���ĵ�ַ:https://arxiv.org/pdf/2101.00529.pdf
��ز���:
����Ȼ���Դ���������ģ̬��CLIP:����Ȼ���Լල��ѧϰ��Ǩ���Ӿ�ģ��
����Ȼ���Դ���������ģ̬��ViT-BERT:�ڷ�ͼ���ı���������Ԥѵ��ͳһ����ģ��
����Ȼ���Դ���������ģ̬��BLIP:����ͳһ�Ӿ�������������ɵ��Ծ�����ͼ��Ԥѵ��
����Ȼ���Դ���������ģ̬��FLAVA:һ���������Ժ��Ӿ�����ģ��
����Ȼ���Դ���������ģ̬��SIMVLM:�������ල�ļ��Ӿ�����ģ��Ԥѵ��
����Ȼ���Դ���������ģ̬��UniT:����ͳһTransformer�Ķ�ģ̬������ѧϰ
����Ȼ���Դ���������ģ̬��Product1M:���ڿ�ģ̬Ԥѵ�������ලʵ������Ʒ����
����Ȼ���Դ���������ģ̬��ALBEF:���ڶ���������Ӿ����Ա�ʾѧϰ
����Ȼ���Դ���������ģ̬��VinVL:�ع��Ӿ�����ģ���е��Ӿ���ʾ
һ�����
? �Ӿ�����Ԥѵ�� ( VLP ) (\text{VLP}) (VLP)��֤���ڹ㷺���Ӿ��������� ( VL ) (\text{VL}) (VL)������Ч�ġ����͵� VLP \text{VLP} VLP���������:(1) һ��Ԥѵ����Ŀ����ģ��,���ڱ���ͼ���е��Ӿ�Ŀ������������;(2) һ��Ԥѵ���Ŀ�ģ̬�ں�ģ��,�����ں��ı����Ӿ����������е� VLP \text{VLP} VLP�о���Ҫרע�ڸ��ƿ�ģ���ں�ģ��,������רע�ڸ�����Ŀ��Ϊ���ĵ��Ӿ���ʾ,���������һ��ȫ���ʵ֤�о���֤�� VL \text{VL} VLģ�����Ӿ���������Ҫ�ԡ�
? ����ǰ�Ĺ�����,�㷺ʹ�õ�Ŀ�����ģ������ Visual?Genome \text{Visual Genome} Visual?Genome���ݼ���ѵ���ġ�Ŀ����ģ���ṩ��һ����Ŀ��Ϊ���ĵ�ͼ���ʾ,������Ϊ�ںб����ڸ��� VL \text{VL} VLģ���С��ڱ�����,������ ResNetXt-152?C4 \text{ResNetXt-152 C4} ResNetXt-152?C4�ܹ�Ԥѵ����һ�����ģ��Ŀ��-���Լ��ģ�͡������֮ǰ��Ŀ����ģ��,��ģ����� VL \text{VL} VL��������˸��õ����,���ҹ�ģ�����ڸ����������Ͻ���ѵ��,�ϲ��˶��������Ŀ�������ݼ�,����: COCO \text{COCO} COCO�� OpenImages(OI) \text{OpenImages(OI)} OpenImages(OI)�� Ojbects365 \text{Ojbects365} Ojbects365�� Visual?Genome(VG) \text{Visual Genome(VG)} Visual?Genome(VG)������,���ĵ�Ŀ����ģ���ڹ㷺�� VL \text{VL} VL������ʵ���˸��õĽ���������������Ŀ����ģ��,���� X152-FPN \text{X152-FPN} X152-FPN�� OpenImages \text{OpenImages} OpenImages��ѵ��,���ĵ���ģ���ܹ�������������Ӿ�Ŀ�����ϡ�
? Ϊ����֤��Ŀ����ģ�͵���Ч��,�����ڰ�����885���text-image�Ե����ݼ���Ԥѵ����һ������
Transformer
\text{Transformer}
Transformer�Ŀ�ģ���ں�ģ��
OSCAR+
\text{OSCAR+}
OSCAR+,����ͼ����Ӿ���ʾ���µ�Ŀ����ģ������,������
OSCAR+
\text{OSCAR+}
OSCAR+Ԥѵ��ʱ���̶���Ȼ���ڹ㷺��������������Ԥѵ����
OSCAR+
\text{OSCAR+}
OSCAR+,������
VQA
\text{VQA}
VQA��
GQA
\text{GQA}
GQA��
NLVR2
\text{NLVR2}
NLVR2������
VL
\text{VL}
VL��������,�Լ�
COCO
\text{COCO}
COCO text-image����,�Լ���
COCO?image?cpationing
\text{COCO image cpationing}
COCO?image?cpationing��
NoCaps
\text{NoCaps}
NoCaps������
VL
\text{VL}
VL�������������,����Ŀ����ģ�Ͳ�������Ŀ��Ϊ���ĵı�ʾ����ĸ����˸���
VL
\text{VL}
VL����,ͨ����ʹ�þ���Ŀ����ģ�͵�baselineǿ�ܶ�,�ڸ��������ϴ������µ�
SOTA
\text{SOTA}
SOTA��
? ���ĵ���Ҫ�����ܽ�����:(1) �����һ��ȫ���ʵ֤�о�������
VL
\text{VL}
VLģ���е��Ӿ�����������Ҫ;(2) ������һ���µ�Ŀ����ģ��,����ڴ�ͳ��Ŀ����ģ��,���ܹ��������õ��Ӿ�����,������������Ҫ��
VL
\text{VL}
VL����Ķ����������ʵ����state-of-the-art���;(3) �ṩ����ϸ��Ԥѵ��Ŀ���������ʵ�顣
���������Ӿ����� ( VL ) (\text{VL}) (VL)�е��Ӿ� ( V ) (\text{V}) (V)
? �������ѧϰ��
VL
\text{VL}
VLģ��ͨ��������ģ�����:һ��ͼ������ģ��
Vision
\text{Vision}
Vision��һ����ģ̬����ģ��
VL
\text{VL}
VL:
(
q
,
v
)
=
Vision
(
I
m
g
)
,
y
=
VL
(
w
,
q
,
v
)
(1)
(\textbf{q},\textbf{v})=\textbf{Vision}(Img),\quad y=\textbf{VL}(\textbf{w},\textbf{q},\textbf{v}) \tag{1}
(q,v)=Vision(Img),y=VL(w,q,v)(1)
����,
I
m
g
Img
Img��
w
\textbf{w}
w���Ӿ�ģ̬������ģ̬�����롣
Vision
\textbf{Vision}
Visionģ��������
q
\textbf{q}
q��
v
\textbf{v}
v���ɡ�
q
\textbf{q}
qͼ��������ʾ,�����ǩ�����Ķ���,����
v
\textbf{v}
vͼ���ڸ�ά���ռ��еķֲ�ʽ��ʾ,������
VG-pretrained?Faster-RCNN
\text{VG-pretrained Faster-RCNN}
VG-pretrained?Faster-RCNN������box���������������������
VL
\textbf{VL}
VLģ�ͽ�ʹ���Ӿ�����
v
\textbf{v}
v,�����������
OSCAR
\text{OSCAR}
OSCARģ����ʾ
q
\textbf{q}
q������Ϊѧϰ�����Ӿ��������ϱ�ʾ��ê��,���Ҹ��Ƹ���
VL
\text{VL}
VL����ı��֡���ʽ
(
1
)
(1)
(1)��
VL
\textbf{VL}
VLģ���
w
\textbf{w}
w��
y
y
y�ڲ�ͬ��
VL
\textbf{VL}
VL�������Dz�ͬ�ġ���
VQA
\text{VQA}
VQA��,
w
\textbf{w}
w��������
y
y
y�DZ�Ԥ��Ĵ𰸡���text-image������,
w
\textbf{w}
w��һ�����Ӷ�
y
y
y�Ǿ��Ӻ�ͼ��Ե�ƥ���������image captioning������,
w
\textbf{w}
wû�и�����
y
y
y�����ɵ�caption��
? ��Ԥѵ������ģ���ڸ�����Ȼ���Դ��������Ͼ�ɹ�������,
VLP
\text{VLP}
VLP�ڸ��ƿ�ģ̬����ģ��
VL
\textbf{VL}
VL��ʵ���������ijɹ�,ͨ��:(1) ʹ��
Transformer
\text{Transformer}
Transformerͳһ��ģ�Ӿ�������;(2) ʹ�ô��ģ��text-image������Ԥѵ��ͳһ��
VL
\textbf{VL}
VL��Ȼ��,�����
VLP
\text{VLP}
VLP������ͼ������ģ��
Vision
\text{Vision}
Vision��Ϊһ���ں�,����δ���Ӿ��������иĽ����������,Ŀ����ĸĽ��Ѿ����������չ,ͨ��:(1) �����˸��������ḻ���Ҹ����ѵ����;(2) ��Ŀ�����㷨�����˸���Ķ���,����:feature pyramid network��one-stage dense prediction��anchor-free detectors;(3) ���ø�ǿ����
GPU
\text{GPU}
GPUѵ�������ģ�͡�
? �ڱ�������,����רע�ڸ���
Vision
\textbf{Vision}
Vision����ø��õ��Ӿ���ʾ�����߿�����һ���µ�
OD
\text{OD}
ODģ��,ͨ���ḻ�Ӿ�������������,����ģ�ͳߴ�,��һ�������
OD
\text{OD}
OD���ݼ���ѵ��,�Ӷ��ڹ㷺��
VL
\text{VL}
VL�����ϴﵽ��state-of-the-art��
1. Ŀ����Ԥѵ��
? Ϊ�˸��� VL \text{VL} VL����� OD \text{OD} ODģ��,����������4��������Ŀ�������ݼ��������������ݼ���û�����Ա�ע,���߲���Ԥѵ�������IJ��������� OD \text{OD} ODģ�͡�������һ�������ĸ��������ݼ��ϵĴ��ģ������Ԥѵ�� OD \text{OD} ODģ��,Ȼ���� Visual?Genome \text{Visual Genome} Visual?Genome�������ж������Է�֧��ģ��,ʹ���ܹ����Ŀ������ԡ�
1.1 ����
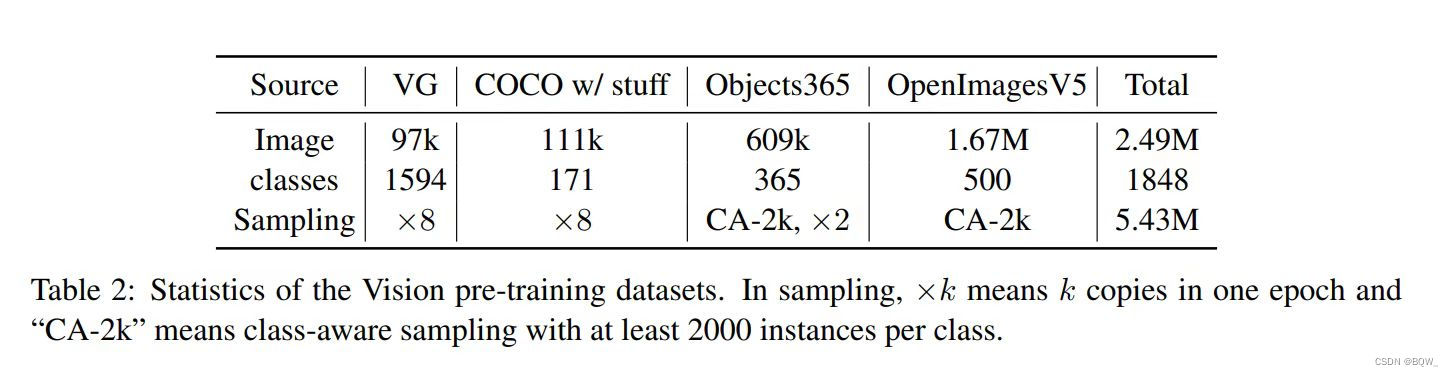
? �ϱ������˱�Ŀ�����Ԥѵ��ʹ�õ��ĸ����ݼ���ͳ����Ϣ,����: COCO \text{COCO} COCO�� OpenImagesV5(OI) \text{OpenImagesV5(OI)} OpenImagesV5(OI)�� Objects365V1 \text{Objects365V1} Objects365V1�� Visual?Genome(VG) \text{Visual Genome(VG)} Visual?Genome(VG)����Щ���ݼ����л���������,���������ݳߴ硢Ŀ��ʱ���ÿ�����ı������϶����Ȳ�ƽ�⡣����, VG \text{VG} VG���ݼ�����Ŀ������Ծ��зḻ�Ҷ����ı�ע������,���ı�ע���������һ��ܵ�ȱʧ��ע��Ӱ�졣��һ����, COCO \text{COCO} COCO���ݼ����ע�ķdz���,���Ǹ��ǵ��Ӿ����������Զ���� VG \text{VG} VG����ѭ���εIJ������ϲ�4�����ݼ�������һ��ͳһ�����ϡ�
- ����,Ϊ����ǿβ�������Ӿ�����,��
OpenImages
\text{OpenImages}
OpenImages��
Objects365
\text{Objects365}
Objects365��ִ�������ʶ�IJ��������ÿ���������2000��ʵ��,���յõ�
2.2M��0.8Mͼ�� - Ϊ��ƽ��ÿ�����ݼ��Ĺ���,���ߺϲ��ĸ����ݼ�ʹ��, COCO \text{COCO} COCO��8������ ( 8 �� 0.11 M ) (8\times 0.11M) (8��0.11M)�� VG \text{VG} VG��8������ ( 8 �� 0.1 M ) (8\times 0.1M) (8��0.1M)�������ʶ���� Objects365 \text{Objects365} Objects365��2������ ( 2 �� 0.8 M ) (2\times 0.8M) (2��0.8M)�������ʶ���� OpenImages \text{OpenImages} OpenImages��1������ (2.2M) \text{(2.2M)} (2.2M)��
- Ϊ��ͳһ����ʱ�,����ʹ�� VG \text{VG} VG�ʱ��Լ�����ı�����Ϊ�����Ĵʱ�,Ȼ�������������ݼ��е��� VG \text{VG} VG�����ƥ������ϲ��� VG \text{VG} VG,����ƥ��������һ�������
- ���,���߱�����
VG
\text{VG}
VG��������30��ʵ�������,������
1594�� VG \text{VG} VG���,�Լ����������������ݼ�����ӳ���� VG \text{VG} VG�ʱ���254�����,���պϲ���Ŀ�������ݼ�����1848�����
1.2 ģ�ͼܹ�( FPN?vs?C4 \text{FPN vs C4} FPN?vs?C4)
? ��Ȼ�о���ʵ FPN \text{FPN} FPNģ����Ŀ������Ч������ C4 \text{C4} C4,��������о����� FPN \text{FPN} FPN�������� VL \text{VL} VL�ṩ�� C4 \text{C4} C4���õ��������������,�������߾��������һ��ʵ�鲢��������Ҫ��ԭ������, C4 \text{C4} C4����������������ȡ�����в㶼��ʹ�� ImageNet \text{ImageNet} ImageNetԤѵ������,�� FPN \text{FPN} FPNģ�͵� MLP \text{MLP} MLPͷ��û�С���Ҳ֤���� VG \text{VG} VG���ݼ����� VL \text{VL} VL���������㹻�õ��Ӿ�������Ȼ��̫С��,����ʹ�� ImageNet \text{ImageNet} ImageNetԤѵ��Ȩ��������ġ���������ڲ�ͬ������ܹ� ( CNN?vs.?MLP ) (\text{CNN vs. MLP}) (CNN?vs.?MLP)������� FPN \text{FPN} FPN�е� MLP \text{MLP} MLPͷ, C4 \text{C4} C4��ʹ�õľ���ͷ�ܹ��ڱ����Ӿ���Ϣʱ���õĹ���ƫ����,������ʹ�� C4 \text{C4} C4�ܹ����� VLP \text{VLP} VLP��
1.3 ģ��Ԥѵ��
? ��ѭĿ����ѵ���еij���ʵ��,�����һ�������㡢��һ���в������е�batch-norm�㡣ʹ�ü���������ǿ�ķ���,����:horizontal flipping��multi-scale training��Ϊ��ʹ��
X152-C4
\text{X152-C4}
X152-C4�ܹ�ѵ�����ģ��,��
ImageNet-5K?checkpoint
\text{ImageNet-5K checkpoint}
ImageNet-5K?checkpoint�г�ʼ��ģ������,����batch sizeΪ16��ͼƬѵ��1.8M�ε�����
2. ��ģ����ע��������Ϣ
? ��Ԥѵ�� OD \text{OD} ODģ��������һ�����Է�֧,Ȼ���� VG \text{VG} VG���� OD \text{OD} ODģ����ע��������Ϣ��������Ŀ����Ԥѵ�����Ѿ���Ŀ���ʾ������Ԥѵ��,ͨ��ʹ��һ�������������ʧ����Ȩ��1.25��ʹ VG \text{VG} VG��רע��ѧϰ���ԡ����ַ�ʽ�õ���ģ���� VG \text{VG} VG�ϼ��Ŀ�������������Խ����ǰ��ģ�͡�
3. ���� VL \text{VL} VL���������������ȡ��
? �����Ӿ���������Եķḻ,��ͳ������֪��������ƺ���
NMS
\text{NMS}
NMS��ɾ���ص���bounding boxes,��ʹ��������ȡ���̷dz�������Ϊ�˸���Ч��,ʹ�����֪
NMS
\text{NMS}
NMS���滻����֪
NMS
\text{NMS}
NMS,������ִ��
NMS
\text{NMS}
NMSһ�Ρ�����Ҳ����ʱ�����;����滻Ϊ�����;������������滻ʹ������������ȡ���̿�������,������
VL
\text{VL}
VL������û��ȷ�ʵ���ʧ��
? ��������,Ԥѵ�� OD \text{OD} ODģ����Ϊͼ�� ����ģ���������Ӿ���ʾ ( q , v ) (\textbf{q},\textbf{v}) (q,v)�������ε� VL \text{VL} VL��������, q \textbf{q} q�Ǽ�Ŀ������Ƽ���,�� v \textbf{v} v�������������ϡ�ÿ����������������ʾΪ ( v ^ , z ) (\hat{v},z) (v^,z),���� v ^ \hat{v} v^�����Լ��ͷ������Է��������� P P Pά��ʾ,���� z z z������� R R Rά��λ�ñ��롣
���� OSCAR \text{OSCAR} OSCAR+Ԥѵ��
?
VLP
\text{VLP}
VLP�ijɹ�����Ϊ�㷺��
VL
\text{VL}
VL����ʹ��ͳһ�ļܹ�,����ʹ��������
VL
\text{VL}
VL���������ص�Ŀ�꺯�������ģԤѵ��ͳһģ�͡�������,����Ԥѵ��һ�����ư汾��
OSCAR
\text{OSCAR}
OSCAR,��֮Ϊ
OSCAR+
\text{OSCAR+}
OSCAR+ģ��,ʹ��ͼ��ı�ǩ��Ϊê����ѧϰ����image-text��ʾ��
1. Ԥѵ������
? �������е������Ӿ���
VL
\text{VL}
VL���ݼ�����Ԥѵ������:(1) image captioning���ݼ�,�����˹���ע��captions
w
\textbf{w}
w�ͻ������ɵ�ͼ���ǩ
q
\textbf{q}
q,����:
COCO
\text{COCO}
COCO��
Conceptual?Captions(CC)
\text{Conceptual Captions(CC)}
Conceptual?Captions(CC)��
SBU?cpations
\text{SBU cpations}
SBU?cpations��
flicker30k
\text{flicker30k}
flicker30k;(2) ��������
w
\textbf{w}
w���˹���ע��
q
\textbf{q}
q���Ӿ�
QA
\text{QA}
QA���ݼ�,����:
GQA
\text{GQA}
GQA��
VQA
\text{VQA}
VQA��
VG-QAs
\text{VG-QAs}
VG-QAs;(3) ���������captions
w
\textbf{w}
w���˹���ע��ǩ
q
\textbf{q}
q��image tagging���ݼ�,����
OpenImages
\text{OpenImages}
OpenImages��һ���Ӽ����ܵ���˵,���ϰ���565���ΨһͼƬ,885���text-tag-image��Ԫ�顣���ݼ�����ϸͳ����Ϣ����¼��ͨ���ϲ����ģ��image tagging���ݼ�,Ԥѵ�����ϵĹ�ģ��������,����
OpenImages(9M?images)
\text{OpenImages(9M images)}
OpenImages(9M?images)��
YFCC(92M?images)
\text{YFCC(92M images)}
YFCC(92M?images)��
2. Ԥѵ��Ŀ��
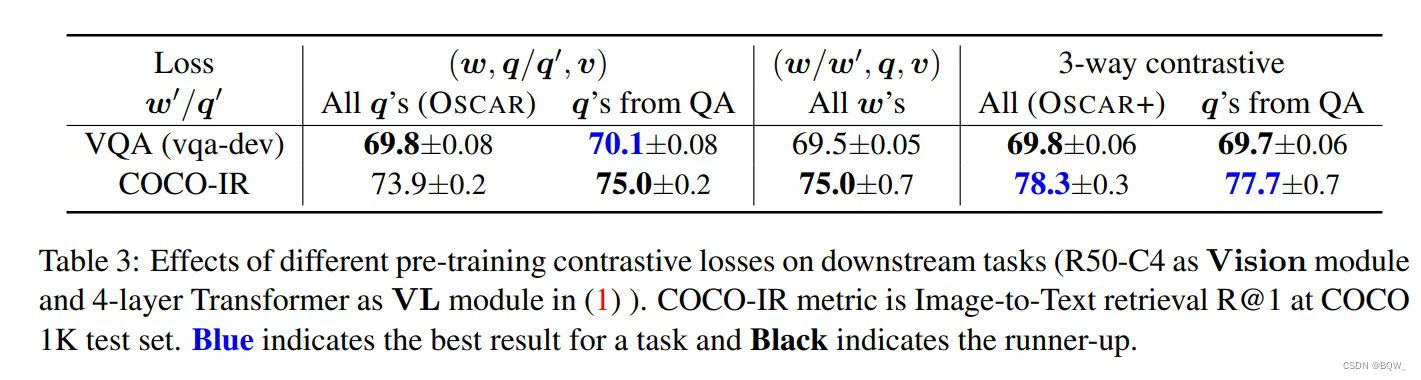
?
OSCAR+
\text{OSCAR+}
OSCAR+Ԥѵ����ʧ��������������:
L
P
r
e
?
t
r
a
i
n
i
n
g
=
L
MTL
+
L
CL3
(2)
\mathcal{L}_{Pre-training}=\mathcal{L}_{\text{MTL}}+\mathcal{L}_{\text{CL3}} \tag{2}
LPre?training?=LMTL?+LCL3?(2)
L
MTL
\mathcal{L}_{\text{MTL}}
LMTL?�Ƕ������ı�ģ̬(
w
\textbf{w}
w��
q
\textbf{q}
q)�ϵ�Masked Token Loss��
L
CL3
\mathcal{L}_{\text{CL3}}
LCL3?��һ����ӱ����·�Ա���ʧ��������ͬ��
OSCAR
\text{OSCAR}
OSCAR��ʹ�õĶ�Ԫ�Ա���ʧ����,�������·�Ա���ʧ�����ܹ���Ч���Ż�
VQA
\text{VQA}
VQA��text-image matchingʹ�õ�Ŀ�꺯�������ʽ
(
3
)
(3)
(3)����,
L
CL3
\mathcal{L}_{\text{CL3}}
LCL3?�ῼ���������͵�ѵ������
x
\textbf{x}
x:��image captioning��image tagging�����е�{caption,image-tags,image-features}��Ԫ��,�Լ�
VQA
\text{VQA}
VQA�����е�{question,answer,image-features}��Ԫ�顣
x
?
(
w
?
caption
,
q,v
?
tags&image
)
or
(
w,q
?
Q&A
,
v
?
image
)
(3)
\textbf{x}\triangleq (\underbrace{\textbf{w}}_{\text{caption}},\underbrace{\textbf{q,v}}_{\text{tags\&image}})\quad \text{or}\quad(\underbrace{\textbf{w,q}}_{\text{Q\&A}},\underbrace{\textbf{v}}_{\text{image}}) \tag{3}
x?(caption
w??,tags&image
q,v??)or(Q&A
w,q??,image
v??)(3)
? Ϊ�˼���Ա���ʧ����,��Ҫ���츺����������Ϊ����ѵ�������������������͵ĸ���Ԫ�顣һ����ʹ���ƻ���captions
(
w
��
,
q
,
v
)
(\textbf{w}',\textbf{q}, \textbf{v})
(w��,q,v),��һ����ʹ���ƻ���answers
(
w
,
q
��
,
v
)
(\textbf{w},\textbf{q}',\textbf{v})
(w,q��,v)��Ϊ�˷���caption-tags-image��Ԫ���Ƿ�������ƻ���caption��һ��text-imageƥ������Ϊ�˷���һ��question-answer-image��Ԫ���Ƿ�������ƻ���answer��һ��
VQA
\text{VQA}
VQA�Ĵ�ѡ����������[CLS]�ı����ܹ�����������Ԫ��
(
w
,
q
,
v
)
(\textbf{w},\textbf{q}, \textbf{v})
(w,q,v)��һ����ʾ,����������Ӧ��ȫ���Ӳ�����Ϊ��������,����Ԥ����Ԫ��Ϊƥ��
(
c
=
0
)
(c=0)
(c=0)���������ƻ���
w
(
c
=
1
)
\textbf{w}(c=1)
w(c=1)�����߰������ƻ���
q
(
c
=
2
)
\textbf{q}(c=2)
q(c=2)����·�Ա���ʧ��������Ϊ:
L
CL3
=
?
E
(
w
,
q
,
v
;
c
)
��
D
~
log
??
p
(
c
�O
f
(
w
,
q
,
v
)
)
(4)
\mathcal{L}_{\text{CL3}}=-\mathbb{E}_{(\textbf{w},\textbf{q},\textbf{v};c)\sim\tilde{D}}\text{log}\;p(c|f(\textbf{w},\textbf{q},\textbf{v})) \tag{4}
LCL3?=?E(w,q,v;c)��D~?logp(c�Of(w,q,v))(4)
����,���ݼ�
(
w
,
q
,
v
;
c
)
��
D
~
(\textbf{w},\textbf{q},\textbf{v};c)\in\tilde{D}
(w,q,v;c)��D~����50%��ƥ����Ԫ��,25%���ƻ�
w
\textbf{w}
w��Ԫ���25%���ƻ�
q
\textbf{q}
q��Ԫ�顣Ϊ�˸�����Ч��ʵ��,���ƻ���
w
��
\textbf{w}'
w���Ǵ�����
w
\textbf{w}
w�о��Ȳ�����,����
q
��
\textbf{q}'
q���Ǵ�����
q
\textbf{q}
q�о��Ȳ����ġ������ϱ���ʾ,����ʹ�ñ��ƻ��𰸵���Ԫ��,����QA���ݼ��е�
q
\textbf{q}
q���
q
��
\textbf{q}'
q�����õ�����Ԫ��
(
w
,
q
��
,
v
)
(\textbf{w},\textbf{q}',\textbf{v})
(w,q��,v),�Ա���ʧ������ģ�����
VQA
\text{VQA}
VQA�����Ŀ�꺯��,������text-image�����������,Ԥѵ��ģ���ܹ���Ч����Ӧ
VQA
\text{VQA}
VQA,��������Ӧtext-image��������Ϊ�Ա�,�������·�Ա���ʧ�����ܹ������������϶��ܺõ�Ǩ�ơ�
3. Ԥѵ��ģ��
? ����Ԥѵ��������ģ�ͱ���,��ʾΪ
OSCAR+
B
\text{OSCAR+}_{B}
OSCAR+B?��
OSCAR+
L
\text{OSCAR+}_{L}
OSCAR+L?,��ֱ�ʹ��
BERT?base
\text{BERT base}
BERT?base��
BERT?large
\text{BERT large}
BERT?large�IJ���
��
BERT
\theta_{\text{BERT}}
��BERT?���г�ʼ����Ϊ��ȷ��ͼ����������������embeddings�ߴ���
BERT
\text{BERT}
BERT��ͬ,����ͨ��һ�����о���
W
\textbf{W}
W������ͶӰ��ת��λ����ǿ��������������ѵ������Ϊ
��
=
{
��
BERT
,
W
}
\theta=\{\theta_{\text{BERT}},\textbf{W}\}
��={��BERT?,W}��
OSCAR+
B
\text{OSCAR+}_{B}
OSCAR+B?����ѵ��1M steps,ѧϰ��Ϊ
1
e
?
4
1e^{-4}
1e?4����batch sizeΪ1024��
OSCAR+
L
\text{OSCAR+}_{L}
OSCAR+L?����ѧϰ��
3
e
?
5
3e^{-5}
3e?5��batch sizeΪ1024ѵ��������1M steps��
�ġ���Ӧ VL \text{VL} VL����
? ���߽�Ԥѵ��ģ��Ӧ����7�����ε� VL \text{VL} VL����,����5�����������2����������С�ڻ��Ҫ���������Լ������ԡ�
VQA & GQA
? ���������������������
VL
\text{VL}
VLģ�㷺ʹ�õ���������������Ҫģ�ͻ���ͼ�����ش���Ȼ�������⡣�ڱ�����,�ڹ㷺ʹ�õ�VQA v2.0��GQA���ݼ���ִ��ʵ�顣����ÿ������,ģ�ͻ�ӹ����Ĵ𰸼�������ѡһ���𰸡�����һ��
VLP
\text{VLP}
VLPģ��Ӧ����
VQA
\text{VQA}
VQA������,���߽����������⡢Ŀ���ǩ��Ŀǰ������������ƴ������������,Ȼ��
OSCAR+
\text{OSCAR+}
OSCAR+�����[CLS]��Ӧ������������һ��������صķ�����,���д�Ԥ�⡣
Image Captioning & NoCaps
? captioning�����Ƕ��ڸ�����ͼ������һ����Ȼ���Ե�caption�����DZ��о������㷺ʹ�õ�
VL
\text{VL}
VL��������,��ֹ2020��12��10��,
Image?Captioning?Leaderboard
\text{Image Captioning Leaderboard}
Image?Captioning?Leaderboard�г���260��ģ�͡�Ϊ��ʵ��caption����,ʹ��seq2seqĿ�꺯������
OSCAR+
\text{OSCAR+}
OSCAR+��ÿ��ѵ���������ᱻת��Ϊһ����Ԫ��,����Ԫ��һ��caption��ͼ�������������ϡ��Լ�Ŀ���ǩ������ɡ�����ڱ�caption��15%��tokens,��ʹ���������ݵı�����Ԥ�ⱻ�ڱε�tokens������ע�����������Լ��,ʹ��ֻ�ܹ�עcaption�е�ǰλ��֮ǰ��tokens��ģ�ⵥ�����ɵĹ��̡����е�caption token����ȫ��ע������ͼ�������Ŀ���ǩ�����ƶϵĹ�����,�ȱ���ͼ������Ŀ���ǩ�Լ��ض�token [CLS]��Ϊ���롣Ȼ��ģ��ͨ������[MASK] token������caption,������token�ĸ�������Ӵʱ��в���token��������,ǰ�����������е�[MASK] token���滻Ϊ������token,��������һ���µ�[MASK]������һ���ʵ�Ԥ�⡣��ģ�����[STOP] token�������ɵľ��ӳ���Ԥ��������,�����ɹ�����ֹ����COCO image captioning���ݼ���ִ��ͼ��ʵ�顣
Novel?Ojbect?Captioning?at?Scale
\text{Novel Ojbect Captioning at Scale}
Novel?Ojbect?Captioning?at?Scale��չ��ͼ��captioning����������ģ������ѵ������δ���ֵ���Ŀ�����������ѭ
NoCaps
\text{NoCaps}
NoCaps������,ʹ��Ԥ���
Visual?Genome
\text{Visual Genome}
Visual?Genome��
Open?Images
\text{Open Images}
Open?Images��ǩ���γ������ǩ����,��ֱ����
COCO
\text{COCO}
COCO��ѵ��
OSCAR+
\text{OSCAR+}
OSCAR+,������ӦԤѵ�����г�ʼ����
Image(-to-Text) Retrieval & Text(-to-Image) Retrieval
? ������������Ҫģ��������ͼ��;��ӵ����Ʒ��������,�����㷺Ӧ����ֱ�Ӻ�����ģ̬
VL
\text{VL}
VL��ʾ������������������ʽ��Ϊһ������������,����һ��ƥ���image-text��,�����ѡ��ͬ��ͼ����߲�ͬ�ľ������γɲ�ƥ��ԡ�[CLS]��ʾ��������������������Ԥ��һ������,�÷�����ʾ�������������Ƿ�ƥ�䡣�ڲ�����,Ԥ��ķ������������������image-text�ԡ����߱�������1K��5K COCO���Լ��ϵ�top-K���������
NLVR2
? �����ݼ�������Ȼ���Ժ�ͼ���������������������Ҫȷ�Ϲ���һ��ͼ����ı������Ƿ�Ϊ�档Ϊ����,�ȹ���������������,ÿ�����а��������ı�������һ��ͼ���ƴ��,���Ҵ�
OSCAR+
\text{OSCAR+}
OSCAR+�����������[CLS]��ƴ�����γ�����,���ڶ�����Ԥ�⡣