摘要
? ? ? ? 我们引入一种新的可预训练的视觉语言任务的通用表示方法---视觉-语言BERT(VL-BERT)。VL-BERT采用Transformer模型作为主干,将视觉和语言特征作为输入。输入的每个元素要么是输入句子中的一个单词,要么是输入图像中的一个感兴趣区域。它的是设计是为了适合大多数视觉-语言的下游任务。为更好的利用通用表示,我们在大规模的Conceptual Captions数据集和仅文本语料库上预训练。广泛的实验表明,预训练能过呢更好地对齐视觉-语言线索,有利于下游任务。
一、介绍
? ? ? ? 之前的视觉-语言任务是将用于图像识别和NLP的预训练好的基本网络以特定于任务的方式结合起来,特定任务的模型直接用于特定目标任务的微调,没有任何通用的视觉-语言预训练。当目标任务的数据稀缺时,特定于任务的模型很可能会出现过拟合。此外,由于特定任务的模型设计,很难从预训练中获益,预训练任务可能与目标有很大不同。研究视觉-语言任务的特征设计和和预训练缺乏共同点。
? ? ? ? 在VQA中,我们寻求推导出能够有效聚合和对齐视觉和语言信息的通用表示形式。我们开发了VL-BERT,一种用于视觉-语言任务的可预训练的通用表示方法,如图1。主干是transformer模块,视觉和语言的嵌入特征作为输入。每个元素要么是输入句子中的一个单词,或者输入图像中的一个感兴趣的区域(RoI),以及某些特定的元素,以消除输入格式不同的歧义。每个元素都可以根据在其内容、位置、类别等上定义的兼容性,自适应地聚合来自所有其它元素的信息。一个单词/一个RoI的内容特征是领域内特定的(单词特征是Word Piece嵌入、RoIs是Faster R-CNN特征),通过堆叠多层多模态Transformer注意力模块,所导出的表示具有丰富的视觉-语言线索的聚合和对齐能力,且特定任务的分支可以添加到上面用于特定的视觉-语言任务。
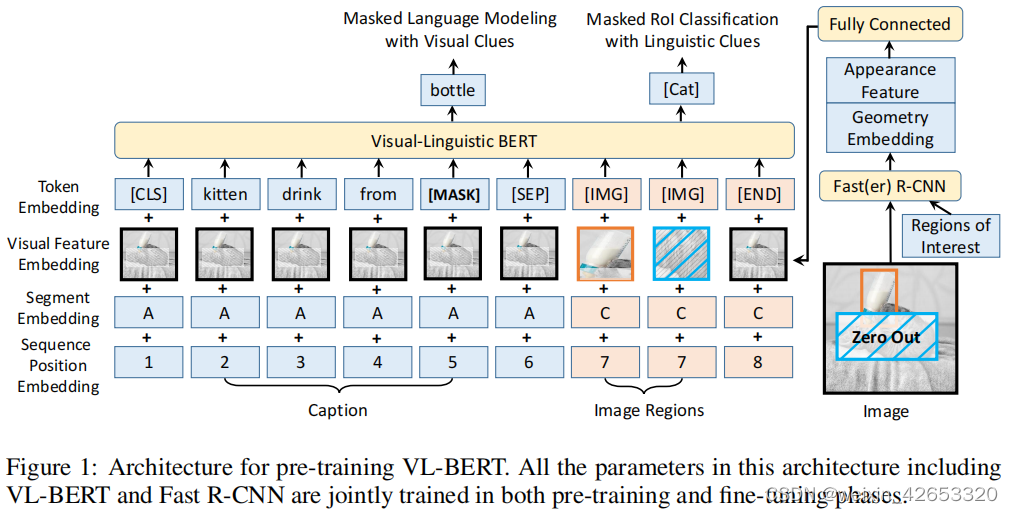
? ? ? ? 为了更好利用通用表示,我们在大型视觉-语言语料库和纯文本数据集上对VL-BERT进行预训练。视觉-语言语料库的预训练损失是通过预测随机掩码的单词或RoIs而产生的。这种预训练增强了VL-BERT在聚集和对齐视觉-语言线索的能力。而纯文本语料库的损失是BERT中标准的MLM损失,提高了在长和复杂句子的泛化程度。
? ? ? ?综合的实验证据表明,所提出的VL-BERT在各种下游视觉语言任务上取得了最先进的性能。
二、相关工作
? ? ? ? 计算机视觉的预训练? ? 最近有研究表明,在大规模目标数据集上从头训练CNN,与ImageNet预训练的效果相当。同时他们也注意到,在适当的大规模数据集上进行预训练对于提高数据稀缺的目标任务的性能至关重要。
? ? ? ? NLP的预训练? ? ? ? 提出了大量的基于Transformer的方法,如GPT、BERT、GPT-2、XLNet、XLM和RoBERTa。其中,BERT可能是最受欢迎的一个,因为它的简单性和优越的性能。
? ? ? ? 视觉-语言任务的预训练? ? 之前,设计特定任务的模型,其中,从现有的计算机视觉和NLP模型中衍生出来的特征以一种特定方式组合,仅针对特定任务的数据集训练。在ViLBERT和LXMERT中,分别由两个单模态网络用于输入句子和图像,然后是一个跨模态Transformer结合来自两个来源的信息。跨模态Transformer的注意力模式受到了限制,作者任务这样能提高性能。ViLBERT的作者声称,这种双流设计优于单流统一模型。在提出的VL-BERT中,它是基于transformer的统一架构,对注意力模式没有任何限制。视觉和语言内容被送入到VLBERT,在其中他们早地且自由地相互作用。我们发现,这种VL-BERT统一模型优于这两种双流设计。
? ? ? ? VisualBERT、B2T2和Unicoder-VL也是统一的单流架构,表5体现了这些模型的差异。这些研究工作同时出现表明,为视觉-语言任务获得一个通用的可预训练的表示是重要的。

? ? ? ? ?VL-BERT与其它同步工作由三个显著区别:(1)我们发现在所有其它同步进行的工作(ViLBERT和LXMERT)中使用的句子-图像关系预测对预训练视觉-语言表示没有帮助,因此,这样的任务没有被合并在VL-BERT中。(2)我们在视觉-语言和纯文本数据集上对VL-BERT进行预训练,我们发现这种联合预训练提高了长句子和复杂句子的泛化效果。(3)改进了视觉表示的调整。在VL-BERT中,用于导出视觉特征的Faster R-CNN的参数也被更新。为避免语言线索的掩码RoI分类预训练任务中的视觉线索泄露,除卷积层产生的特征图外,还对输入的原始像素中进行掩码操作。
三、VL-BERT
3.1 回顾BERT模型
? ? ? ? BERT预训练中,引入掩码语言建模(MLM)和下一个句子预测的预训练任务。
3.2 模型结构
? ? ? ? 如图1,它修改了原始的BERT模型,通过添加新的元素来适应视觉内容,将一种新的视觉特征嵌入到输入特征嵌入。与BERT类似,主干是多层双向Transformer编码器,可以在所有输入元素之间进行依赖建模。VL-BERT的输入是图像中感兴趣的区域(RoIs)和输入句子的子单词,RoI可以是由对象检测器产生的边界框,也可以是在某些任务中被注释的边界框。
? ? ? ? 值得注意的是,不同的视觉-语言任务的输入格式不同,但由于Transformer注意力的无序表示特性(如句子中的一个单词的位置仅由位置嵌入编码,而不是输入句子中的顺序),只要输入元素和嵌入特征设计适当,就可以导出通用表示。涉及到三种类型的输入元素,即视觉、语言和特殊元素,用于消除不同输入格式的歧义。输入序列总是以一个特殊的分类元素([CLS])开始,然后是语言元素,然后是视觉元素,最后以一个特殊的结束元素([END])结束。在语言元素中的不同句子之间,以及语言元素和视觉元素之间插入了一个特殊的分离元素([SEP])。对于每个输入元素,其嵌入特征是四种嵌入类型的总和,即标记嵌入、视觉特征嵌入、分割嵌入和序列位置嵌入。其中,视觉特征嵌入是新引入的方法来捕捉视觉线索,而其他三种嵌入则遵循原BERT论文的设计。
? ? ? ? 标记嵌入? ? 根据BERT,语言单词被嵌入为WordPiece嵌入,为每个特殊元素分配一个特殊的标记。对于视觉元素,为每个元素分配一个特殊的[IMG]标记。
? ? ? ? 视觉特征嵌入? ??我们首先分别描述了视觉外观特征和视觉几何嵌入,然后如何将它们结合起来形成视觉特征嵌入。视觉元素对应一个RoI,通过Faster R-CNN提取视觉外观特征,在特征向量之前每个RoI的输出层被利用作为视觉特征嵌入。对于非视觉元素,对应的视觉外观特征是在整个输入图像上提取的特征,通过在覆盖整个输入图像的RoI上应用Faster R-CNN。
? ? ? ? 视觉几何嵌入的设计是为了告知VL-BERT在图像中每个输入元素的几何位置。视觉特征嵌入被附加到每个输入元素上,这是一个以视觉外观特征和视觉几何嵌入的连接为输入的全连接层的输出。
? ? ? ? 分割嵌入? ? 三种类型的分割,以分离来自不同来源的输入元素,A和B分别表示来自第一和第二输入句子的单词,C表示来自输入图像的RoI。
? ? ? ? 序列位置嵌入? ? 一个可学习的序列位置嵌入被添加到每个输入元素中,表示其在序列中的顺序,如BERT。视觉元素中的序列位置嵌入都是相同的。
3.3 预训练VL-BERT
? ? ? ? 我们在两个视觉-语言和纯文本数据集上预训练VL-BERT,使用Conceptual Captions数据集作为视觉语言语料库,为避免在这种短、简单的文本场景中的过拟合,我们还在具有长和复杂句子的纯文本语料库上进行预训练,利用BooksCorpus和英语维基百科数据集。
? ? ? ? 具有视觉线索的掩码语言建模? ? ? ? 此任务不仅建模句子词间的依赖关系,还对齐了视觉和语言内容。在预训练期间,在Softmax交叉熵损失的驱动下,将掩码的词对应的最终输出特征输入到整个词汇表的分类器中。
? ? ? ? 具有语言线索的掩码RoI分类?
3.4 微调VL-BERT
? ? ? ? 我们只需向VL-BERT提供适当格式的输入和输出,并端到端微调所有的网络参数。
四、实验
4.2.2 视觉问答
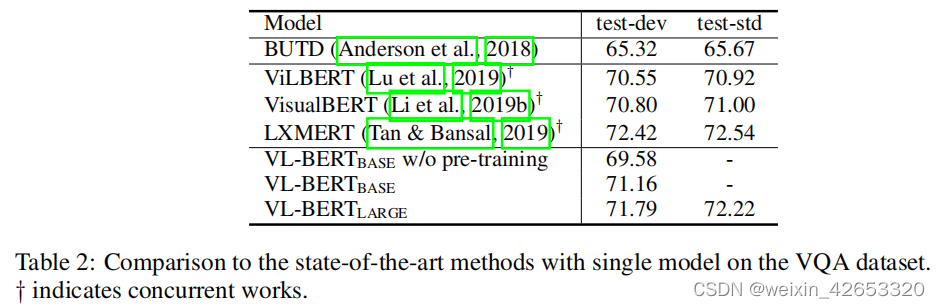
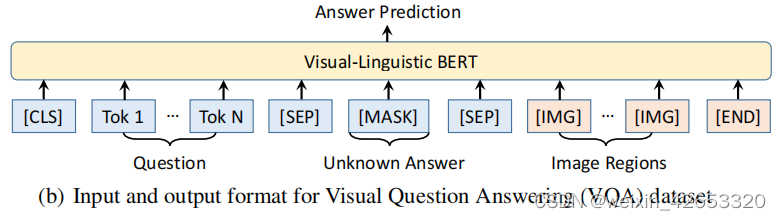
? ? ? ? ?预训练的VL-BERT提高了1.6%的性能,这验证了预训练的重要性。VL-BERT与BUTD共享相同的输入(即问题、图像和roi)、输出和实验设置,BUTD是一种专门为任务设计的流行模型,尽管如此,VL-BERT的准确率还是超过了BUTD的5%以上。除了LXMERT外,我们的VL-BERT比其他并行工作具有更好的性能。这是因为LXMERT对大量的视觉问题回答数据进行了预先训练(聚合了几乎所有基于COCO和视觉基因组的VQA数据集)。虽然我们的模型只在字幕和仅文本数据集上进行了预先训练,但这与VQA任务仍然存在差距。
五、总结
? ? ? ? 本文我们提出VL-BERT,一种用于视觉-语言任务的可训练的通用表示。VL-BERT不采用特定于特殊任务的模块,而是采用了简单而又功能强大的Transforemr模型作为骨干。它在大规模的概念标题数据集和纯文本语料库上进行了预训练。广泛的实证分析表明,预训练的程序可以更好地对齐视觉-语言线索,从而有利于下游任务。在未来,我们希望寻求更好的预训练任务,这可能有利于更多的下游任务(例如,图像标题生成)。