Self-Attention Generative Adversarial Networks����ע�����ɶԿ�����
0.ժҪ
�ڱ�����,�������������ע�����ɶԿ�����(Self-Attention Generative Adversarial Network, SAGAN),������������ͼ�������������ע���������ij���������ģ����ͳ�ľ���GANs�ڵͷֱ�������ͼ�н��Կռ�ֲ���Ϊ���������ɸ߷ֱ��ʵ�ϸ�ڡ���SAGAN��,����ʹ����������λ�õ�����������ϸ�ڡ�����,�ü����������Լ��ͼ��Զ�����ֵĸ�ϸ�������Ƿ�һ�¡�����,������о�����,������������Ӱ��GAN���ܡ�������һ����,���ǽ�����һ��Ӧ����GAN������,�������������ѵ������ѧ�������SAGAN��֮ǰ�Ĺ������ָ���1,�����Inception score(IS)��36.8��ߵ�52.52,����������ս�Ե�ImageNet���ݼ��ϵ���ʼ�����27.62���͵�18.65��ע���Ŀ��ӻ���ʾ,��������������������״���Ӧ������,�����ǹ̶���״�ľֲ�����
1.����

ͼ1��ʾ�������SAGANͨ������ͼ��Զ�����ֵĻ������������ǹ̶���״�ľֲ�����������һ�µ�Ŀ��/����������ͼ����ÿһ����,��һ��ͼ����ʾ��������д����ԵIJ�ѯλ��,��ʹ����ɫ����㡣�������ͼ����Щ��ѯλ�õ�ע������ͼ,����Ӧ����ɫ����ļ�ͷ�ܽ������ܹ�ע������
ͼ��ϳ��Ǽ�����Ӿ��е�һ����Ҫ���⡣�������ɶԿ�����(GANs)�ij���,��һ����ȡ���������Ľ�չ(Goodfellow����,2014),�����Դ������������(Odena, 2019)��������Ⱦ��������GANs (Radford et al., 2016;Karras����,2018;Zhang����)����ɹ���Ȼ��,ͨ����ϸ�����Щģ�����ɵ�����,���ǿ��Թ۲쵽����GANs (Odena����,2017;Miyato����,2018;Miyato & Koyama, 2018)�ڶ������ݼ���ѵ��ʱ(����,ImageNet (Russakovsky����,2015)),�ڽ�ģijЩͼ����ʱ������ͼ����Ҫ���ѵöࡣ����,��Ȼ���Ƚ���ImageNet GANģ��(Miyato & Koyama, 2018)�ó��ں��ٵĽṹԼ���ºϳ�ͼ����(����,������պ;�����,���Ǹ����ͨ�����������Ǽ���������),�������ܲ���ijЩ����һ�³��ֵļ��λ�ṹģʽ(����,��ͨ���ñ����Ƥë��������,��û����ȷ����ĵ����Ľ�)��һ�����ܵĽ�����,֮ǰ��ģ�����������ھ�������ģ��ͬͼ������֮��������ԡ����ھ������Ӿ��оֲ��Ľ�����,���ֻ�о����������֮����ܴ���������������ϵ�����ڸ���ԭ��,����ܻ���ֹ�˽ⳤ��������ϵ:һ��Сģ�Ϳ�������ʾ����,�Ż��㷨�������Է�����ϸЭ������Բ�����Щ������ϵ�IJ���ֵ,������Щ��������ͳ���Ͽ��ܴܺ���,��Ӧ�õ���ǰ���ɼ�������ʱ����ʧ�ܡ���������˵Ĵ�С������������ı�ʾ����,��ͬʱҲ��ʧȥ���þֲ������ṹ��õļ����ͳ��Ч�ʡ�����ע��(Cheng����,2016;Parikh����,2016;��һ����,V aswani����,2017)��ģ��Զ��������ϵ������������ͳ��Ч��֮����ֳ����õ�ƽ�⡣����ע��ģ�齫ijһλ�õ���Ӧ����Ϊ����λ�������ļ�Ȩ��,����Ȩ��(��ע������)�ļ���ֻ��Ҫ��С�ļ���ɱ���
�ڱ��о���,�������������ע�����ɶԿ�����(SAGANs),�����罫����ע��������뵽�������ɶԿ������С�����ע��ģ���Ǿ����IJ���,�������ڽ�ģ�ij���,����������ͼ�������������ҹ�ע������,���������Ի��Ƴ�ͼ��,����ÿ��λ�õ�ϸ�ڶ���ͼ��Զ�����ֵ�ϸ�ڽ�������ϸ��Э��������,�ü��������ܸ�ȷ�ض�ȫ��ͼ��ṹʩ�Ӹ��ӵļ���Լ��
��������ע��֮��,���ǻ���������������������������GAN���ܵļ��⡣Odena���˵Ĺ���(2018��)����,�������õ��������������ֵø��á����ǽ���ʹ�ù���һ��������GAN�������������õĵ���,�ü�����ǰֻӦ���ڼ�����(Miyato����,2018)��
������ImageNet���ݼ��Ͻ����˴�����ʵ��,����֤�����������ע����ƺ��ȶ���������Ч�ԡ�SAGANͨ����IS����ѵ÷ִ�36.8��ߵ�52.52,����Fr��che IS�����27.62���͵�18.65,��ͼ��ϳɷ�����������֮ǰ�Ĺ�����ע���Ŀ��ӻ���ʾ,��������������������״���Ӧ������,�����ǹ̶���״�ľֲ�����
2.��ع���
2.1.GAN
GANs�ڸ���ͼ������������ȡ���˾�ijɹ�,����ͼ��ͼ���ת��(Isola et al., 2017;Zhu����,2017;̩��������,2017;Liu��Tuzel, 2016;Ѧ��,2018;Park����,2019),ͼ�ֱ���(Ledig����,2017;Snderby����,2017)���ı���ͼ��ϳ�(Reed����,2016b;a;Zhang����,2017;Hong et al., 2018)��������һ�ɹ�,������֪,GANs��ѵ���Dz��ȶ���,�Գ�������ѡ������С��м������ͼͨ������µ�����ܹ����ȶ�GANѵ������ѧ���������������(Radford et al., 2016;Zhang����,2017;Karras����,2018;2019),��ѧϰĿ��Ͷ�̬(Arjovsky����,2017;Salimans����,2018;÷�ĵ���,2017;Che����,2017;�Ե���,2017;Jolicoeur-Martineau, 2019),����������(Gulrajani����,2017;Miyato et al., 2018)����������ʽ����(Salimans et al., 2016;Odena����,2017;Azadi����,2018)�����,Miyato����(Miyato et al., 2018)������Ƽ�������Ȩ�ؾ��������,��Լ��������������Lipschitz��������ϻ���ͶӰ�ļ�����(Miyato & Koyama, 2018),����һ��ģ�ʹ�������ImageNet�ϵ�������ͼ�����ɡ�
2.2.ע����ģ��
���,ע���������Ѿ���Ϊ���벶��ȫ��������ϵ��ģ�͵���ɲ���(Bahdanau����,2014;Xu����,2015;���,2016;Gregor����,2015;Chen����,2018)���ر�������ע��(Cheng����,2016;Parikh et al., 2016),Ҳ����Ϊintra-attention,ͨ����עͬһ�����е�����λ��������������ij��λ�õ���Ӧ��V aswani����(V aswani et al., 2017)֤��,��������ģ�ͽ�ͨ��ʹ������ע��ģ�;Ϳ��Ի�����Ƚ��Ľ����Parmar����(Parmar et al., 2018)�����һ��Image Transformerģ��,������ע�����ӵ��Իع�ģ����,��������ͼ��Wang����(Wang et al., 2018)������ע����ʽ��Ϊһ�ַǾֲ�����,�Խ�ģ��Ƶ�����е�ʱ������ԡ�����ȡ������Щ��չ,����GANs�л�û�ж�����ע�����̽�֡�(AttnGAN (Xu et al., 2018)�����������еĵ���Ƕ��ʹ��ע��,�����ڲ�ģ��״̬��ʹ������ע��)��SAGANѧϰ��ͼ����ڲ���������Ч���ҵ�ȫ�ֵġ����ڵ�������ϵ��
3.��ע�����ɶԿ�����Self-Attention Generative Adversarial Networks
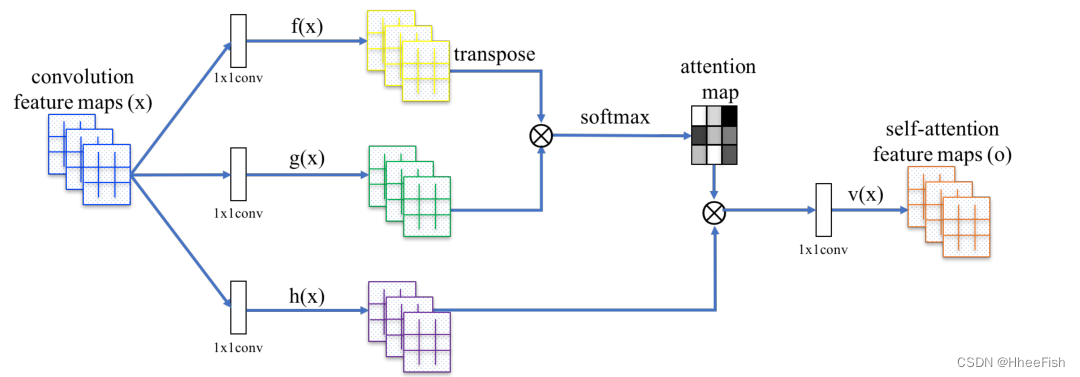
ͼ2��SAGAN������ע��ģ�顣?��ʾ����˷�����ÿһ��ִ��softmax����
���������GAN��ģ��(Radford����,2016;Salimans����,2016;Karras����,2018)��ͼ������ʹ�þ����㹹����������������Ϣ��һ���ֲ�����,���ʹ�þ����㵥���Ǽ���Ч�ʵ͵Ľ�ģԶ������ͼ���ڱ�����,���Dz�����(Wang et al., 2018)�ķǾֲ�ģ��,������ע������GAN���,ʹ�������ͼ��������ܹ���Ч�ؽ�ģ�㷺����Ŀռ�����֮��Ĺ�ϵ������������ע��ģ��(�μ�ͼ2),���ǽ�������ķ�����Ϊ����ע�����ɶԿ�����(Self-Attention Generative Adversarial Networks, SAGAN)��
���Ƚ�֮ǰ���ز��ͼ������x��RC��Nת��Ϊ���������ռ�f, g������ע����,����f(x) = Wfx, g(x) = Wgx,
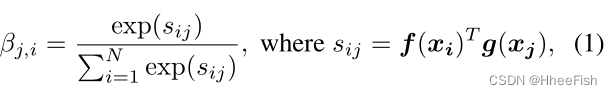
��j,i��ʾģ���ںϳɵ�j������ʱ�Ե�i��λ�õĹ�ע�̶ȡ�����CΪͨ����,NΪǰһ����������������λ������ע���������o = (o1, o2,����oj����oN)��RC��N,����,
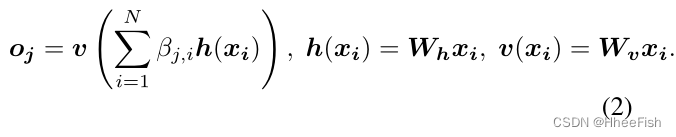
��������ʽ��,Wg��RC����C��Wf��RC����C��Wh��RC����C��Wv��RC��C��ѧϰ����Ȩ�ؾ���,���DZ�ʵ��Ϊ1��1��������Ϊ�����ǽ�C����ͨ��������ΪC/k(��ImageNet�Ͼ�������ѵ���ں�,k = 1,2,4,8)ʱ,����û��ע��κ������������½���Ϊ������ڴ�Ч��,����������ʵ���ж�ѡ��k = 8(��C�� = C/8)��
����,���ǽ�һ����ע��������������һ����������,�����ӻ���������ͼ�����,�������Ϊ,

���Ц���һ����ѧϰ�ı���,��ʼ��Ϊ0�������ѧϰ�Ħ�ʹ���������������ھֲ����������������Ϊ������ס���Ȼ����ѧ�ḳ��Ǿֲ�֤�ݸ����Ȩ�ء�������ô����ԭ��ܼ�:��������ѧϰ������,Ȼ������������ĸ����ԡ���SAGAN��,�����ע��ģ����Ӧ�����������ͼ�����,����ͨ����С���Կ�����ʧ�Ľ����汾�Խ��淽ʽ����ѵ��(Lim & Ye, 2017;Tran����,2017;Miyato et al., 2018),
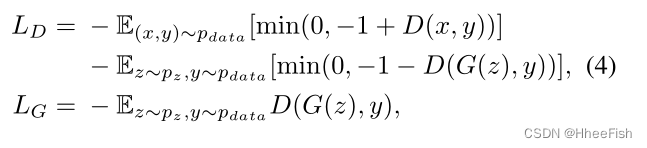
4.�ȶ�GANsѵ���ļ���
���ǻ��о������ּ������ȶ�GANs�ھ�����ս�Ե����ݼ��ϵ�ѵ��������,�������������ͼ�������ʹ�ù���һ��(Miyato et al., 2018)�����,����ȷ����˫ʱ��߶ȸ��¹���(TTUR) (Heusel et al., 2017)����Ч��,���������ر�ʹ������������������е���ѧϰ���⡣
4.1. �������ͼ������Ĺ���һ��
Miyato����(Miyato et al., 2018)������ͨ���Լ���������Ӧ�ù���һ�����ȶ�GANs��ѵ����������ͨ������ÿһ������������Ƽ�����������ϣ�ij�������������һ���������,��һ������Ҫ����ij���������(������Ȩֵ�����������Ϊ1��ʵ��Ӧ����ʼ�ձ�������)������,����ɱ�Ҳ��Խ�С��
������Ϊ,���������֤��,�����������������GANs���ܵ���Ҫ�������,�����Ҳ���������ڹ���һ��(Odena����,2018)��Ƶ��һ�����Է�ֹ�������ȵ�����,�����쳣�ݶȡ�����ͨ��ʵ�鷢��,�Բ������ͼ��������й���һ������ʹÿ������������ʹ�ø��ٵļ���������,�Ӷ���������ѵ���ļ���ɱ����÷�������ʾ�����ȶ���ѵ����Ϊ��
4.2. �������ͼ��������µIJ�ƽ��ѧϰ��
��֮ǰ�Ĺ�����,������������(Miyato et al., 2018;Gulrajani����,2017)��������GANs��ѧϰ���̡���ʵ����,ʹ�����������ķ���ͨ����ѵ��������,ÿ�����������²�����Ҫ���(����,5)���������²��衣������,Heusel����(Heusel et al., 2017)���Ŷ��������ͼ�����ʹ�õ�����ѧϰ��(TTUR)�����ǽ���ʹ��TTUR��������������ѧϰ����������,ʹÿ������������ʹ�ø��ٵļ����������Ϊ���ܡ�ʹ�����ַ���,�����ܹ�����ͬ��ʱ���ڲ������õĽ����
5.ʵ��

ͼ4��128��128ʾ��������ɵĻ���ģ�ͺ����ǵ�ģ�͡�SN on G/D���͡�SN on G/D+TTUR��
Ϊ������������ķ���,������LSVRC2012 (ImageNet)���ݼ��Ͻ����˴���ʵ��(Russakovsky et al., 2015)������,��5.1����,���������ּ�������ȶ�GANsѵ�������ּ�������Ч�Ե�ʵ�顣������,�ڵ�5.2�����о��������������ע����ơ����,���ǵ�SAGAN���������Ƚ��ķ��������˱Ƚ�(Odena����,2017;Miyato & Koyama, 2018)��5.3���е�ͼ����������ģ����ÿ��4��gpu��ʹ��ͬ��SGD(������֪,�첽SGD��������,�μ���(Odena, 2016))ѵ��Լ2�ܡ�
����ָ��
����ѡ��Inception����(IS) (Salimans et al., 2016)��Fr��echet Inception����(FID) (Heusel et al., 2017)���ж������������ܴ����������(Zhou����,2019;Khrulkov��Oseledets, 2018;Olsson et al., 2018),���Dz�û�б��㷺ʹ�á�Inception����(Salimans et al., 2016)����������ֲ��ͱ�Ե��ֲ�֮���KLɢ�ȡ�Inception����Խ��,ͼ������Խ�á����ǰ���Inception�÷�,��Ϊ�����㷺ʹ��,��˿��Խ����ǵĽ������ǰ�Ĺ������бȽϡ�Ȼ��,��Ҫ����Ҫ����Inception���������ص����ơ�����Ҫ��Ϊ��ȷ��ģ�����ɵ��������Ա�ȷ�ŵ�ʶ��Ϊ����һ���ض�����,����ģ�ʹ�����������������,��һ��Ҫ����ϸ�ڵ���ʵ�Ի����ڶ����ԡ�FID��һ�ָ���ԭ��ȫ��ĺ�����,������������������ʵ�Ժͱ�����ʱ,�ѱ�֤��������������һ��(Heusel et al., 2017)��FID������Inception-v3����������ռ������ɵ�ͼ������ʵͼ��֮���Wasserstein-2����
���˶��������ݷֲ�(����, ImageNet�е�����1000��ͼ��),���ǻ�����ÿ���������ɵ�ͼ������ݼ�ͼ��֮���FID(��Ϊintra FID (Miyato & Koyama, 2018))���ϵ͵�FID���ڲ�FIDֵ��ζ�źϳ����ݷֲ�����ʵ���ݷֲ�֮��ľ�����������������е�ʵ����,ÿ��ģ���������50k������,����Inception������FID��intra FID��
����ṹ��ʵ��ϸ�ڡ�����ѵ��������SAGANģ�Ͷ�ּ������128��128ͼ��Ĭ�������,�������ͼ������еIJ㶼ʹ���˹���һ��(Miyato et al., 2018)��������(Miyato & Koyama, 2018), SAGAN����������ʹ����������һ��,�ڼ�������ʹ��ͶӰ����������ģ��,����ʹ�æ�1 = 0�ͦ�2 = 0.9��Adam�Ż���(Kingma & Ba, 2015)����ѵ����ȱʡ�����,��������ѧϰ��Ϊ0.0004,��������ѧϰ��Ϊ0.0001��
5.1. ����������ȶ�����
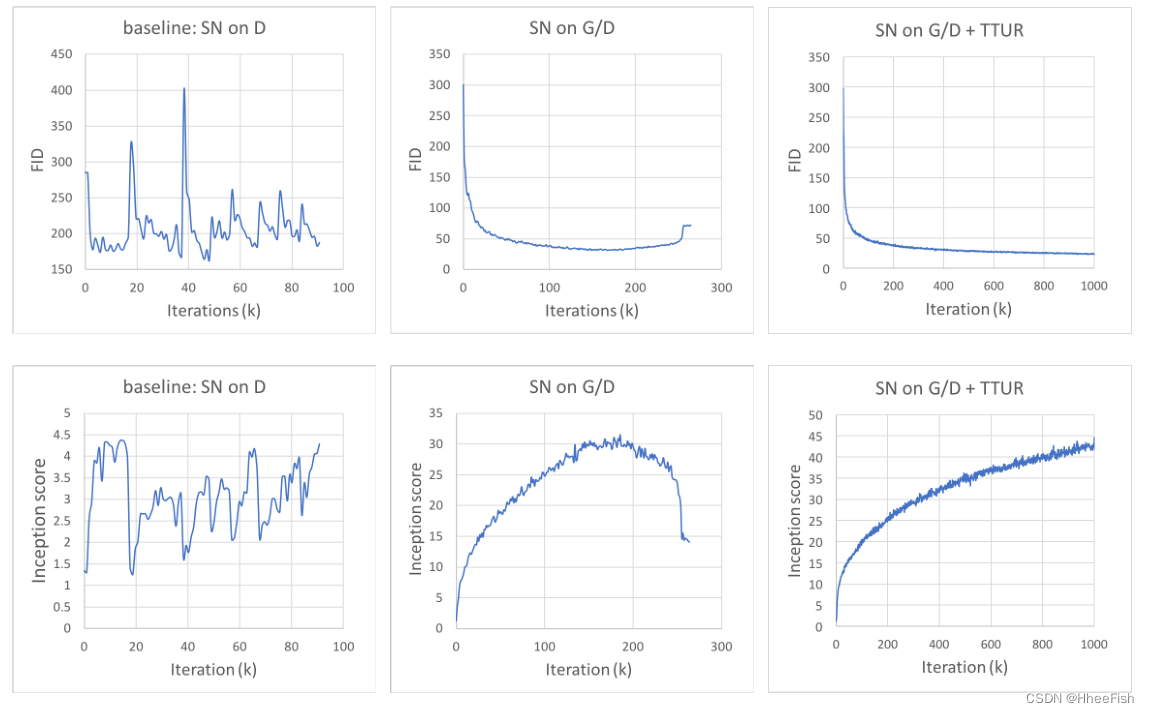
ͼ3��ѵ�����ߵĻ���ģ�ͺ����ǵ�ģ����������ȶ�����,��SN�ϵ�G/D������ʱ��߶�ѧϰ��(TTUR)��������ģ��G��D����1:1�������ѵ��
�ڱ�����,���ǽ�����ʵ��������������ȶ���������Ч��,��,������һ��(SN)Ӧ�õ������������ò�ƽ��ѧϰ��(TTUR)����ͼ3��,���ǵ�ģ�͡�SN on G/D���͡�SN on G/D+TTUR����������Ƚ���ͼ�����ɷ���ʵ�ֵĻ���ģ�ͽ����˱Ƚ�(Miyato et al., 2018)���ڸû���ģ����,���ڼ�������ʹ��SN�������Ƕ��б���(D)��������(G)����1:1������µ�ѵ��ʱ,ѵ����÷dz����ȶ�,��ͼ3����ߵ���ͼ��ʾ������ѵ�����ڱ��ֳ�ģʽ����������,ͼ4���Ͻǵ���ͼչʾ�˻���ģ���ڵ�10k�ε���ʱ������ɵ�һЩͼ����Ȼ��ԭ����(Miyato et al., 2018)��,��D��G����5:1�IJ�ƽ����´�������ֲ��ȶ���ѵ����Ϊ,��Ϊ�����ģ�͵������ٶ�,����1:1��ƽ����½����ȶ�ѵ���������ǿ�ȡ�ġ����,ʹ����������ļ�����ζ������ͬ�Ĺ���ʱ����,��ģ�Ϳ��Բ������õĽ�������,����ҪΪ�������ͼ�����Ѱ�Һ��ʵĸ��±ȡ���ͼ3�м���ͼ��ʾ,�ڷ������ͼ�������ͬʱ����SN,��ʹ��1:1�������ѵ��,���ǵ�ģ�͡�SN on G/D��Ҳ��õ��ܴ���ȶ�������ѵ��������,���������������ǵ�����ߵġ�����,ͨ��FID��IS������ͼ�������ڵ�260k�ε���ʱ��ʼ�½�����ͼ4�п����ҵ���ģ���ڲ�ͬ����������������ɵ�ʾ��ͼ������ͬ��ʹ�ò�ƽ��ѧϰ��ѵ���б�����������ʱ,���ǵ�ģ�͡�SN on G/D+TTUR��������ѵ��������ͼ������������ߡ���ͼ3��ͼ4��ʾ,��һ�����ѵ��������,����û�й۲쵽����������FID��Inception�������κ������½������,��������Ͷ��Խ����֤������������ȶ�������GANsѵ������Ч�ԡ����ǻ�����,���ּ�����Ч��������һ���̶����ǵ��ӵġ��������ʵ����,���е�ģ�Ͷ����������ͼ����������˹���һ������,��ʹ�ò�ƽ��ѧϰ�ʶ��������ͼ���������1:1���µ�ѵ����
5.2. Self-Attention����

��1��GANs������ע����ʣ���ıȽϡ���Щ�鱻���ӵ�����IJ�ͬ���С����е�ģ�Ͷ�������һ����ε�����ѵ��,���ұ�������õ�Inception����(IS)��Fr��echet Inception����(FID)��F eatk��ζ����k��k����ͼ���������ҹ�ע

ͼ5��ע������ͼ�Ŀ��ӻ�����Щͼ�������������ɵġ����ǽ�ʹ��ע���������һ�����������ע������ͼ���ӻ�,��Ϊ��һ����ӽ��������,����������Ͷ�䵽���ؿռ䲢���͡���ÿ����Ԫ����,��һ��ͼ����ʾ���������д����ԵIJ�ѯλ��,��Щλ������ɫ����ĵ��ʾ����������ͼ������Щ��ѯλ�õ�ע������ͼ,����Ӧ����ɫ����ļ�ͷ�ܽ������ܹ�ע���������ǹ۲쵽�������ѧ���˸�����ɫ��������������������ע����,���������ǿռ��ڽ�(�����Ͻǵĵ�Ԫ��)�����ǻ�����,����һЩ��ѯ���ڿռ�λ���Ϸdz��ӽ�,�����ǵ�ע������ͼ���ܷdz���ͬ,�����½ǵ�Ԫ����ʾ����ͼ���ϵ�Ԫ����ʾ,SAGAN�ܹ�������������μ�����Ĺ�����ɫ�IJ�ѯ���ʾע�������ڻ����ȷ�Ĺؽ�����ṹ���������ϰ��ע��ͼ���Ե���������ı��ġ�
Ϊ��̽�������������ע����Ƶ�Ч��,����ͨ���ڲ������ͼ������IJ�ͬ����������ע��������������SAGANģ�͡����1��ʾ,���и�����ͼ(��f eat32��f eat64)�о�������ע����Ƶ�SAGANģ�ͱ��ڵͼ�����ͼ(��f eat8��f eat16)�о�������ע����Ƶ�ģ��ȡ���˸��õ����ܡ�����,��SAGAN, f eat8��ģ�͵�FID��22.98��ߵ�18.28,��SAGAN, f eat32����ԭ������,����ע����յ������֤��,�����и��������ѡ����нϴ�����ӳ�������(��,���ڽϴ������ӳ��,���Ǿ����IJ���),���ڶԽ�С������ӳ��(��8��8)��ģ������ϵʱ,�����������ھֲ����������á��������,ע�����ʹ�������ͼ����������и�ǿ��������ֱ�ӽ�ģ����ͼ�е�Զ��������ϵ������,���ǵ�SAGANģ������ע�����ģ��(��1�ĵڶ���)�ıȽϽ�һ�������������������ע����Ƶ���Ч�ԡ�
����ͬ�������IJв�����,��ע���Ҳȡ���˸��õ�Ч��������,��������8��8 feature maps�еIJв���滻self-attention blockʱ,ѵ���Dz��ȶ���,��������ܵ������½�(����,FID��22.98���ӵ�42.13)����ʹ��ѵ��˳���������,�òв���滻����ע�����Ȼ�ᵼ��FID��Inception��������Ľ����(����,����ͼ32 �� 32�е�FID 18.28 vs 27.33)����һ�Ƚϱ���,ʹ��SAGAN���������ܸĽ�����������Ϊģ����Ⱥ����������ӡ�
Ϊ�˸��õ����������ɹ�����ѧϰ��ʲô,������SAGAN�п��ӻ����������Բ�ͬͼ���ע��Ȩ�ء�ͼ5��ͼ1��ʾ��һЩֵ��ע���ʾ��ͼ����ѧϰע��ͼ��һЩ���Ե�����,��μ�ͼ5��˵����
5.3. �����Ƚ��ıȽ�

��2�������SAGAN�����Ƚ���GANģ�͵ıȽ�(Odena����,2017;Miyato & Koyama, 2018)����ImageNet�ϵ�������ͼ�����ɡ����ݹٷ�������Ȩ�ؼ����sngan��FID��

ͼ6����SAGANΪ��ͬ�������ɵ�128x128ʾ��ͼ��ÿ����ʾһ�����ʾ����������ߵ�һ��,�г������ǵ�SAGAN�ڲ�FID(��)�����Ƚ��ķ���(Miyato & Koyama, 2018))(��)��

���ǻ������ǵ�SAGAN�����Ƚ���GANģ�ͽ����˱Ƚ�(Odena����,2017;Miyato & Koyama, 2018)����ImageNet�ϵ�������ͼ�����ɡ����2��ʾ,���������SAGANʵ������õ�Inception����,�ڲ�FID��FID�������SAGAN������������published Inception score,��36.8��ߵ�52.52��SAGANʵ�ֵĽϵ�FID(18.65)��intra FID(83.7)Ҳ����,SAGANͨ��ʹ������ע��ģ���ͼ������֮���Զ�������Խ�ģ,���Ը��õرƽ�ԭʼͼ��ֲ���
ͼ6��ʾ��һЩImageNet��������ıȽϽ�������ɵ�ͼ�����ǹ۲쵽,�ںϳɾ��и��Ӽ��λ�ṹģʽ��ͼ����(������ʥ����Ȯ)����,���ǵ�SAGAN�����Ƚ���GANģ��(Miyato & Koyama, 2018)ȡ���˸��õ�����(��,�ϵ͵��ڲ�FID)�����ڽṹԼ�����ٵ���(����,ɽ�ȡ�ʯǽ��ɺ�����,���Ǹ����ͨ�����������Ǽ���������),���ǵ�SAGAN��ʾ���Ȼ���ģ���ٵ�����(Miyato & Koyama, 2018)��ͬ��,ԭ����SAGAN�е�����ע���ǶԾ����IJ���,���ڲ����ڼ��λ�ṹģʽ��һ�·����ij��ڡ�ȫ�ּ����������ϵ,����Ϊ��������ģ������ϵʱ,��������ֲ��������ơ�
6. ����
�ڱ�����,�����������ע�����ɶԿ�����(SAGANs),�����罫����ע��������뵽GAN����С�����ע��ģ���ڽ�ģԶ��������������Ч�ġ�����,���DZ���,����һ��Ӧ���ڷ������ȶ�GANѵ����TTUR�ӿ�ѵ������������SAGAN��ImageNet�ϵ�������ͼ�����ɷ���ʵ�������Ƚ������ܡ�
�����
Arjovsky, M., Chintala, S., and Bottou, L. Wasserstein GAN. arXiv:1701.07875, 2017.
Azadi, S., Olsson, C., Darrell, T., Goodfellow, I., and Odena, A. Discriminator rejection sampling. arXiv preprint arXiv:1810.06758, 2018.
Bahdanau, D., Cho, K., and Bengio, Y . Neural machine translation by jointly learning to align and translate. arXiv:1409.0473, 2014.
Brock, A., Donahue, J., and Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
Che, T., Li, Y ., Jacob, A. P ., Bengio, Y ., and Li, W. Mode regularized generative adversarial networks. In ICLR, 2017.
Chen, X., Mishra, N., Rohaninejad, M., and Abbeel, P . Pixelsnail: An improved autoregressive generative model. In ICML, 2018.
Cheng, J., Dong, L., and Lapata, M. Long short-term memory-networks for machine reading. In EMNLP, 2016.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A. C., and Bengio, Y . Generative adversarial nets. In NIPS, 2014.
Gregor, K., Danihelka, I., Graves, A., Rezende, D. J., and Wierstra, D. DRAW: A recurrent neural network for image generation. In ICML, 2015.
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V ., and Courville, A. C. Improved training of wasserstein GANs. In NIPS, 2017.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, pp. 6629�C6640, 2017.
Hong, S., Y ang, D., Choi, J., and Lee, H. Inferring semantic layout for hierarchical text-to-image synthesis. In CVPR, 2018.
Isola, P ., Zhu, J.-Y ., Zhou, T., and Efros, A. A. Image-toimage translation with conditional adversarial networks. In CVPR, 2017.
Jolicoeur-Martineau, A. The relativistic discriminator: a key element missing from standard GAN. In ICLR, 2019. Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. In ICLR, 2018.
Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks. In CVPR, 2019. Khrulkov, V . and Oseledets, I. Geometry score: A method for comparing generative adversarial networks. arXiv preprint arXiv:1802.02664, 2018.
Kingma, D. P . and Ba, J. Adam: A method for stochastic optimization. In ICLR, 2015.
Ledig, C., Theis, L., Huszar, F., Caballero, J., Aitken, A., Tejani, A., Totz, J., Wang, Z., and Shi, W. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, 2017.
Lim, J. H. and Y e, J. C. Geometric GAN. arXiv:1705.02894, 2017.
Liu, M. and Tuzel, O. Coupled generative adversarial networks. In NIPS, 2016.
Metz, L., Poole, B., Pfau, D., and Sohl-Dickstein, J. Unrolled generative adversarial networks. In ICLR, 2017.
Miyato, T. and Koyama, M. cGANs with projection discriminator. In ICLR, 2018.
Miyato, T., Kataoka, T., Koyama, M., and Y oshida, Y . Spectral normalization for generative adversarial networks. In ICLR, 2018.
Odena, A. Faster asynchronous sgd. arXiv preprint arXiv:1601.04033, 2016.
Odena, A. Open questions about generative adversarial networks. Distill, 2019. doi: 10.23915/distill.00018. https://distill.pub/2019/gan-open-problems. Odena, A., Olah, C., and Shlens, J. Conditional image synthesis with auxiliary classifier GANs. In ICML, 2017.
Odena, A., Buckman, J., Olsson, C., Brown, T. B., Olah, C., Raffel, C., and Goodfellow, I. Is generator conditioning causally related to GAN performance? In ICML, 2018.
Olsson, C., Bhupatiraju, S., Brown, T., Odena, A., and Goodfellow, I. Skill rating for generative models. arXiv preprint arXiv:1808.04888, 2018.
Parikh, A. P ., T��ackstr��om, O., Das, D., and Uszkoreit, J. A decomposable attention model for natural language inference. In EMNLP, 2016.
Park, T., Liu, M., Wang, T., and Zhu, J. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019. Parmar, N., V aswani, A., Uszkoreit, J., ukasz Kaiser, Shazeer, N., and Ku, A. Image transformer. arXiv:1802.05751, 2018.
Radford, A., Metz, L., and Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016.
Reed, S., Akata, Z., Mohan, S., Tenka, S., Schiele, B., and Lee, H. Learning what and where to draw. In NIPS, 2016a.
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., and Lee, H. Generative adversarial text-to-image synthesis. In ICML, 2016b. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. ImageNet large scale visual recognition challenge. IJCV, 2015.
Salimans, T., Goodfellow, I. J., Zaremba, W., Cheung, V ., Radford, A., and Chen, X. Improved techniques for training GANs. In NIPS, 2016.
Salimans, T., Zhang, H., Radford, A., and Metaxas, D. N. Improving GANs using optimal transport. In ICLR, 2018.
Snderby, C. K., Caballero, J., Theis, L., Shi, W., and Huszar, F. Amortised map inference for image super-resolution. In ICLR, 2017.
Taigman, Y ., Polyak, A., and Wolf, L. Unsupervised crossdomain image generation. In ICLR, 2017.
Tran, D., Ranganath, R., and Blei, D. M. Deep and hierarchical implicit models. arXiv:1702.08896, 2017.
V aswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. arXiv:1706.03762, 2017.
Wang, X., Girshick, R., Gupta, A., and He, K. Non-local neural networks. In CVPR, 2018.
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A. C., Salakhutdinov, R., Zemel, R. S., and Bengio, Y . Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
Xu, T., Zhang, P ., Huang, Q., Zhang, H., Gan, Z., Huang, X., and He, X. AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks. In CVPR, 2018.
Xue, Y ., Xu, T., Zhang, H., Long, L. R., and Huang, X. SegAN: Adversarial network with multi-scale L1 loss for medical image segmentation. Neuroinformatics, pp. 1�C10, 2018.
Y ang, Z., He, X., Gao, J., Deng, L., and Smola, A. J. Stacked attention networks for image question answering. In CVPR, 2016.
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., and Metaxas, D. N. StackGAN++: Realistic image synthesis with stacked generative adversarial networks. TPAMI. Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., and Metaxas, D. StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks. In ICCV, 2017.
Zhao, J., Mathieu, M., and LeCun, Y . Energy-based generative adversarial network. In ICLR, 2017.
Zhou, S., Gordon, M., Krishna, R., Narcomey, A., Morina, D., and Bernstein, M. S. HYPE: human eye perceptual evaluation of generative models. CoRR, abs/1904.01121, 2019. URL http://arxiv.org/ abs/1904.01121. Zhu, J.-Y ., Park, T., Isola, P ., and Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, 2017.