1���������
1.1 ʲô�Ǿ���
??������ǰ����ݶ��ϰ��������Ի��ֳɶ���Ӽ��Ĺ���(����ͼ)������,ÿ���Ӽ���Ϊһ���ء������Ҫʹ���еĶ���˴�����,����Ҫ���������еĶ����������������ලѧϰ,���ݲ���Ҫ����(��ע)��Ϣ��

?? ������������ƶ�Ϊ����,��һ�������е�ģʽ�Ȳ�����������е�ģʽ�и�������ƶȡ�
1.2 ���������
??�������мලѧϰ,��ÿ��ѵ�����������ݶ����Ѿ������ǩ,ͨ���б�ǩ����ѧϰ��������
??�������ලѧϰ,����ʹ��ѵ�����ݽ���ѧϰ,ͨ���۲�ѧϰ�����ݼ��ָ�ɶ���ء�
1.3 �����Ӧ��
- ��ҵ����:����������ڷ��ֲ�ͬ�Ŀͻ�Ⱥ,����ͨ������ģʽ�̻���ͬ�ͻ�Ⱥ��������
- ��������:������������������Ϊ�Ŀͻ�,�������ͻ��Ĺ�ͬ����,���Ը��õذ�������������û��˽��Լ��Ŀͻ�,��ͻ��ṩ�����ʵķ���
- ������:�����ȵ㡢���塢���⡢�¼�,����δ֪�쳣�ȡ�
2�������ľ����
2.1 ���ַ���
2.1.1 ���ַ�������
���ַ�����ָ����n����������ݼ�D���ֳ�k(k<=n)����,��������������:
- ÿ�������ٰ���һ������
- ÿ�����������ҽ�����һ���ء�
??�����˼�������ȴ���һ����ʼk����(kΪҪ����Ļ�����),Ȼ�ϵ�����������صľ�������,�������µľ������ĵ����������,ֱ��������
���ַ�����Ŀ��������:
- ͬһ�����еĶ���֮�価���ܡ��ӽ��������
- ��ͬ���еĶ����ܡ�ԭ������ͬ��
����ʽ����������:
- K��ֵ(K-Means),ÿ�����øô��ж���ľ�ֵ����ʾ,Ϊ�������ĵļ�����
- K���ĵ�(K-Medoids),ÿ�����ýӽ������ĵ�һ����������ʾ,Ϊ���ڴ�������ļ�����
��Щ����ʽ�㷨�ʺϷ�����С��ģ���ݿ��е���״����;���ڴ��ģ���ݿ�ʹ���������״�ľ���,��Щ�㷨����Ҫ��һ����չ��
2.1.2 K-Means�㷨
??K-Means�㷨������ʽ�㷨,��ѭѰ��ԭ��(����ͼ),��ÿ�ξ��ౣ֤�ֲ�����,����������,���þֲ����ž�������������ϱƽ�ȫ�����š�

�����㷨��������:
- (1)�����ݼ������ȡK��������Ϊ��ʼ�ľ������� C = c 1 , c 2 , . . . , c k C={c_1,c_2,...,c_k} C=c1?,c2?,...,ck?��
- (2)������ݼ��е�ÿ������ x i x_i xi?,��������K���������ĵľ��벢����ֵ�������С�ľ������Ķ�Ӧ�����С�
- (3)���ÿ����� C i C_i Ci?,���¼������������ c i = 1 �O c i �O �� x �� c i x c_i=\frac{1}{\left | c_i \right | } \sum_{x\in c_i }^{x} ci?=�Oci?�O1?��x��ci?x?
- (4)�ظ���2���͵�3��,ֱ�� �� i = 0 n m i n c j �� C ( �� x j ? c i �� 2 ) \sum_{i=0}^{n}\underset{c_j\in C }{min}(\left \| x_j-c_i \right \|^2 ) ��i=0n?cj?��Cmin?(��xj??ci?��2)

2.1.3 K-means����ʵ��
??��1:��������Ҫ���о���Ķ���:{2,4,10,12,3,20,30,11,25},K= 2,��ʹ��K��ֵ���־��ࡣ������㲽������:
| m 1 m_1 m1? | m 2 m_2 m2? | K 1 K_1 K1? | K 2 K_2 K2? |
|---|---|---|---|
| 2 | 4 | {2,3} | {4,10,12,20,30,11,25} |
| 2.5 | 16 | {2,3,4} | {10,12,20,30,11,25} |
| 3 | 18 | {2,3,4,10} | {10,12,20,30,11,25} |
| 4.75 | 19.6 | {2,3,4,10,11,12} | {20,30,25} |
| 7 | 25 | {2,3,4,10,11,12} | {20,30,25} |
??��2:�ٶ����Ƕ�A��B��C��D�ĸ���Ʒ�ֱ�������������͵õ�����������Խ����е���Ʒ�۳����ࡣ

??��һ��:��Ҫ��ȡK=2,Ϊ��ʵʩ��ֵ������,���ǽ���Щ��Ʒ����ֳ�����,����(A��B)��(C��D),Ȼ������������������������,���±���ʾ��
??����������ͨ��ԭʼ���ݼ�������ġ�

??�ڶ���:����ij����Ʒ���������ĵ�ŷ��ƽ������,Ȼ����Ʒ����������һ�ࡣ������Ʒ�б䶯����,���¼������ǵ���������,Ϊ��һ�������������ȼ���A���������ƽ������:
d
2
(
A
,
(
A
B
)
)
=
(
5
?
2
)
2
+
(
3
?
2
)
2
=
10
d
2
(
A
,
(
C
D
)
)
=
(
5
+
1
)
2
+
(
3
+
2
)
2
=
61
d^2(A,(AB))=(5-2)^2+(3-2)^2=10\\ d^2(A,(CD))=(5+1)^2+(3+2)^2=61
d2(A,(AB))=(5?2)2+(3?2)2=10d2(A,(CD))=(5+1)2+(3+2)2=61
??����A��(A��B)�ľ���С�ڵ�(C��D)�ľ���,���A�������·��䡣����B�������ƽ������:
d
2
(
B
,
(
A
B
)
)
=
(
?
1
?
2
)
2
+
(
1
?
2
)
2
=
10
d
2
(
B
,
(
C
D
)
)
=
(
?
1
+
1
)
2
+
(
1
+
2
)
2
=
9
d^2(B,(AB))=(-1-2)^2+(1-2)^2=10\\ d^2(B,(CD))=(-1+1)^2+(1+2)^2=9
d2(B,(AB))=(?1?2)2+(1?2)2=10d2(B,(CD))=(?1+1)2+(1+2)2=9
??����B��(A��B)�ľ�����ڵ�(C��D)�ľ���,���BҪ�����(C��D)��,�õ��µľ�����(A)��(B��C��D)�� ���������������±���ʾ��

??������:�ٴμ��ÿ����Ʒ,�Ծ����Ƿ���Ҫ���·��ࡣ�������Ʒ�������ĵľ���ƽ��,������±���

??������Ϊֹ,ÿ����Ʒ���Ѿ���������������������,��˾�����̵��˽��������յõ�K=2�ľ�������A���Գ� һ��,B��C��D�۳�һ�ࡣ
2.1.4 K-means�Ľ��㷨
(1)K-Mode�㷨
- ����������ƽ����
- ʹ���µ������Զ�����
(2)K-means++�㷨
??ͨ��������ѡ�����Զ�õ���Ϊ��ʼ���ӽڵ�,�Ӷ����K-means��ʼ��ѡ�����⡣������㷨��������:
- ����������ݵ㼯�������ѡ��һ������Ϊ��һ����������
- �������ݼ��е�ÿһ����X,��������������ĵľ���D(X)
- ѡ��һ��D(X)���ĵ���Ϊ�µľ�������
- �ظ�2��3��ֱ��K���������ı�ѡ��
- ����K����ʼ������������K-Means
(3)K���ĵ�(K-Mediods)�㷨
??K���ĵ���Ҫͨ��ѡ�ô���λ�������ĵ�ʵ�ʶ��������ĵ���Ϊ���յ㲢������С�����ж���������յ�֮��������֮�� E = �� i = 1 k �� p �� C i �O p ? o i �O E=\sum_{i=1}^{k}\sum_{p\in C_i}^{} \left |p-o_i \right | E=��i=1k?��p��Ci??�Op?oi?�O����(ʹ�þ�������),�����Ⱥ���������⡣

2.2 ����
2.1.1 ��������
����������������:
- �Ը������ݶ����в�εķֽ�
- ʹ�þ��������Ϊ�����
- ����Ҫ���������Ŀk,����Ҫ��ֹ����
�����ֲ�η���:
- (1) �Ե����Ϸ���(����):��ʼ��ÿ��������Ϊ������һ����,Ȼ����̵ĺϲ�����Ķ�����,ֱ�����еĴغϲ�Ϊһ��,���ߴﵽһ����ֹ�����������㷨:AGNES�㷨
- (2) �Զ����·���(����):��ʼ�����еĶ�������һ������,�ڵ�����ÿһ��,һ���ر�����Ϊ�����С�Ĵ�,ֱ������ÿ��������һ�������Ĵ���,��ﵽһ����ֹ�����������㷨:DIANA�㷨

3�������ܶȵķ���
3.1 ��ظ���
??�����ܶȾ�����ָ�����ܶ��������ڽ���������γɴ�,�ص��������߸��������ܶ�,���߸����ض����ܶȺ���(ֻҪ�ٽ�������ܶȳ���ij����ֵ,�ͼ�������)
��Ҫ�ص�:
- ����������״�ľ���
- ��������
- һ��ɨ��
- ��Ҫ�ܶȲ�����Ϊ��ֹ������
??��-����:��������뾶���ڵ������Ϊ�ö���Ħ�-����

??���Ķ���:�������Ħ�-�������ٰ�����С��ĿMinPts������,��Ƹö���Ϊ���Ķ���
??ֱ���ܶȿɴ�:��������D,���p ����q �Ħ�-������,��q �Ǻ��Ķ���,��ƶ���p �ǴӶ���q ���ڦź�MinPtsֱ���ܶȿɴ�ġ�

??�ܶȿɴ�:�������һ�������� p 1 , . . . , p n , p 1 = q , p n = p p_1,...,p_n,p_1=q,p_n=p p1?,...,pn?,p1?=q,pn?=p,ʹ�� p i + 1 p_{i+1} pi+1?�Ǵ� p i p_i pi?ֱ���ܶȿɴ��,��ƶ���p�ǴӶ���q���ڦź�MinPts(���)�ܶȿɴ��.
??�ܶ�����:������ڶ���o ʹ��,p ��q ���Ǵ�o���ڦź�MinPts�ܶȿɴ��,��ƶ���p��q���ڦź�MinPts���ܶ�������

4����������
??��������ּ�ڹ��������ݼ������о���Ŀ����Ժͱ�����������Ľ������������Ҫ����:���ƾ������ơ�ȷ�����ݼ��еĴ������ⶨ����������
4.1 ���ƾ�������
??���ڸ��������ݼ�,�������ƹ���ȷ�����������ݼ��Ƿ���п��Եõ�������ľ���ķ�����ṹ��������ݷ��Ӿ��ȷֲ�,��Ȼ������еľ����������û������ġ�
??���ս�˹ͳ������һ�ֿռ�ͳ����,���Լ���ռ�ֲ��ı����Ŀռ�����ԡ�
4.2 ȷ�����ݼ��еĴ���
??K��ֵ�������㷨��Ҫ���ݼ��Ĵ�����Ϊ����,����Ҳ���Կ������ݼ���һ����Ҫ�ĸ�������,���,��ʹ�þ����㷨������ϸ�Ĵ�֮ǰ,���ƴ����ǿ�ȡ�ġ�
- ʵ�鷽��:����n��������ݼ�,���� n 2 \sqrt{\frac{n}{2} } 2n??,ÿ����Լ�� 2 n \sqrt{2n } 2n?���㡣
- �ⷽ��(Elbow method):���Ӵ������Խ��ʹ��ڷ���֮��,��������γ�̫��Ĵ�,���ʹ��ڷ���֮�͵ı�ԵЧӦ�����½���
4.3 ���������Ķ���
??һ�����,�����Ƿ��л�(��ר�ҹ���������ľ���),�����������IJⶨ��Ϊ���ڷ��������ڷ��������ڷ���ͨ���ȽϾ������ͻ����о��������ⶨ�����ڷ���û�п��õĻ�,��ͨ���صķ��������������ĺû���
4.3.1 ���ڷ���
??���������(���ء����ȡ����ȡ��ٻ��ʺ�F����)������������ģ�͵����ܡ����ڷ���,����Ԥ���������ʵ�����ŵĶ�Ӧ�̶ȡ�������Щ����ͨ��ʹ�ôر�Ŷ�����Ԥ�������,����Ҫ���ϴ�ĸı䡣
??����������Ҫ��������ϵ������������ϵ����
??����ϵ��(Rand Index,RI)����Ϊ:
R
I
=
a
+
b
C
2
n
s
a
m
p
l
e
s
RI=\frac{a+b}{C_2^n samples}
RI=C2n?samplesa+b?
a��ʾ��ʵ�������Ϣ��������ж���ͬ����Ԫ�ض���,
b��ʾ��ʵ�������Ϣ��������ж��Dz�ͬ����Ԫ�ض���,
��ĸ��ʾ���ݼ��п�����ɵ���Ԫ�ض�����
??����ϵ����ֵ��[0,1]֮��,������������ƥ��ʱ,����ϵ��Ϊ1������������,RI�����ܱ�֤�����ӽ��㡣
??Ϊ��ʵ�֡��ھ�������������������,ָ��Ӧ�ýӽ��㡱,��������ϵ��(Adjusted rand index)�����,�����и��ߵ����ֶȡ�

??ARIȡֵ��ΧΪ[-1,1],���������������,ֵԽ����ζ�ž���������ʵ���Խ�Ǻϡ�ARI�����ھ����㷨֮��ıȽϡ�

4.3.2 ���ڷ���
??���ڷ�������û�л�����ʱ�ľ�����������,ͨ������صķ�������ʹصĽ��նȽ��о���������
??����ϵ��(Silhouette Coefficient)��һ��������������������n����������ݼ�D,����D��Ϊk���ء�����ÿ������
o
��
D
o\in D
o��D,����o����������������������ľ���a(o)��o�������������һ���ڵ����е��ƽ������b(o),��o������ϵ������Ϊ:
s
(
o
)
=
b
(
o
)
?
a
(
o
)
m
a
x
{
b
(
o
)
,
a
(
o
)
}
s(o)=\frac{b(o)-a(o)}{max\{b(o),a(o)\}}
s(o)=max{b(o),a(o)}b(o)?a(o)?
??����ϵ����ֵΪ-1~1,a(o)��ӳ����o�����ĴصĽ�����,ֵԽС,��Խ����;b(o)��ӳ����o�������صķ���̶�,ֵԽ��,˵��o��������Խ���롣��o������ϵ���ӽ�1ʱ,����o�Ĵ��ǽ��յ�,����oԶ�������ء�������ϵ��Ϊ��ֵʱ,˵��o���������صĶ���Ⱦ������Ӽ�ͬ�ڴصĶ���������ںܶ����,������Ҫ����ġ�
sklearn��ͨ��sklearn.metrics.silhouette_score()����������������ϵ����
�������������ĸ�ά��:
- �ص�ͬ����
- �ص���ȫ��
- �鲼����
- С�ر�����
5��ʵս
5.1 K-Meansʵ���β������
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn import metrics
iris=load_iris()
X=iris['data']
# ���������
estimator=KMeans(n_clusters=3,random_state=42)
kmeans_pred=estimator.fit_predict(X)
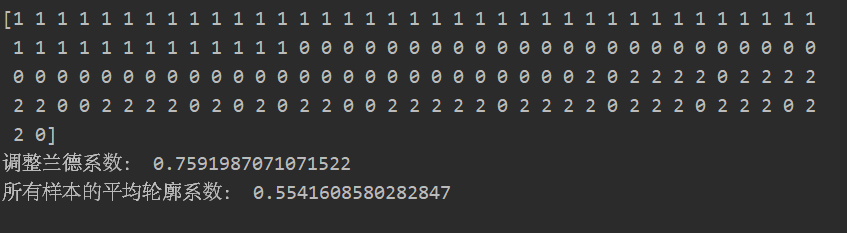
print(kmeans_pred)
# ���ӻ�
x1 = X[kmeans_pred==0]
x2 = X[kmeans_pred==1]
x3 = X[kmeans_pred==2]
plt.scatter(x1[:,0],x1[:,1],s=100,c='red',label='Cluter 1') #ѡ���β�����ݼ���ǰ��������������Ϊ��������
plt.scatter(x2[:,0],x2[:,1],s=100,c='blue',label='Cluter 2')
plt.scatter(x3[:,0],x3[:,1],s=100,c='green',label='Cluter 3')
plt.scatter(estimator.cluster_centers_[:,0],estimator.cluster_centers_[:,1],s=100,c='black',label='Controids')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
# ģ������
# ��������ϵ��
print('��������ϵ��:',metrics.adjusted_rand_score(iris.target, kmeans_pred))
# metric str ��ɵ���,Ĭ��='euclidean'
# ��������������ʵ��֮��ľ���ʱʹ�õĶ�����
print('����������ƽ������ϵ��:',metrics.silhouette_score(X,kmeans_pred,metric='euclidean'))

5.2 ����
from sklearn.cluster import AgglomerativeClustering
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn import metrics
iris=load_iris()
X=iris['data']
clustering=AgglomerativeClustering(linkage='average',n_clusters=3)
kmeans_pred=clustering.fit_predict(X)
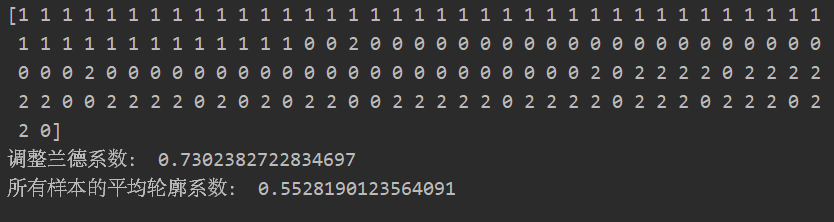
print(kmeans_pred)
# ���ӻ�
x1 = X[kmeans_pred==0]
x2 = X[kmeans_pred==1]
x3 = X[kmeans_pred==2]
print(x1)
plt.scatter(x1[:,0],x1[:,1],s=100,c='red',label='Cluter 1') #ѡ���β�����ݼ���ǰ��������������Ϊ��������
plt.scatter(x2[:,0],x2[:,1],s=100,c='blue',label='Cluter 2')
plt.scatter(x3[:,0],x3[:,1],s=100,c='green',label='Cluter 3')
# plt.scatter(clustering.cluster_centers_[:,0],clustering.cluster_centers_[:,1],s=100,c='black',label='Controids')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
# ��������ϵ��
print('��������ϵ��:',metrics.adjusted_rand_score(iris.target, kmeans_pred))
# metric str ��ɵ���,Ĭ��='euclidean'
# ��������������ʵ��֮��ľ���ʱʹ�õĶ�����
print('����������ƽ������ϵ��:',metrics.silhouette_score(X,kmeans_pred,metric='euclidean'))