Ŀ¼
����:
��ͳ���������:
��ͳ�㷨ͨ��ͳ�Ƶķ������������й���,����̬�����ܽ�����Ч���롣���Է���̬������˲̬����Ч����̫���롣
AI��������ڴ�ͳ����,��������Ч���õ�����,������ʱ�ܵ��豸�������洢������������ơ�
һ. AI����ģ�͵Ȼ���֪ʶ:
AI����ʱ�������������ķ���,��ģ��ѧϰ������������Ϣ�� ģ������ʱ����������ź�,ģ�͵����ʱ�����������źš�
1.1 ������ģ�ͽṹ:
DNN
DNN������ÿ����Ԫ����ǰһ��ļ�Ȩƽ�����õ�һ��������������Ը����źŴ������н�ģ��
CNN
һά����(ʱ��)�Ͷ�ά����(TF)
RNN
LSTM, GRU,�Իع顢ʱ��ģ
1.2 ģ��ѵ������
��Ϊ�мල���ලѵ��������һ������мලѵ��
����:
- ͨ��Ԥ�����Ѵ����źŴ����� �����NN����������
- ͨ��NNԤ����Ƶ�����
- ������Ƶ�������label ����֮��IJ��,loss(����MSE��)
- Loss����,����ݶ��½�����ģ�Ͳ���
- �ظ�������,loss�����½���
1.3 ���AI����ģ��:
����
- NN����ģ��,����ģ�͵�Ԥ�����ͺ�������
- ���ʵ�loss
- ���ʵ������źź������źŵ����ݿ�
ʱ��ģ��:TasNet��
Ƶ��ģ��:RNNoise��CRN��
��. ����Ƶ�������AI����ģ��
���ƴ�ͳ��ά���˲�ͨ���������������,Ȼ���Ƶ��ÿһ��Ƶ���һ��С��1��ϵ��������������Щϵ����ΪƵ�����롣��ͳ�����ǻ���ͳ�Ƶķ����õ�Ƶ������,����NN�ķ�����ͨ��ģ��Ԥ���NN��
����Ƶ�������AI�����㷨����:
- �����źŹ�STFT,ʱ��תƵ��
- Ƶ������NN,NNԤ����ɾ��źŵ�Ƶ������
- Ƶ���ź� �� Ƶ������,�õ������Ƶ���ź�
- ������Ƶ���ź���iSTFT �õ����������ź�
������:�Ը������ȡģ���Ƿ�����,������ͬƵ��������ֲ���
��λ��:�Ը�������ʵ�����鲿��ֵ������,�õ���λ�ס�(-pai��pai)
��������ֻ�ı��˷�����û�иı���λ�ס���λ��û��ȷ��������������,��ģ�������˶�����λ���Ǻ����С�
���ڸ��������:����PHASEN��2020DNS���������ڵ�DCCRN��

��. AI����ģ�͵Ĺ��̲���
����AIģ����������ģ�Ͳ����洢�ϱȴ�ͳ����Ҫ����ߡ�
�����:
RTCʵʱ��Ƶ��Ӧ�ó�����,���봦����������ԡ�? ��Ϊδ������Ϣ���ò���������һЩ˫��ṹRNN�Ȳ����á�? ��һ��δ����Ϣ���ûص���ģ�͵Ľ��������½���
��˲�������һ���ӳٵķ�ʽ����ģ�͵Ľ���������? �����ڵ�I + m֡�����i֡���źš�? mһ�㲻����3�� ģ�Ϳ���look ahead ǰ3֡��
AI����ģ�ʹ洢�ռ�����������
ģ�Ͳ���ʱ,�������ֻ���IOT���ƶ��˲���,�豸�������ʹ洢 �ռ䶼���ܵ����ơ�
��ͬģ�͵��������ӶȺͲ������ֲ�:

ģ��ѡ��:
CNN�ľ������ܸ������Բ�������С��DNN��RNN���������������,�������ϴ�����ƶ��˵ȴ洢�ռ�С���豸����㷨ʱ,�ᾡ��ѡ��CNN,��CNN��ϱ�Ľṹ��ѹ����������
��������:
��һ�������RNN��DNN�ȿ���ͨ�����������ȷ�ʽ��ģ�ͽ���ѹ������float32 תint8bit������? �������ģ�;����������,CNN�Ȳ��ʺ�,��RNN��DNN��������������,û��ô���С�
����(����/Ӳ��/IO/����ƽ̨�� ):
ѡ������:������RNNoise ����BFCC ����ѹ����Ƶ��������Ϊ����,����������
�ض���Ӳ��:�ص�ļ���оƬ֧�ֲ�ͬ���ȵļ���,����������ٶȸ��졣
���ݶ�ȡ�Ż�:��ģ�Ͳ�������������,�����ڴ�������ȡ���ŵķ�ʽ��������,ʵ��IO�ļ���
���ú��ʲ���:
����ͼ���õ�AIģ�Ͳ���
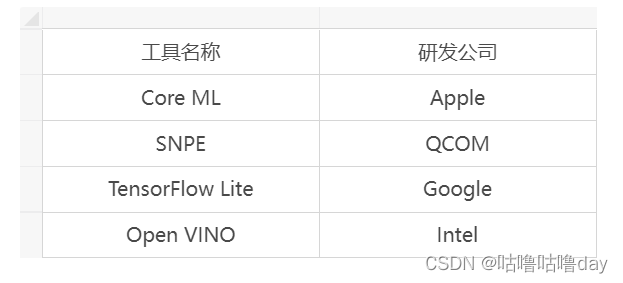
?
�����
?1��Luo Y, Mesgarani N. Tasnet: time-domain audio separation network for real-time, single-channel speech separation[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 696-700.
2��Luo Y, Mesgarani N. Conv-tasnet: Surpassing ideal time�Cfrequency magnitude maskingfor speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2019, 27(8): 1256-1266.
3��Valin J M. A hybrid DSP/deep learning approach to real-time full-band speech enhancement[C]//2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018: 1-5.
4��Strake M, Defraene B, Fluyt K, et al. Fully convolutional recurrent networks for speech enhancement[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 6674-6678.
5��Ma C, Li D, Jia X. Optimal scale-invariant signal-to-noise ratio and curriculum learning for monaural multi-speaker speech separation in noisy environment[C]//2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2020: 711-715.
6��Yin D, Luo C, Xiong Z, et al. PHASEN: A phase-and-harmonics-aware speech enhancement network[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 9458-9465.
7��Hu Y, Liu Y, Lv S, et al. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement[J]. arXiv preprint arXiv:2008.00264, 2020.
�ܽ��Լ��Ϳγ̡��㶨��Ƶ������