֮ǰ�����д��һ���ٴ�Ԥ��ģ��:R���ݷ���:����top�ڿ��ְ��ֽ�����һ���ٴ�Ԥ��ģ��,������ʵ���DZȽϻ�����ģ���б�����discrimination��һЩָ��,��ô������ٽ�һ��,����ҷ���һЩ���ٴ�����ʵ����ص�ָ��,��Ҫ��Уcalibration�;�������Decision curve analysis��
����
��Ԥ��ģ�Ͷ�Ӧ�ñ���У���ߵ�:
Reporting on calibration performance is recommended by the TRIPOD (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis) guidelines for prediction modeling studies
�ȸ���ҽ���,Ԥ��ģ��Ϊʲô������Ҫdiscrimination��һЩָ����(����tp,tn,fp,fn,roc,LR+,LR-�ȵ�)����Ҫ��У����:
Clinical predictive model performance is commonly published based on discrimination measures, but use of models for individualized predictions requires adequate model calibration
����Ϊ:��Щָ����������������,�������ڹ���ϵ������,���ֵúܺá���ô����Ԥ��ģ����û����,�Ҳ�����?�ô���ʺš�
in contrast to discrimination, which refers to the ability of a model to rank patients according to risk, calibration refers to the agreement between the estimated and the ��true�� risk of an outcome
��Ȼ�Ǹ���Ҿ�����˵��:һ�����ֶȺܺõ�Ԥ��ģ��,AUC�ܸ�,���ģ����������ij��������������Ԥ��մ���ģ��,�������������ģ��Ԥ��ȫ������������,���ְ���ģ�͵�Ԥ����,����������40%�������˵óմ�,�����ղ����������������մ�������ֻ��10%���������һ������ϵ�ģ�߹���ַ��յ�����(���Ⲣ����������ѵ�������б��ֵĺܺ�),�������ģ�Ͳ����á�
When predictive models are built based on a population that differs from the population in which they will be used, blind application of these models could result in large ��residuals�� (ie, a large difference between a model��s estimate and the true outcome) because of factors that are difficult to account for.
��α�ʾģ�͵���������(Ԥ��ֵ��ʵ��ֵƫ��)�����س̶�,����˵�������ģ���ܲ�����,�ܲ��ܻ�������ҲԤ���,��Ҫ����ģ�͵�У��,����������Ҫ����ģ�͵�У���ߡ�
��������Ҫ���ľ��ǶԱ�ģ��Ԥ����ʺ۲���ʵ�һ���ԡ���Ϊ������ƾģ�͵�Ԥ������жϾ��岡�������Ե�,����ҵ�ģ�ͱ��ֺ�,����������0.5��Ԥ����ʻ�������,���ģ�ͱ��ֺ�,�Dz���Ӧ��100��Ԥ�������0.5���˻���50����?����һ������,����������0.3��Ԥ����ʻ�������,���ģ�ͱ��ֺ�,�Dz���Ӧ��100��Ԥ�������0.3���˻���30����?
��������ҵ�ģ�͵�У�Ⱥ�,�Dz��ǾͲ��ᷢ���Ҹովݵijմ�Ԥ���������,����˵:
Calibration plot is a visual tool to assess the agreement between predictions and observations in different percentiles (mostly deciles) of the predicted values.
У���߿���˵��ģ�ͱ��ֵ���һ������:Performance can further be quantified in terms of calibration (do close to?x?of 100 patients with a risk prediction of?x% have the outcome?)
�������ģ�͵Ľ�������������ģ�ͱ��ֵ�����,�������������������ǵ�Ԥ��ģ��Ԥ�������Y��������ʵ��Y֮�������ԽСԽ��,������ǵĽ�ֱ�������������,��ô�������Ԥ���yֵ��ʵ��yֵ�IJ�,�������Ƕ����������ô����������Ը���p��ʵ��p�IJ�:
The distance between the predicted outcome and actual outcome is central to quantify overall model performance from a statistical modeler��s perspective 32. The distance is Y ?? for continuous outcomes. For binary outcomes, with Y defined 0 �C 1, ? is equal to the predicted probability p, and for survival outcomes it is the predicted event probability at a given time (or as a function of time)
������ϵ��,������ǽ�ģ��Ԥ����ʷ��ں���,ʵ�ʸ��ʷ�������,һ��������Ԥ��ģ�͵Ľ�������Ӧ����һ��45�����Ϲ�0��ֱ��(Ideal),��ζ��ģ��Ԥ����ʺ�ʵ�ʸ�����ȫ�Ǻϡ����������������п����Ľ�������һ������ͼ���ӵ�:
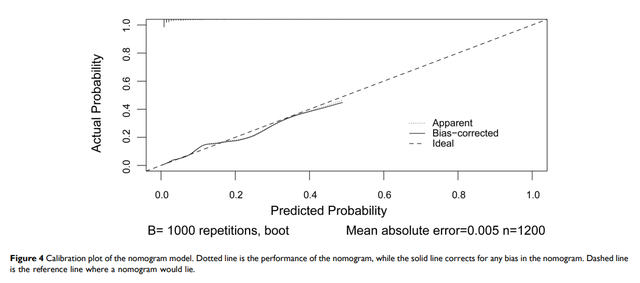
ͼ�е�Ideal�߸ո��Ѿ�������(�������������ģ��Ԥ���ʵ����ȫһ��),ͼ�л�����Apparent�ߺ�Bais-corrected��,�������߾ͱ�ʾ�Լ���ģ�͵ı���,Apparent�����е���˼���Լ���ѵ���ı��ֶ�Bais-corrected�߱�ʾ��������������������ѵ������ģ�ͱ���,������˹�������(����һ������:Apparent��Ϊ�ڲ�����,Bais-corrected��Ϊģ�͵��ⲿ��������,�ⲿ������ô����,��������������)���˴����þ���,���������ĵ��жԽ������ߵ�����ͨ��Ҳ����һ�仰:

���Դ��ֻҪ����ס,����һ��,�����߶���Ideal�ߵ���Χû��ƫ���̫���Ϳ��ԡ�
���Ͼ���ģ��У�Ļ���֪ʶ,���ݴֲμ�����:
Yingxiang Huang, Wentao Li, Fima Macheret, Rodney A Gabriel, Lucila Ohno-Machado, A tutorial on calibration measurements and calibration models for clinical prediction models, Journal of the American Medical Informatics Association, Volume 27, Issue 4, April 2020, Pages 621�C633, https://doi.org/10.1093/jamia/ocz228
DCA����ԭ������
����һ����Ϸ����Ƿ����,һ������ROC����,����AUC������,ROCֻ�ǴӸ÷����������Ժ������Կ���,�����ȷ�����ٴ�����Ҫ��Ԥ���������Dz�����Ҫ��ȡ��Ԥ,ȷ���㹻����?ȷ�Ƚϸߵ�����¾�һ��Ҫ����ģ��Ԥ�������и�Ԥ��?��Ԥ���߾�һ��������?Ҳ�ô���ʺš�
����ģ��Ԥ����ȷ,Ҳ���ܰٷְ�ȷ,ʼ���м����Ժͼ����Դ���,����ȴҪ����ģ�͵�Ԥ����ȥ��Ԥ����,���������һ����Ԥ����������������:˵���پ����,������ͨ��ij�������־��Ԥ����Ƿ���ij��,����ѡȡ�ĸ�ֵΪ�ٽ�ֵ,�������������ԵĿ���,�����ԵIJ���Ҳ����ܸ�Ԥ(����ʵ�ǿ����),����ϣ���Լ���������Ԥ��ģ�����ٴ�ʹ����,���κ�ʱ������ģ�ͽ�����и�Ԥ�����涼��Ĭ�ϵĺ�(�����Ĭ���������ȫ��Ԥ��ȫ����Ԥ)��
��ô��������Ҫ�ɵ�������ɶ?���ǽ�����ģ��Ԥ�ľ������Ĭ�Ϸ���(ȫ��Ԥ�Ͳ���Ԥ)��Ԥ�ľ�������бȽ�:
In brief, decision curve analysis calculates a clinical ��net benefit�� for one or more prediction models or diagnostic tests in comparison to default strategies of treating all or no patients.
�е�����,ʲô�Ǿ�����?
�ø�Ԥ������,��Ԥ��ģ����,������ȫ��Ԥ�������(ȫ����Ⱥ����Ԥ),����ʹ�����ֲ���ʱ�������Ӧ����true positives��false negatives,���ǵĴ��۾���false positives��true negatives,��ʱ�����ȥ���۾ͽ���������:
In the case of diagnosis, the income is true positives (e.g., finding a cancer) and the expenditure is false positives (e.g., unnecessary biopsies), with the ��exchange rate�� being the number of false positives that are worth one true positive. The exchange rate will depend on the relative seriousness of the intervention and outcome. For instance, we will be willing to conduct more unnecessary biopsies to find one cancer if the biopsy procedure is safe vs. dangerous or the cancer is aggressive vs. more indolent. The exchange rate is calculated, as explained above, from the threshold probability. Another analogy is with net health benefit or net monetary benefit, which both depend on the willingness to pay threshold in their exchange of benefits in terms of health and costs
��ʵ������������Dz��Ͻ�,�ٴ����߿����Dz���ʩ�Ӹ�Ԥ,�϶���Ҫ���Ǹ�Ԥ������Σ����,���������Ԥ��ȫ�ǶԲ�������,��ô�붼������,�������߶�ʮһ,���㲡��ֻ��0.1�ĸ��ʻ���,��ҲҪ�Ѹ�Ԥֱ�Ӹ�����,��Ϊ��Ԥû���
���Ǹ�Ԥ���ڸ����õ�ʱ��,���ǿ�������ôһ�������ϵ:���ٸ������Եĸ�Ԥ�����ֵܵ���һ�������Եĸ�Ԥ��ʧ?
�ص����ǵ�ʵ������:�������ģ������,���˻����ĸ�����100%,��һ���������ʩ�Ӹ�Ԥ,��������!���ģ�����Ҳ��˻����ĸ�����98%,�ҹ�����Ҳ������Ԥ����(���������Ԥ��һ��Σ��),��ô���ģ�����Ҳ��˻����ĸ�����90%,��Ԥ���Dz���Ԥ��?���ʱ���ҾͲ�֪����,�е�����
����˵����Ӧ�ø�Ԥ,��ô��������¶�:
���ǹ����ľ��������(�����ұ�����֪��):һ�������ú�ǿ�ĸ�Ԥ,�������Բ��˸�Ԥ�Ļ����Ƕ����Բ��˸�Ԥ��ʧ��1/9(��Ԥ������ʧ�Ǹ�Ԥһ�������Ի����9��),��һ����������Ҹ�Ԥ���Բ���9���˵Ļ����Ԥ��1�����Բ��˵���ʧ���Ե�������ʱ���ģ������,ij�������Եĸ�����90%,������Բ��������и�Ԥ?
�ش���!
�������������������,�������ʱ��ԤҲ��,��Ϊ����ʱ���Ԥ����������ʵ��û�������(����ģ���������IJ��ĸ��ʴﵽ90%,0.9*1/9=(1-0.9)*1)��
����ġ����Եĸ�����90%���е�90%�ͽ����и���(Threshold Probability),��ʾ����ֻ�в��˵�Ԥ����ʳ�������и���,��Ԥ��������,��ֵ�ø�Ԥ:
threshold probabilities, defined as the minimum probability of disease at which further intervention would be warranted, as net benefit = sensitivity �� prevalence �C (1 �C specificity) �� (1 �C prevalence) �� w where w is the odds at the threshold probability
����и��ʱ��������Dz�֪����,�������ǹ��ĵ����Dz������ǵ�ѵ��������ģ�����κ��и�������¶����������,����ֵ��Ӧ�õ�,�����DCA����Ҫ�������ǻش�����⡣
�������Ҽ�ס:��������Ҫ�����Ķ���������Ԥ��ģ�ͻ�����ij������,����Ҫ������ģ�ͽ�����и�Ԥ�ľ����档
���ǻ����ٿ�һ��DCA����:
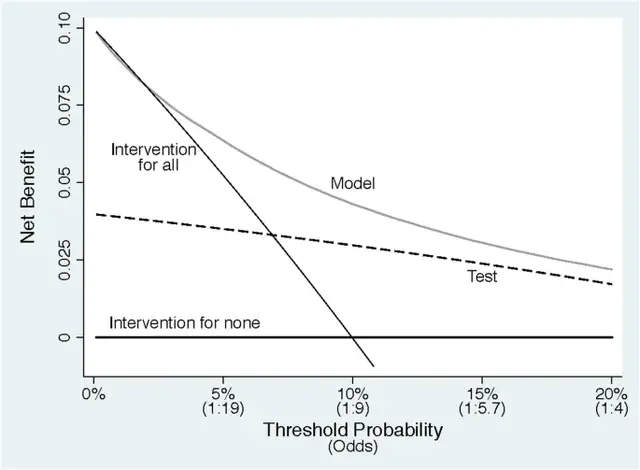
DCA���ߵĺ������и���,�����Ǿ�����,���Կ����и�����DCA������չʾ�Ķ��DZȽ�С��,�ոո���Ҿٵ�������ʵ�е㼫���ˡ��ٻع�һ�¾�����,�ո�д���������˼����ȷʶ������,����ģ����ʵ������ʧ����(���Ǵ����ʶ��������),��Ϊ�����������Ǿ͵ý��и�Ԥ,���Ǹ�Ԥ��û���洦,�ñȽ���������------���������ԵĻ���ͼ����Ե���ʧ,��������ͽ��������档
����DCA���߾Ϳ������������и��ʱ仯,����ģ��Ԥ��ֵ���и�Ԥ������¾�����ı仯��
ע����������һ��������intervention for all��,���Ǽ������,�����˶����и�Ԥ,���ʱ��ֻ�������ԲŻ���,����и��ʴ�С����仯(���Ǹ�Ԥ������ʧ/��Ԥ�Ļ����ֵ��С����仯,���翴ͼ�к����1:19��1:9)��ô�����˶����и�Ԥ���徻����϶���Ӵ�С��,���������и��ʵ�����(��Ԥ����ʧ����/��Ԥ����ı�ֵ������)��ô�������˶����и�Ԥ�ľ�����Ҳ����С(�����Ϊʲôintervention for all��б���Ǹ���)��
ע����������һ��������intervention for none��,���Ǽ������,�����˶������и�Ԥ,���ʱ�������и�����α仯������϶�Ϊ0,�ܺ�����,��Ϊ�㶼����Ԥ��,�����и�Ԥ����ĵ���?������������һֱ��ƽ�ġ�
��intervention for all�������ߺ͡�intervention for none����������һ������,����˵��ij���и���ˮƽ��,�������Բ��˲�ȡȫ��Ԥ��ȫ����Ԥ�ľ����涼��һ����,����ոո����д�����ӷ�����:�����Ԥһ�������Բ��˵Ļ�����9,��Ԥһ�������Բ��˵���ʧ��1,��ʱ�и���Ӧ��Ϊ1/(9+1)=0.1,����˵������������и���Ϊ0.1��ʱ�������߾ͻ��ཻ��
�ڻ���˼ά�ٸ���Ҿٸ�����,���ڼ�����֪����Ԥ�����Ⱥ��ij��������Ϊ0.2,ij��Ԥ�����ĸ�Ԥ�����Ե�������8,��Ԥ�����Ե���ʧ��2,��ô��ʱ��Ӧ���и���Ϊ2/(2+8)=0.2,��ʱ����ȫ��Ԥ���Եľ�����Ϊ0.2*8-2*0.8=0,��ʱ�������ཻ��
ͨ��������������,Ӧ�ô�ҾͿ���������:���и��ʵ����о���Ⱥ�����ʵ������,�������ཻ,Ҳ����ȫ��Ԥ���Եľ�����Ϊ0��
����IJ�������˼·��Դ������,����Ȥ��ͬѧ���黹��ȥ�Ķ�ԭ��Ŷ:
Vickers, A.J., van Calster, B. & Steyerberg, E.W. A simple, step-by-step guide to interpreting decision curve analysis. Diagn Progn Res 3, 18 (2019). https://doi.org/10.1186/s41512-019-0064-7
��ζ�DCA����
�ٻص���ͼ����һ��DCA���ߵij�������,����������߽�Ԥ��ģ�ͺ�����һ����⼼��test,������һ��ͼ��,��ô��ô��ͼ��?
����ͼ������ʵ����������˵����,һ��������intervention for all��,��һ������"intervention for none",�ոս������ǵ���˼�ˡ�
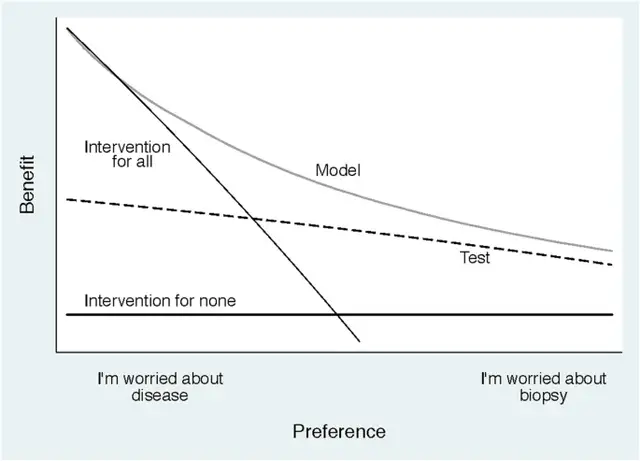
���Դ�ͼ�п���,�����и��ʵ�����,ģ�͵ľ�������½�(����ȷ��˵���Ǹ���ģ�ͽ�����и�Ԥ�ľ�������½�),���Ƕ�������ѵ����Model����,����Model��Ԥ�������и�Ԥ�Ļ�,�����и��ʺ�С�������,��������и���������ģ�͵ı��ֶ��DZȽϺõ�,����ģ�ͱ���ʼ�ձ�test�á�
����Ԥ��ģ��֮��,���ǰ����ͼ��������,���൱�ڸ��༭˵�������������Ԥ��ģ��ȷʵ��,ȷʵ�����еļ�⼼������,�Ͻ�����������,�������DCA���ߡ�
Hence, we can conclude that, except for a small range of low preferences, intervening on (i.e., biopsying) patients on the basis of the prediction model leads to higher benefit than the alternative strategies of biopsying all patients, biopsying no patients, or only biopsy those patients who are positive on the diagnostic test. For the prostate biopsy study, the conclusion is that using the model to determine whether patients should have a biopsy would lead to improved clinical outcome.
��
�������ҽ������ٴ�Ԥ��ģ���н������ߺ;������ߵ�����(����2������Ϊ��),��������ǽ�����һ��д��,����д��̫����,�ַ�������,�Ǿͷ�Ϊ2�ڰ�,���ھͳ�ʵ��,ϣ���Դ����������