迁移学习
深度学习中,最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。所以例如,也许你已经训练好一个神经网络,能够识别像猫这样的对象,然后使用那些知识,或者部分习得的知识去帮助您更好地阅读 x 射线扫描图,这就是所谓的迁移学习。
example
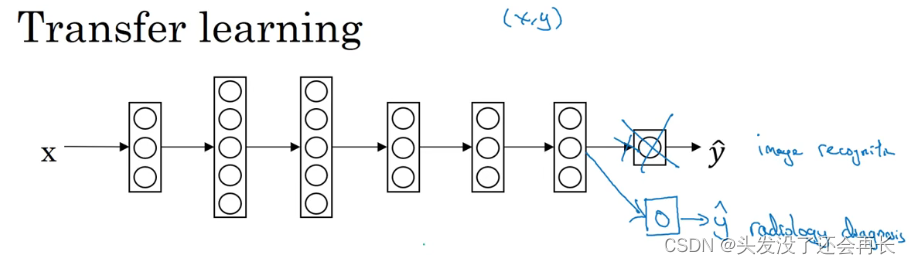
假设你已经训练好一个图像识别神经网络,所以你首先用一个神经网络,
并在(𝑥, 𝑦)对上训练,其中𝑥是图像,𝑦是某些对象,图像是猫、狗、鸟或其他东西。
如果你把这个神经网络拿来,然后让它适应或者说迁移,在不同任务中学到的知识,比如放射科诊断,就是说阅读𝑋射线扫描图。
你可以做的是把神经网络最后的输出层拿走,就把它删掉,还有进入到最后一层的权重删掉,然后为最后一层重新赋予随机权重,然后让它在放射诊断数据上训练。
具体来说:在第一阶段训练过程中,当你进行图像识别任务训练时,你可以训练神经网络的所有常用参数,所有的权重,所有的层,然后你就得到了一个能够做图像识别预测的网络。
在训练了这个神经网络后,要实现迁移学习,你现在要做的是,把数据集换成新的(𝑥, 𝑦)对,现在这些变成放射科图像,而𝑦是你想要预测的诊断,你要做的是初始化最后一层的权重,让我们称之为𝑤[𝐿]和𝑏[𝐿]随机初始化。
经验规则是,如果你有一个小数据集,就只训练输出层前的最后一层,或者也许是最后一两层。但是如果你有很多数据,那么也许你可以重新训练网络中的所有参数。
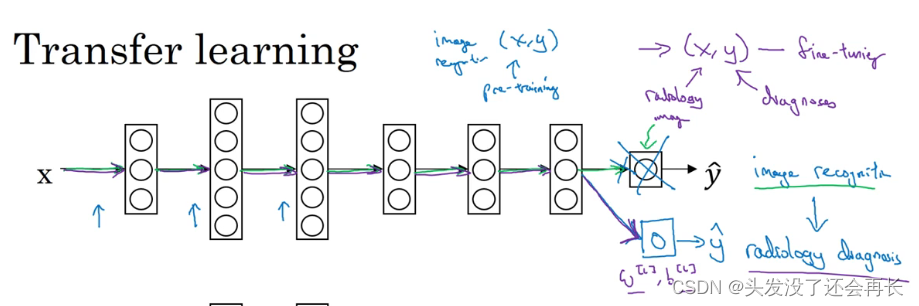
预训练和微调:
如果你重新训练神经网络中的所有参数,那么这个在图像识
别数据的初期训练阶段,有时称为预训练(pre-training),因为你在用图像识别数据去预先初始化,或者预训练神经网络的权重。然后,如果你以后更新所有权重,然后在放射科数据上训练,有时这个过程叫微调(fine tuning)。
Q:为什么这样做有效果呢?
A:有很多低层次特征,比如说边缘检测、曲线检测、阳性对象检测(positive
objects),从非常大的图像识别数据库中习得这些能力可能有助于你的学习算法在放射科诊断中做得更好,算法学到了很多结构信息,图像形状的信息,其中一些知识可能会很有用,所以学会了图像识别,它就可能学到足够多的信息,可以了解不同图像的组成部分是怎样的,学到线条、点、曲线这些知识,也许对象的一小部分,这些知识有可能帮助你的放射科诊断
网络学习更快一些,或者需要更少的学习数据。
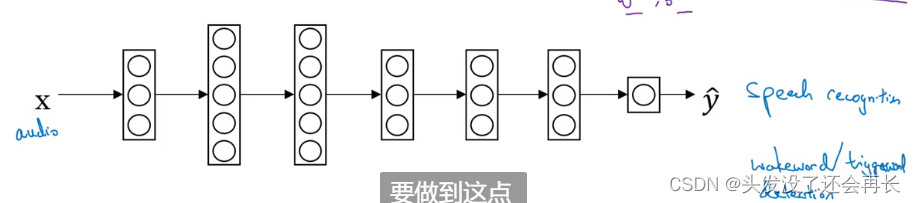
另外一个例子是语音识别系统:假设你已经训练出一个语音识别系统,现在𝑥是音频或音频片段输入,而𝑦是听写文本,所以你已经训练了语音识别系统,让它输出听写文本。
现在我们说你想搭建一个“唤醒词”或“触发词”检测系统,所谓唤醒词或触发词就是我们说的一句话,可以唤醒家里的语音控制设备,比如你说“Alexa”可以唤醒一个亚马逊 Echo 设备,或用“OK Google”来唤醒 Google 设备,用"Hey Siri"来唤醒苹果设备,用"你好百度"唤醒一个百度设备。
要做到这点,你可能需要去掉神经网络的最后一层,然后加入新的输出节点,但有时你可以不只加入一个新节点,或者甚至往你的神经网络加入几个新层,然后把唤醒词检测问题的标签𝑦喂进去训练。再次,这取决于你有多少数据,你可能只需要重新训练网络的新层,也许你需要重新训练神经网络中更多的层。
Q:迁移学习什么时候有意义?
A:
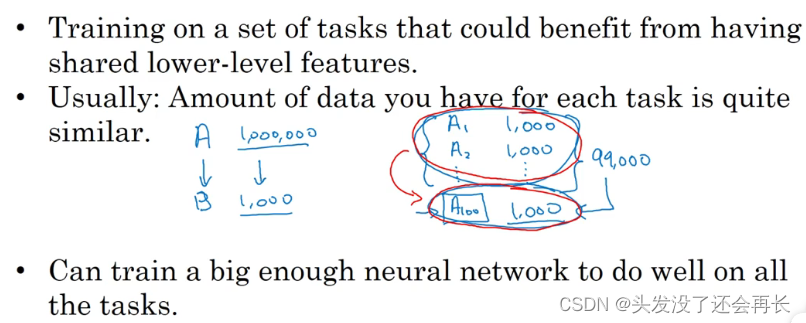
所以总结一下,迁移学习最有用的场合是,如果你尝试优化任务𝐵的性能,通常这个任务数据相对较少,例如,在放射科中你知道很难收集很多𝑋射线扫描图来搭建一个性能良好的放射科诊断系统,所以在这种情况下,你可能会找一个相关但不同的任务,如图像识别,其中你可能用 1 百万张图片训练过了,并从中学到很多低层次特征,所以那也许能帮助网络在任务𝐵在放射科任务上做得更好,尽管任务𝐵没有这么多数据。
通俗来讲,如果有想要训练的任务B已经有很多数据了,且比相关的任务A数据多,那就直接用B的数据训练就好了,不必用A的数据训练再迁移到任务B上,没有什么意义。

多任务学习
在迁移学习中,你的步骤是串行的,你从任务𝐴里学习知识然后迁移到任务𝐵。在
多任务学习中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
example
假设你在研发无人驾驶车辆,那么你的无人驾驶车可能需要同时检
测不同的物体,比如检测行人、车辆、停车标志,还有交通灯各种其他东西。比如在下面这个例子中,图像里有个停车标志,然后图像中有辆车,但没有行人,也没有交通灯。
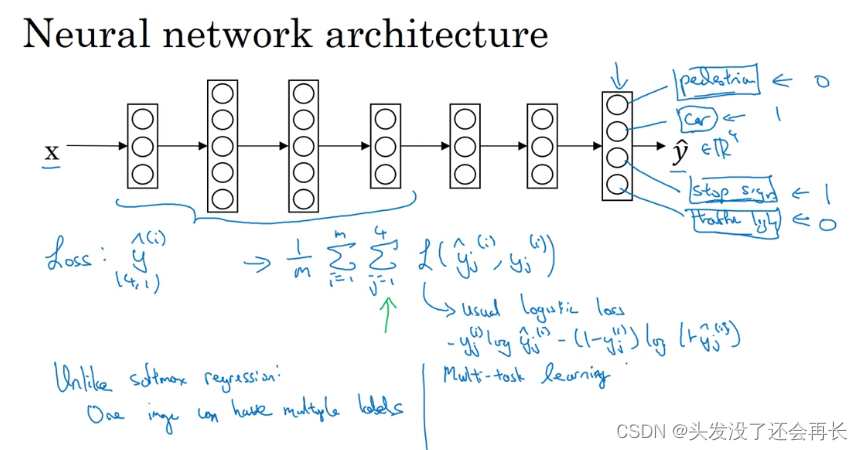
如果这是输入图像𝑥(𝑖),那么这里不再是一个标签 𝑦(𝑖),而是有 4 个标签。在这个例子中,没有行人,有一辆车,有一个停车标志,没有交通灯。所以 𝑦(𝑖)是个 4×1 向量。
如果你从整体来看这个训练集标签和以前类似,我们将训练集的标签水平堆叠起来,像这样𝑦(1)一直到𝑦(𝑚),不过现在𝑦(𝑖)是 4×1 向量,所以这些都是竖向的列向量,所以这个矩阵𝑌现在变成4 × 𝑚矩阵。而之前,当𝑦是单实数时,这就是1 × 𝑚矩阵。
那么你现在可以做的是训练一个神经网络,来预测这些𝑦值,你就得到这样的神经网络,输入𝑥,现在输出是一个四维向量𝑦。请注意,这里输出我画了四个节点,所以第一个节点就是我们想预测图中有没有行人,然后第二个输出节点预测的是有没有车,这里预测有没有停车标志,这里预测有没有交通灯,所以这里𝑦^是四维的。
要训练这个神经网络,你现在需要定义神经网络的损失函数,对于一个输出𝑦^,是个 4维向量,对于整个训练集的平均损失:
这些单个预测的损失,所以这就是对四个分量的求和,行人、车、停车标志、交通灯,而这个标志𝐿指的是 logistic 损失,我们就这么写:
Q:与softmax有什么不同?
A:整个训练集的平均损失和之前分类猫的例子主要区别在于,现在你要对𝑗 = 1到4求和,这与 softmax 回归的主要区别在于,与 softmax 回归不同,softmax 将单个标签分配给单个样本。而这张图可以有很多不同的标签,所以不是说每张图都只是一张行人图片,汽车图片、停车标志图片或者交通灯图片。你要知道每张照片是否有行人、或汽车、停车标志或交通灯,多个物体可能同时出现在一张图里。所以你不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,那类物体有没有出现在图中。
如果你训练了一个神经网络,试图最小化这个成本函数,你做的就是多任务学习。因为你现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉你,每张图里面有没有这四个物体。
同时,不是所有的图像都是有标签的,也不是所有标签都存在。事实证明,多任务学习也可以处理图像只有部分物体被标记的情况。即使是这样的数据集,你也可以在上面训练算法,同时做四个任务,即使一些图像只有一小部分标签,其他是问号或者不管是什么。然后你训练算法的方式,即使这里有些标签是问号,或者没有标记,这就是对𝑗从 1 到 4 求和,你就只对带 0 和 1 标签的𝑗值求和,所以当有问号的时候,你就在求和时忽略那个项,这样只对有标签的值求和,于是你就能利用这样的数据集。

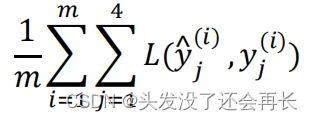
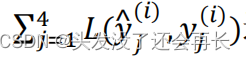
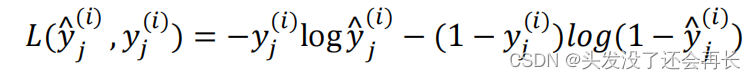
Q:多任务学习什么时候有意义?
A:
最后多任务学习往往在以下场合更有意义,当你可以训练一个足够大的神经网络,同时做好所有的工作,所以多任务学习的替代方法是为每个任务训练一个单独的神经网络。所以不是训练单个神经网络同时处理行人、汽车、停车标志和交通灯检测。你可以训练一个用于行人检测的神经网络,一个用于汽车检测的神经网络,一个用于停车标志检测的神经网络和一个用于交通信号灯检测的神经网络。
端到端学习
深度学习中最令人振奋的最新动态之一就是端到端深度学习的兴起,那么端到端学习到底是什么呢?简而言之,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理。那么端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它。
example
以语音识别为例,你的目标是输入𝑥,比如说一段音频,然后把它映射到一个输出𝑦,就是这段音频的听写文本。所以传统上,语音识别需要很多阶段的处理。
首先你会提取一些特征,一些手工设计的音频特征,也许你听过 MFCC,这种算法是用来从音频中提取一组特定的人工设计的特征。在提取出一些低层次特征之后,你可以应用机器学习算法在音频片段中找到音位,所以音位是声音的基本单位,比如说“Cat”这个词是三个音节构成的,Cu-、Ah-和 Tu-,算法就把这三个音位提取出来,然后你将音位串在一起构成独立的词,然后你将词串起来构成音频片段的听写文本。
所以和这种有很多阶段的流水线相比,端到端深度学习做的是,你训练一个巨大的神经网络,输入就是一段音频,输出直接是听写文本。
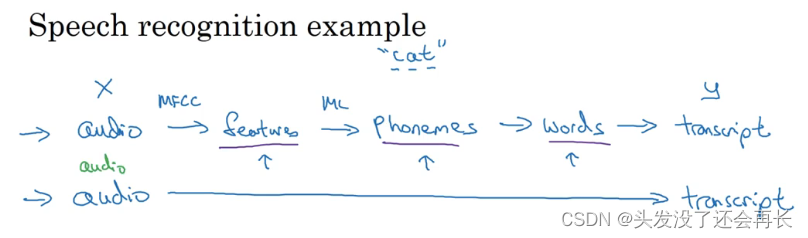
事实证明,端到端深度学习的挑战之一是,你可能需要大量数据才能让系统表现良好,比如,你只有 3000 小时数据去训练你的语音识别系统,那么传统的流水线效果真的很好。但当你拥有非常大的数据集时,比如 10,000 小时数据或者 100,000 小时数据,这样端到端方法突然开始很厉害了。
下面这张图是人脸识别门禁,是百度的林元庆研究员做的。这是一个相机,它会拍下接近门禁的人,如果它认出了那个人,门禁系统就自动打开,让他通过,所以你不需要刷一个 RFID 工卡就能进入这个设施。
那么如何搭建这个系统呢?
你可以做的第一件事是,看看相机拍到的照片,你知道,有人接近门禁了,所以这可能是相机拍到的图像𝑥。有件事你可以做,就是尝试直接学习图像𝑥到人物𝑦身份的函数映射,事实证明这不是最好的方法。其中一个问题是,人可以从很多不同的角度接近门禁,他们可能在绿色位置,可能在蓝色位置。有时他们更靠近相机,所以他们看起来更大,有时候他们非常接近相机,那照片中脸就很大了。在实际研制这些门禁系统时,他不是直接将原始照片喂到一个神经网络,试图找出一个人的身份。
相反,迄今为止最好的方法似乎是一个多步方法,首先,你运行一个软件来检测人脸,所以第一个检测器找的是人脸位置,检测到人脸,然后放大图像的那部分,并裁剪图像,使人脸居中显示,然后就是这里红线框起来的照片,再喂到神经网络里,让网络去学习,或估计那人的身份。
比起一步到位,一步学习,把这个问题分解成两个更简单的步骤。首先,是弄清楚脸在哪里。第二步是看着脸,弄清楚这是谁。这第二种方法让学习算法,或者说两个学习算法分别解决两个更简单的任务,并在整体上得到更好的表现。
Q:在第二步,弄清这个人是不是办公楼的员工是怎么做的呢?
A:训练网络的方式就是输入两张图片,然后你的网络做的就是将输入的两张图比较一下,判断是否是同一个人。比如你记录了 10,000 个员工 ID,你可以把红色框起来的图像快速比较……也许是全部 10,000 个员工记录在案的 ID,看看这张红线内的照片,是不是那10000 个员工之一,来判断是否应该允许其进入这个设施或者进入这个办公楼。这是一个门禁系统,允许员工进入工作场所的门禁。

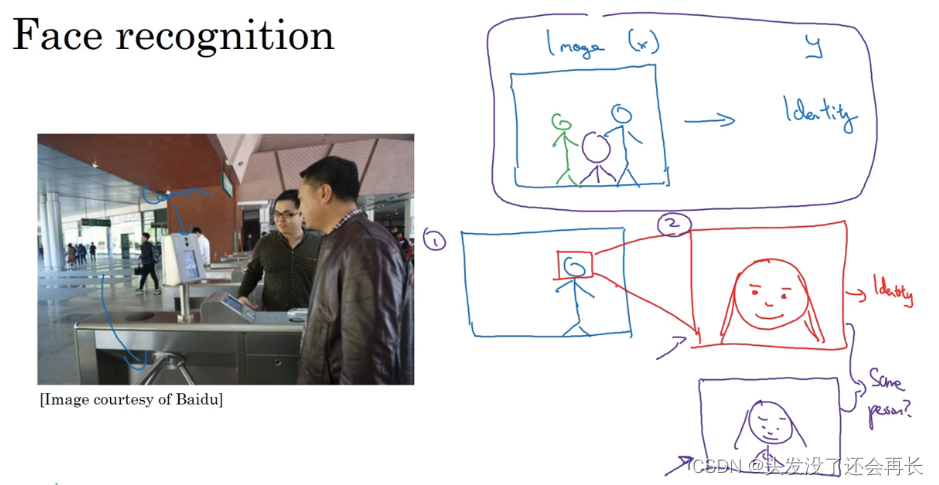
Q:为什么两步法更好?
A:实际上有两个原因。一是,你解决的两个问题,每个问题实际上要简单得多。但第二,两个子任务的训练数据都很多。
实际上,把这个分成两个子问题,比纯粹的端到端深度学习方法,达到更好的表现。不过如果你有足够多的数据来做端到端学习,也许端到端方法效果更好。但在今天的实践中,并不是最好的方法。
More examples
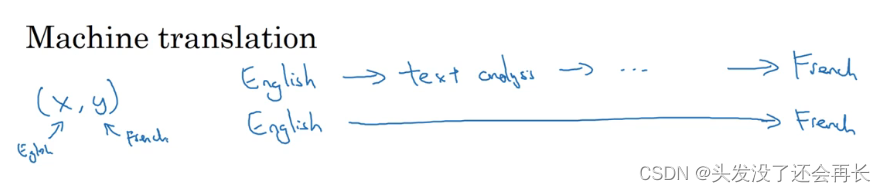
机器翻译:
传统上,机器翻译系统也有一个很复杂的流水线,比如英语机翻得到文本,然后做文本分析,基本上要从文本中提取一些特征之类的,经过很多步骤,你最后会将英文文本翻译成法文。因为对于机器翻译来说的确有很多(英文,法文)的数据对,端到端深度学习在机器翻译领域非常好用,那是因为在今天可以收集𝑥 ? 𝑦对的大数据集,就是英文句子和对应的法语翻译。所以在这个例子中,端到端深度学习效果很好。
通过X光照片,判断孩子年龄:
处理这个例子的一个非端到端方法,就是照一张图,然后分割出每一块骨头,所以就是分辨出那段骨头应该在哪里,那段骨头在哪里,那段骨头在哪里,等等。然后,知道不同骨骼的长度,你可以去查表,查到儿童手中骨头的平均长度,然后用它来估计孩子的年龄,所以这种方法实际上很好。相比之下,如果你直接从图像去判断孩子的年龄,那么你需要大量的数据去直接训练。据我所知,这种做法今天还是不行的,因为没有足够的数据来用端到端的方式来训练这个任务。
所以端到端深度学习系统是可行的,它表现可以很好,也可以简化系统架构,让你不需要搭建那么多手工设计的单独组件,但它也不是灵丹妙药,并不是每次都能成功。

是否使用端到端的深度学习
端到端的深度学习的优缺点:
如果你在构建一个新的机器学习系统,而你在尝试决定是否使用端到端深度学习,我认为关键的问题是,你有足够的数据能够直接学到从𝑥映射到𝑦足够复杂的函数吗?
