmatrix}/\sqrt{d_k}\\&=\frac{\boldsymbol{K}^{{(l)}^T}Q^{(l)}}{\sqrt{d_k}} \end{aligned} E(l)?=[e0(l)?,e1(l)?,…,enf??1(l)??]=???????e0,0(l)?e0,1(l)??e0,nf??1(l)??e1,0(l)?e1,1(l)??e1,nf??1(l)???????enf??1,0(l)?enf??1,1(l)??enf??1,nf??1(l)?????????=????????k0(l)T?q0?k1(l)T?q0??knf??1(l)T?q0??k0(l)T?q1?k1(l)T?q1??knf??1(l)T?q1???????k0(l)T?qnf??1?k1(l)T?qnf??1??knf??1(l)T?qnf??1??????????/dk??=????????k0(l)T?k1(l)T??knf??1(l)T???????????[q0(l)?,q1(l)?,…,qnf??1(l)??]/dk??=dk??K(l)TQ(l)??
以Softmax()作为对齐函数,计算注意力权重:
A ( l ) = [ a 0 ( l ) , a 1 ( l ) , . . . , a n f ? 1 ( l ) ] = [ a 0 , 0 ( l ) a 1 , 0 ( l ) ? a n f ? 1 , 0 ( l ) a 0 , 1 ( l ) a 1 , 1 ( l ) ? a n f ? 1 , 1 ( l ) ? ? ? ? a 0 , n f ? 1 ( l ) a 1 , n f ? 1 ( l ) ? a n f ? 1 , n f ? 1 ( l ) ] = [ Softmax ? ( e 0 , 0 ( l ) ; e 0 ( l ) ) Softmax ? ( e 1 , 0 ( l ) ; e 1 ( l ) ) ? Softmax ? ( e n f ? 1 , 0 ( l ) ; e n f ? 1 ( l ) ) Softmax ? ( e 0 , 1 ( l ) ; e 0 ( l ) ) Softmax ? ( e 1 , 1 ( l ) ; e 1 ( l ) ) ? Softmax ? ( e n f ? 1 , 1 ( l ) ; e n f ? 1 ( l ) ) ? ? ? ? Softmax ? ( e 0 , n f ? 1 ( l ) ; e 0 ( l ) ) Softmax ? ( e 1 , n f ? 1 ( l ) ; e 1 ( l ) ) ? Softmax ? ( e n f ? 1 , n f ? 1 ( l ) ; e n f ? 1 ( l ) ) ] = Softmax ? ( K ( l ) T Q ( l ) d k ) \begin{aligned} \boldsymbol{A}^{(l)}&=[\boldsymbol{a}^{(l)}_0,\boldsymbol{a}^{(l)}_1,...,\boldsymbol{a}^{(l)}_{n_f-1}] \\&=\begin{bmatrix}a^{(l)}_{0,0}&a^{(l)}_{1,0}&\cdots&a^{(l)}_{n_f-1,0} \\a^{(l)}_{0,1} &a^{(l)}_{1,1} &\cdots&a^{(l)}_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\a^{(l)}_{0,n_f-1} &a^{(l)}_{1,n_f-1} &\cdots&a^{(l)}_{n_f-1,n_f-1} \end{bmatrix} \\&=\begin{bmatrix}\operatorname{Softmax}\left({e^{(l)}_{0,0} ;} {\boldsymbol{e^{(l)}_0}}\right)&\operatorname{Softmax}\left({e^{(l)}_{1,0} ;} {\boldsymbol{e^{(l)}_1}}\right)&\cdots&\operatorname{Softmax}\left({e^{(l)}_{n_f-1,0} ;} {\boldsymbol{e^{(l)}_{n_f-1}}}\right) \\\operatorname{Softmax}\left({e^{(l)}_{0,1} ;} {\boldsymbol{e^{(l)}_0}}\right)&\operatorname{Softmax}\left({e^{(l)}_{1,1} ;} {\boldsymbol{e^{(l)}_1}}\right)&\cdots&\operatorname{Softmax}\left({e^{(l)}_{n_f-1,1} ;} {\boldsymbol{e^{(l)}_{n_f-1}}}\right) \\\vdots&\vdots&\ddots&\vdots \\\operatorname{Softmax}\left({e^{(l)}_{0,n_f-1} ;} {\boldsymbol{e^{(l)}_0}}\right)&\operatorname{Softmax}\left({e^{(l)}_{1,n_f-1} ;} {\boldsymbol{e^{(l)}_1}}\right)&\cdots&\operatorname{Softmax}\left({e^{(l)}_{n_f-1,n_f-1} ;} {\boldsymbol{e^{(l)}_{n_f-1}}}\right) \\\end{bmatrix} \\&=\operatorname{Softmax}(\frac{{\boldsymbol{K^{(l)}}}^T\boldsymbol{Q}^{(l)}}{\sqrt{d_k}}) \end{aligned} A(l)?=[a0(l)?,a1(l)?,...,anf??1(l)?]=???????a0,0(l)?a0,1(l)??a0,nf??1(l)??a1,0(l)?a1,1(l)??a1,nf??1(l)???????anf??1,0(l)?anf??1,1(l)??anf??1,nf??1(l)?????????=?????????Softmax(e0,0(l)?;e0(l)?)Softmax(e0,1(l)?;e0(l)?)?Softmax(e0,nf??1(l)?;e0(l)?)?Softmax(e1,0(l)?;e1(l)?)Softmax(e1,1(l)?;e1(l)?)?Softmax(e1,nf??1(l)?;e1(l)?)??????Softmax(enf??1,0(l)?;enf??1(l)?)Softmax(enf??1,1(l)?;enf??1(l)?)?Softmax(enf??1,nf??1(l)?;enf??1(l)?)??????????=Softmax(dk??K(l)TQ(l)?)?
自注意力头 ( l ) ^{(l)} (l)输出为:
C ( l ) = [ c 0 ( l ) , c 1 ( l ) , … , c n f ? 1 ( l ) ] = [ v 0 ( l ) , v 1 ( l ) , … , v n f ? 1 ( l ) ] [ a 0 , 0 ( l ) a 1 , 0 ( l ) ? a n f ? 1 , 0 ( l ) a 0 , 1 ( l ) a 1 , 1 ( l ) ? a n f ? 1 , 1 ( l ) ? ? ? ? a 0 , n f ? 1 ( l ) a 1 , n f ? 1 ( l ) ? a n f ? 1 , n f ? 1 ( l ) ] = V ( l ) Softmax ? ( K ( l ) T Q ( l ) d k ) \begin{aligned} \boldsymbol{C^{(l)}}&=\left[\boldsymbol{c}^{(l)}_{0}, \boldsymbol{c}^{(l)}_{1},\ldots, \boldsymbol{c}^{(l)}_{n_{f}-1}\right] \\&=\left[\boldsymbol{v}^{(l)}_{0}, \boldsymbol{v}^{(l)}_{1},\ldots, \boldsymbol{v}^{(l)}_{n_{f}-1}\right]\begin{bmatrix}a^{(l)}_{0,0}&a^{(l)}_{1,0}&\cdots&a^{(l)}_{n_f-1,0} \\a^{(l)}_{0,1} &a^{(l)}_{1,1} &\cdots&a^{(l)}_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\a^{(l)}_{0,n_f-1} &a^{(l)}_{1,n_f-1} &\cdots&a^{(l)}_{n_f-1,n_f-1} \\\end{bmatrix} \\&=\boldsymbol{V}^{(l)}\operatorname{Softmax}(\frac{\boldsymbol{K}^{{(l)}^T}Q^{(l)}}{\sqrt{d_k}}) \end{aligned} C(l)?=[c0(l)?,c1(l)?,…,cnf??1(l)?]=[v0(l)?,v1(l)?,…,vnf??1(l)?]???????a0,0(l)?a0,1(l)??a0,nf??1(l)??a1,0(l)?a1,1(l)??a1,nf??1(l)???????anf??1,0(l)?anf??1,1(l)??anf??1,nf??1(l)?????????=V(l)Softmax(dk??K(l)TQ(l)?)?
将上述每个头部的自注意力计算过程总结为表达式:
c i ( l ) = self-att ? ( q i ( l ) , K ( l ) , V ( l ) ) \boldsymbol{c}^{(l)}_i=\operatorname{self-att}(\boldsymbol{q_i}^{(l)},\boldsymbol{K}^{(l)},\boldsymbol{V}^{(l)})\\ ci(l)?=self-att(qi?(l),K(l),V(l))
C ( l ) = [ c 0 ( l ) , c 1 ( l ) , … , c n f ? 1 ( l ) ] = self-att ? ( Q ( l ) , K ( l ) , V ( l ) ) = V ( l ) Softmax ? ( K ( l ) T Q ( l ) d k ) ∈ R d v × n f \begin{aligned} \boldsymbol{C}^{(l)}&=\left[\boldsymbol{c}^{(l)}_{0}, \boldsymbol{c}^{(l)}_{1},\ldots, \boldsymbol{c}^{(l)}_{n_{f}-1}\right]\\&=\operatorname{self-att}(\boldsymbol{Q}^{(l)},\boldsymbol{K}^{(l)},\boldsymbol{V}^{(l)})\\&=\boldsymbol{V}^{(l)}\operatorname{Softmax}(\frac{\boldsymbol{K}^{{(l)}^T}Q^{(l)}}{\sqrt{d_k}})\in \mathbb{R}^{d_v\times n_f} \end{aligned} C(l)?=[c0(l)?,c1(l)?,…,cnf??1(l)?]=self-att(Q(l),K(l),V(l))=V(l)Softmax(dk??K(l)TQ(l)?)∈Rdv?×nf??
我们的目标仍然是创建一个上下文向量作为注意力模型的输出。因此,要将各个注意力头产生的上下文向量被连接成一个向量 concat ? ( C ( 0 ) ; C ( 1 ) ; … ; C ( h ? 1 ) ) ∈ R d v h × n f \operatorname{concat}\left( \boldsymbol{C}^{(0)};\boldsymbol{C}^{(1)}; \ldots;\boldsymbol{C}^{(h-1)}\right)\in\mathbb{R}^{d_{v} h\times n_f} concat(C(0);C(1);…;C(h?1))∈Rdv?h×nf?。然后,使用权重矩阵 W O ∈ R d c × d v h \boldsymbol{W}_{O} \in \mathbb{R}^{d_{c} \times d_{v} h} WO?∈Rdc?×dv?h对其进行线性变换:
C = W O × concat ? ( C ( 0 ) ; C ( 1 ) ; … ; C ( h ? 1 ) ) = W O × [ concat ? ( c 0 ( 0 ) ; … ; c 0 ( h ? 1 ) ) , concat ? ( c 1 ( 0 ) ; … ; c 1 ( h ? 1 ) ) , . . . , concat ? ( c n f ? 1 ( 0 ) ; … ; c n f ? 1 ( h ? 1 ) ) ] ∈ R d c × n f \begin{aligned} {\boldsymbol{C}}&={\boldsymbol{W}_{O}} \times \operatorname{concat}\left( \boldsymbol{C}^{(0)};\boldsymbol{C}^{(1)}; \ldots;\boldsymbol{C}^{(h-1)}\right) \\&={\boldsymbol{W}_{O}} \times\left[ \operatorname{concat}(\boldsymbol{c}_0^{(0)};\ldots; {\boldsymbol{c}_0^{(h-1)}}), \operatorname{concat}(\boldsymbol{c}_1^{(0)} ; \ldots; {\boldsymbol{c}_1^{(h-1)}}),...,\operatorname{concat}(\boldsymbol{c}_{ n_f-1}^{(0)} ; \ldots;{\boldsymbol{c}_{n_f-1}^{(h-1)}})\right]\in \mathbb{R}^{d_c\times n_f} \end{aligned} C?=WO?×concat(C(0);C(1);…;C(h?1))=WO?×[concat(c0(0)?;…;c0(h?1)?),concat(c1(0)?;…;c1(h?1)?),...,concat(cnf??1(0)?;…;cnf??1(h?1)?)]∈Rdc?×nf??
对于每一个头,可以令 d k = d v = d q = d c / h d_k=d_v=d_q=d_{c}/h dk?=dv?=dq?=dc?/h。由于每个头部的输出尺寸大小都 / h /h /h,所以总计算成本与全尺寸 d c d_{c} dc?单头注意的计算成本差不多。
Transformer的多头自注意力层还使用了残差连接和层归一化,最终输出为:
F ( new? ) = LayerNorm ? ( F ( old ) + C ) {\boldsymbol{F}^{(\text {new })}}=\operatorname{LayerNorm}\left({\boldsymbol{F}^{(\text {old})}}+{\boldsymbol{C}}\right) F(new?)=LayerNorm(F(old)+C)
前馈网络
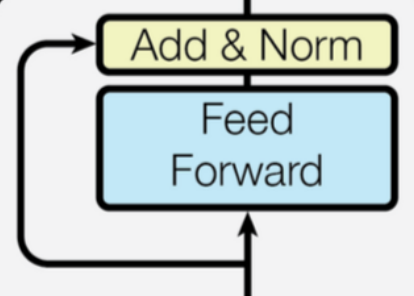
编码模块最终输出:
Z
=
LayerNorm
?
(
F
(
new?
)
+
FFN
?
(
F
(
new?
)
)
)
\boldsymbol{Z}=\operatorname{LayerNorm}\left( {\boldsymbol{F}^{(\text {new })}}+ \operatorname{FFN}({\boldsymbol{F}^{(\text {new })}})\right)
Z=LayerNorm(F(new?)+FFN(F(new?)))
其中
FFN ? ( F ( new? ) ) = W 1 ReLu ? ( W 0 F ( new? ) + b 0 ) + b 1 \operatorname{FFN}(\boldsymbol{F}^{(\text {new })})=\boldsymbol{W}_1\operatorname{ReLu}(\boldsymbol{W}_0\boldsymbol{F}^{(\text {new })}+\boldsymbol{b}_0)+\boldsymbol{b}_1 FFN(F(new?))=W1?ReLu(W0?F(new?)+b0?)+b1?
解码器
带掩码的多头自注意力
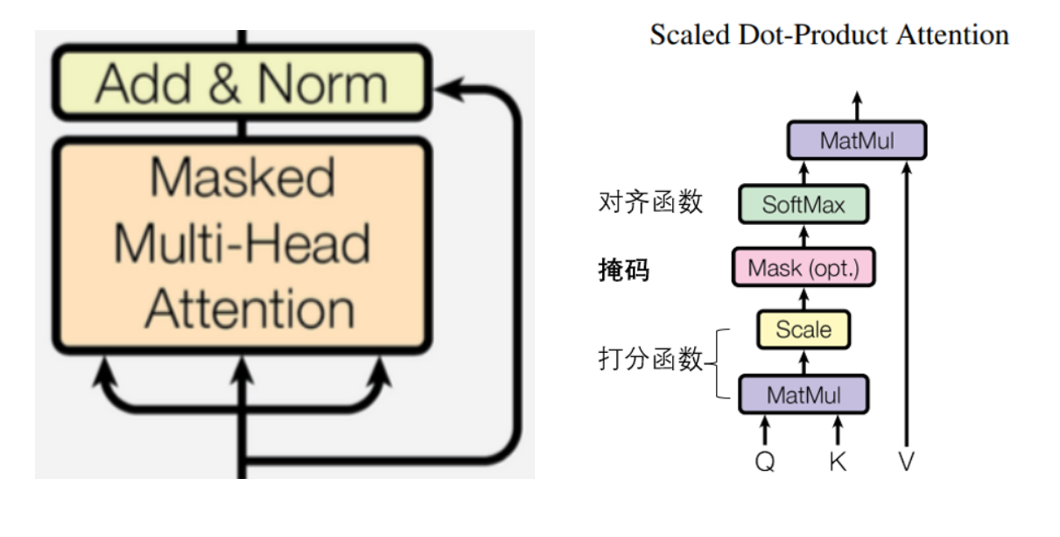
解码器为了保持自回归性,要求解码器中注意力层的输出 c i \boldsymbol{c}_i ci?只与 v 0 , . . . , v i \boldsymbol{v}_0,...,\boldsymbol{v}_{i} v0?,...,vi?有关,这可以通过在打分函数和对齐函数之间加了一个掩码实现。
掩码:
E ′ = Mask ? ( E ) = [ e 0 , 0 e 1 , 0 ? e n f ? 1 , 0 ? ∞ e 1 , 1 ? e n f ? 1 , 1 ? ? ? ? ? ∞ ? ∞ ? e n f ? 1 , n f ? 1 ] \begin{aligned} \boldsymbol{E}'&=\operatorname{Mask}(\boldsymbol{E})\\&=\begin{bmatrix}e_{0,0}&e_{1,0}&\cdots&e_{n_f-1,0} \\-\infty &e_{1,1} &\cdots&e_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\-\infty&-\infty&\cdots&e_{n_f-1,n_f-1} \\\end{bmatrix} \end{aligned} E′?=Mask(E)=??????e0,0??∞??∞?e1,0?e1,1???∞??????enf??1,0?enf??1,1??enf??1,nf??1?????????
对齐:
A = [ a 0 , a 1 , . . . , a n f ? 1 ] = [ a 0 , 0 a 1 , 0 ? a n f ? 1 , 0 a 0 , 1 a 1 , 1 ? a n f ? 1 , 1 ? ? ? ? a 0 , n f ? 1 a 1 , n f ? 1 ? a n f ? 1 , n f ? 1 ] = Softmax ? ( E ′ ) = [ Softmax ? ( e 0 , 0 ; e 0 ) Softmax ? ( e 1 , 0 ; e 0 ) ? Softmax ? ( e n f ? 1 , 0 ; e n f ? 1 ) 0 Softmax ? ( e 1 , 1 ; e 1 ) ? Softmax ? ( e n f ? 1 , 1 ; e n f ? 1 ) ? ? ? ? 0 0 ? Softmax ? ( e n f ? 1 , n f ? 1 ; e n f ? 1 ) ] \begin{aligned} \boldsymbol{A}&=[\boldsymbol{a}_0,\boldsymbol{a}_1,...,\boldsymbol{a}_{n_f-1}] \\&=\begin{bmatrix}a_{0,0}&a_{1,0}&\cdots&a_{n_f-1,0} \\a_{0,1} &a_{1,1} &\cdots&a_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\a_{0,n_f-1} &a_{1,n_f-1} &\cdots&a_{n_f-1,n_f-1} \\\end{bmatrix} \\&=\operatorname{Softmax}(\boldsymbol{E}') \\&=\begin{bmatrix}\operatorname{Softmax}\left({e_{0,0} ;} {\boldsymbol{e_0}}\right)&\operatorname{Softmax}\left({e_{1,0} ;} {\boldsymbol{e_0}}\right)&\cdots&\operatorname{Softmax}\left({e_{n_f-1,0} ;} {\boldsymbol{e_{n_f-1}}}\right) \\0&\operatorname{Softmax}\left({e_{1,1} ;} {\boldsymbol{e_1}}\right)&\cdots&\operatorname{Softmax}\left({e_{n_f-1,1} ;} {\boldsymbol{e_{n_f-1}}}\right) \\\vdots&\vdots&\ddots&\vdots \\0&0&\cdots&\operatorname{Softmax}\left({e_{n_f-1,n_f-1} ;} {\boldsymbol{e_{n_f-1}}}\right) \\\end{bmatrix} \end{aligned} A?=[a0?,a1?,...,anf??1?]=??????a0,0?a0,1??a0,nf??1??a1,0?a1,1??a1,nf??1???????anf??1,0?anf??1,1??anf??1,nf??1????????=Softmax(E′)=??????Softmax(e0,0?;e0?)0?0?Softmax(e1,0?;e0?)Softmax(e1,1?;e1?)?0??????Softmax(enf??1,0?;enf??1?)Softmax(enf??1,1?;enf??1?)?Softmax(enf??1,nf??1?;enf??1?)????????
得到上下文矩阵,即自注意力层的输出:
C = [ c 0 , c 1 , … , c n f ? 1 ] = [ v 0 , v 1 , … , v n f ? 1 ] [ a 0 , 0 a 1 , 0 ? a n f ? 1 , 0 0 a 1 , 1 ? a n f ? 1 , 1 ? ? ? ? 0 0 ? a n f ? 1 , n f ? 1 ] \begin{aligned} \boldsymbol{C}&=\left[\boldsymbol{c}_{0}, \boldsymbol{c}_{1},\ldots, \boldsymbol{c}_{n_{f}-1}\right] \\&=\left[\boldsymbol{v}_{0}, \boldsymbol{v}_{1},\ldots, \boldsymbol{v}_{n_{f}-1}\right] \begin{bmatrix}a_{0,0}&a_{1,0}&\cdots&a_{n_f-1,0} \\0 &a_{1,1} &\cdots&a_{n_f-1,1} \\\vdots&\vdots&\ddots&\vdots \\0 &0 &\cdots&a_{n_f-1,n_f-1} \\\end{bmatrix} \end{aligned} C?=[c0?,c1?,…,cnf??1?]=[v0?,v1?,…,vnf??1?]??????a0,0?0?0?a1,0?a1,1??0??????anf??1,0?anf??1,1??anf??1,nf??1?????????
可以看到,使用掩码之后,注意力层的输出 c i \boldsymbol{c}_i ci?只与 v 0 , . . . , v i \boldsymbol{v}_0,...,\boldsymbol{v}_{i} v0?,...,vi?有关
其他跟编码器的是一样的。
以编码器输出作为输入的多头自注意力
解码器第二个多头自注意力与编码器的一样,不过它的 K \boldsymbol{K} K, V \boldsymbol{V} V矩阵不是使用上一层的输出计算,而是使用编码器的最终编码信息计算。
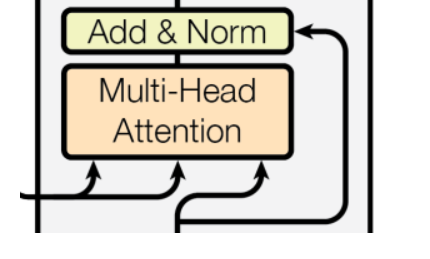
若编码器的最终输出为 Z ( e n c ) \boldsymbol{Z}^{(enc)} Z(enc);上一层输出为 F ( d e c ) \boldsymbol{F}^{(dec)} F(dec),则:
键(Key)矩阵:
K ( l ) = W K ( l ) × Z ( e n c ) \begin{aligned} {\boldsymbol{K}^{(l)}}&={\boldsymbol{W}_K^{(l)}} \times\boldsymbol{Z}^{(enc)} \end{aligned} K(l)?=WK(l)?×Z(enc)?
值(Value)矩阵:
V
(
l
)
=
W
V
(
l
)
×
Z
(
e
n
c
)
\begin{aligned} {\boldsymbol{V}^{(l)}}&={\boldsymbol{W}_V^{(l)}} \times \boldsymbol{Z}^{(enc)} \end{aligned}
V(l)?=WV(l)?×Z(enc)?
查询(Query)矩阵:
Q ( l ) = W Q ( l ) × F ( d e c ) \begin{aligned} {\boldsymbol{Q}^{(l)}}&={\boldsymbol{W}_{Q}^{(l)}} \times\boldsymbol{F}^{(dec)} \end{aligned} Q(l)?=WQ(l)?×F(dec)?
前馈网络
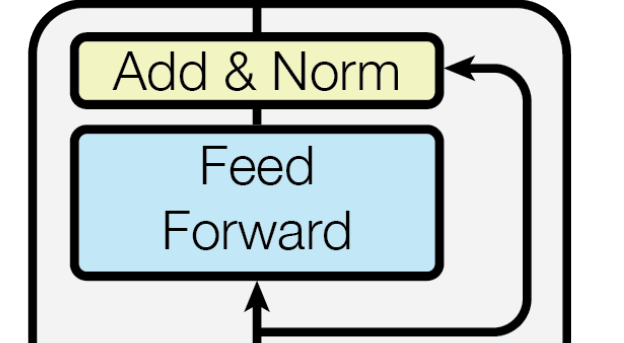
与编码器的相同。
暂时介绍到这里,更多细节可能会在后续的博客展开。
参考:
[1] A General Survey on Attention Mechanisms in Deep Learning https://arxiv.org/pdf/2203.14263v1.pdf
[2] Attention Is All You Need https://arxiv.org/pdf/1706.03762.pdf
[3] 《神经网络与深度学习》 邱锡鹏
位置编码推荐进一步阅读:
[4] https://zhuanlan.zhihu.com/p/454482273
[5] https://blog.csdn.net/qq_43391414/article/details/121061766
[6] https://zhuanlan.zhihu.com/p/106644634
[7] https://kazemnejad.com/blog/transformer_architecture_positional_encoding/