
0 导读
这是我写在公众号里的一篇文章,在此分享到CSDN上,一来是希望能和CSDN上的朋友们一起交流学习CV算法以及相应的知识,也欢迎大家关注我的公众号WeThinkIn。
公众号原文:
【CV算法内功】获得CVPR2022 workshop双赛道冠军之后的总结与思考
1 写在前面
【CV算法内功】栏目专注于分享关于CV算法与机器学习在业务侧,研究侧,学习侧的一些经验与总结心得,欢迎大家一起交流学习
大家好,我是Rocky。
我们团队参加了CVPR2022 workshop的算法竞赛,在AI安全方向获得了双赛道的冠军。在压力,竞争,学习,榜单更新,边做边学,及时复盘等关键词汇填充的竞赛周期里,我收获了很多,成长了很多,对算法竞赛也有了新的思考与感悟。
故本文不单单讲述这两个赛道的竞赛总结,更多的是我对算法竞赛的整体思考与方法论提炼。在写这篇文章的时候,难免会想起2019年第一次参加算法竞赛的场景,以及对时间流逝的唏嘘。
So,enjoy(与本文的BGM一起食用更佳哦):
2 干货篇
2.1 目录先行
- CVPR2022 workshop双赛道赛题逻辑
- CVPR2022 workshop双赛道冠军方案
- 算法竞赛厮杀方法论
- 算法竞赛的成果沉淀
2.2 CVPR2022 workshop双赛道赛题逻辑
我们参加了Classification Task Defense 和Open Set Defense两个赛道的比赛。这两个赛题方向聚焦AI安全,具备很高的实际价值,对AI安全的发展提出了很多的思考。

【一】Classification Task Defense:
这个赛道的主要逻辑是训练一个具备强泛化性能与鲁棒性能的模型,使其能够抵御线上的白盒攻击,黑盒攻击以及corruptions样本的同时,在干净测试数据上依然能有较好的性能。
核心难点:
1)数据集本身有很多相似类别,属于精细化分类范畴;
2)黑盒攻击的强度和类型不设限制,且一个样本可能存在黑盒攻击和image corruptions叠加的情况;
3)初赛中最后会有50%的全新测试集,来考验模型的泛化性能;
4)决赛中线上测试集有20%存在白盒攻击,且攻击类型多样;
5)比赛中不能使用模型融合,预训练模型,额外数据,且决赛中模型的size和FLOPs限制在120M和5G以内。
评价指标:

【二】Open Set Defense:
第二赛道的主要逻辑则是训练一个对抗样本检测器,让其能在开放世界中准确区分对抗样本和干净样本。线上测试集中有各式各样的对抗样本,其中不乏对抗扰动极其微小的对抗样本,人眼视觉系统下几乎与干净样本无异,这种情形显然对于检测模型来说是一个较大的挑战。
核心难点:
1)干净样本和一些对抗样本的特征差别微小,人类视觉系统都无法分辨,如何约束定义这个问题是一个挑战;
2)对抗样本的强度和类型不设限制,且一个样本可能存在多个不同类型对抗扰动叠加的情况;
3)初赛中最后会有50%的全新测试集,来考验模型的泛化性能;
4)对抗样本中的扰动特征容易与color_jitter,auto_augment,image corruptons等操作后的特征混淆;
5)比赛中不能使用模型融合,预训练模型,额外数据,且决赛中模型的size和FLOPs限制在120M和5G以内。
评价指标:

2.3 CVPR2022 workshop双赛道冠军方案
【一】Classification Task Defense:
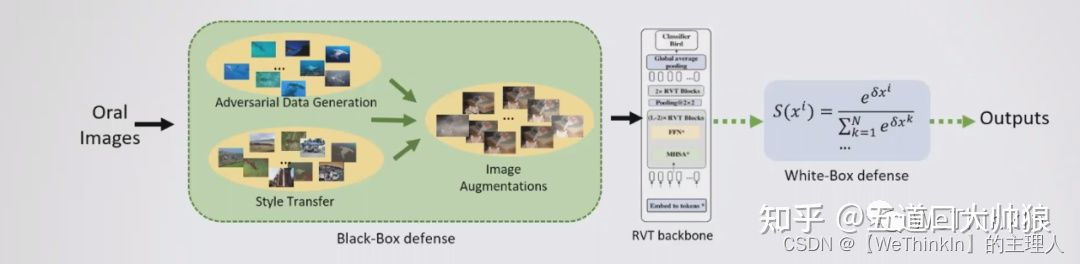
我们的方案核心聚焦在下面几个方面:
1.线下数据增强侧:a)我们使用了FGSM, BIM, RFGSM, CW, PGD, PGDL2, EOTPGD, MIFGSM, APGD, APGDT, AutoAttack, DeepFool, DIFGSM, NIFGSM, TIFGSM, UPGD, Adv_patch等攻击算法生成相应的对抗样本,每次攻击都从三个扰动限制中随机选择一个。针对一张图片可能会添加多个对抗噪声的情况,我们使用上述17种攻击算法进行二阶段的攻击,进一步增加对抗样本的多样性。b)生成风格转换数据:我们使用了cartoon,style transform,GAN,Amplitude-Phase Recombination 这4类增强方法生成风格转换图片。
2.在线数据增强侧:常规在线增强使用了auto_augment,特殊在线数据增强的方式包括了’Shot Noise’, ‘Impulse Noise’, ‘Defocus Blur’, ‘Glass Blur’,‘Motion Blur’, ‘Zoom Blur’, ‘Snow’, ‘Frost’, ‘Fog’, ‘Brightness’, ‘Contrast’, ‘Elastic’, ‘Pixelate’, ‘JPEG’, ‘Speckle Noise’, ‘Gaussian Blur’, ‘Gaussian Noise’, ‘Spatter’, 'Saturate’等,在训练时随机选取1到3个方式进行增强,每个增强方式选取随机1-3个不同强度等级。并且对输入图像加入中值滤波(滤波核大小在3和5之间随机取值),去除噪点后进行训练。

3.模型侧:我们对多种模型结构包括但不限于RVT, Swin,RresNet, Inception, ShuffleNet, MobileNet进行了横向比较,我们最终选取了RVT作为我们的baseline。RVT能得到一个较好的baseline得分,且RVT本身做了对抗防御的设计,易于进行进一步优化。在ResNet分支中的GP_ResNet50也具备很强的对抗鲁棒性,但其模型大小超过了限制,故只能舍弃。
4.训练侧:使用对抗训练,Model Exponential Moving Average的参数更新策略,图像随机擦除,mixup,cutmix以及余弦退火学习率等优化手段。
5.防御侧:我们针对白盒攻击设计防御策略。我们设计了基于Softmax的梯度隐藏策略,破坏对抗噪声结构的防御策略和多防御算法预处理策略等。
一些展望(后续可以继续实验与挖掘的点):
1.设计可以防御白盒攻击的模型结构。
2.设计更多可以防御白盒攻击的预处理/后处理算法。
3.设计更加温和的对抗训练逻辑,让模型能抵御对抗攻击的同时,其在常规测试集上的性能稳定。
【二】Open Set Defense:
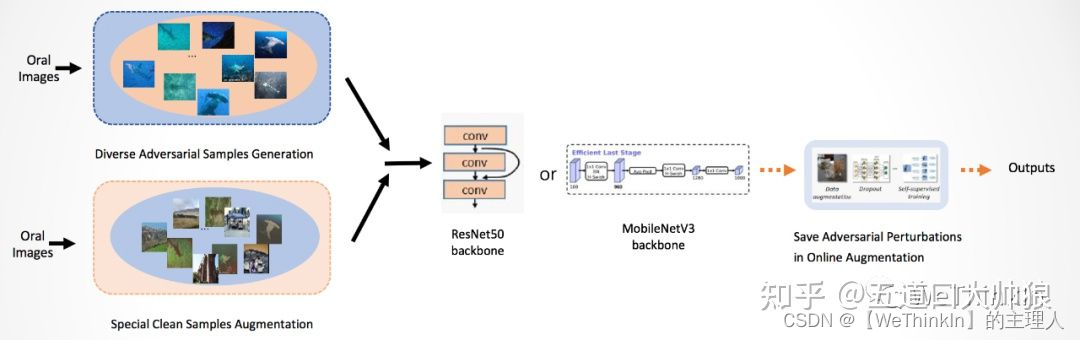
我们的方案核心聚焦在下面几个方面:
1.对抗样本侧:我们生成了类型丰富的对抗样本。我们使用了FGSM, BIM, RFGSM, CW, PGD, PGDL2, EOTPGD, MIFGSM, APGD, APGDT, AutoAttack, DeepFool, DIFGSM, NIFGSM, TIFGSM, UPGD, Adv_patch等攻击算法生成相应的对抗样本,每次攻击都从三个扰动限制中随机选择一个。针对一张图片可能会添加多个对抗噪声的情况,我们使用上述17种攻击算法进行二阶段的攻击,进一步增加对抗样本的多样性。

2.干净样本侧:我们设计了特殊的干净样本增强策略。我们使用了cartoon,style transform,GAN,Amplitude-Phase Recombination 这4类增强方法生成增强数据作为干净样本类别。在实验中我们发现除了cartoon之外,其余增强都会产生副作用,降低模型得分。于是最后选用原始数据集与cartoon化的样本作为干净样本类别。

3.模型侧:我们使用了常规的ResNet50和轻量型模型MobileNetV3分别进行实验和优化。一开始,我们使用ResNet50,Frelu_ResNet,CNSN_ResNet,ResNext50,MobileNetv3,EfficientNetB0,RVT等模型进行消融实验,发现在第一赛道效果优异的RVT模型在这个赛道并不适合,我们认为其数据分块输入的逻辑会破坏对抗样本的特征。
4.训练侧:我们使用了对抗训练,Model Exponential Moving Average参数更新策略,mixup,cutmix以及余弦退火学习率等优化手段。其中对抗训练不太适合这个任务,会降低线上得分。
- 训练预处理侧:我们设计了特殊的在线增强来防止对抗样本的特征在预处理阶段丢失。在训练初期,我们发现在超参数一致的情况下,训练的模型得分波动很大,通过观察对抗样本与干净样本的特征差异,结合赛题给出的无限制对抗扰动情形,我们认为可能是模型对微小的对抗扰动捕捉能力较差造成的。而在timm库自带的预处理函数create_transform中,会有很多破坏对抗扰动特征的预处理操作。我们修改RandomResizedCropAndInterpolation函数中的参数,减小crop和resize的程度,并关闭了预处理中auto_augment和color_jitter操作,尽可能减少在预处理阶段破坏对抗样本类别特征的情况,以稳定模型的训练与性能。
6.训练数据比例设计:我们发现在干净样本与对抗样本的比例约为1:1时,MobileNetv3能取得最好的得分70.37。当干净样本与对抗样本的比例约为1:2时,ResNet50能取得最好的得分70.13。MobileNetv3的参数约是ResNet50的1/9,但是能达到和ResNet50同量级的效果,甚至有微微的超过,我们认为是MobileNetv3的模型结构适合捕捉对抗扰动的特征。
一些展望(后续可以继续实验与挖掘的点):
1.我们在实验中发现检测模型对光照以及颜色抖动十分敏感,模型很容易将颜色抖动的干净样本误识别成对抗样本。
2.我们在实验中发现检测模型对一些常规aug(imgaug库里的增强)也十分敏感,模型很容易将常规aug的干净样本误识别成对抗样本。
3.对抗样本高维特征的提取与表达。我们认为有些对抗样本虽然与干净样本在低维空间中差异微小,但在高维特征中,这种差异会被放大,有助于检测模型的工作。
4.设计适合捕捉对抗扰动的模型结构。(硬核的点,但是我们在竞赛中有试过)
2.4 算法竞赛厮杀方法论
在本章节,我想聚焦于算法竞赛厮杀方法论的总结与沉淀。

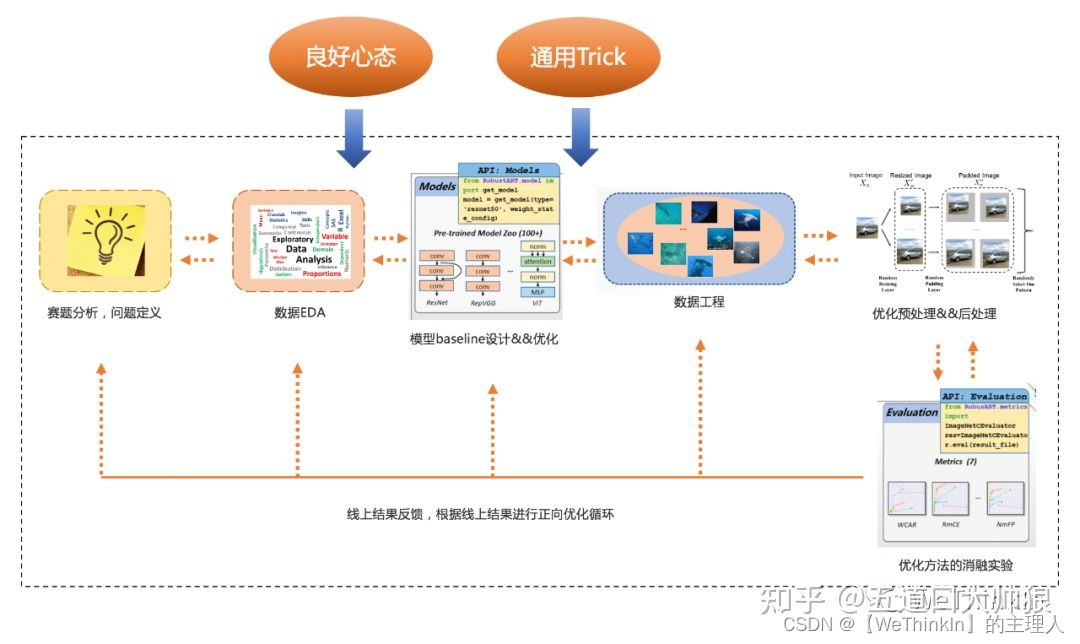
不管是哪个细分领域的算法竞赛,都有以下的通用方法论:
- 赛题分析,问题定义。如何提炼赛题核心,并进行建模非常关键。
2.数据EDA。磨刀不误砍柴工,对数据进行分析挖掘,有时往往能发现一些优化方向,对数据整体特征也会有较好的把握。
3.模型baseline设计&&优化。一般选择该细分领域的SOTA模型或者竞赛打榜热门模型做baseline入场;再针对竞赛赛题的特点对模型结构进行针对性的优化。
4.数据工程。针对赛题特点对数据进行增强,包括线下增强和线上增强等。
5.优化预处理&&后处理。通过一些前处理算法与后处理算法对模型进行更多的约束,提升模型综合性能。
6.优化方法的消融实验。高效的消融实验非常重要,因为深度学习模型训练时间一般较久,如果一个实验跑一周的话是完全不行的。
7.线上结果反馈,根据线上结果倒逼1-6步的推进,从而形成正向的优化循环。
8.整个竞赛过程保持良好的心态。竞赛短则1-2个月,长则半年,不同的竞赛时间段都需要保持一个合适的心态,在竞赛前期不要放松,在竞赛中期不要焦躁,在竞赛后期冲刺时保持心态平稳。
9.竞赛所在细分领域的奇技Trick。这些Trick往往非常有效,且历经时间的考验。
2.5 算法竞赛的成果沉淀
完成竞赛不是最终的目的,将竞赛成果与思考向业务侧和研究侧进行迁移,才会更加有价值。
同时竞赛方法论也具备迁移价值。业务侧也好,研究侧也好,我发现其逻辑也可以从竞赛侧中获得启发。
3 精致的结尾
最后,希望本文能给大家带来关于算法竞赛细节战术与整体方法论上的思考,也希望能和大家多多交流~
最后的最后,我运营了一个技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于CV算法,算法,开发,IT技术等。欢迎大家入群一起学习交流~(可以知乎私信我加群/加我微信USTB-Rocky,我拉你进群~)
