����Ŀ¼
1. ��Ŀ��
1.1. �����
ͼ������Ǽ�����Ӿ�����Ҫ����,����Ŀ���ǽ�ͼ����ൽԤ����ı�ǩ�������о�������˺ܶͬ�����������,������������˷����㷨�����ܡ�����ʵ����ѵ��ResNetģ��ʵ�ֶ��ز�CTӰ��ķ���,�������¹ڷ����ߡ������Է������Լ������ˡ�
1.2. ���ݼ����
�¹ڷ�����ȫ���Ժ�,���Կ��������ϼ��������ͻ�˹̹�Լ��������ǵ��о���Ա��ҽ������,������һ�����������ˡ������Է����ߡ��¹ڷ����ߵ��ز�CTӰ������ݼ������ݼ�����1200���¹����Ի��ߵ�Ӱ��1341�������˵�Ӱ���1345�������Է����ߵ�Ӱ��
�������ݼ�����������:COVID-19�ز�X����ͼ�����ݿ� - AI Studio
2. ResNetģ��
2.1. ģ�ͱ���
VGG��GoogleNet��ģ��֤��,�����������Գ��������������ǿ������,������ø�ǿ�ķ�����������������˵,��û�вв�����������,������������ļ���,����ı�������Խ��Խǿ,������ʵ�ʲ���������,��ô���ᵼ��ģ��Ч��Խ��Խ�һ����,����������н��з���ʱ,�����ķ�������ʹ�ý�����˵��ݶȽӽ�0,�Ӷ������ݶ���ʧ,ʹ�������ѵ��ʧЧ;��һ����,�����������˻�����(Degradation of Deep Network),��ʹ�����������ѧϰ�������ŵ���ʵ�ʵ����ŵ�������Խ��ԽԶ�ġ�
Ϊ�˽����������,���������」����(2015)�������������ResNet,����һ����Ȳв�������硣��ͼչʾ��VGG-19��ResNet-34������ṹ,���ǿ��Կ���,��VGGģ�͵ĸ�������ֱ�Ӽ��Ӳ�ͬ����,ResNetģ�ͻὫ�в�������Ҳ��Ϊ��һ���в�������,��������ʹ����������ܹ��ں�dz����������ȡ������,������Ⱦ���������������ܡ�

2.2. ģ�ͽ���
ResNet��һϵ�вв��(����ͼFigure 2��ʾ)����,�����ÿ���в�������
x
x
x����������
F
(
x
)
F(x)
F(x)�������,��ʹ��ReLU����������ӽ��֮��,���DZ�õ��˸òв����������Ҫע�����,���
x
x
x��
F
(
x
)
F(x)
F(x)��ͨ������һ��,��ô�ڽ������֮ǰ,���ǻ����
x
x
x������Ӧ�ľ�������,��ʵ���²���(downsample),ͳһ
x
x
x��
F
(
x
)
F(x)
F(x)��ͨ������

����ͼFigure 5��ʾ,ResNetģ��һ�������ֲ�ͬ�IJв�顣����,50�����µ�ResNet���õ�������Basic�в��,��50�㼰���ϵ�ResNet���õ����Ҳ��Bottleneck�в�顣
�±�չʾ��ResNetģ�͵�����ṹ,����,
[
3
��
3
,
a
3
��
3
,
a
]
\left[\begin{array}{c} 3��3, a \\ 3��3, a \end{array}\right]
[3��3,a3��3,a?]����Basic��,
[
1
��
1
,
b
3
��
3
,
b
1
��
1
,
4
b
]
\left[\begin{array}{c} 1��1, b \\ 3��3, b \\ 1��1, 4b \end{array}\right]
???1��1,b3��3,b1��1,4b????����Bottleneck�в�顣ResNetһ��������汾,��ResNet-18��ResNet-34��ResNet-50��ResNet-101��ResNet-152,������õİ汾��ResNet-50��ResNet-101��

3. ʵ�鲽��

3.0. ǰ����
- ����ģ��
ע��:��������������
PaddlePaddle 2.0+�汾
import os
import zipfile
import random
import numpy as np
from PIL import Image, ImageEnhance
import matplotlib.pyplot as plt
import paddle
from paddle import nn
from paddle import metric as M
from paddle.io import DataLoader, Dataset
from paddle.nn import functional as F
from paddle.optimizer import Adam
from paddle.optimizer.lr import NaturalExpDecay
- ������
BATCH_SIZE = 64 # ÿ���ε�������
EPOCHS = 8 # ѵ������
LOG_GAP = 30 # ���ѵ����Ϣ�ļ��
CLASS_DIM = 3 # ͼ������
LAB_DICT = { # ��¼��ǩ�����ֵĹ�ϵ
"0": "�����β�",
"1": "�����Է���",
"2": "�¹ڷ���",
}
INIT_LR = 3e-4 # ��ʼѧϰ��
LR_DECAY = 0.6 # ѧϰ��˥����
SRC_PATH = "./data/input_data.zip" # ѹ����·��
DST_PATH = "./data" # ��ѹ·��
DATA_PATH = { # ʵ�����ݼ�·��
"0": DST_PATH + "/input_data/NORMAL",
"1": DST_PATH + "/input_data/Viral_Pneumonia",
"2": DST_PATH + "/input_data/COVID",
}
MODEL_PATH = "ResNet.pdparams" # ģ�Ͳ�������·��
3.1. ������
- ��ѹ���ݼ�
�������ݼ��е���������ѹ��������ʽ��ŵ�,���������Ҫ�Ƚ�ѹ����ѹ������
if not os.path.isdir(DATA_PATH["0"]) or\
not os.path.isdir(DATA_PATH["1"]) or\
not os.path.isdir(DATA_PATH["2"]):
z = zipfile.ZipFile(SRC_PATH, "r") # ��ѹ���ļ�,����zip����
z.extractall(path=DST_PATH) # ��ѹzip�ļ���Ŀ��·��
z.close()
print("���ݼ���ѹ���!")
- �������ݼ�
������Ҫ��1:9�������ֲ��Լ���ѵ����,�ֱ�����������������·���ͱ�ǩӳ���ϵ���б���
def get_data_list(lab_no, path): # ����path·���µ����ݼ�
tmp_train_list, tmp_test_list = [], [] # ��ʱ������ݼ�λ�ü���ǩ
for idx, img in enumerate(os.listdir(path)[:-1]):
img_path = os.path.join(path, img)
if idx % 10 == 0: # ����1:9�ı����������ݼ�
tmp_test_list.append([img_path, lab_no])
else:
tmp_train_list.append([img_path, lab_no])
return tmp_train_list, tmp_test_list
def get_infer_data(data_path): # �����ݼ������һ��������ΪԤ�⼯
tmp_infer_list = []
for lab_no in data_path.keys():
path, lab_no = data_path[lab_no], int(lab_no)
img_path = os.path.join(path, os.listdir(path)[-1])
tmp_infer_list.append([img_path, lab_no])
return tmp_infer_list
train_lt0, test_lt0 = get_data_list(0, DATA_PATH["0"]) # ���֡������β���
train_lt1, test_lt1 = get_data_list(1, DATA_PATH["1"]) # ���֡������Է��ס�
train_lt2, test_lt2 = get_data_list(2, DATA_PATH["2"]) # ���֡��¹ڷ��ס�
train_list = train_lt0 + train_lt1 + train_lt2
test_list = test_lt0 + test_lt1 + test_lt2
infer_list = get_infer_data(DATA_PATH)
- ������ǿ
���݉���(Data Augmentation),��������ǿ,������ǿ��Ŀ����Ҫ�Ǽ�������Ĺ��������,ͨ����ѵ��ͼƬ���б任���Եõ�����������ǿ������,���õ���ӦӦ�ó�����
����ʵ��ģ�ͽ�Ϊ����,ֱ��ѵ�������������,���ڴ���ʵ�����ݼ�ʱ����������ǿ�ķ����������ݼ��Ķ����ԡ���ʵ�����õ���������ǿ������:����ı�����,����ı�Աȶ�,����ı䱥�Ͷ�,����ı�������,�����תͼ��,�����תͼ��,����Ӹ�˹�����ȡ�
def random_brightness(img, low=0.5, high=1.5):
''' ����ı�����(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Brightness(img).enhance(x)
return img
def random_contrast(img, low=0.5, high=1.5):
''' ����ı�Աȶ�(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Contrast(img).enhance(x)
return img
def random_color(img, low=0.5, high=1.5):
''' ����ı䱥�Ͷ�(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Color(img).enhance(x)
return img
def random_sharpness(img, low=0.5, high=1.5):
''' ����ı�������(0.5~1.5) '''
x = random.uniform(low, high)
img = ImageEnhance.Sharpness(img).enhance(x)
return img
def random_flip(img, prob=0.5):
''' �����תͼ��(p=0.5) '''
if random.random() < prob: # ���ҷ�ת
img = img.transpose(Image.FLIP_LEFT_RIGHT)
# if random.random() < prob: # ���·�ת
# img = img.transpose(Image.FLIP_TOP_BOTTOM)
return img
def random_rotate(img, low=-30, high=30):
''' �����תͼ��(-30~30) '''
angle = random.choice(range(low, high))
img = img.rotate(angle)
return img
def random_noise(img, low=0, high=10):
''' ����Ӹ�˹����(0~10) '''
img = np.asarray(img)
sigma = np.random.uniform(low, high)
noise = np.random.randn(img.shape[0], img.shape[1], 3) * sigma
img = img + np.round(noise).astype('uint8')
# �������е�����Ԫ��ֵ������0~255֮��:
img[img > 255], img[img < 0] = 255, 0
img = Image.fromarray(img)
return img
def image_augment(img, prob=0.5):
''' ���Ӷ���������ǿ���� '''
opts = [random_brightness, random_contrast, random_color, random_flip,
random_rotate, random_noise, random_sharpness,] # ������ǿ����
random.shuffle(opts)
for opt in opts:
img = opt(img) if random.random() < prob else img # ����ͼ��
return img
- ����Ԥ����
������Ҫ�����ݼ�ͼ��������ź�һ��������
class MyDataset(Dataset):
''' �Զ�������ݼ��� '''
def __init__(self, label_list, transform, augment=None):
'''
* `label_list`: ��ǩ���ļ�·����ӳ���б�
* `transform`: ���ݴ�������
* `augment`: ������ǿ����(Ĭ��Ϊ��)
'''
super(MyDataset, self).__init__()
random.shuffle(label_list) # ����ӳ���б�
self.label_list = label_list
self.transform = transform
self.augment = augment
def __getitem__(self, index):
''' ����λ���ȡ��Ӧ���� '''
img_path, label = self.label_list[index]
img = self.transform(img_path, self.augment)
return img, int(label)
def __len__(self):
''' ��ȡ���ݼ��������� '''
return len(self.label_list)
def data_mapper(img_path, augment=None, show=False):
''' ͼ�������� '''
img = Image.open(img_path).convert("RGB") # ��RGBģʽ��ͼƬ
# ��������Ϊ224*224�ĸ�����ͼ��:
img = img.resize((224, 224), Image.ANTIALIAS)
if show: # չʾͼ��
display(img)
if augment is not None: # ������ǿ
img = augment(img)
# ��ͼ����һ��numpy������ƥ����������ʽ:
img = np.array(img).astype("float32")
# ��ͼ������ɡ�rgb,rgb,rbg...��ת��Ϊ��rr...,gg...,bb...��:
img = img.transpose((2, 0, 1))
# ��ͼ�����ݹ�һ��,��ת����Tensor��ʽ:
img = paddle.to_tensor(img / 255.0)
return img
train_dataset = MyDataset(train_list, data_mapper, image_augment) # ѵ����
test_dataset = MyDataset(test_list, data_mapper, augment=None) # ���Լ�
- ���������ṩ��
������Ҫ�ֱ�����ѵ���Ͳ��Ե������ṩ��,����ѵ�������ṩ�������������ṩ���ݵġ�
train_loader = DataLoader(train_dataset, # ѵ�����ݼ�
batch_size=BATCH_SIZE, # ÿ����ȡ��������
num_workers=0, # �������ݵ��ӽ��̸���
shuffle=True, # ����ѵ�����ݼ�
drop_last=False) # ������������������
test_loader = DataLoader(test_dataset, # �������ݼ�
batch_size=BATCH_SIZE, # ÿ����ȡ��������
num_workers=0, # �������ݵ��ӽ��̸���
shuffle=False, # �����Ҳ������ݼ�
drop_last=False) # ������������������
3.2. ��������
- ע������
��ResNet�IJв����,���߲����˴�����С�ߴ�����ˡ�����,���ڰ���1��1�����˵ľ��������,��ֻ�ܸı�����ͼ��ͨ����;���ڰ���3��3�����˵ľ��������,���ҽ������㲽��(stride)��Ϊ1ʱ,���ſ��Ըı�����ͼ�ijߴ硣
class ConvBN2d(nn.Layer):
''' Conv2d with BatchNorm2d and ReLU '''
def __init__(self, in_channels: int, out_channels: int,
kernel_size: int, stride=1, padding=0, act=None):
'''
* `in_channels`: ����ͨ����
* `out_channels`: ���ͨ����
* `kernel_size`: �����˴�С
* `stride`: ��������IJ���
* `padding`: �������Ĵ�С
* `act`: �����(None / relu)
'''
super(ConvBN2d, self).__init__()
self.act = act
self.net = nn.Sequential(
nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2D(out_channels)
)
def forward(self, x):
if self.act == "relu":
return F.relu(self.net(x))
else:
return self.net(x)
class BasicBlock(nn.Layer):
''' A Residual Block for ResNet-18/34 '''
expansion = 1 # ���һ�������ͨ����չ����
def __init__(self, in_size, out_size, stride=1):
'''
* `in_size`: ��һ������������ͨ����
* `out_size`: ��һ�����������ͨ����
* `stride`: ��һ�����������㲽��
'''
super(BasicBlock, self).__init__()
end_size = self.expansion * out_size # ���һ�����������ͨ����
self.layers = nn.Sequential(
ConvBN2d(in_size, out_size, 3, stride, 1, "relu"),
ConvBN2d(out_size, end_size, 3, 1, 1, None),
)
if in_size != end_size: # ����ƴ��֮ǰ��Ҫͳһͨ�����ͳߴ�
self.shortcut = ConvBN2d(in_size, end_size, 1, stride, act=None)
else:
self.shortcut = None
def forward(self, x):
fx = self.layers(x)
if self.shortcut is not None:
x = self.shortcut(x)
y = F.relu(fx + x)
return y
class Bottleneck(nn.Layer):
''' A Residual Block for ResNet-50/101/152 '''
expansion = 4 # ���һ�������ͨ����չ����
def __init__(self, in_size, out_size, stride=1):
'''
* `in_size`: ��һ������������ͨ����
* `out_size`: ��һ�����������ͨ����
* `stride`: ��һ�����������㲽��
'''
super(Bottleneck, self).__init__()
end_size = self.expansion * out_size # ���һ�����������ͨ����
self.layers = nn.Sequential(
ConvBN2d(in_size, out_size, 1, act="relu"),
ConvBN2d(out_size, out_size, 3, stride, 1, "relu"),
ConvBN2d(out_size, end_size, 1, act=None),
)
if in_size != end_size: # ����ƴ��֮ǰ��Ҫͳһͨ�����ͳߴ�
self.shortcut = ConvBN2d(in_size, end_size, 1, stride, act=None)
else:
self.shortcut = None
def forward(self, x):
fx = self.layers(x)
if self.shortcut is not None:
x = self.shortcut(x)
y = F.relu(fx + x)
return y
class ResNet(nn.Layer):
def __init__(self, in_channels=3, n_classes=2, mtype=50):
'''
* `in_channels`: �����ͨ����
* `n_classes`: �����������
* `mtype`: ResNet����(18/34/50/101/152)
'''
super(ResNet, self).__init__()
if mtype == 18: # ResNet-18
self.Block, n_blocks = BasicBlock, [2, 2, 2, 2]
elif mtype == 34: # ResNet-34
self.Block, n_blocks = BasicBlock, [3, 4, 6, 3]
elif mtype == 50: # ResNet-50
self.Block, n_blocks = Bottleneck, [3, 4, 6, 3]
elif mtype == 101: # ResNet-101
self.Block, n_blocks = Bottleneck, [3, 4, 23, 3]
elif mtype == 152: # ResNet-152
self.Block, n_blocks = Bottleneck, [3, 8, 36, 3]
else:
raise NotImplementedError("`mtype` must in [18, 34, 50, 101, 152]")
self.e = self.Block.expansion # �в�ṹ���ͨ��������չ����
self.conv1 = ConvBN2d(in_channels, 64, 7, 2, 3, "relu")
self.pool1 = nn.MaxPool2D(3, 2, 1)
self.conv2 = self._res_blocks(n_blocks[0], 64, 64, 1) # ���㲻�ı�ߴ�
self.conv3 = self._res_blocks(n_blocks[1], 64 * self.e, 128, 2)
self.conv4 = self._res_blocks(n_blocks[2], 128 * self.e, 256, 2)
self.conv5 = self._res_blocks(n_blocks[3], 256 * self.e, 512, 2)
self.pool2 = nn.AdaptiveAvgPool2D((1, 1))
self.linear = nn.Sequential(nn.Flatten(1, -1),
nn.Linear(512 * self.e, n_classes))
def forward(self, x):
x = self.conv1(x) # 64*112*112
x = self.pool1(x) # 64*56*56
x = self.conv2(x) # 64*56*56 or 256*56*56
x = self.conv3(x) # 128*28*28 or 512*28*28
x = self.conv4(x) # 256*14*14 or 1024*14*14
x = self.conv5(x) # 512*7*7 or 2048*7*7
x = self.pool2(x) # 512*1*1 or 2048*1*1
y = self.linear(x) # n_classes
return y
def _res_blocks(self, n_block, in_size, out_size, stride):
'''
* `n_block`: �������
* `in_size`: ��һ������������ͨ����
* `out_size`: ��һ�����������ͨ����
* `stride`: ��һ���в���������IJ���
'''
blocks = [self.Block(in_size, out_size, stride),]
in_size = out_size * self.e # �����в�������ͨ����
for _ in range(1, n_block):
blocks.append( self.Block(in_size, out_size, stride=1) )
return nn.Sequential(*blocks)
- ʵ����ģ��
model = ResNet(in_channels=3, n_classes=CLASS_DIM, mtype=50) # ResNet-50
3.3. ģ��ѵ��
model.train() # ����ѵ��ģʽ
scheduler = NaturalExpDecay(
learning_rate=INIT_LR,
gamma=LR_DECAY
) # ����ѧϰ��˥����
optimizer = Adam(
learning_rate=scheduler,
parameters=model.parameters()
) # ����Adam�Ż���
loss_arr, acc_arr = [], [] # ���ڿ��ӻ�
for ep in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # ����һάά��
y_pred = model(x_data) # Ԥ����
acc = M.accuracy(y_pred, y_data) # ����ȷ��
loss = F.cross_entropy(y_pred, y_data) # ���㽻����
if batch_id % LOG_GAP == 0: # �������ѵ�����
print("Epoch:%d,Batch:%2d,Loss:%.5f,Acc:%.5f"\
% (ep, batch_id, loss, acc))
acc_arr.append(acc.item())
loss_arr.append(loss.item())
optimizer.clear_grad()
loss.backward()
optimizer.step()
scheduler.step() # ÿ��˥��һ��ѧϰ��
paddle.save(model.state_dict(), MODEL_PATH) # ����ѵ���õ�ģ��
ģ��ѵ���������:
Epoch:0,Batch: 0,Loss:1.28814,Acc:0.40625
Epoch:0,Batch:30,Loss:0.50501,Acc:0.81250
Epoch:1,Batch: 0,Loss:0.47952,Acc:0.79688
Epoch:1,Batch:30,Loss:0.28905,Acc:0.87500
Epoch:2,Batch: 0,Loss:0.53422,Acc:0.78125
Epoch:2,Batch:30,Loss:0.23787,Acc:0.89062
Epoch:3,Batch: 0,Loss:0.21741,Acc:0.92188
Epoch:3,Batch:30,Loss:0.21679,Acc:0.93750
Epoch:4,Batch: 0,Loss:0.22656,Acc:0.90625
Epoch:4,Batch:30,Loss:0.29999,Acc:0.89062
Epoch:5,Batch: 0,Loss:0.14857,Acc:0.95312
Epoch:5,Batch:30,Loss:0.07505,Acc:1.00000
Epoch:6,Batch: 0,Loss:0.18624,Acc:0.89062
Epoch:6,Batch:30,Loss:0.10810,Acc:0.96875
Epoch:7,Batch: 0,Loss:0.16827,Acc:0.93750
Epoch:7,Batch:30,Loss:0.11762,Acc:0.95312
- ���ӻ�ѵ������
fig = plt.figure(figsize=[10, 8])
# ѵ�����ͼ��:
ax1 = fig.add_subplot(211, facecolor="#E8E8F8")
ax1.set_ylabel("Loss", fontsize=18)
plt.tick_params(labelsize=14)
ax1.plot(range(len(loss_arr)), loss_arr, color="orangered")
ax1.grid(linewidth=1.5, color="white") # ��ʾ����
# ѵ��ȷ��ͼ��:
ax2 = fig.add_subplot(212, facecolor="#E8E8F8")
ax2.set_xlabel("Training Steps", fontsize=18)
ax2.set_ylabel("Accuracy", fontsize=18)
plt.tick_params(labelsize=14)
ax2.plot(range(len(acc_arr)), acc_arr, color="dodgerblue")
ax2.grid(linewidth=1.5, color="white") # ��ʾ����
fig.tight_layout()
plt.show()
plt.close()

3.4. ģ������
model.eval() # ��������ģʽ
test_costs, test_accs = [], []
for batch_id, data in enumerate(test_loader()):
x_data, y_data = data
y_data = y_data[:, np.newaxis] # ����һάά��
y_pred = model(x_data) # Ԥ����
acc = M.accuracy(y_pred, y_data) # ����ȷ��
loss = F.cross_entropy(y_pred, y_data) # ���㽻����
test_accs.append(acc.item())
test_costs.append(loss.item())
test_loss = np.mean(test_costs) # ÿ�ֲ��Ե�ƽ�����
test_acc = np.mean(test_accs) # ÿ�ֲ��Ե�ƽ��ȷ��
print("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
ģ�������������:
Eval Loss:0.12486,Acc:0.95536
3.5. ģ��Ԥ��
model.eval() # ��������ģʽ
model.set_state_dict(
paddle.load(MODEL_PATH)
) # ����Ԥѵ��ģ�Ͳ���
for idx, (img_path, label) in enumerate(infer_list):
truth_lab = LAB_DICT[str(label)] # ��ȡ��ʵ��ǩ
image = data_mapper(img_path, show=True) # ��ȡԤ��ͼƬ
result = model(image[np.newaxis, :, :, :]) # ��ʼģ��Ԥ��
infer_lab = LAB_DICT[str(np.argmax(result))] # ��ȡԤ����
print("ͼ%d����ʵ��ǩ:%s,Ԥ����:%s" % (idx+1, truth_lab, infer_lab))
ģ��Ԥ��������:
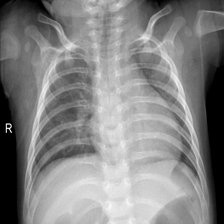
ͼ1����ʵ��ǩ:�����β�,Ԥ����:�����β�
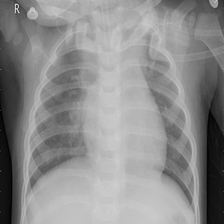
ͼ2����ʵ��ǩ:�����Է���,Ԥ����:�����Է���
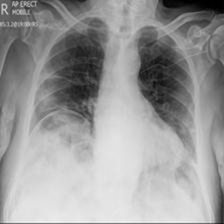
ͼ3����ʵ��ǩ:�¹ڷ���,Ԥ����:�¹ڷ���
4. �����ܽ�

����
- �����������Ŀ��������,����������и��õĽ���,��ӭ���·�����������������~
- ���DZ���Ŀ������:ʵ����Ŀ - AI Studio,���
fork��ֱ����AI Studio����~- �����ҵĸ�����ҳ:������ҳ - AI Studio,��AI Studio���۰�,����Ŷ~
- �������εΡ���ӭ�����ʱ�����ҵ����˲���~