����(���)������ƽ��(class-imbalance)ָ���Ƿ��������в�ͬ����ѵ��������Ŀ���ܴ�����,һ���,����������(Imbalance Ratio)(������vs������)���Դ���1:1(��4:1)�Ϳ��Թ�Ϊ��������������⡣
��ʵ��,������ƽ����һ�ֳ���������,��:������թ�����,��թ���Ķ�������ͨ����ռ�ܽ��������ļ��ٲ���,���Ҷ�����Щ�����������������Ϊ��Ҫ�����Ľ���ϸ����������������ƽ����,ϲ���ǵõ��ޡ��ղء���ע��
��ĩ�ṩ��������������

ע:������Ҫ̽�ַ�������������,�ع���������������������Delving into Deep Imbalanced Regression��
������ĸ���Ӱ��
�ܶ�ʱ������������������������ʱ,��ֱ�ӵķ�Ӧ����ȥ�����ơ����ֲ�ƽ�⡣����������������ʲôӰ��?�б�Ҫȥ�����?
����ٸ�����,��һ����թʶ��İ�����,�û�������ռ����1000:1,���������ֱ�����������ȥѧϰģ�͵Ļ�,��Ϊ�ӽ�ȥģ��ѧϰ�������ֶ��Ǻõ�,�ͺ�����ѧ��һ��������������Ԥ��Ϊ�õ�ģ��,��������Ԥ��ĸ���ȷ�ʻ��Ƿdz��ߵġ���ģ������ѧϰ�IJ�������ηֱ�û�,����ѧϰ���ˡ��� Զ�� ���Ķࡰ������������Ϣ,ƾ�������Ϣ�������������ж�Ϊ���á��Ϳ����ˡ������ͱ�����ģ��ѧϰȥ�ֱ�û��ij����ˡ�
����,��������������ĸ���Ӱ����:ģ�ͻ�ѧϰ��ѵ����������������������������Ϣ,������ʵ��Ԥ��ʱ�ͻ�Զ�������в���(���ܵ��¶����ྫ�ȸ���,��������Ƚϲ�)������ͼ(ʾ���������:github.com/aialgorithm),���������µķ���߽��ƫ����ռ���������������Ҫ��һ��,���Ӱ��ģ��ѧϰ�����ʵ�����,Ӱ��ģ�͵�³���ԡ�

�ܽ�һ��Ҳ����,����ͨ���������������,���Լ���ģ��ѧϰ����������������Ϣ,�Ի����ѧϰ�����û�����������ģ����
1.3 �жϽ��������ı�Ҫ��
�ӷ���Ч������,ͨ����������ӿ�֪,��������ڷ�������Ӱ�첻һ���Dz��õ�,��ʲôʱ����Ҫ�������������?
-
�ж������Ƿ���:���Ӷ�ѧϰ����ĸ��Ӷ���������ƽ������ж��dz����ȵ�**(�μ���Survey on deep learning with class imbalance��),���ڼ����Կɷ�����,�����Ƿ����Ӱ�첻����Ҫע�����,ѧϰ����ĸ��Ӷ�����������ϵ�,�ô�����ǿ����������������Լ�ģ�������ȷ����ۺ�������
-
�ж�ѵ�������ķֲ�����ʵ�����ֲ��Ƿ�һ�����ȶ�,����ֲ���һ�µ�,����������ȷ��������Ԥ����Ӱ�첻����,����Ҫ���ǵ�,���������ʵ�����ֲ�����,�������������������и������ˡ�
-
�ж��Ƿ����ijһ���������Ŀ�dz�ϡ�ٵ����,��ʱģ�ͺ��п���ѧϰ����,���������Ҫ�����,��ѡ��һЩ������ǿ�ķ���,���߳������쳣���ĵ�����ģ�͡�
����������������
������,��ѧϰ������Щ�Ѷȵ�ǰ����,���������������Թ��Ϊ:ͨ��ij�ַ���ʹ�ò�ͬ������������ģ��ѧϰ�е�Loss(���ݶ�)�����DZȽϾ������������ģ�ͶԲ�ͬ����ƫ����,ѧϰ����Ϊ���ʵ����������Ĵ�����������ģ���㷨��Ŀ��(��ʧ)����������ָ���ȷ���,�Ը��еĽ����������̽�֡�
1 ��������
1.1Ƿ������������
��ֱ�ӵĴ�����ʽ�������������ĵ�����,���õĿ���:
-
Ƿ����:���ٶ����������(�����Ƿ������NearMiss��ENN)��
-
������:�����������������ĵ���������(��������������Լ�2.1.2������ǿ����),�Դﵽ������Ŀ���⡣
-
���ɽ����������ϲ���(��Smote+ENN)��
���廹���Բμ���scikit-learn��imbalanced-learn.org/stable/user_guide.html�Լ�github��awesome-imbalanced-learning��
1.2 ������ǿ
������ǿ(Data Augmentation)���ڲ�ʵ���Ե��������ݵ������,��ԭʼ���ݼӹ����������ݵı�ʾ,���ԭ���ݵ�����������,�Խӽ��ڸ��������������ļ�ֵ,�Ӷ����ģ�͵�ѧϰЧ���������оٳ��õķ���:
- ���������任��������ǿ
�����任������ǿ������Ԥ������ݱ任��������������ݵ�����,����������������ǿ�Ͷ�����������ǿ��
��������ǿ(��Ҫ����ͼ��):��Ҫ�м��β�������ɫ�任��������������������ȷ��������µ�����,�ɲμ�imgaug��Դ�⡣
��������ǿ:��ͨ����ϼ�ת���������,��Ҫ��Smote��(�ɼ�imbalanced-learn.org/stable/references/over_sampling.html)��SamplePairing��Mixup�ȷ����������ռ��ڹ�����֪����������ֵ������
- �������ѧϰ��������ǿ
����ģ�������Ա�������(Variational Auto-Encoding network, VAE)�����ɶԿ�����(Generative Adversarial Network, GAN),�����������ķ���Ҳ��������������ǿ�����ֻ�������ϳɵķ�������ڴ�ͳ��������ǿ������Ȼ���̸��Ӹ���, �������ɵ��������Ӷ�����
��������������������ķ���,��Ҫ��ע����:
-
���Ƿ�������ܻᵼ�¶���������Ҫ��Ϣ���������ڼ��������㹻��,���Կ������ݵķֲ���Ϣ(ͨ���ǻ��ھ���������ϵ)�IJ�������,��ENN��NearMiss�ȡ�
-
�����������������ǿ����Ҳ�п�����ǿ��(������)Ƭ������,���¹���ϡ�Ҳ������������Ϣ���������������ʱ��Ҫ���ǵ��ǵ�����������,����ͨ����ල�㷨(�ɽ��Pu-Learning˼·)ѡ����ǿ���ݵ������Ӽ�,�����ģ�͵ķ���������
2.2 ��ʧ�����IJ���
��ʧ�������������ķ���Ҳ���dz��õĴ�������ѧϰ(cost-sensitive),Ϊ��ͬ�ķ��������費ͬ�ͷ�����(Ȩ��),�ڵ������ƽ���ͬʱ,Ҳ�������Ӽ��㸴�Ӷȡ����³��÷���:
2.2.1 class weight
�����Ҳ����scikitģ�͵ġ�class weight������,If ��balanced��, class weights will be given by n_samples / (n_classes * np.bincount(y)). If a dictionary is given, keys are classes and values are corresponding class weights. If None is given, the class weights will be uniform.,class weight����Ϊ��ͬ���������ṩ��ͬ��Ȩ��(�������и��ߵ�Ȩ��),�Ӷ�ģ�Ϳ���ƽ�������ѧϰ������ͼͨ��Ϊ�����������ߵ�Ȩ��,�Ա������ƫ�ض����������(���Ȩ�س����趨Ϊbalanced,��������Ϊһ������������ʾ���������github.com/aialgorithm):
clf2 = LogisticRegression(class_weight={0:1,1:10}) # ��������ѧϰ

2.2.2 OHEM �� Focal Loss
In this work, we first point out that the class imbalance can be summarized to the imbalance in difficulty and the imbalance in difficulty can be summarized to the imbalance in gradient norm distribution.
�Cԭ�Ŀɼ���Gradient Harmonized Single-stage Detector��
���ĵĴ�����,���IJ�ƽ����Թ��Ϊ���������IJ�ƽ��,�����������IJ�ƽ����Թ��Ϊ�ݶȵIJ�ƽ�����������˼·,OHEM��Focal loss������������:�������ھ��Լ�����ƽ�⡣(������� GHM�� PISA�ȷ���,���������˽�)
-
OHEM(Online Hard Example Mining)�㷨�ĺ�����ѡ��һЩhard examples(�����Ժ���ʧ������)��Ϊѵ��������,����Եظ���ģ��ѧϰЧ�����������ݵ����ƽ������,OHEM������Ը�ǿ��
-
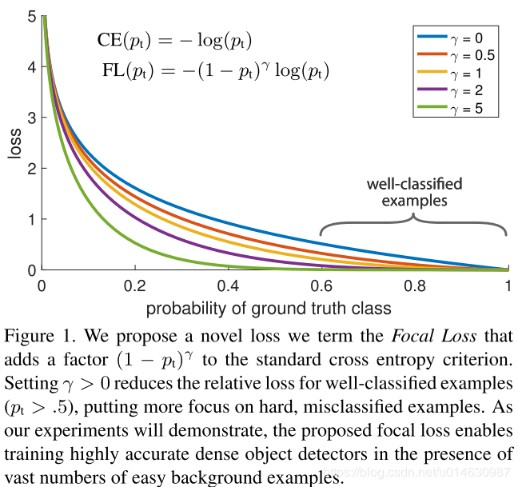
Focal loss�ĺ���˼�����ڽ�������ʧ����(CE)�Ļ��������������IJ�ͬȨ���Լ�����(����ʧ)������Ȩ��(���¹�ʽ),�Ը���ģ��ѧϰЧ����
2.3 ģ�Ͳ���
ģ�ͷ�����Ҫ��ѡ��һЩ�Բ�����Ƚϲ����е�ģ��,����,�Ա����ع�ģ��(lrѧϰ����ȫ��ѵ����������С��ʧ,��Ȼ��Ƚ�ƫ��ȥ���ٶ�����������ɵ���ʧ),�������ڲ�ƽ���������������Ժ�һЩ,��ģ���ǰ�������ݹ�ػ�������(����ͼ),���ֹ��̿��ǵ��Ǿֲ�������,ȫ�������Dz�����,�ֲ��ռ�Ͳ�һ��,���ԱȽϲ�����һЩ(�����ǻ���ƫ����)�����ʵ��ɼ�arxiv.org/abs/2104.02240��

�������������,��Ϊ������ǻ��ڲ���+������ģ�͵ȷ���,����������������ϱ������á�
2.3.1����+����ѧϰ
���������˵,ͨ���ظ���������������������ͬ�������Ķ���������,ѵ�����ɵķ��������м���ѧϰ��
-
BalanceCascade BalanceCascade����Adaboost��Ϊ��������,����˼·����ÿһ��ѵ��ʱ��ʹ�ö���������������������ȵ�ѵ����,Ȼ��ʹ�ø÷�������ȫ����������Ԥ��,ͨ�����Ʒ�����ֵ������FP(False Positive)��,�������ж���ȷ����ɾ��,Ȼ�������һ�ֵ����������Ͷ�����������
-
EasyEnsemble EasyEnsembleҲ�ǻ���Adaboost��Ϊ��������,���ǽ�����������������ֳ� N ���Ӽ�,��ÿһ���Ӽ�������������������ͬ,Ȼ��ֱ��������������Ӽ��������������������,ʹ��AdaBoost������ģ�ͽ���ѵ��,���bagging���ɸ���������,�õ�����ģ�͡�ʾ������ɼ�:www.kaggle.com/orange90/ensemble-test-credit-score-model-example
ͨ��,�����ݼ�������С�������,������BalanceCascade,�����ý��ٵĻ������������õ��Ϻõı���(���ڴ��еļ���ѧϰ����,�����������������)��������������,������EasyEnsemble,���ڴ���+���еļ���ѧϰ����,bagging���Adaboost���̿��Ե���һЩ����Ӱ�졣�����RUSB��SmoteBoost��balanced RF���������ɷ������������˽⡣
2.3.2 �쳣���
���ƽ��ܼ��˵������(����������ֻ�м�ʮ������),���������⿼�dz��쳣���(anomaly detection)������ܻ���á�
�쳣�����ͨ�������ھ����������ݼ��ֲ���һ�µ��쳣����,Ҳ����Ϊ��Ⱥ�㡢�쳣ֵ���ȵȡ��ල�쳣��ⰴ���㷨˼����¿ɷ�Ϊ����:���ھ���ķ���������ͳ�Ƶķ�����������ȵķ���(����ɭ��)�����ڷ���ģ��(one-class SVM)�Լ�����������ķ���(�Ա�����AE)�ȵȡ�

2.4 ��������ָ��
���ڹ�ע���ص���,�����Dz��ò�ƽ������ѵ��ģ��,��θ��þ����Լ��۵�������ƽ�������µ�ģ�ͱ��֡����ڷ��ೣ�õ�precision��recall��F1����������,����������IJ�ͬ�̶�,�������Ըı���Щָ��ı��֡�
�����������ģ�͵�Ԥ��,���ǿ�����������ֵ�ƶ�,�Ե���ģ�Ͷ��ڲ�ͬ���ƫ�õ����(��ģ��ƫ��Ԥ�⸺����,ƫ��0,��Ӧ�����ǵķ�����ֵҲ���µ���),�ﵽ����ʱ���ƽ���Ŀ�ġ�����,ͨ������ͨ��P-R����,ѡ���ű��ֵ���ֵ��
����������µ�ģ������,���Բ���AUC��AUPRC(����)����ģ�ͱ��֡�AUC�ĺ�����ROC���ߵ����,����ֵ������������:�������һ��һ����������,��������Ԥ���ֵ���ڸ������ĸ��ʴ�С��AUC������������������������Dz�����,��ʹ�����븺���ı��������˺ܴ�仯,ROC�������Ҳ���������ı仯��
��:
����ͨ���������������,���Լ���ģ��ѧϰ����������������Ϣ,�Ի����ѧϰ�����û�����������ģ�͡�
���Խ����������������Ϊ:ͨ��ij�ַ���ʹ�ò�ͬ������������ģ��ѧϰ�е�Loss(���ݶ�)�����DZȽϾ���ġ�������Դ�����������ģ���㷨��Ŀ�꺯��������ָ��ȷ�������Ż�,����������ǿ����������ѧϰ������+����ѧϰ�DZȽϳ��õ�,Ч��Ҳ�DZȽ����Եġ���ʵ,������������Ҳ�ǽ��ʵ����������ѡ����ϼ�����,����֤�е��ŵĹ��̡�
�Ƽ�����
��������
��ӭת�ء��ղء������ջ����֧��һ��!���ݡ�����������һ�ȡ

Ŀǰ��ͨ�˼�������Ⱥ,Ⱥ���ѳ���2000��,����ʱ��õı�ע��ʽΪ:��Դ+��Ȥ����,�����ҵ�־ͬ���ϵ�����
- ��ʽ�١���������ͼƬ����,����ʶ��,��̨�ظ�:��Ⱥ;
- ��ʽ�ڡ������ź�:dkl88191,��ע:����CSDN
- ��ʽ�ۡ����������ں�:Pythonѧϰ�������ھ�,��̨�ظ�:��Ⱥ
