���ĵ�ַ:https://arxiv.org/pdf/2202.03052.pdf
��ز���:
����Ȼ���Դ���������ģ̬��CLIP:����Ȼ���Լල��ѧϰ��Ǩ���Ӿ�ģ��
����Ȼ���Դ���������ģ̬��ViT-BERT:�ڷ�ͼ���ı���������Ԥѵ��ͳһ����ģ��
����Ȼ���Դ���������ģ̬��BLIP:����ͳһ�Ӿ�������������ɵ��Ծ�����ͼ��Ԥѵ��
����Ȼ���Դ���������ģ̬��FLAVA:һ���������Ժ��Ӿ�����ģ��
����Ȼ���Դ���������ģ̬��SIMVLM:�������ල�ļ��Ӿ�����ģ��Ԥѵ��
����Ȼ���Դ���������ģ̬��UniT:����ͳһTransformer�Ķ�ģ̬������ѧϰ
����Ȼ���Դ���������ģ̬��Product1M:���ڿ�ģ̬Ԥѵ�������ලʵ������Ʒ����
����Ȼ���Դ���������ģ̬��ALBEF:���ڶ���������Ӿ����Ա�ʾѧϰ
����Ȼ���Դ���������ģ̬��VinVL:�ع��Ӿ�����ģ���е��Ӿ���ʾ
����Ȼ���Դ���������ģ̬��OFA:ͨ����sequence-to-sequenceѧϰ���ͳһ�ܹ��������ģ̬
һ�����
? ���˹���������,����һ���������ദ��������Ͷ�ģ̬��ȫ��ģ����һ������������Ŀ�ꡣ���Ŀ��ĺ����������ڵ�һģ���б��������ͬģ̬�������ѵ�����ơ�
?
Transformer
\text{Transformer}
Transformer�ܹ����ڵķ�չ�Ѿ�չʾ�����Ϊͨ�ü��������DZ�����ڼලѧϰ��������,Ԥѵ��-����ʽ����������ʵ���˾�ijɹ�,����few-/zero-shotѧϰ�Ļ�����,����prompt/instruction tuning������ģ�ͱ�֤����ǿ����few-/zero-shotѧϰ������Щ����Ϊȫ��ģ�͵ij����ṩ�˸���Ҫ�Ļ��ᡣ
? Ϊ���ڱ��ֶ��������ܺ������Ե�ͬʱ,���õ�֧�ֿ���������ķ�������,��������ȫ��ģ��Ӧ�þ����������������:(1) ������( TA \text{TA} TA):ͳһ����ı�ʾ��֧�ֲ�ͬ���͵�����,�������ࡢ���ɡ��Լල�����,���Ҷ���Ԥѵ���������Dz���֪��;(2) ģ̬��( MA \text{MA} MA):�����е�������,���ڴ�����ͬ��ģ̬ͳһ����������ʾ;(3) ����ȫ��( TC \text{TC} TC):�㹻���������������ӷ��������Ļ��ۡ�
? Ȼ��,Ҫ��ʵ����Խ���ܵ�ͬʱ������������������Ǿ�����ս�Եġ�������������ѡ��,��ǰ�����ԺͶ�ģ̬Ԥѵ��ģ�ͺ�������ijЩ�����ϲ����㡣(1) �������Ķ����ѧϰ���,����:������ص�ͷ��adapters��soft propmts����ʹ��ģ�;������������,�Ӷ�Υ����
TA
\text{TA}
TA������,Ѱ���������Ҳʮ������,������������ƶ���δ���������zero-shot�����Ѻá�(2) ������ص���ʽ�����ڴ������ǰ�ķ���,Ԥѵ��������zero-shotͨ����������ʽ��ѵ��Ŀ���Dz�ͬ����Υ����
TA
\text{TA}
TA,����ͨ����������������ʵ��
TC
\text{TC}
TC��һ�ָ�����(3) ��Ը���I/O��ģ̬�����ơ�
VL
\text{VL}
VLԤѵ��ģ�͵�ͨ�������ǽ�����Ŀ����Ϊ����������������������ı��֡�Ȼ��,����ģ̬��ص����ʹ��ͼ���Ŀ��ĸ��������һ����ʹ����������ģ���к��ѽ�ģ����ͼ�����ɡ�����Ŀ����һ��ѵ����
? ���,����̽�������ڶ�ģ̬Ԥѵ����ȫ��ģ��,�������ģ��
OFA,One?For?All
\text{OFA,One For All}
OFA,One?For?All,��ʵ����ͳһ�ܹ���ģ̬�������Ŀ��,��֧��������������ԡ�������˵,��Ԥѵ������������ʽ��Ϊͳһ��sequence-to-sequence,��ͨ���ֹ���instructions��ʵ�����������ء�
Transformer
\text{Transformer}
Transformer��Ϊģ̬�صļ�������,�����һ��Լ��,����ѧϰ��������ػ���ģ̬���������ᱻ������������������Ա�ʾ��ͬģ�͵���Ϣ,ͨ��һ�������������ȫ�ֹ�����ģ̬�ʱ���
? �ܵ���˵:
-
��������� OFA \text{OFA} OFA,һ��֧��ȫ�����������֪��ģ̬����֪��ܡ���ͨ������
instruction��seq-to-seqѧϰ���ͳһ������,�������������,����:image generation��visual grounding��visual question answering��image captioning��image classification��language modeling�� -
ʵ������ʾ OFA \text{OFA} OFA�ڶ�ģ̬����ʵ�����µ� SOTA \text{SOTA} SOTA,����:
image captioning��text-to-image generation��VQA��SNLI-VE��; -
����֤���� OFA \text{OFA} OFA��
zero-shotѧϰ��ʵ�����о������ı��֡�����,���ܹ�ͨ���µ�����instructionǨ����δ����������,���Ҳ���Ӧ�����������Ӧ��������Ϣ��
����OFA
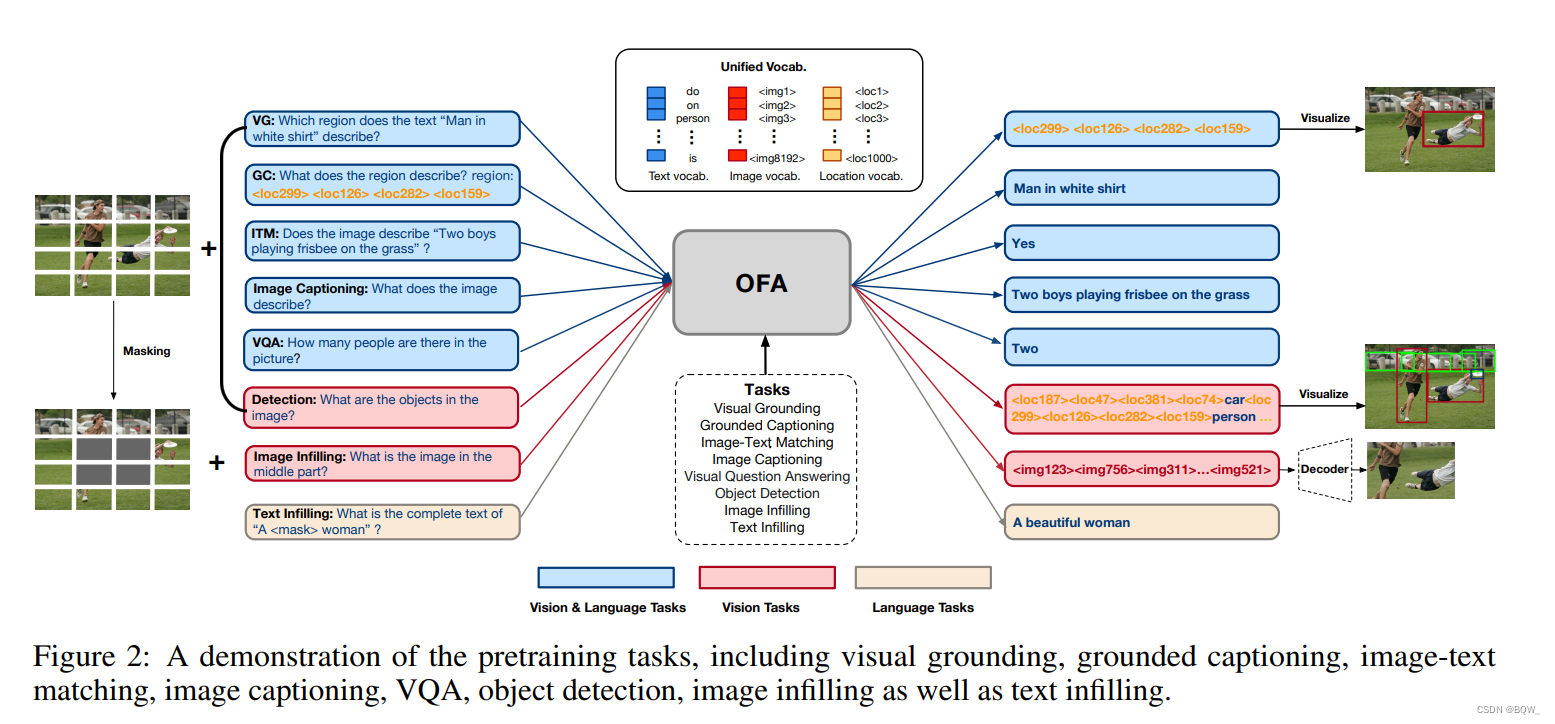
? OFA \text{OFA} OFA����ܹ�����ͼ������
1. I/O&�ܹ�
- I/O
? ��ģ̬Ԥѵ����Ҫ�ڴ��ģimage-text������Ԥѵ��
Transformer
\text{Transformer}
Transformerģ�͡�Ϊ���ܹ����ж�ģ̬Ԥѵ��,��Ҫ�����ݽ���Ԥ����ʹ���Ӿ���������Ϣ�ܹ���
Transformer
\text{Transformer}
Transformer���ϴ���������ڸ����Һ�ʱ������Դ��Ŀ��������,���ļ��������,ֱ�ӽ�һ��ͼ��
x
v
��
R
H
��
W
��
C
\textbf{x}_{v}\in\mathbb{R}^{H\times W\times C}
xv?��RH��W��C����Ϊ
P
P
P��patches,���ҽ�patchesͶӰ��hidden sizeΪ
H
H
H���������ڴ���������Ϣʱ,��ѭ
GPT
\text{GPT}
GPT��
BART
\text{BART}
BARTʵ��,Ӧ��byte-pair encoding(BPE)�����������ı�����ת��Ϊ�Ӵ�����,Ȼ����Ƕ���������
? Ϊ����������ص����ģʽ��������ͬ��ģ̬,��ͳһ�Ŀռ��б�ʾ����ģ̬���������б�Ҫ�ġ�һ�ֿ��ܵĽ����������ɢ���ı���ͼ���Ŀ����һ��ͳһ������ʱ���������ͼ�������ϵĽ�չ�Ѿ�֤����text-to-image�ϳɵ���Ч��,��˱�����Ŀ��˵�ͼ���ʾ������������ԡ�ϡ�����������ͼ���ʾ�����г���ʱ����Ч�ġ�����,һ���ֱ���Ϊ
256
��
256
256\times 256
256��256��ͼ��ʾΪ����Ϊ
16
��
16
16\times 16
16��16��code���С�ÿ����ɢ�ı��붼����ڵ�patchǿ��ء�
? ���˱�ʾͼ������,��ʾͼ���е�Ŀ�����б�Ҫ��,��Ϊ��һϵ��������ص�������ѭ��ǰ�Ĺ���,��Ŀ���ʾΪ��ɢtokens�����С�������˵,����ÿ��Ŀ��,��ȡ���ı�ǩ������bounding box��bounding box�����������걻ͳһ��ɢ��Ϊ��������Ϊλ��tokens
?
x
1
,
y
1
,
x
2
,
y
2
?
\langle x_1,y_1,x_2,y_2 \rangle
?x1?,y1?,x2?,y2??��Ϊ�˸��ӵļ�,Ϊ���е����Ժ��Ӿ�tokensʹ��ͳһ�Ĵʱ�,����:�ִʡ�image codes��location tokens��
- �ܹ�
? ��ѭ��ǰ��ģ̬Ԥѵ���ɹ���ʵ��,ѡ��
Transformer
\text{Transformer}
Transformer��Ϊbackbone�ܹ�,���Ҳ���encoder-decoder������Ϊ����Ԥѵ�������Լ�zero-shot����ļܹ���������˵,encoder��decoder���Ƕѵ���
Transformer
\text{Transformer}
Transformer�㡣һ��
Transformer
\text{Transformer}
Transformer���������ע������
FFN
\text{FFN}
FFN���,��
Transformer
\text{Transformer}
Transformer��������������ע�������ơ�
FFN
\text{FFN}
FFN�����ӽ������ͱ����������ʾ�Ľ���ע������ɡ�Ϊ���ȶ�ѵ�����Ҽ�������,��������ע������head scaling��һ����ע������layer normalization,�Լ��ڵ�һ��
FFN
\text{FFN}
FFN���
LN
\text{LN}
LN�㡣
2. ����&ģ̬
? һ��ͳһ�Ŀ�ܱ�������ṩ�粻ͬģ̬����������ļܹ�����,�Ӷ���ͬһģ���з�����δ����������ģ����Ҫ��ͳһ�ķ�ʽ�г��ֲ�ͬģ���¾����ܵ������������,Ԥѵ������������Ҫ���Ƕ�����Ͷ�ģ̬��
? Ϊ��ͳһ�����ģ̬,���������sequence-to-sequenceѧϰ��ʽ��Ԥѵ���������������е�������Щ�������:Ԥѵ���������εĿ�ģ̬�͵�ģ̬�����Լ�����Seq2Seq��ʽ�����������ڶ�ģ̬�͵�ģ̬��ִ�ж�����Ԥѵ���ܹ�ʹģ�;����ۺ�������������˵,�����������Ϲ���ͳһ��schema,ͬʱΪ���ֲ�ͬ�������ṩ�ֹ���instructions��
? ���ڿ�ģ̬��ʾѧϰ,�����5������,����visual grounding(VG)��grounded captioning(GC)��image-text matching(ITM)��image captioning(IC)�Լ�visual question answering(VQA)������
VG
\text{VG}
VG,ģ�ͻ����ͼ��
x
i
x_i
xi?��instruction
Which?region?dose?the?text?
x
t
?describe?
\text{Which region dose the text }x_t\text{ describe?}
Which?region?dose?the?text?xt??describe?�����ɾ���λ��
?
x
1
,
y
1
,
x
2
,
y
2
?
\langle x_1,y_1,x_2,y_2 \rangle
?x1?,y1?,x2?,y2??��location tokens,����
x
t
x_t
xt?������caption��
GC
\text{GC}
GC��
VG
\text{VG}
VG��������ģ�ͻ��������ͼ��
x
i
x_i
xi?��instruction
What?does?the?region?describe?region:
?
x
1
,
y
1
,
x
2
,
y
2
?
\text{What does the region describe?region:}\langle x_1,y_1,x_2,y_2 \rangle
What?does?the?region?describe?region:?x1?,y1?,x2?,y2??����������������
ITM
\text{ITM}
ITM,ʹ��ԭʼ��image-text����Ϊ������,Ȼ��ͨ��ͼ����caption�������������츺������ģ��ѧϰ�жϸ�����ͼ����ı��Ƿ������ѧϰ����Yes����No,����ͼ��
x
i
\text{x}_i
xi?��instruction
Does?the?image?describe?
x
t
?
\text{Does the image describe }x_t?
Does?the?image?describe?xt??������image captioning,��������ܹ���Ȼ�IJ���sequence-to-sequence��ʽ��ģ�ͻ���ڸ�����ͼ���instruction
What?does?the?image?describe?
\text{What does the image describe?}
What?does?the?image?describe?��ѧϰ����caption������
VQA
\text{VQA}
VQA,��ͼ���������Ϊ����,����Ҫģ��ѧϰ������ȷ�Ĵ𰸡�
? ���ڵ�ģ̬��ʾѧϰ,Ϊ�Ӿ������2������,���������1������ģ��ͨ��ͼ��infilliing��Ŀ������Ԥѵ��ѧϰ�Ӿ���ʾ���ڼ�����Ӿ��������Լලѧϰ�еĽ��ڽ�չ��ʾmasked image modeling��һ����Ч��Ԥѵ������ʵ����,���ڱ����м䲿�ֵ�ͼ����Ϊ���롣ģ�ʹӻ��ڱ��ƻ������ͼ���instruction
What?is?the?image?in?the?middle?part?
\text{What is the image in the middle part?}
What?is?the?image?in?the?middle?part?������ͼ�����IJ��ֵ�ϡ����롣����,��Ԥѵ���ж���������Ŀ��������ģ�ͻ���ͼ��������ı�
What?are?the?objects?in?the?image?
\text{What are the objects in the image?}
What?are?the?objects?in?the?image?��ѧϰ�����˹���ע��Ŀ���ʾ,��Ŀ��λ�úͱ�ǩ�����С��������Ա�ʾѧϰ,��ͨ�����ı������Ͻ����ı������Ԥѵ����
? ͨ�����ַ�ʽ,������ģ̬�Ͷ�������ͳһ������ģ�ͺ�Ԥѵ����ʽ�С� OFA \text{OFA} OFA��������Щ���������Ԥѵ���ġ����,��������Բ�ͬ��ģ̬���ӵĿ�ģ̬����ִ�в�ͬ������,���������ɴ𰸵�������
3. Ԥѵ�����ݼ�
? ͨ���ϲ��Ӿ��������ݡ��Ӿ����ݺ���������������Ԥѵ�����ݼ���Ϊ�˿ɸ���,��ʹ�ù������ݼ�������ͨ����ϸ�Ĺ���Ԥѵ���������ų����������е���֤�Ͳ��Լ�ͼ��,�Ա�������й¶��
4. ѵ��&�ƶ�
? ʹ�ý�������ʧ�������Ż�ģ�͡�����һ������
x
x
x,һ��instruction
s
s
s��һ�����
y
y
y,ͨ����С����ʧ����
L
=
?
��
i
=
1
�O
y
�O
log
P
��
(
y
i
�O
y
<
i
,
x
,
s
)
\mathcal{L}=-\sum_{i=1}^{|y|}\text{log} P_\theta(y_i|y_{<i},x,s)
L=?��i=1�Oy�O?logP��?(yi?�Oy<i?,x,s)��ѵ��
OFA
\text{OFA}
OFA,����
��
\theta
����ģ�Ͳ����������ƶ�,��Ӧ�ý������,����beam search,����ǿ���ɵ�������Ȼ��,���ַ�ʽ�ڷ����������м�������:(1) �Ż������ʱ��Dz���Ҫ��Ч�ʵ���;2. ���ƶϹ�����,ģ�Ϳ��ܻ����ɳ�����ձ�ǩ������Ч��ǩ��Ϊ�˿˷���Щ����,������ѵ��ʱ���ƶ�ʱ�����˻���ǰ�����������ԡ�ʵ������ʾ����ǰ�������IJ����ܹ���ǿ
OFA
\text{OFA}
OFA�ڷ��������ϵ�Ч����
����ʵ��
- OFA \text{OFA} OFA�ڿ�ģ�͵�����������ʵ���� SOTA \text{SOTA} SOTA
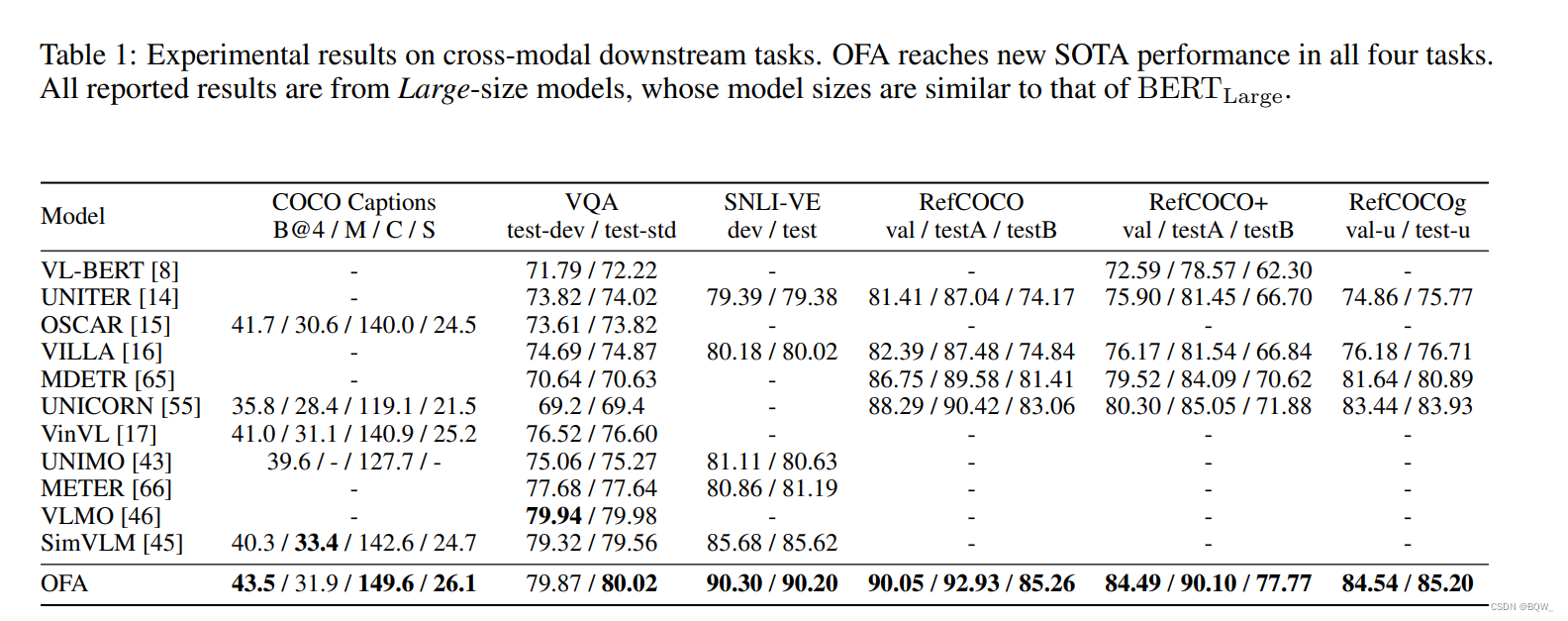
text-to-image��������Ľ��, OFA \text{OFA} OFA��Խ��baseline��
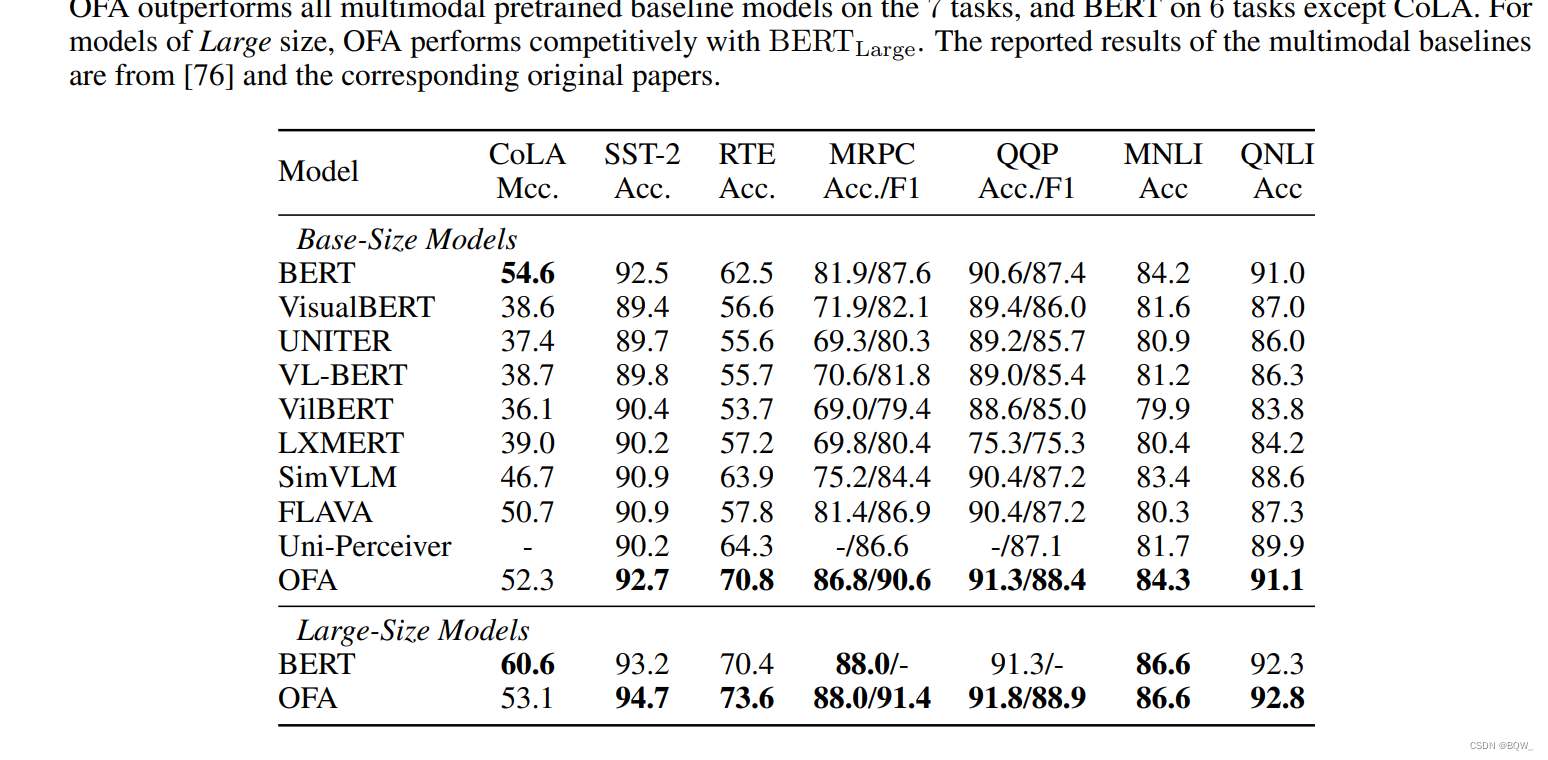
- BERT \text{BERT} BERT�Ͷ�ģ̬Ԥѵ��ģ���� GLUE \text{GLUE} GLUE�ϵĽ��, OFA \text{OFA} OFA�������еĶ�ģ̬Ԥѵ��baseline��
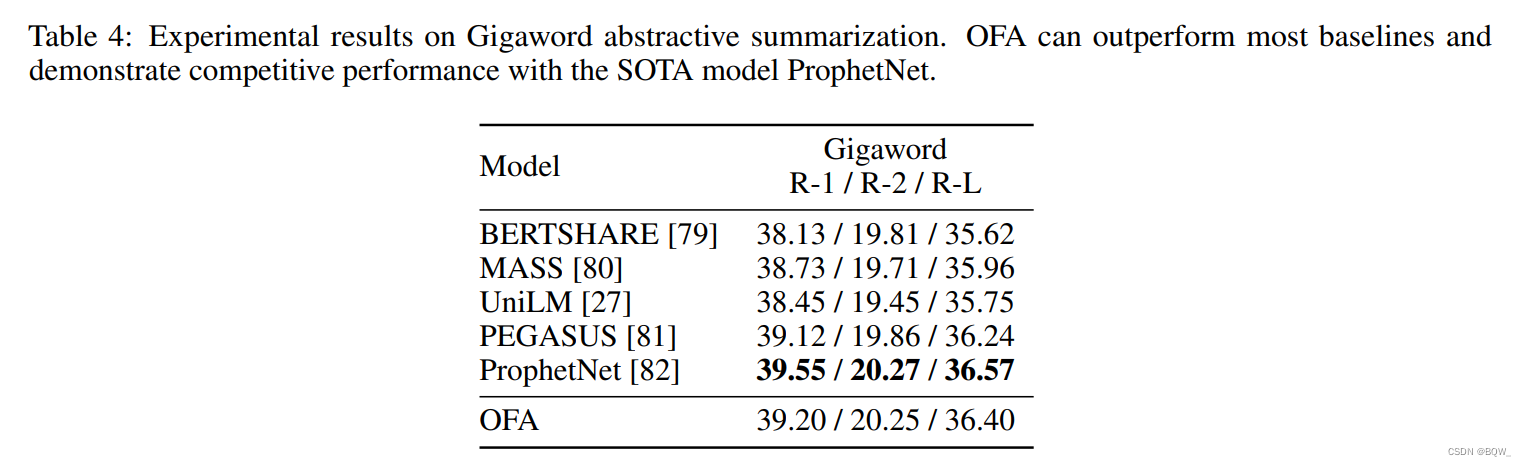
Gigaword����ʽժҪ�Ľ���� OFA \text{OFA} OFA���ڴ������baseline��
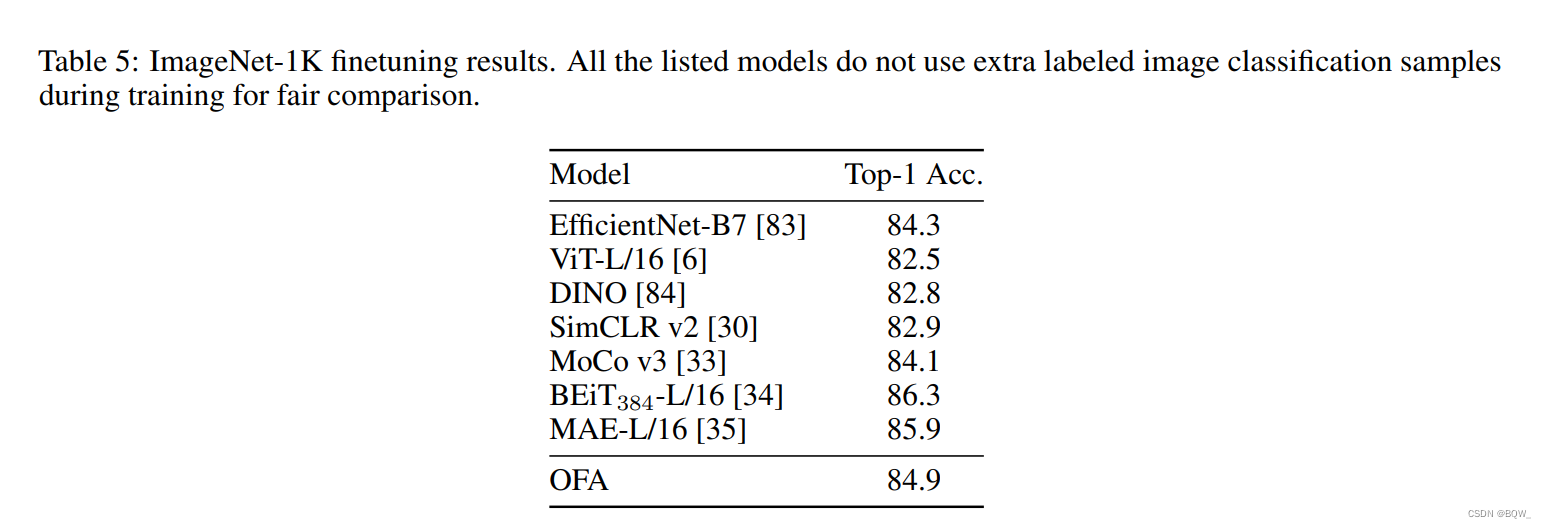
- �� ImageNet-1K \text{ImageNet-1K} ImageNet-1K�����Ľ����
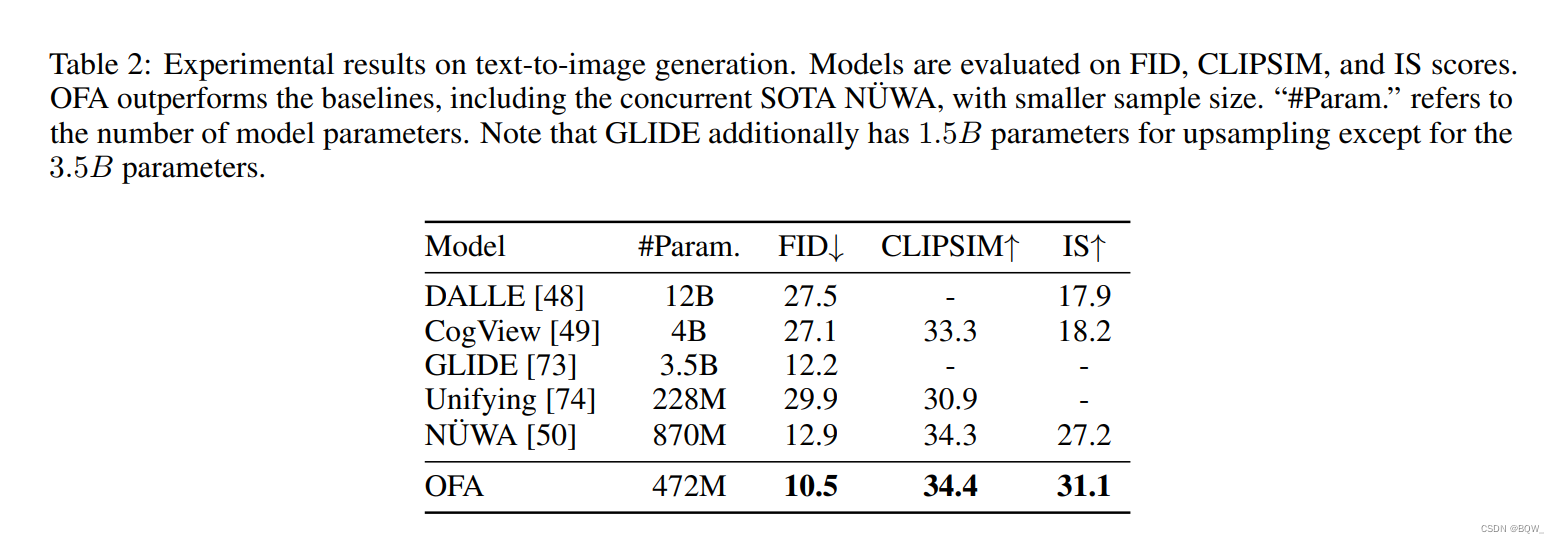
- ��6��
GLUE
\text{GLUE}
GLUE�������
SNLI-VE
\text{SNLI-VE}
SNLI-VE�ϵ�
zero-shot��