Title: Temporal Alignment Networks for Long-term Video
作者:Tengda Han,?Weidi Xie, and?Andrew Zisserman
发表单位:Visual Geometry Group, University of Oxford and Shanghai Jiao Tong University
关键词:clip、video
论文:https://arxiv.org/pdf/2204.02968.pdf
首先我并不是做视频的方向,如有错误,欢迎指正。
摘要
本文的目标是建立一个时间对齐网络,该网络吸收长期视频序列和相关的文本句子,以便:(1)确定句子是否与视频对齐;和(2)如果可对齐,则确定其对齐。面临的挑战是从大规模数据集(如HowTo100M)中训练这样的网络,其中相关的文本句子具有显著的噪声,并且在相关时只有弱对齐。
除了提出对齐网络外,我们还做出了四个贡献:(i)我们描述了一种新的协同训练方法,该方法能够在噪声较大的情况下,不使用手动注释对原始教学视频进行去噪和训练;(ii)为了对对齐性能进行基准测试,我们手动curate了一个10小时的HowTo100M子集,总共80个视频,其时间描述很少。我们提出的模型,经过HowTo100M的训练,在这个对齐数据集上比强基线(CLIP,MIL-NCE)有很大的优势;(iii)我们将零镜头设置下的训练模型应用于多个下游视频理解任务,并实现最先进的结果,包括YouCook2上的文本视频检索,以及早餐动作上的弱监督视频动作分割;(iv)我们使用automaticallyaligned HowTo100M注释对主干模型进行端到端微调,并在下游动作识别任务上获得更好的性能。
预备知识?
视频对齐
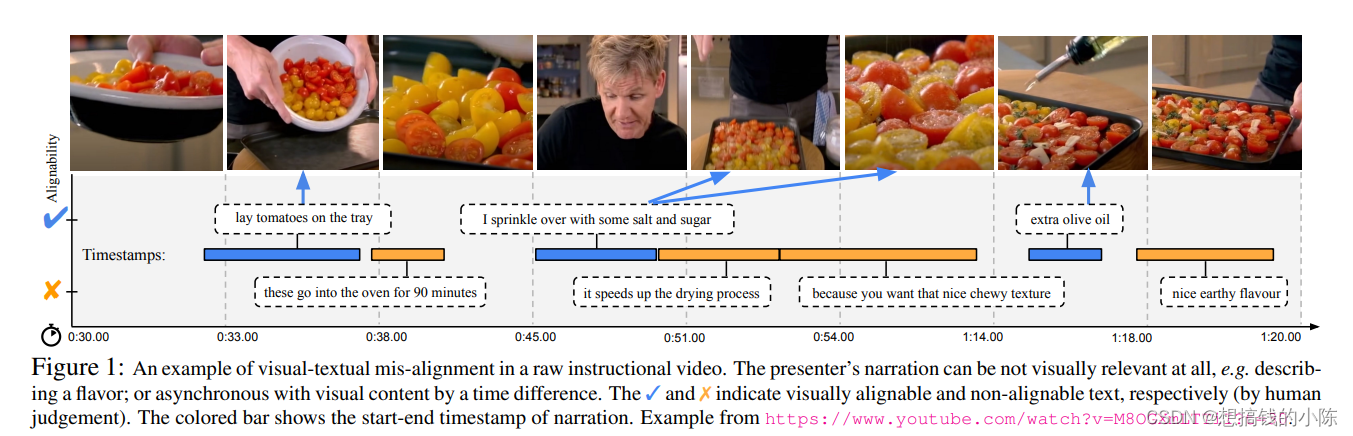
如下图所示,就是希望文字和图片能够相对应,蓝色代表的是可对齐文本,橙色代表的是这个文本不可对齐(因为这句话描述的可能是实物的味道,时间等)。
?
任务描述
给定一个未修剪的视频X={I,S},其中I={I1,I2, ..., IT},T 代表有T个帧。S={S1,...,Sk},K代表K个句子(按时间排序)。对于第k个句子,我们有对应的时间戳([t_k^start, t_k^end])。我们的目标是通过一个非线性函数得到{y_hat, A_hat}.
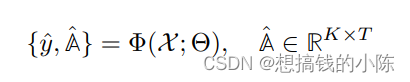
其中,y_hat是所有句子的一个二分类数,所以维度是K*2.这个二分类数代表这个句子是否是一个可对齐文本。A_hat是一个图片与文本的对齐矩阵。
TAN
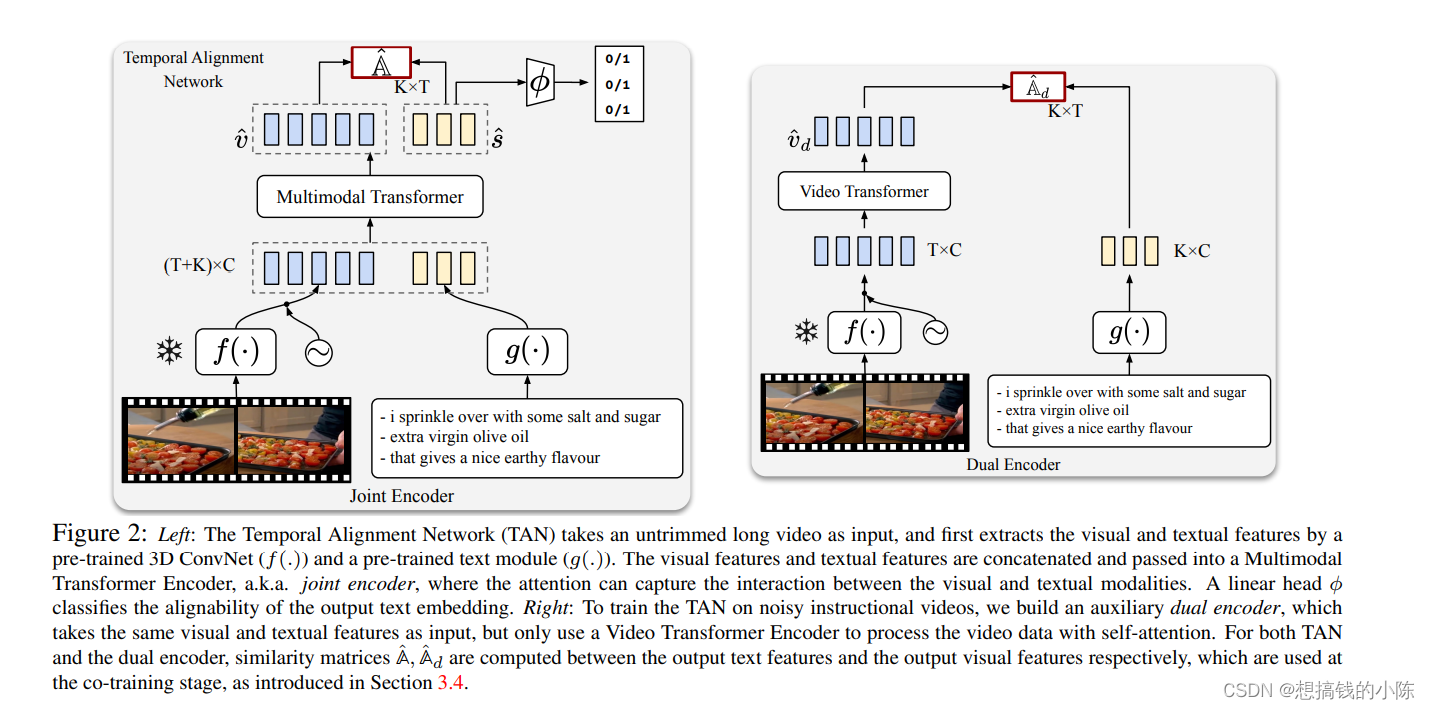
TAN的结构如上图左所示。图片通过S3D-G backbone提取特征,得到vision token,文本通过word2vec embedding+ 2 linear 得到text token,两者进通过一个multimodal transformer得到具有交互信息的和?
。这两者在通过cosine similarity计算得到一个对齐矩阵。同时,?
用1个linear layer来输出y_hat.公式总结如下:
?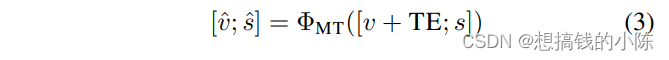
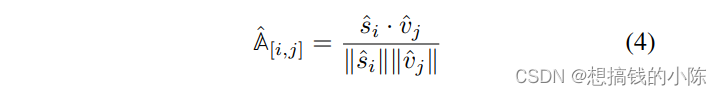

?
?Training
用对比学习的方式学习。InfoNCE。公式如图。(这块部分有点不太明白)

?Co-training
co-training是核心,作者首先提出了一个dual encoder,如图2的右所示,dual encoder是没有信息交互的,只有在最后计算矩阵的时候有信息交互。作者认为这样可以让模型更加敏感。

如图3(a)与图3(b)所示,这是TAN和dual encoder的相似度矩阵,联合TAN和Dual encoder的输出,将TAN的输出与Dual-Encoder的输出计算IoU,如果超过某个阈值,那就将2者的输出结果做一个并为pseudo-labels。如果没有超过阈值,那就保留之前的标签。
?
?