����:��������-����Э��ѧϰ�Ĵ���ģ��
����:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9747052
����:��
�ؼ���:���岿��Э��ѧϰ(whole-part collaborative learning,WPCL)������Ӧ���������ں�ģ��(adaptive part feature fusion module,APFF)��˫��֧�ṹ(two-branch architecture of collaborative learning,TBCL)
ժҪ:
????????������һ���˵�����촽�˶����Ӿ���Ϣ��ʶ���������ݵ���������,һЩ�о�����ؼ�������γ����ȡʱ����Ϣ,�Լ���ȡ��ռ���Ϣ�ļ������ϡ�������Ҫ�о����������пռ���Ϣ�ij���������⡣�������δ���ȫ�ֿռ���Ϣ,���β��ְ���ϸ���ȿռ���Ϣ������˻�������-����Эͬѧϰ(WPCL)�Ĵ���ģ��,��ģ���ܹ�������ô�����ȫ�ֺ�ϸ���ȿռ���Ϣ��WPCL����������֧,�ֱ������������;ֲ�����,ͨ��Э��ѧϰ��������ѵ������һ��,Ϊ��ͻ�������������ں�ʱ�IJ�ͬ��Ҫ��,���������һ������Ӧ���������ں�ģ��(APFF)���ںϲ������������,����ͨ��ʵ����֤�����ǵĹ۵㲢���������ǵ�WPCL����LRW��CAS-VSR-W1k���ݼ��ϵ�ʵ�����,���ǵķ����ﵽ�����Ƚ������ܡ�
1 ����:
????????������ʶ��ͬ,������Ҫ�����Ӿ���Ϣ���Ӿ���Ϣ��������֡�Ŀռ���Ϣ����Ƶ����ʱ����Ϣ��һЩģ��������ʹ��ʱ̬��Ϣ�����Ӱ���ʹ�ù���[3],��̬��[1],ʱ��ת��ģ��[2]�ȡ�����������Щģ�ͽ��������˿ռ���Ϣ���ռ���Ϣ��Ϊ�Ӿ���Ϣ����Ҫ��ɲ���,�ڴ���������Ӧ���ܵ����ӡ�
????????��ʹ�ÿռ���Ϣʱ,�����ģ��[4�C6]��������ȡ�����촽���������ڽ�ģ���������촽��ģ����ģ��ѧϰ�����촽��ȫ�ֿռ���Ϣ��Ȼ��,���������촽�Ĵ����Ұ,����ܵ���ģ�ͺ���һЩϸ���ȵĿռ���Ϣ����ͼ1��ʾ,��˵���˶���ABOUT��ʱ,�촽�м�ı仯����Ǹ����ԡ���GREAT������ʵķ�������������Եı仯,�촽�м���ƽ���ı仯�������Ƕ�������н�ģʱ,���ڸ���Ұ�ϴ�,�����������־�ϸ�ռ���Ϣ���ܻᱻ���ԡ����,�����뵽��ͨ���ֿ��촽����С����Ұ������������⡣����,ͨ���鿴ͼ1,���Ƿ��ֽ�ģ�ͷֿ�ᶪʧ�����촽�ĸ�֪,���һ��ᶪʧ�촽�����ֵĿռ�λ����Ϣ��PBL�ķ���[7]ʹ����һ���������촽�����ֱ仯�IJ��ֲ��ģ�͡�����PBLʧȥ��ȫ�ֿռ���Ϣ��֪ʶ,ʹ��ģ��ֻ�ܲ��촽ÿ�����ֵ�ϸ���ȿռ���Ϣ����������촽������������ȫ�ֿռ���Ϣ,�Լ�Ƕ�����촽���ֵ�ϸ���ȿռ���Ϣ,�����ڴ�����
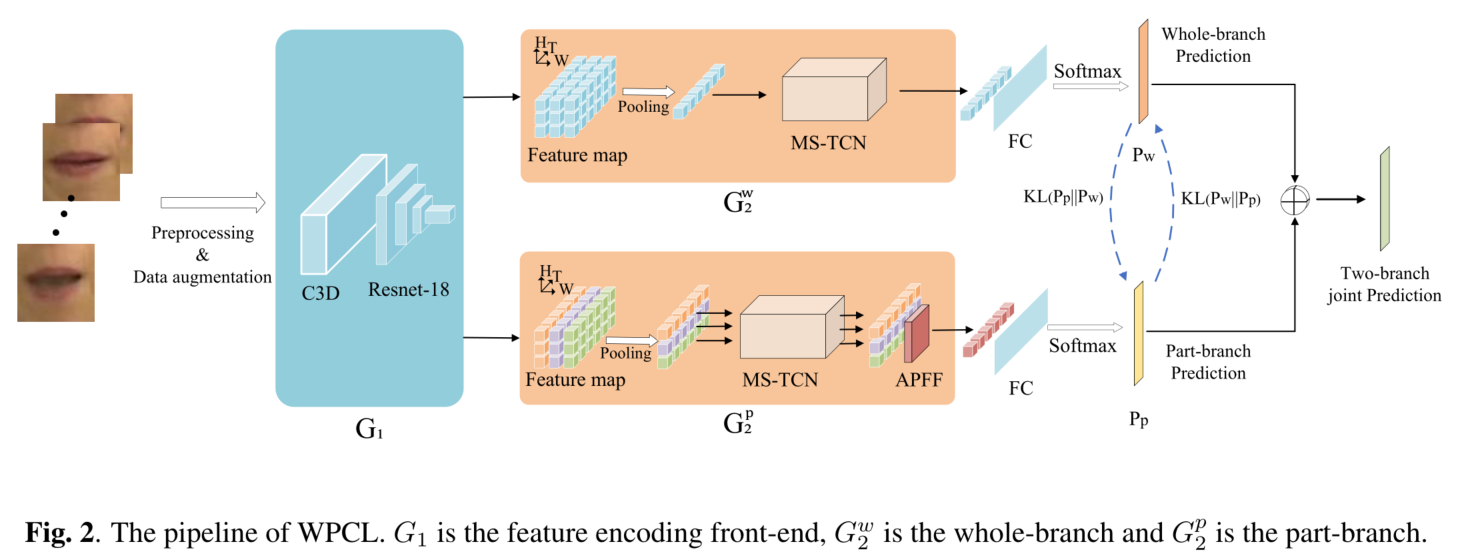
????????Ϊ�˰���ģ�ͳ������lip��ȫ�ֺ�ϸ���ȵĿռ���Ϣ,���������һ����ΪWPCL��˫��֧�ṹ����������֧��ǰ�˱���������������Ͳ��ֽ�ģ,��ʹ���촽��ȫ�ֺ�ϸ���ȿռ���Ϣ��������֧ͨ��Э��ѧϰ�Ӱ��[9�C11]�����,ÿ����֧ʹ����һ����֧��Ԥ����Ϊ����ļ���ź�����ǿ��������ѧϰ������
????????�������ںϲ��������Բ�������Ԥ�⡣Ϊ���������ںϹ����в���ÿ�����ֵ���Ҫ��,���������APFF,������ÿ��������������������֮�����������Ϊÿ���������������ں�Ȩ�ء�
��֮,���ǵĹ�������:
(1)WPCLӵ��һ��˫��֧Э��ѧϰ�ܹ�,�üܹ������������lip��ȫ�ֺ�ϸ���ȿռ���Ϣ��
(2)Ϊ����Ч�ںϲ�������,���������APFFģ����
(3)����֤��WPCL��LRW��CAS-VSR-W1k���ݼ���ʵ�������Ƚ���������

ͼ1��ʾ������������,�ڷ�ABOUT��GREA T����������ʱ,��Ǻ��촽�м䲿�ֵı仯��
?
2 ���鹤��:
2.1 ��������-����Э��ѧϰ�Ĵ���ģ��:
????????�촽�Ǵ�������Ҫ���������촽����ȫ�ֺͿռ�λ����Ϣ,���촽�ĸ���������ͻ��ϸ�ڡ�������Ͳ��ֽ������,�����ṩ�㹻�Ŀ�ǻ��Ϣ,ʵ�ָ������Ĵ�������ͼ2��ʾ,����ʹ��WPCL�����������Ͳ��������ֱ�ģ��
????????����ģ��һ����һ����������ǰ�˺�һ��������������ɡ��ڱ�����,����ʹ��һ��˫��֧����������,��������������ǰ�˲��䡣��Ƶ���о���Ԥ�����������ɵ���C3D��Resnet-18��ɵ���������ǰ��[8]�����ǰ�˵������Dz����ڵ�ʱ�䶯̬����ȡ��֡ͼ��Ŀռ�������˫��֧�����������������ṹ��ͬ��MS-TCN��ɡ������䲻ͬ�Ĺ���,��������֧�ֱ�����Ϊ�����֧�Ͳ��ַ�֧��
2.1.1 �����֧:
????????������֧����ǰ����ȡ������ֱ����Ϊ����,���ڶ������촽���н�ģ��������֧��Ԥ�������Ա�ʾΪ:
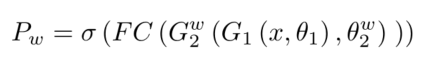

2.1.2 ���ַ�֧:
????????���ڲ��ַ�֧,���Ǹ����촽��ʵ�ʿռ�ֲ�,������������Ϊ��������,��������Ǻ��촽�м�,Ȼ�������������硣��Ҫע�����,ͬһ�촽�Ķ�����������������ַ�֧,������˲��ַ�֧�ķ����������������ǵ�WPCL��[7]��һ����Ҫ���𡣲��ַ�֧��Ԥ�������¡�
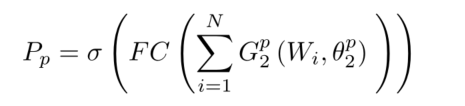

��һС�ڽ���ϸ��������Ӧ���������ں�ģ�顣
2.1.3 Э��ѧϰ��˫��֧�ṹ:
????????Э��ѧϰ����Ϊÿ����֧�ṩ����ļල�źš�Э��ѧϰ��˫��֧�ṹ(TBCL)����������֧��һ��������Ϊ����������ͷ��Э��ѵ�����봫ͳ������֪ʶ�������[13,14],TBCL��ѵ��ʱ�����кܴ����ơ���Ϊ����Э��ѧϰ��˵,����Ҫ��һ��Ԥ��ѵ���õ�ģ����Ϊ��ʦ��
????????WPCLʹ������Э��ѧϰ������֧�ܹ�������һ��,WPCL��ÿ����֧������ѧϰ����Ͳ��ִ�����,WPCL������ʧ��������:
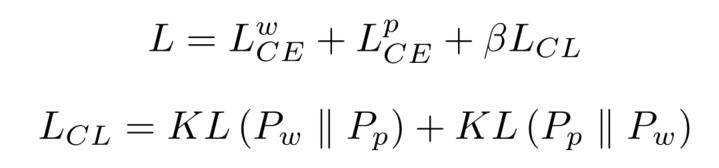

2.2 ����Ӧ�����ں�ģ��:
????????�����ڲ��ַ�֧�в���һ�������ں�ģ��,���������������������������Ԥ�⡣�ڰ��ռ�λ�û�������������,��������Ϣ����Ҫ�̶��Dz�ͬ�ġ�����������Ȼ����ϸ���ȵĿռ���Ϣ,������Ϣ��������С�����,���Ǹ��ݲ�����������������֮�����������������������Ȩ�ء���ͬ�IJ��ֱ�����Ӧ�ط����˸��Ե��ں�Ȩ�ء��ںϺ������������FC������롣ֵ��ע�����,��ģ�鲻�����κβ���,�����ɱ����Ժ��Բ��ơ�������֧��������ʾΪ:

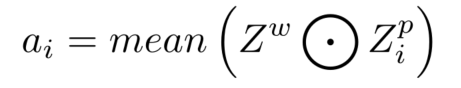
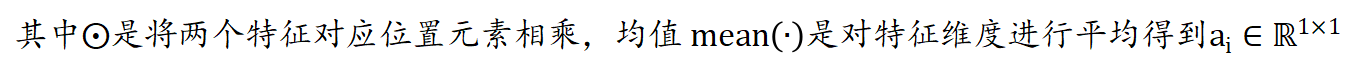
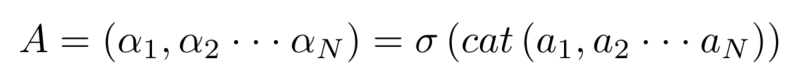
ͼ2. WPCL����ˮ�ߡ�G1�����������ǰ��,Gw2�������֧,Gp 2�Dz��ַ�֧��
?
3 ʵ��:
3.1 ���ݼ�:
????????������Ӣ�����ͨ���Ĵʼ��������ݼ������������ǵ�ģ�͡�
????????LRW[15]:����һ���dz�������ս�Ե����ݼ��������ݼ�����500��Ӣ�ﵥ��,ÿ��������800-1000��ѵ������,50����֤������50������������
ÿ��������29֡���,Ŀ��ʳ�����������ͷ���м䡣
????????CAS-VSR-W1k[16]:�����ݼ�ԭ��ΪLRW-1000,��Ŀǰ������������ͨ���ʻ㼶�������ݼ�����1000������ͳ���700,000����������LRW��ͬ����,�����������Ȳ��Ǻ㶨��,������û��������ͳһ�ֱ��ʡ�
?
3.2 ����Ԥ����:
????????����LRW��CAS-VSR-W1k���ݼ�,���ǽ�ÿ�������ü�Ϊ96��96�̶����ش�С��ROI�����е�ͼ��Ϊ�Ҷ�,�Լ��ټ���������ѵ��������,ÿһ֡����������ü���88��88���صĴ�С,��ʹ�ø���Ϊ0.5��ˮƽ��ת��Ȩ��Ϊ0.4��Mixup[17]������������ǿ������CAS-VSR-W1k���ݼ�,����ʹ����[6]����ͬ������Ԥ�������������ǽ�ÿ����������Ƶ֡���̶�Ϊ29,Ŀ�����ÿ��������ͷ���м䡣
?
3.3 ѵ��ϸ��:
????????����ʹ��AdamW�Ż���[18],��ʼѧϰ��Ϊ3e-4,����˥��Ϊ1e-2�������˻��㷨����������ѧϰ�ʡ�ģ�ʹ�ͷ��βѵ����80��epochs,ʹ��32��mini-batch������ʹ��[5]�е�ģ�ͳ�ʼ������,�Լӿ�ģ�͵������ٶȡ�����,���ǻ�ʹ����[5]�еı䳤��ǿ����,����ǿģ�Ͷ�ʱ�����е�³���ԡ�
3.4 Э��ѧϰ��˫��֧�ṹ����:
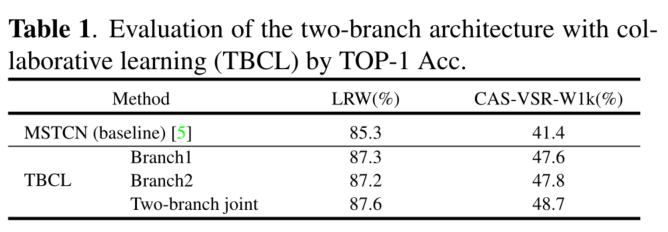
????????�����ʵ����,����������Э��ѧϰ��˫��֧�ṹ����Ч�ԡ�������MSTCN[5],��ʹ�������촽��Ϊ���롣TBCL��������֧( branch1, branch2 )����������MSTCN��ͬ�Ľṹ,����Ҳʹ�������촽��Ϊ���롣�ӱ�1���Կ���,ÿ����֧��Ԥ�⾫�ȶ��Ȼ����нϴ�����,����֧����Ԥ�����������ݼ��ϱȻ��߷ֱ������2.3%(LRW)��7.3%(CAS-VSR-W1k)��
ʵ����������,ӵ����ͬ�ṹ��������֧�в�ͬ�ı��֡���Ӧ���������Dz�ͬ�ij�ʼ������ɵġ�
3.5 ��������-����Э��ѧϰ�Ĵ���ģ������:
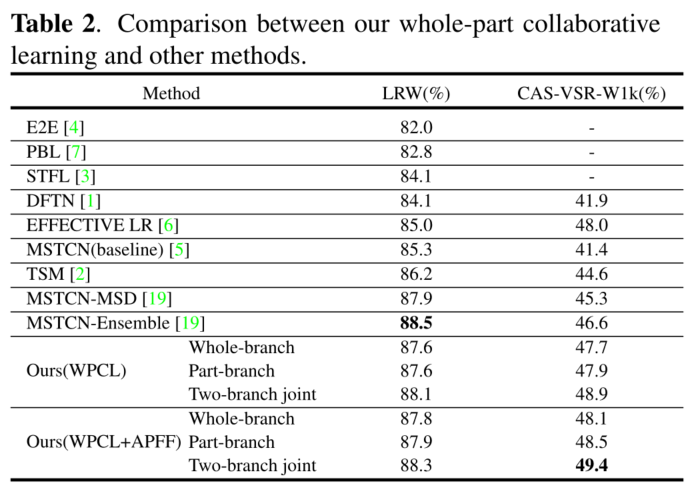
????????����һ����,����������WPCL����Ч�ԡ�����,TBCL��һ����֧ѧϰ��������,��һ����֧ѧϰ�������������ַ�֧ʹ�ü���ͷ����������ںϡ��ӱ�2�����ǿ��Է���,��������֧��LRW���ݼ��ϴﵽ��87.6%,87.6%,���ǵ�����Ԥ��ﵽ��88.1%����������֧��CAS-VSR-W1k���ݼ��ϵ�ȷ�ʷֱ�ﵽ47.7%��47.9%,������Ԥ��ﵽ48.9%�����ʵ�����,��������֧�ֱ������Ͳ��ֽ��н�ģʱ,ģ�Ϳ��Գ������ȫ�ֿռ���Ϣ��ϸ���ȵĿռ���Ϣ��
????????��ʹ��APFF���ں�����ʱ,���ܵõ���һ����ߡ����ַ�֧�ľ��������0.3%(LRW)��0.6%(CAS-VSR-W1k),���ǵ�����Ԥ������LRW��CAS-VSRW1k�зֱ�ﵽ88.3%��49.4%��ԭ������,���������ļ�������������˸����ֵIJ�ͬ��Ҫ��,��APFF�Ǹ��ݲ����������������������ƶ�������Ȩ�صġ������������Բ�����ϸ�Ŀռ���Ϣ,���APFF��������ʵ�ָ�Ч�Ĵ������ӱ�2�����ǿ��Է���,��������촽��ȫ�ֺ�ϸ���ȵĿռ���Ϣ�����ڴ����Ķ�,���ǵķ���ȡ�������Ƚ������ܡ�
3.6 ��ģ����SOTAģ�͵ļ��㸴�Ӷ�����:
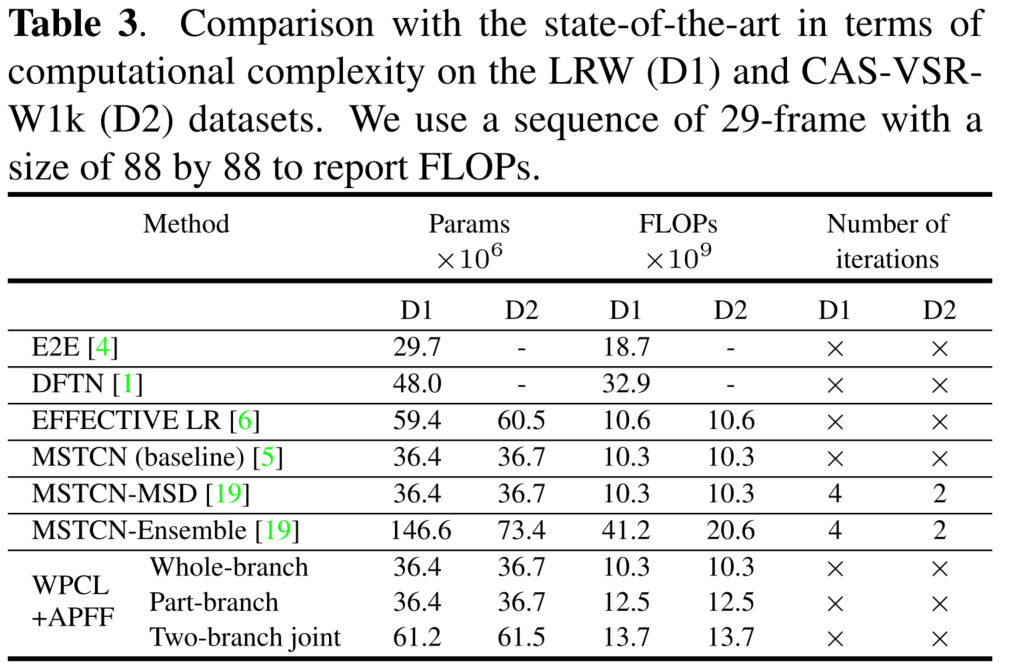
????????MSTCN�������(MSTCN-MSD[19])ʹ����[14, 20]��ͬ�IJ��ԡ�����ȱ����,ʵ��һ���õ�ѧ����Ҫ���֪ʶ������̡�MSTCN-MSD���������ݼ��Ϸֱ�����4�κ�2�ε���,���ѵ��ʱ����һ�־���˷ѡ����֮��,���ǵ�˫��֧ģ��ֻ��һ���ν���Эͬѵ��,��������֧�ܹ�ʵ�ֲ��м���[11]�����2�ͱ�3��ʾ,����ģ�͵�ÿ����֧��MSTCN-MSD�IJ�����FLOPs����������ͬ����LRW���ݼ���,ÿ����֧���ﵽ����MSTCN-MSD��ͬ�ľ��ȡ�������ܵ���,��CAS-VSR-W1k���ݼ���,ÿ����֧����MSTCN-MSD�����Ե����,�ֱ�Ϊ2.8%��3.2%����MSTCN-Ensemble���,���ǵ�˫��֧����Ԥ����LRW�ϵ�ȷ���½���0.2%,����Ҫ�IJ���������2.4��,FLOPs������3��������CAS-VSR-W1k,���ǵ�˫��֧����Ԥ�⾫�ȱ�MSTCN-Ensemble�����2.8%,��������FLOPs������ȴ�����ˡ��������������,���ǵ�ģ�͵�ÿ����֧�ڲ�����FLOPs�Ըߵ�����¶�ʵ����ȷ�ʵĴ����ߡ�
4 ����:
????????�ڱ�����,���������һ�����͵�WPCLģ��,������Э��ѧϰ����������촽��ȫ�ֺ�ϸ���ȿռ���Ϣ����WPCL��,���Dz�����һ��APFF���ںϲ�������,����Խ�һ���������ģ�͵�ȷ�ԡ����ǵ�ģ����ѵ��ʱ�䡢ģ�Ͳ�����FLOPs����Ҳ���������е����Ƚ�ˮƽ�����ǵ�ģ��ʵ�������Ƚ������ܡ�