文章目录
一.前言
1.1 本文原理
KNN算法:通过在整个训练集中搜索k个最相似的实例(邻居)并汇总这些k个实例的输出变量来预测新的数据点。它可以用于分类和回归,是一种监督学习算法。
混淆矩阵:至少有m*m的表。前m行和m列的条目CMJ表示分类器标记为J的类I元组数。
1.2 本文目的
- 使用scikit-learn的数据归一化函数,对鸢尾花数据进行归一化;
- 使用scikit-learn的切分数据集函数,将鸢尾花数据切分为训练数据集和测试数据集;
- 使用scikit-learn的KNN算法,对鸢尾花进行分类训练和测试(即预测);
- 使用scikit-learn的混淆矩阵函数,显示性能评估的混淆矩阵以及准确率,并分析混淆矩阵的内容;
二.实验过程
2.1 使用scikit-learn的数据归一化函数,对鸢尾花数据进行归一化;
老规矩,先使用load_iris模块,里面有150组鸢尾花特征数据,我们可以拿来进行学习特征分类。
如下代码:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
引入混淆矩阵confusion_matrix函数,评估方法函数accuracy_score,数据预处理函数模块preprocessing如下:
from sklearn.metrics import confusion_matrix,accuracy_score,recall_score,precision_score
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
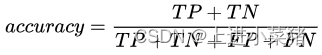
数据预处理:按列归一化
iris_X=preprocessing.scale(X)
输出归一化结果如下:
print(iris_X)
2.2 使用scikit-learn的切分数据集函数,将鸢尾花数据切分为训练数据集和测试数据集;
随机划分训练集和测试集切分数据集函数如下:
X_train,X_test,y_train,y_test =train_test_split(iris_X,y,test_size=0.3,random_state=0)
功能是从样本中随机的按比例选取train_data和test_data
我们输出来看一下:
print(X_train)
print(X_test)
print(y_train)
print(y_test)
2.3使用scikit-learn的KNN算法,对鸢尾花进行分类训练和测试(即预测);
KNN分类模型如下:
引入k近邻算法模块:
from sklearn import neighbors
KNeighborsClassifier用于实现k近邻投票算法的分类器如下:
model=neighbors.KNeighborsClassifier(n_neighbors=3)
查询使用的邻居数。就是k-NN的k的值,选取最近的k个点。这里选择最近的3个点。
模型训练如下:
model.fit(X_train,y_train)
模型预测如下:
v_pred=model.predict(X_test)
输出鸢尾花特征分类结果如下:
print(v_pred)

2.4 使用scikit-learn的混淆矩阵函数,显示性能评估的混淆矩阵以及准确率,并分析混淆矩阵的内容;
使用混淆矩阵confusion_matrix:
confusion_matrix(y_test,v_pred)
输出混淆矩阵:
print(confusion_matrix(y_test,v_pred))
输出准确率:
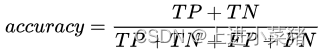
print("准确率:%.3f"% accuracy_score(y_test,v_pred))
结果如下:

2.5 分析混淆矩阵的内容以及总结
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
y_true: 是样本真实分类结果 y_pred: 是样本预测分类结果 labels:是所给出的类别,通过这个可对类别进行选择 sample_weight : 样本权重
预测正确的结果占总样本的百分比的97.8,本次KNN算法对鸢尾花进行分类训练和测试效果非常的准确。
总结:
1.熟悉机器学习之KNN算法及性能评估方法
2.使用KNN算法解决问题并做性能评估
