NLP竞赛参与打卡记录:汽车领域多语种迁移学习挑战赛
本博客为Coggle 30 Days of ML(22年7月)竞赛打卡活动记录页面,会记录本人的打卡内容。活动链接为:活动链接
任务1:比赛报名
步骤1:报名比赛
前往竞赛地址,完成账号注册和比赛的报名。
报名成果截图:
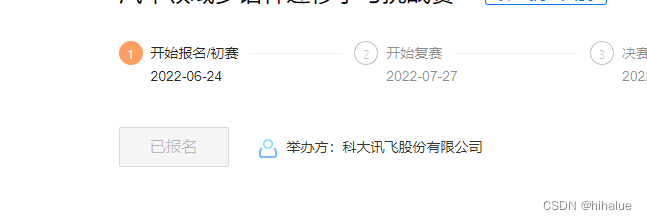
步骤2:下载比赛数据
在竞赛页面点击数据下载:

步骤3:解压比赛数据,并使用pandas进行读取
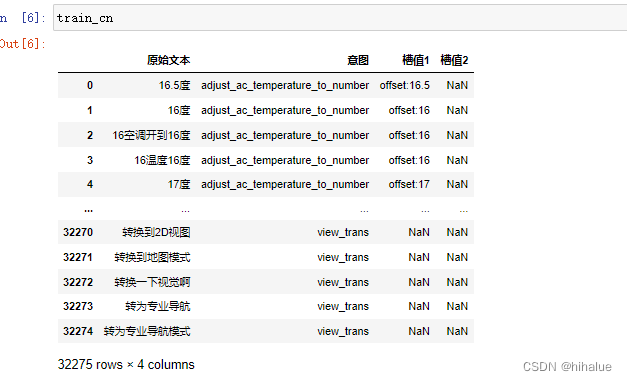
将下载下来的内容进行解压,然后调用pandas进行读取,展示
读取的代码如下:
import pandas as pd
train_cn = pd.read_excel("data/1/中文_train.xlsx")
train_en = pd.read_excel("data/1/英文_train.xlsx")
train_jp = pd.read_excel("data/1/日语_train.xlsx")
test_a = pd.read_excel("data/testA.xlsx")
要展示的话,你可以选择print或者在jupoyter notebook上直接用变量名
步骤4:查看数据类型
可以用pandas的info()来查看训练集和测试集的相关字段信息
print("cn train")
print(train_cn.info())
print("---"*10)
print("en train")
print(train_en.info())
print("---"*10)
print("jp train")
print(train_jp.info())
print("---"*10)
print("testa")
print(test_a.info())

任务2:文本分析与文本分词
步骤1:使用jieba对中文进行分词;
jieba是常用的处理中文字符的第三库,关于它的用法可自行搜索。
先用pip来安装它
pip install jieba
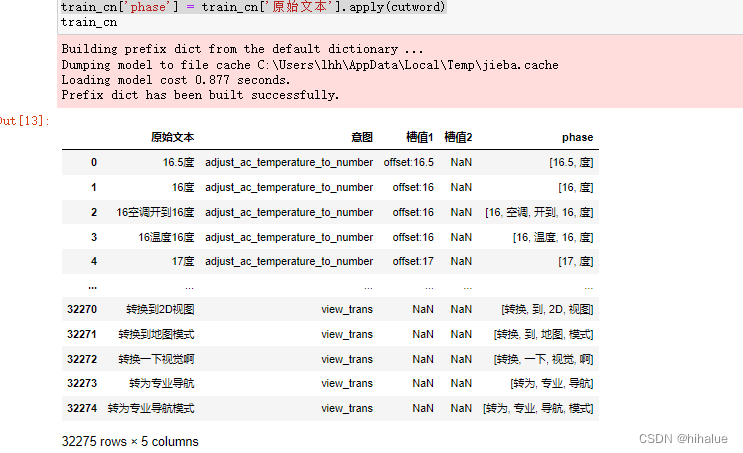
然后,我们可以利用jieba进行简单的中文分词
import jieba
def cutword(txt):
return jieba.lcut(txt)
train_cn['phase'] = train_cn['原始文本'].apply(cutword)
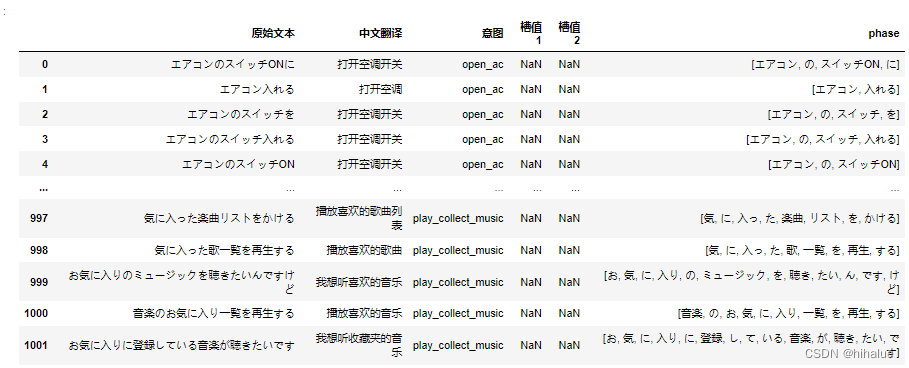
步骤2:使用negisa对日语进行分词
对于日文的数据,我们可以使用negisa这个库来进行分词操作;具体的用法可见官方文档negisa;直接pip安装需要一定时间(视网络条件而定,这个包20m左右大小;一般还会安装其他依赖)
类似的,分词代码如下
import nagisa
def cutword_jp(txt):
words = nagisa.tagging(txt)
return words.words
train_jp['phase'] = train_jp['原始文本'].apply(cutword_jp
任务3:TFIDF与文本分类
任务3总的来说可以参考Coggle 给的例子。
步骤1:学习TFIDF的使用,提取语料的TFIDF特征;步骤2:使用逻辑回归结合TFIDF进行训练(所有的语言语料),并对测试集的意图进行分类
这里,两个步骤是可以合并在一起完成的,因为可以把提取特征和逻辑回归一起构建成一个pipeline,一起进行训练。
第一部分,数据预处理代码如下:
import pandas as pd
import numpy as np
import nagisa
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征提取
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.pipeline import make_pipeline # 组合流水线
# 读取数据
train_cn = pd.read_excel("data/1/中文_train.xlsx") # 因为test仅包含英文和中文,所以本次没有使用cn的数据来加强特征学习
train_en = pd.read_excel("data/1/英文_train.xlsx")
train_jp = pd.read_excel("data/1/日语_train.xlsx")
test_jp = pd.read_excel('data/testA.xlsx', sheet_name='日语_testA')
test_en = pd.read_excel('data/testA.xlsx', sheet_name='英文_testA')
# 文本分词
train_jp['words'] = train_jp['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
train_en['words'] = train_en['原始文本'].apply(lambda x: x.lower())
test_jp['words'] = test_jp['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
test_en['words'] = test_en['原始文本'].apply(lambda x: x.lower())
第二部分,就是简单划分一下train数据集,然后进行模型的训练;代码如下:
from sklearn.model_selection import train_test_split #y用于切分数据集
# 以8:2的比例来划分训练集和验证集
train_en1, dev_en = train_test_split(train_en, test_size=.2, random_state=2)
train_jp1, dev_jp = train_test_split(train_jp, test_size=.2, random_state=2)
# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_jp1['words'].tolist() + train_en1['words'].tolist(),
train_jp1['意图'].tolist() + train_en1['意图'].tolist()
)
dev_a = dev_en['words'].tolist() + dev_jp['words'].tolist()
output_dev = pipline.predict(dev_a)
num_dev = len(dev_a)
tmp = 0
for i in range(num_dev):
if(output_dev[i] == y_dev[i]):
tmp += 1
acc = tmp / num_dev
print(acc)
train1 = train_en1['words'].tolist() + train_jp1['words'].tolist()
y_train = train_en1['意图'].tolist() + train_jp1['意图'].tolist()
output_train = pipline.predict(train1)
num_train = len(train1)
tmp = 0
for i in range(num_train):
if(output_train[i] == y_train[i]):
tmp += 1
acc_train = tmp / num_train
print(acc_train)
两个acc的结果可见截图:
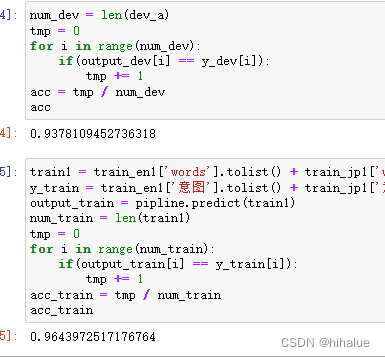
额外思考
其实TfidfVectorizer()和LogisticRegression()是有很多参数提供使用的;但是在简单的测试参数的时候,发现貌似默认的情况会好一点?(当然,没有认真去调参,只是简单加几个参数,看看acc的差别)
代码如下:
# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(ngram_range=(1,3)),
LogisticRegression(tol=1e-5)
)
只是简单给个例子,因为参数组合比较多,不放全部组合的例子了
结果见图:
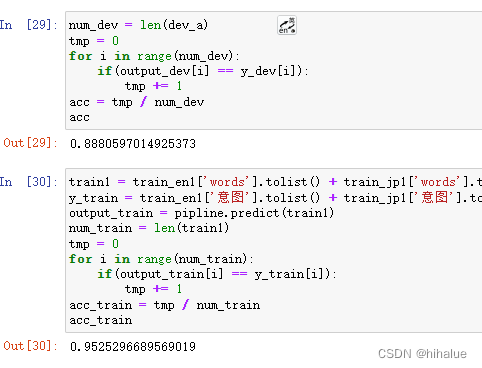
所以,目前来看,默认情况貌似会更好一丢丢~
步骤3:将步骤2预测的结果文件提交到比赛,截图分数
最终输出的不仅需要意图,很多情况还有具体的参数,比如空调调到多少度。但是这里,先完成打卡,先把这个结果提交一下(从学习的角度来看是可以的,但是如果你想要分数高一点,毕竟是竞赛,可以等任务4,再具体得到而外的输出再一起提交)
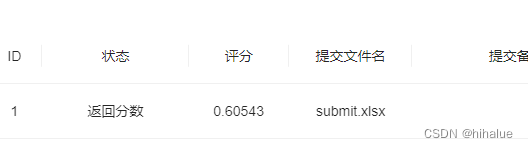
任务4:正则表达式
Todo…
任务5:BERT模型入门
Todo…
任务6:BERT文本分类
Todo…
任务7:BER实体抽取
Todo…