前言?在本文中,作者引入了一个简单的框架,即Slimmable Domain Adaptation,以通过权重共享模型库改进跨域泛化,从中可以对不同容量的模型进行采样,以适应不同的精度效率权衡。此外,作者还开发了一种随机集成蒸馏方法,以充分利用模型库中的互补知识进行模型间交互。
在各种资源限制下,作者的框架在多个基准上大大超过了其他竞争方法,并可以保持对仅源代码模型的性能改进,即使计算复杂性降低到1/64。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:Slimmable Domain Adaptation
论文:http://arxiv.org/pdf/2206.06620
代码:https://github.com/hikvision-research/SlimDA
背景
深度神经网络通常对离线采集的图像(标记的源数据)进行训练,然后嵌入到边缘设备中,以测试从新场景中采集的图像(未标记的目标数据)。在实践中,这种模式由于域转移而降低了网络性能。近年来,越来越多的研究者对无监督领域适应(UDA)进行了深入研究,以解决这一问题。
Vanilla UDA旨在将源数据和目标数据对齐到联合表示空间中,以便根据源数据训练的模型可以很好地推广到目标数据。但是,学术研究与工业需求之间仍然存在差距:大多数现有的UDA方法仅使用固定的神经结构进行权重自适应,但无法有效地满足现实世界应用中各种设备的要求。
以图1所示的广泛使用的应用场景为例,在这种情况下,普通UDA方法必须反复训练一系列具有不同容量和体系结构的模型,以满足具有不同计算预算的设备的需求,这既昂贵又耗时。
为了解决上述问题,作者提出了Slimmable Domain Adaption(SlimDA),即只对模型进行一次训练,这样就可以灵活地从中抽取具有不同容量和体系结构的定制模型,以满足不同计算预算的设备的需求。
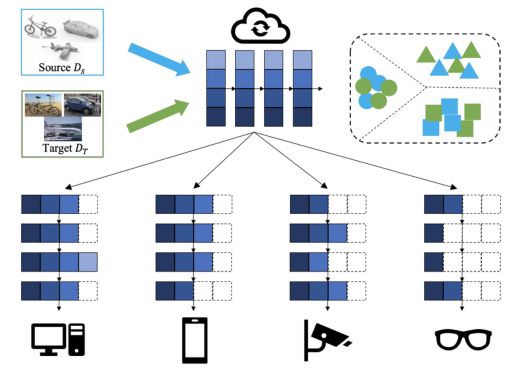
图1 SlimDA
当纤细的神经网络满足无监督领域自适应时,仍然存在两个挑战:
1)权重自适应:如何同时提高模型库中所有模型的自适应性能。
2) 架构适应:给定特定的计算预算,如何在未标记的目标数据上搜索适当的模型。
对于第一个挑战,作者提出了随机集成蒸馏(SEED)来交互模型库中的模型,以抑制模型内自适应对未标记目标数据的不确定性。表1显示了SEED和传统知识蒸馏之间的差异。
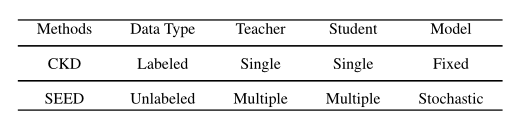
表1 传统知识蒸馏(CKD)与随机集成蒸馏(SEED)
对于第二个挑战,作者提出了一种无监督的绩效评估指标,可以缓解候选模型和锚模型之间的输出差异。度量值越小,假设性能越好。
贡献
1.提出了SlimDA,一个“一劳永逸”的框架,以共同适应资源有限设备的适应性能和计算预算。
2.提出了SEED,能够同时提高模型库中所有模型的适应性能。
3.设计了一个优化分离的三分类器来调节模型内适应和模型间交互之间的优化。
4.提出了一种无监督的性能评估指标,以促进架构适应。
相关方法
1.无监督域自适应(UDA)
现有的UDA方法旨在提高模型在未标记目标域上的性能。在过去几年中,提出了基于差异的方法和对抗性优化方法,通过域对齐来解决这个问题。SymNet开发了一种双分类器体系结构,以促进类别级领域混淆。最近,Li等人试图学习最佳架构,以进一步提高目标域的性能,这证明了网络架构对UDA的重要性。这些UDA方法侧重于实现在目标域上具有更好性能的特定模型。
2. 神经架构搜索(NAS)
NAS方法旨在通过强化学习、进化方法、基于梯度的方法等自动搜索最优架构。最近,一次性方法非常流行,因为只需要训练一个超级网络,并且同时优化了各种架构的多个权重共享子网络。这样,就可以从模型库中搜索最优的网络结构。在本文中,作者强调UDA对于NAS来说是一个未被注意到但意义重大的场景,因为它们可以在无监督的情况下合作优化特定于场景的轻量级体系结构。
3.跨域网络压缩
Chen等人提出了一种跨域非结构化剪枝方法。Y u等人采用MMD来最小化域差异,并在基于泰勒的策略中修剪过滤器,Yang等人专注于压缩图神经网络。Feng等人在通道修剪网络和全尺寸网络之间进行对抗性训练。然而,现有方法的性能仍有很大的改进空间。此外,他们的方法不够灵活,无法在不同的资源约束下获得众多的最优模型。
方法
1. SlimDA框架
在可精简的神经网络中已经证明,具有不同宽度(即层通道)的众多网络可以耦合到权重共享模型库中,并同时进行优化。从一个基线开始,在此基线中,SymNet直接与纤细的神经网络合并。
为了简单起见,SymNet的总体目标统一为Ldc。在每次训练迭代中,可以从模型库{(Fj,Csj,Ctj)}mj=1中随机抽样几个模型∈(F,Cs,Ct),命名为模型批次,其中m表示模型批次大小。此处(F、Cs、Ct)可被视为最大模型,其余模型可通过权重共享的方式从中采样。
为了确保模型库能够得到充分的训练,应在每次训练迭代中对最大和最小的模型进行采样,并将其构成模型批的一部分。
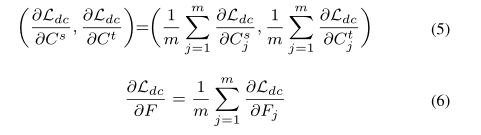
该基线可被视为Eqn的两个交替过程。为了鼓励上述基线中的模型间交互,作者提出了SlimDA框架,如图2所示。该框架由随机集成蒸馏(SEED)和优化分离三分类器(OSTC)设计组成。
SEED旨在利用模型库中的互补知识进行多模型交互。Cs和Ct分类器上的红色箭头表示领域混淆训练Ldc和模型库中的知识聚合。Ca分类器上的紫色箭头表示种子优化Lseed。
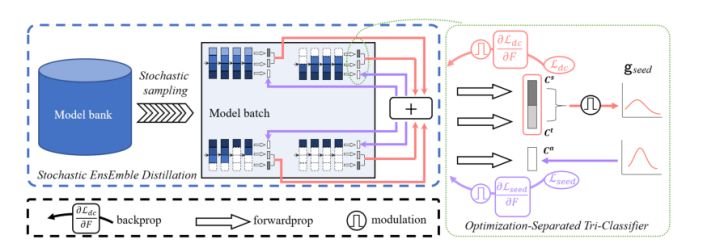
图2 SlimDA框架
2. 随机集成蒸馏(SEED)
SEED旨在利用模型库中的互补知识进行多模型交互。模型库中的不同模型可以直观地学习有关未标记目标数据的补充知识。受带有模型扰动的贝叶斯学习的启发,作者通过蒙特卡罗采样利用模型库中的模型来抑制未标记目标数据的不确定性。
模型置信度定义:
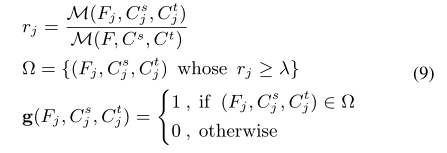
锐化函数以诱导种子训练期间的隐式熵最小化:
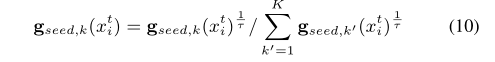
3. 优化分离三分类器(OSTC)
其中前两个用于域混淆训练,最后一个用于接收随机聚合的知识以进行蒸馏。蒸馏损失公式如下:
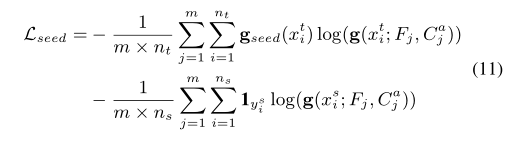
4. 无监督性能评估指标
无监督绩效评估指标(UPEM):
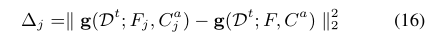
实验
表2 ImageCLEF-DA数据集上的两项消融实验
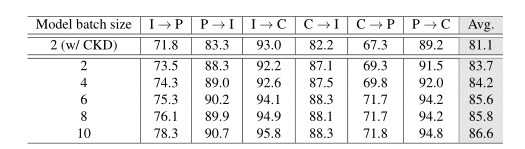
表3 在ImageCLEF-DA数据集上对SlimDA中的成分进行消融实验

表4 ImageCLEF-DA对I→P适应任务的两次消融实验
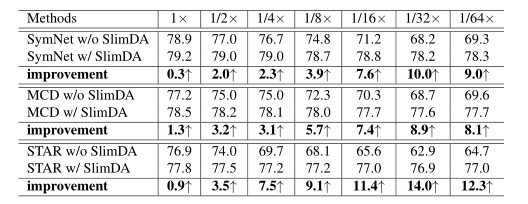
表5 在ImageCLEF-DA数据集上与不同最先进的轻量级网络进行性能比较
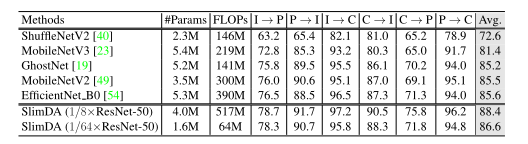
表7 Office-31数据集上的性能

图3 与随机搜索模型在ImageCLEF-DA上的六项适应任务进行比较
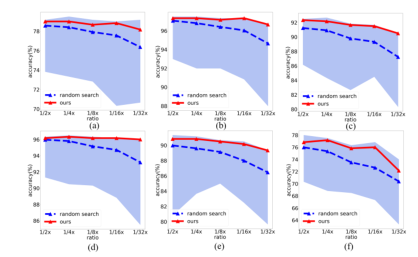
图4 无监督绩效评估指标(UPEM)与使用ground-truth 标签的准确性之间的Pearson相关系数
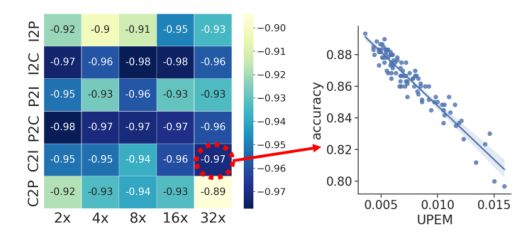
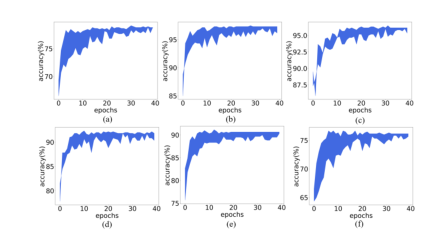
图5 模型库的收敛性能
结论
在本文中,作者提出了一个简单而有效的SlimDA框架,以促进权重和架构的联合适应。在SlimDA中,提出的SEED利用权重共享模型库中的架构多样性来抑制未标记目标数据的预测不确定性,并且提出的OSTC调节模型内自适应和模型间交互之间的优化冲突。
通过这种方式,可以通过无需再训练的采样方式将资源满意模型灵活地分布到目标域上的各种设备上。为了验证SlimDA的有效性,进行了广泛的消融实验。
CV技术指南创建了一个计算机视觉技术交流群和免费版的知识星球,目前星球内人数已经700+,主题数量达到200+。
知识星球内将会每天发布一些作业,用于引导大家去学一些东西,大家可根据作业来持续打卡学习。
CV技术群内每天都会发最近几天出来的顶会论文,大家可以选择感兴趣的论文去阅读,持续follow最新技术,若是看完后写个解读给我们投稿,还可以收到稿费。 另外,技术群内和本人朋友圈内也将发布各个期刊、会议的征稿通知,若有需要的请扫描加好友,并及时关注。
加群加星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

公众号其它文章
CVPR2022 | iFS-RCNN:一种增量小样本实例分割器
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
CVPR2022 | PanopticDepth:深度感知全景分割的统一框架
CVPR2022 | 未知目标检测模块STUD:学习视频中的未知目标
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(四)编写训练过程--参数解析