зджїМнЪЛГЕСОЕФЪгОѕSLAMЗНЗЈЛиЙЫ
дТлЮФдкЮФеТФЉЮВЁЃ
еЊвЊ:
зджїМнЪЛГЕСОдкВЛЭЌЕФМнЪЛЛЗОГжаЖМашвЊОЋШЗЕФЖЈЮЛКЭВтЛцНтОіЗНАИЁЃдкетжжЧщПіЯТ,ЭЌВНЖЈЮЛКЭВтЛц(SLAM)ММЪѕЪЧвЛИіКмКУЕФбаОПНтОіЗНАИЁЃЙтЬНВтКЭВтОр(LIDAR)КЭЩуЯёЭЗДЋИаЦїЭЈГЃгУгкЖЈЮЛКЭИажЊЁЃШЛЖј,ЭЈЙ§ЪЎФъЛђЖўЪЎФъЕФбнБф,МЄЙтРзДя-SLAMЗНЗЈЫЦКѕУЛгаЪВУДБфЛЏЁЃгыЛљгкМЄЙтРзДяЕФЗНАИЯрБШ,ЪгОѕSLAMОпгаКмЧПЕФГЁОАЪЖБ№ФмСІ,ВЂОпгаГЩБОЕЭКЭвзгкАВзАЕФгХЕуЁЃЪТЪЕЩЯ,дкздЖЏМнЪЛСьгђ,ШЫУЧе§ЪдЭМгУЩуЯёЭЗШЁДњМЄЙтРзДяДЋИаЦї,ЛђдкЩуЯёЭЗЕФЛљДЁЩЯМЏГЩЦфЫћДЋИаЦїЁЃЛљгкЪгОѕSLAMЕФбаОПЯжзД,БОзлЪіКИЧСЫЪгОѕSLAMММЪѕЁЃЬиБ№ЪЧ,ЮвУЧЪзЯШЫЕУїСЫЪгОѕSLAMЕФЕфаЭНсЙЙЁЃЦфДЮ,ЖдЪгОѕКЭЛљгкЪгОѕЕФ(МДЪгОѕ-ЙпадЁЂЪгОѕ-МЄЙтРзДяЁЂЪгОѕ-МЄЙтРзДя-IMU)SLAMЕФзюЯШНјбаОПНјааСЫШЋУцЛиЙЫ,ВЂНЋЮвУЧвдЧАЕФЙЄзїгыЙЋЙВЪ§ОнМЏЩЯЕФжЊУћПђМмЕФЖЈЮЛОЋЖШНјааСЫБШНЯЁЃзюКѓ,ЬжТлСЫЪгОѕSLAMММЪѕдкздЖЏМнЪЛЦћГЕгІгУжаЕФЙиМќЮЪЬтКЭЮДРДЗЂеЙЧїЪЦЁЃ
ЮЪЬтКЭЗНАИ:
гыДѓЖрЪ§ПЊЗЂЕФЪгОѕSLAMЗНЗЈЫљВтЪдЕФЪвФкЛђЪвЭтвЦЖЏЛњЦїШЫВЛЭЌ,зджїМнЪЛГЕСОгаИќИДдгЕФВЮЪ§ашвЊПМТЧ,ЬиБ№ЪЧЕБГЕСОдкГЧЪаЛЗОГжазджїМнЪЛЪБЁЃР§Шч,ЛЗОГЧјгђЕФЙцФЃНЯДѓ,гаЖЏЬЌЕФеЯАЮя,ДгЖјЪЙЪгОѕSLAMЗНЗЈЕФадФмВЛЙЛзМШЗКЭЮШНЁ(CadenaЕШШЫ,2016a)ЁЃЮѓВюЛ§РлЁЂЙтееБфЛЏКЭПьЫйдЫЖЏЕШЮЪЬтЕМжТСЫЙРЫуЕФЮЪЬтЁЃЮЊСЫНтОіетаЉгызджїМнЪЛГЕСОЯрЙиЕФЮЪЬт,ШЫУЧПМТЧСЫИїжжЗНЗЈЁЃШчЛљгкЬиеїЕу/жБНг/АыжБНг/ЕуЯпШкКЯЕФЪгОѕВтОр(VO)ЕФЫуЗЈЁЃКЭРЉеЙПЈЖћТќТЫВЈ(EKF)/ЛљгкЭМаЮЕФгХЛЏЫуЗЈНјаазЫЬЌЙРМЦ(TaklehЕШШЫ,2018)ЁЃСэЭт,ЛљгкЪгОѕЕФЖрДЋИаЦїШкКЯЗНЗЈдкЬсИпзджїЯЕЭГЕФОЋЖШЗНУцвВв§Ц№СЫМЋДѓЕФЙизЂЁЃ
ЮФеТАВХХ:
ОЭЛљгкЪгОѕЕФSLAMЯЕЭГЖјбд,Г§СЫжЦЭМФЃПщ,ДЋИаЦїЪ§ОнЕФЪеМЏ,ШчЯрЛњЛђЙпадВтСПЕЅдЊ(IMU)ЁЂVOКЭЪгОѕЙпадВтОр(VIO)ЯЕЭГЖМдкЧАЖЫЭъГЩ,ЖјгХЛЏЁЂБеЛЗдђдкКѓЖЫЭъГЩЁЃдйЖЈЮЛзмЪЧБЛШЯЮЊЪЧЬсИпЪгОѕSLAMЯЕЭГОЋЖШЕФвЛИіИНМгФЃПщ(TaketomiЕШШЫ,2017)ЁЃдкБОЮФжа,ЖдЪгОѕSLAMЗНЗЈНјааСЫЛиЙЫЁЃжївЊДгЪгОѕSLAMЯЕЭГЕФЖЈЮЛОЋЖШЗНУцПМТЧ,ОЁПЩФмЯъЯИЕибаОПСЫПЩФмгІгУгкздЖЏМнЪЛГЁОАЕФЗНЗЈ,АќРЈДПЪгОѕSLAMЗНЗЈЁЂЪгОѕ-ЙпадSLAMЗНЗЈКЭЪгОѕ-МЄЙтРзДя-ЙпадSLAMЗНЗЈ,ВЂНЋЮвУЧвдЧАЕФЙЄзїгыЙЋЙВЪ§ОнМЏЩЯЕФжЊУћЗНЗЈЕФЖЈЮЛОЋЖШНјааСЫБШНЯЁЃетЦЊзлЪіЬсЙЉСЫЪгОѕSLAMММЪѕЕФЯъЯИЕїВщ,ПЩвдзїЮЊзджїМнЪЛЦћГЕСьгђаТбаОПШЫдБЕФгбКУжИФЯЁЃЭЌЪБ,ЫќвВПЩвдБЛШЯЮЊЪЧгаОбщЕФбаОПШЫдБбАЧѓЮДРДЙЄзїЕФПЩФмЗНЯђЕФзжЕфЁЃБОЮФЕФЦфгрВПЗжНсЙЙШчЯТЁЃЪзЯШ,ЮвУЧНщЩмСЫЪгОѕSLAMЯЕЭГЕФдРэ,дкЕкЖўНкжаЦРТлСЫЯрЛњДЋИаЦїЁЂЧАЖЫЁЂКѓЖЫЁЂБеЛЗКЭНЈЭМФЃПщЕФжАд№ЁЃЦфДЮ,дкЕк3НкжаЫЕУїСЫЪгОѕЁЂЪгОѕ-ЙпадЁЂЪгОѕ-МЄЙтРзДяКЭЪгОѕ-МЄЙтРзДя-IMU SLAMЗНЗЈЕФзюЯШНјбаОПЁЃЕкШ§НкЬжТлСЫЪгОѕSLAMММЪѕдкздЖЏМнЪЛЦћГЕгІгУжаЕФЙиМќЮЪЬтКЭЮДРДЗЂеЙЧїЪЦЁЃзюКѓ,дкЕк5НкжаЕУГіНсТлЁЃ
ЪгОѕSLAMЕФддђ

ЪгОѕSLAMЕФдРэЪгОѕSLAMЯЕЭГЕФОЕфНсЙЙПЩвдЗжЮЊЮхИіВПЗжЁЃЯрЛњДЋИаЦїФЃПщЁЂЧАЖЫФЃПщЁЂКѓЖЫФЃПщЁЂБеЛЗФЃПщКЭНЈЭМФЃПщЁЃШчЭМ1ЫљЪО,ЯрЛњДЋИаЦїФЃПщИКд№ЪеМЏЭМЯёЪ§Он,ЧАЖЫФЃПщИКд№ИњзйЯрСкСНжЁжЎМфЕФЭМЯёЬиеї,ЪЕЯжГѕЪМЕФЯрЛњдЫЖЏЙРМЦКЭОжВПНЈЭМ,КѓЖЫФЃПщИКд№ДгЧАЖЫНјааЪ§жЕгХЛЏВЂНјвЛВННјаадЫЖЏЙРМЦ,БеЛЗФЃПщИКд№ЭЈЙ§МЦЫуДѓГпЖШЛЗОГЯТЕФЭМЯёЯрЫЦЖШРДЯћГ§РлЛ§ЮѓВю,НЈЭМФЃПщИКд№жиНЈжмЮЇЛЗОГ(GaoЕШ,2017)ЁЃ
ЁА2.1. Camera sensorsЁБ
ИљОнДЋИаЦїЕФВЛЭЌРраЭ,ГЃМћЕФЪгОѕДЋИаЦїжївЊПЩЗжЮЊЕЅФПЁЂЫЋФПЁЂRGB-DКЭЪТМўЯрЛњЁЃЩуЯёЛњЕФДЋИаЦїШчЭМ2ЫљЪОЁЃ (a). ЕЅФПЩуЯёЭЗ,ЕЅФПЩуЯёЭЗОпгаГЩБОЕЭЁЂВМОжМђЕЅЕФгХЕуЁЃШЛЖј,ЕиБъЕФЩюЖШВЛФмБЛКмКУЕиЙРМЦ,етдкЕиЭМЙЙНЈЙ§ГЬжаДцдкГпЖШФЃК§ЕФЮЪЬт(HaominЕШ,2016)ЁЃДЫЭт,ЕБЯрЛњОВжЙ(ЮоЦНвЦ)ЛђжЛгаДПа§зЊЪБ,ЮоЗЈЛёЕУЯёЫиОрРыЁЃ(b). ЫЋФПЯрЛњ,гыЕЅФПЯрЛњЯрБШ,ЫЋФПSLAMПЩвддкОВЬЌзДЬЌЯТвРППЯрЛњЕФВтСПжЕРДМЦЫуЯёЫиЩюЖШ,вВБЛжЄУїдкЛЇЭтЛЗОГЯТБШЕЅФПSLAMИќЮШНЁЁЃШЛЖј,ЩюЖШВтСПЕФЗЖЮЇЪмЕНЛљЯпГЄЖШКЭЗжБцТЪЕФЯожЦ,ВЮЪ§ХфжУКЭаЃзМЕФЙ§ГЬвВКмИДдг,вђЮЊЯрЛњашвЊДІРэЫЋжиЭМЯёаХЯЂ,ЖджабыДІРэЕЅдЊ(CPU)РДЫЕ,МЦЫуГЩБОИќИпЁЃ(c). RGB-DЯрЛњ,гыЕЅФПКЭЫЋФПЯрЛњВЛЭЌ,RGB-DЯрЛњПЩвдЭЈЙ§КьЭтНсЙЙЙтКЭ/ЛђЗЩааЪБМф(TOF)жБНгЛёЕУЯёЫиЩюЖШ,БмУтСЫИДдгЕФМЦЫуЁЃTOFЕФРэТлЪЧ,ЭЈЙ§ВтСПМЄЙтЕФЗЩааЪБМфРДМЦЫуОрРыЁЃШЛЖј,гЩгкВтСПЗЖЮЇЯСе,ЖјЧвМЋвзЪмЕНбєЙтЕФИЩШХ,RGB-DЯрЛњБЛШЯЮЊВЛЪЪКЯЛЇЭтгІгУ,ШчздЖЏМнЪЛГЁОАЁЃ(d). ЪТМўЯрЛњ,ЪТМўЯрЛњОпга140ЗжБДЕФИпЖЏЬЌЗЖЮЇ,ЖјЦфЫћЯрЛњдђДяВЛЕН60ЗжБД,ДЫЭт,ЫќЛЙОпгаИпЪБМфЗжБцТЪЁЂЕЭЙІКФЁЂВЛЪмдЫЖЏФЃК§ЕФгАЯьЁЃЮФЯз(GallegoЕШ,2019)НщЩмЫЕ,ЪТМўЯрЛњВЛЪЧвдЙЬЖЈЕФЫйТЪВЖзНЭМЯё,ЖјЪЧвдвьВНЗНЪНВтСПУПЯёЫиЕФССЖШБфЛЏЁЃвђДЫ,ЪТМўЯрЛњдкИпЫйКЭИпЖЏЬЌЬѕМўЯТЕФВтОргаИќКУЕФБэЯжЁЃЪТМўЯрЛњПЩЗжЮЊЖЏЬЌЪгОѕДЋИаЦї(LichtsteinerЕШ,2008;SonЕШ,2017a;PoschЕШ,2009;HofstatterЕШ,2010)ЁЂЖЏЬЌЯпЬѕДЋИаЦї(PoschЕШ,2007)ЁЂЖЏЬЌКЭжїЖЏЯёЫиЪгОѕДЋИаЦї(BrandliЕШ,2014)КЭЛљгкЪБМфЕФвьВНЭМЯёДЋИаЦї(PoschЕШ,2010)ЁЃ
ЪаГЁЩЯСїааЕФЪгОѕДЋИаЦїжЦдьЩЬКЭВњЦЗСаОйШчЯТ,ЕЋВЛЯогкДЫЁЃ
? MYNTAI: S1030 Series (stereo camera with IMU), D1000 Series (depth camera), D1200 Series (apply to smart phones).
? Stereolabs ZED: Stereolabs ZED camera (Depth Range: 1.5 to 20 m).
? Intel: 200 Series, 300 Series, Module D400 Series, D415 (Active IR Stereo, Rolling shutter), D435 (Active IR Stereo, Global Shutter), D435i (Integrated IMU).
? Microsoft: Azure Kinect (Apply to microphone with IMU), Kinectc-v1(structured-light), Kinect-v2 (TOF).
? Occipital Structure: Structure Camera (apply to ipad).
? Samsung: Gen2 and Gen3 dynamic cameras and event-based visual solution (Son et al., 2017b).ЁБ

ЁА2.2. Front endЁБ
ЪгОѕSLAMЕФЧАЖЫБЛГЦЮЊЪгОѕВтОр(VO)ЁЃЫќИКд№ИљОнЯрСкжЁЕФаХЯЂДѓжТЙРМЦЩуЯёЛњЕФдЫЖЏКЭЬиеїЗНЯђЁЃЮЊСЫвдПьЫйЕФЯьгІЫйЖШЛёЕУзМШЗЕФзЫЬЌ,вЛИіИпаЇЕФVOЪЧБивЊЕФЁЃФПЧА,ЧАЖЫжївЊПЩвдЗжЮЊСНРр:ЛљгкЬиеїЕФЗНЗЈКЭжБНгЗНЗЈ(АќРЈАыжБНгЗНЗЈ)(ZouЕШШЫ,2020)ЁЃдкБОНкжа,ЮвУЧжївЊЛиЙЫЛљгкЬиеїЕФVOЗНЗЈЁЃЙигкАыжБНгЗЈКЭжБНгЗЈ,ШчSVO(ForsterЕШШЫ,2017)КЭDSO(EngelЕШШЫ,2018)дкЕк3.1.2НкУшЪіЁЃЛљгкЬиеїЕуЕФVOЯЕЭГдЫааИќЮШЖЈ,ЖдЙтЯпКЭЖЏЬЌЮяЬхЯрЖдВЛУєИаЁЃОпгаИпГпЖШКЭСМКУа§зЊВЛБфадЕФЬиеїЬсШЁЗНЗЈПЩвдМЋДѓЕиЬсИпVOЯЕЭГЕФПЩППадКЭЮШЖЈад(ChenЕШ,2019)ЁЃ
1999Фъ,Lowe(2004)ЬсГіСЫГпЖШВЛБфЬиеїБфЛЛ(SIFT)ЫуЗЈ,ИУЫуЗЈдк2004ФъЕУЕНСЫИФНјКЭЗЂеЙЁЃећЬхЫуЗЈЗжЮЊШ§ИіВНжшРДЭъГЩЭМЯёЬиеїЕуЕФЬсШЁКЭУшЪіЁЃ
(i). ЭЈЙ§ИпЫЙВюЗжН№зжЫўЗНЗЈЙЙНЈБъЖШПеМф,ЭЈЙ§ИпЫЙВюЗжКЏЪ§ЪЖБ№аЫШЄЕуЁЃ
(ii). ШЗЖЈУПИіКђбЁЕуЕФЮЛжУКЭГпЖШ,ШЛКѓЖЈЮЛетаЉЙиМќЕуЁЃ
(iii). ЮЊЙиМќЕуЗжХфжИЯђадЬиеї,ЕУЕНУшЪізгЁЃ
SIFTЬиеїЖда§зЊЁЂЫѕЗХКЭЙтееБфЛЏНјааЗЧБфаЮ,ЕЋЫќЯћКФСЫДѓСПЕФМЦЫуСПЁЃSpeeded Up Robust Features (SURF)(HerbertЕШШЫ,2007)ЪЧSIFTЕФвЛИіИФНјЁЃЫќНтОіСЫSIFTМЦЫуСПДѓКЭЪЕЪБадВюЕФШБЕу,ЭЌЪБвВБЃГжСЫSIFTдЫЫуЦїЕФгХСМадФмЁЃОЁЙмШчДЫ,SURFЫуЗЈдкгІгУгкЪЕЪБSLAMЯЕЭГЪБгаНЯДѓЕФОжЯоадЁЃдкБЃжЄадФмЕФЛљДЁЩЯ,ЬсГіСЫвЛжжИќМгзЂжиМЦЫуЫйЖШЕФЬиеїЬсШЁЫуЗЈЁЃ2011Фъ,Viswanathan(2011)ЬсГіСЫвЛжжЛљгкФЃАхКЭЛњЦїбЇЯАЗНЗЈЕФОжВПНЧМьВтЗНЗЈ,МДЬиеїРДздМгЫйЖЮВтЪд(FAST)НЧМьВтЗНЗЈЁЃFASTЫуЗЈвдД§МьВтЕФЯёЫиЮЊдВаФ,ЕБЙЬЖЈАыОЖЕФдВЩЯЕФЦфЫћЯёЫигыдВаФЕФЯёЫижЎМфЕФЛвЖШВюзуЙЛДѓЪБ,ИУЕуБЛШЯЮЊЪЧвЛИіНЧЕуЁЃШЛЖј,FASTНЧЕуУЛгаЗНЯђКЭГпЖШаХЯЂ,ЫќУЧВЛОпгаа§зЊКЭГпЖШВЛБфадЁЃ2012Фъ,RubleeЕШШЫ(2012)ЬсГіСЫЛљгкFASTНЧЕуКЭBRIEFУшЪіЗћЕФOriented FAST and Rotated BRIEF(ORB)ЫуЗЈЁЃИУЫуЗЈЪзЯШдкЭМЯёЩЯНЈСЂвЛИіЭМЯёН№зжЫў,ШЛКѓМьВтFASTЙиМќЕуВЂМЦЫуГіЙиМќЕуЕФЬиеїЯђСПЁЃORBЕФУшЪіЗћВЩгУСЫЖўНјжЦзжЗћДЎЬиеїBRIEFУшЪіЗћ(MichaelЕШШЫ,2010)ЕФПьЫйМЦЫуЫйЖШ,ЫљвдORBЕФМЦЫуЫйЖШБШFASTЫуЗЈЕФЪЕЪБЬиеїМьВтЫйЖШПьЁЃДЫЭт,ORBЪмдыЩљгАЯьаЁ,ОпгаСМКУЕФа§зЊВЛБфадКЭГпЖШВЛБфад,ПЩвдгІгУгкЪЕЪБSLAMЯЕЭГЁЃ2016Фъ,ChienЕШШЫ(2016)ЖдVOгІгУжаЕФSIFTЁЂSURFКЭORBЬиеїЬсШЁЫуЗЈНјааСЫБШНЯКЭЦРЙРЁЃЭЈЙ§ЖдKITTIЪ§ОнМЏ(GeigerЕШШЫ,2013)ЕФДѓСПВтЪд,ПЩвдЕУГіНсТл:SIFTЬсШЁЬиеїЕФзМШЗадзюИп,ЖјORBЕФМЦЫуСПНЯаЁЁЃвђДЫ,зїЮЊМЦЫуФмСІгаЯоЕФЧЖШыЪНМЦЫуЛњ,ORBЗНЗЈБЛШЯЮЊИќЪЪКЯгкздЖЏМнЪЛЦћГЕЕФгІгУЁЃ
ЁА2.3. Back endЁБ
КѓЖЫНгЪегЩЧАЖЫЙРМЦЕФЩуЯёЛњзЫЬЌ,ВЂгХЛЏГѕЪМзЫЬЌвдЛёЕУШЋОжвЛжТЕФдЫЖЏЙьМЃКЭЛЗОГЭМ(SunderhaufКЭProtzel,2012)ЁЃгыЧАЖЫЕФЖрбљЛЏЫуЗЈЯрБШ,ФПЧАКѓЖЫЫуЗЈЕФРраЭжївЊПЩвдЗжЮЊСНРрЁЃЛљгкТЫВЈЦїЕФЗНЗЈ(ШчРЉеЙПЈЖћТќТЫВЈЦї(EKF)BaileyЕШШЫ,2006),КЭЛљгкгХЛЏЕФЗНЗЈ(ШчвђзгЭМWrobel,2001)ЁЃЫќУЧЕФУшЪіШчЯТЁЃ
(a). ЛљгкТЫВЈЦїЕФЗНЗЈ,етжжЗНЗЈжївЊЪЧРћгУБДвЖЫЙдРэ,ИљОнвдЧАЕФзДЬЌКЭЕБЧАЕФЙлВтЪ§ОнРДЙРМЦЕБЧАЕФзДЬЌ(Сѕ,2019)ЁЃЕфаЭЕФЛљгкТЫВЈЕФЗНЗЈАќРЈРЉеЙПЈЖћТќТЫВЈ(EKF)(BaileyЕШШЫ,2006)ЁЂЮоКлПЈЖћТќТЫВЈ(UKF)(WanКЭMerwe,2000)КЭСЃзгТЫВЈ(PF)(ArnaudЕШШЫ,2000)ЁЃвдЕфаЭЕФЛљгкEKFЕФSLAMЗНЗЈЮЊР§,ЫќдкаЁЙцФЃЛЗОГжаЕФгІгУЪЧБШНЯГЩЙІЕФЁЃЕЋЪЧ,гЩгкЪЧДцДЂаЗНВюОиеѓ,ЦфДцДЂШнСПЫцзДЬЌСПЕФЦНЗНЖјдіМг,ЖдДѓЕФЮДжЊГЁОАЕФгІгУЪМжеЪмЕНЯожЦЁЃ
(b). ЛљгкгХЛЏЕФЗНЗЈ,ЛљгкЗЧЯпадгХЛЏ(ЭМгХЛЏ)ЗНЗЈЕФКЫаФЫМЯыЪЧНЋКѓЖЫгХЛЏЫуЗЈзЊЛЏЮЊЭМЕФаЮЪН,вдБЛЩуЬхзЫЬЌКЭВЛЭЌЪБПЬЕФЛЗОГЬиеїЮЊЖЅЕу,ЖЅЕужЎМфЕФдМЪјЙиЯЕгУБпБэЪО(LiangЕШ,2013)ЁЃЭМНЈГЩКѓ,ЛљгкгХЛЏЕФЫуЗЈБЛгУРДНтОіБЛЩуЬхЕФзЫЪЦ,ЪЙЖЅЕуЩЯвЊгХЛЏЕФзДЬЌИќКУЕиТњзуЯргІБпЩЯЕФдМЪјЁЃгХЛЏЫуЗЈжДааКѓ,ЯргІЕФЭМОЭЪЧжїЬхЕФдЫЖЏЙьМЃКЭЛЗОГЭМЁЃФПЧА,ДѓЖрЪ§жїСїЕФЪгОѕSLAMЯЕЭГЪЙгУЗЧЯпадгХЛЏЗНЗЈЁЃ
ЁА2.4. Loop closingЁБ
БеЛЗЕФШЮЮёЪЧШУЯЕЭГИљОнДЋИаЦїаХЯЂЪЖБ№ЕБЧАГЁОА,ВЂдкЗЕЛидЕиЪБШЗЖЈИУЧјгђвбОБЛЗУЮЪЙ§,вВОЭЪЧЯћГ§SLAMЯЕЭГЕФРлЛ§ЮѓВю(Newman and Ho, 2005)ЁЃЖдгкЪгОѕSLAMРДЫЕ,ДЋЭГЕФБеЛЗМьВтЗНЗЈжївЊВЩгУBag-of-Words(BoW)ФЃаЭ(Galvez-LoPez and Tardos, 2012),ЪЕЯжЕФВНжшЪЧ:
(i). еыЖдДгЭМЯёжаЬсШЁЕФОжВПЬиеї,ЭЈЙ§K-meansОлРрЙЙНЈвЛИіАќКЌKИіДЪЕФДЪБэЁЃ
(ii). ИљОнУПИіДЪЕФГіЯжДЮЪ§,НЋЭМЯёБэЪОЮЊвЛИіKЮЌЪ§зжЯђСПЁЃ
(iii). ХаЖЯГЁОАЕФВювь,ВЂЪЖБ№здЖЏМнЪЛЦћГЕЪЧЗёвбОЕНДяЫљЪЖБ№ЕФГЁОАЁЃ
ЁА2.5. MappingЁБ
зджїГЕСОЕФвЛИіЛљБОзщГЩВПЗжЪЧНЈСЂЛЗОГЕиЭМВЂдкЕиЭМЩЯЖЈЮЛЕФФмСІЁЃжЦЭМЪЧЪгОѕSLAMЯЕЭГ(МДЖЈЮЛКЭНЈЭМ)ЕФСНЯюШЮЮёжЎвЛ,ЫќдкзджїМнЪЛЕФЕМКНЁЂБмеЯКЭЛЗОГжиНЈЗНУцЗЂЛгзХживЊзїгУЁЃвЛАуРДЫЕ,ЕиЭМЕФБэЪОПЩвдЗжЮЊСНРр:ЙЋжЦЕиЭМКЭЭиЦЫЕиЭМЁЃЙЋжЦЕиЭМУшЪіЕФЪЧЕиЭМдЊЫижЎМфЕФЯрЖдЮЛжУЙиЯЕ,ЖјЭиЦЫЕиЭМЧПЕїЕФЪЧЕиЭМдЊЫижЎМфЕФСЌНгЙиЯЕЁЃЖдгкОЕфЕФSLAMЯЕЭГ,ЙЋжЦЕиЭМПЩвдНјвЛВНЗжЮЊЯЁЪшЕиЭМКЭУмМЏЕиЭМ,ЯЁЪшЕиЭМжЛАќКЌГЁОАжаЕФЩйСПаХЯЂ,ЪЪгУгкЖЈЮЛ,ЖјУмМЏЕиЭМАќКЌИќЖрЕФаХЯЂ,гаРћгкГЕСОИљОнЕиЭМжДааЕМКНШЮЮёЁЃ
ЁА3. State-of-the-art studiesЁБ
ЁА3.1. Visual SLAM
гыЕк2.2НкжаУшЪіЕФVOзгЯЕЭГРрЫЦ,ИљОнРћгУЭМЯёаХЯЂЕФЗНЗЈ,ДПЪгОѕSLAMЯЕЭГПЩвдЗжЮЊСНРр:ЛљгкЬиеїЕФЗНЗЈКЭжБНгЗНЗЈЁЃЛљгкЬиеїЕФЗНЗЈЪЧжИЖдЯрСкжЁжЎМфЕФЩуЯёЛњдЫЖЏНјааЙРМЦ,ВЂЭЈЙ§ЬсШЁКЭЦЅХфЬиеїЕуЙЙНЈЛЗОГЭМЁЃетжжЗНЗЈЕФШБЕуЪЧашвЊКмГЄЕФЪБМфРДЬсШЁЬиеїЕуКЭМЦЫуУшЪіЗћЁЃвђДЫ,вЛаЉбаОПепНЈвщЗХЦњЖдЙиМќЕуКЭУшЪіЗћЕФМЦЫу,ФЧУДжБНгЗЈОЭгІдЫЖјЩњ(ZouЕШШЫ,2020)ЁЃДЫЭт,ИљОнДЋИаЦїЕФРраЭ,ЪгОѕSLAMПЩвдЗжЮЊЕЅблЁЂЫЋблЁЂRGB-DКЭЛљгкЪТМўЯрЛњЕФЗНЗЈЁЃИљОнЕиЭМЕФУмЖШ,ПЩвдЗжЮЊЯЁЪшЁЂУмМЏКЭАыУмМЏЕФSLAM,ЫќУЧЕФНщЩмШчЯТЁЃ
ЁА3.1.1. Feature-based methodЁБЛљгкЬиеї
2007Фъ,DavisonЕШШЫ(2007)ЬсГіСЫЕквЛИіЪЕЪБЕЅблЪгОѕSLAMЯЕЭГ,Mono-SLAMЁЃЭМ3(a)жаЯдЪОСЫЪЕЪБЬиеїФЃПщЗНЯђЙРМЦЕФНсЙћЁЃдкКѓЖЫЪЙгУEKFЫуЗЈРДИњзйДгЧАЖЫЛёЕУЕФЯЁЪшЬиеїЕу,ВЂЪЙгУЯрЛњЮЛзЫКЭЕиБъЕуЗНЯђзїЮЊзДЬЌСПРДИќаТЦфЦНОљжЕКЭаЗНВюЁЃЭЌФъ,KleinКЭMurray(2007)ЬсГіСЫвЛИіВЂааЕФИњзйКЭЛцЭМЯЕЭГ,PTAMЁЃЫќЪЕЯжСЫИњзйКЭжЦЭМЙЄзїЕФВЂааЛЏЁЃЭМ3(b)ЯдЪОСЫЬиеїЬсШЁКЭНЈЭМЕФЙ§ГЬ,ЫќЪзДЮЧјЗжСЫЧАЖЫКЭКѓЖЫ,ВЂЭЈЙ§ЗЧЯпадгХЛЏЗНЗЈ,ЬсГіСЫЙиМќжЁЛњжЦЁЃЙиМќЭМЯёБЛДЎСЊЦ№РДвдгХЛЏдЫЖЏЙьМЃКЭЬиеїЗНЯђЁЃЫцКѓЕФаэЖрЪгОѕSLAMЯЕЭГЩшМЦвВЖМВЩгУСЫРрЫЦЕФЗНЗЈЁЃ2015Фъ,Mur-ArtalЕШШЫ(2015)ЬсГіСЫORB-SLAM,етЪЧвЛжжЯрЖдЭъећЕФЛљгкЙиМќжЁЕФЕЅблSLAMЗНЗЈЁЃгыPTAMЕФЫЋЯпГЬЛњжЦЯрБШ,ИУЗНЗЈНЋећИіЯЕЭГЛЎЗжЮЊШ§ИіЯпГЬ:ИњзйЁЂНЈЭМКЭБеЛЗМьВтЁЃашвЊзЂвтЕФЪЧ,ЬиеїЬсШЁКЭЦЅХф(зѓРИ)ЁЂЕиЭМЙЙНЈКЭбЛЗМьВтЕФЙ§ГЬЖМЪЧЛљгкORBЬиеї(гвРИ)ЁЃЭМ3(c)ЪЧЕЅФПЩуЯёЭЗдкИпаЃЕРТЗЛЗОГЯТЕФЪЕЪБЬиеїЬсШЁЙ§ГЬ(зѓРИ)КЭЙьМЃИњзйгыНЈЭМНсЙћ(гвРИ)ЁЃ2017Фъ,Mur-ArtalЕШШЫЬсГіСЫORB-SLAM2(Murartal and Tardos, 2017)ЕФКѓајАцБО,ЫќжЇГжбЛЗМьВтКЭжиЖЈЮЛ,ОпгаЪЕЪБЕиЭМжигУЕФЙІФм,ДЫЭтИФНјКѓЕФПђМмЛЙПЊЗХСЫЫЋФПЯрЛњКЭRGB-DЯрЛњЕФНгПкЁЃЭМ3(d)ЕФзѓСаЯдЪОСЫORB-SLAM2ЕФЫЋблЙьМЃЙРМЦКЭЬиеїЬсШЁЁЃЭМ3(d)ЕФгвСаЯдЪОСЫЪвФкГЁОАжаRGB-DЯрЛњЕФЙиМќжЁКЭУмМЏЕудЦгГЩфаЇЙћЁЃЭМжаСЌајЕФТЬЩЋаЁЗНПщЙЙГЩСЫЙиМќжЁЕФЙьМЃ,ЖјRGB-DЯрЛњЙЙНЈЕФУмМЏ3DГЁОАЕиЭМдђЮЇШЦзХЫќЁЃ
ЁА3.1.2. Direct based methodЁБжБНгЗЈ
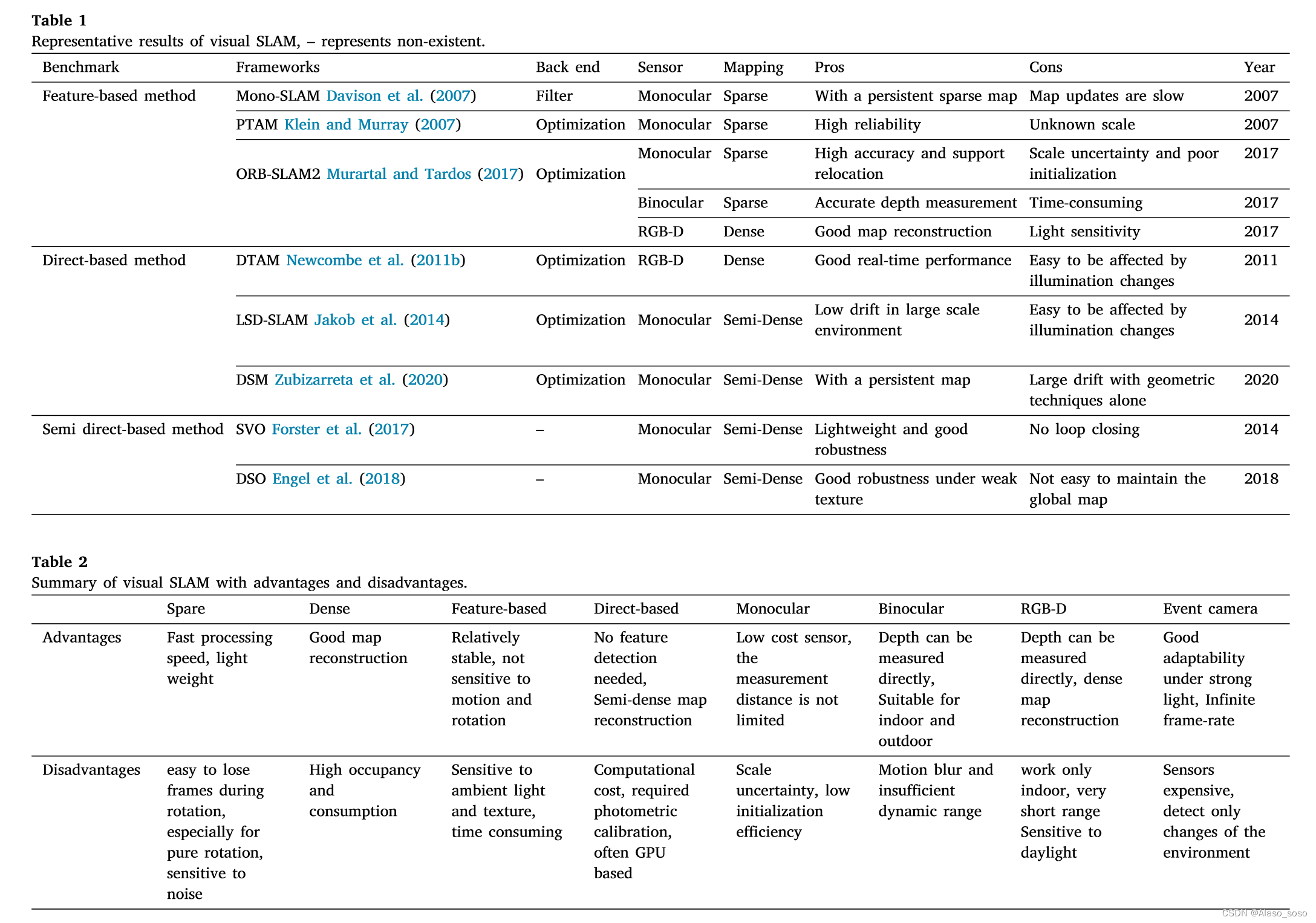
2011Фъ,NewcombeЕШШЫ(2011b)ЬсГіСЫвЛИіЛљгкжБНгЗНЗЈЕФЕЅблSLAMПђМм,МДDTAMЁЃгыЛљгкЬиеїЕФЗНЗЈВЛЭЌ,DTAMВЩгУСЫЛљгкЗДЩюЖШЕФЗНЗЈРДЙРМЦЬиеїЕФЩюЖШЁЃЭЈЙ§жБНгЕФЭМЯёЦЅХфМЦЫуЩуЯёЛњЮЛзЫ,ВЂЭЈЙ§ЛљгкгХЛЏЕФЗНЗЈЙЙНЈУмМЏЭМ(ЭМ4(a))ЁЃ2014Фъ,JakobЕШШЫ(2014)ЬсГіСЫLSD-SLAM(ЭМ4(b)),етЪЧжБНгЗЈдкЕЅблЪгОѕSLAMПђМмжаЕФвЛИіГЩЙІгІгУЁЃИУЗНЗЈНЋУцЯђЯёЫиЕФЗНЗЈгІгУгкАыУмМЏЕФЕЅблSLAMЯЕЭГЁЃгыЛљгкЬиеїЕФЗНЗЈЯрБШ,LSD-SLAMЕФУєИаЖШНЯЕЭ,ЕЋЕБЯрЛњЕФФкВПВЮЪ§КЭееЖШЗЂЩњБфЛЏЪБ,ИУЯЕЭГЪЧДрШѕЕФЁЃ2017Фъ,ForsterЕШШЫ(2017)ЬсГіСЫSVO(Semi-direct Visual Odometry)ЁЃЫќЪЙгУЯЁЪшжБНгЗЈ(вВГЦЮЊАыжБНгЗЈ)РДИњзйЙиМќЕу(ЭМ4(c)ЕФЕзВП),ВЂИљОнЙиМќЕужмЮЇЕФаХЯЂРДЙРМЦзЫЪЦЁЃЭМ4(c)ЕФЖЅВПЯдЪОСЫЪвФкЛЗОГжаЕФЯЁЪшЕиЭМЕФЙьМЃЁЃгЩгкВЩгУАыжБНгЗНЗЈИњзйЯЁЪшЬиеї,МШВЛМЦЫуУшЪіЗћ,вВВЛДІРэУмМЏаХЯЂ,SVOЕФЪБМфИДдгЖШЕЭ,ЪЕЪБадЧПЁЃ2016Фъ,EngelЕШШЫ(2018)ЬсГіСЫDSO,ЫќвВВЩгУСЫАыжБНгЗЈ,вдИќПьЕФдЫааЫйЖШБЃжЄИќИпЕФОЋЖШЁЃШЛЖј,е§ШчЕк2.1НкжаЬсЕНЕФ,ЫћУЧжЛЪЧЪгОѕВтОрЁЃгЩгкШБЗІКѓЖЫгХЛЏФЃПщКЭБеЛЗФЃПщ,ЯЕЭГЕФИњзйЮѓВюНЋЫцзХЪБМфЕФЭЦвЦЖјРлЛ§ЁЃЭМ4(d)ЯдЪОСЫDSO(ЕЅблЪгОѕРяГЬБэ)ЕФШ§ЮЌжиНЈКЭИњзйЕФаЇЙћЁЃжБНгЗЈОпгаМЦЫуЫйЖШПьКЭЖдШѕЬиеїЬѕМўВЛУєИаЕФгХЕуЁЃШЛЖј,ЫќЪЧЛљгкЛвЖШЕШМЖВЛБфЕФЧПСвМйЩш,ЫљвдЫќЖдееЖШЕФБфЛЏЗЧГЃУєИаЁЃЯрЗД,ЬиеїЕуЗНЗЈОпгаСМКУЕФВЛБфадЬиеїЁЃ2020Фъ,ZubizarretaЕШШЫ(2020)ЬсГіСЫвЛжжжБНгЯЁЪшгГЩфЗНЗЈ,МДDSM,ЫќЪЧвЛжжЛљгкЙтЖШЪјЕїећ(PBA)ЫуЗЈЕФШЋЕЅблЪгОѕSLAMЯЕЭГЁЃдкEuRoCЪ§ОнМЏ(V1_03_РЇФбађСа)ЩЯВтЪдЕФЖЈадР§згМћЭМ4(e)ЁЃЪТЪЕжЄУї,ЫќМШФмМѕЩйЙРМЦЙьМЃКЭЕиЭМЮѓВю,ЭЌЪБгжФмБмУтВЛвЛжТЕФЕиЭМЕужиИДЁЃБэ1змНсСЫзюЯШНјЕФЪгОѕSLAMПђМмЕФжївЊЬиеїКЭгХЕугыШБЕуЁЃГ§ЩЯЪіЕфаЭПђМмЭт,ЛЙгаЦфЫћЯрЙиЙЄзїЕФбаОП,
Шч:
(1). ЯЁЪшЪгОѕSLAM:CubemapSLAM,ProSLAM,ENFT-SLAM,OpenVSLAM,TagSLAM,UcoSLAM
(ii). АыУмМЏЪгОѕSLAM:CNN-SVO,EVO(ЛљгкЪТМўЯрЛњ)ЁЃ
(iii). УмМЏЪгОѕSLAM:MLM-SLAM,KinectШкКЯ,DVO,RGBD-SLAM(v2),RTB-MAP,ЖЏЬЌШкКЯЁЂЬхЛ§БфаЮЁЂЕЏадШкКЯЁЂInfini TAMЁЂРІАѓШкКЯЁЂKO-ШкКЯЁЂSOFTSLAM
ЦфЫћЙЄзїПЩвдСаОйШчЯТ,ЕЋВЛЯогкRKD-SLAMКЭRGB-D SLAM ЁЃMaplabЁЂPointNVSNet(XuЕШШЫ,2019)ЁЂMID-FusionКЭMaskFusion
ПЩвдПДГі,дкЪгОѕSLAMСьгђгаКмЖрГЩОЭ,ЮвУЧжЛЪЧЬсЙЉСЫвЛИіСїааЗНЗЈЕФЛиЙЫЁЃМДЪЙЪгОѕSLAMЬсЙЉСЫСМКУЕФЖЈЮЛКЭНЈЭМНсЙћ,етаЉНтОіЗНАИЖМгагХЕуКЭШБЕуЁЃдкетЯюЙЄзїжа,"ЛљгкЯЁЪшЕФЗНЗЈ"ЁЂ"ЛљгкУмМЏЕФЗНЗЈ"ЁЂ"ЛљгкЬиеїЕФЗНЗЈ"ЁЂ"ЛљгкжБНгЕФЗНЗЈ"ЁЂ"ЕЅблЗНЗЈ "''ЫЋблЗЈ''ЁЂ''RGB-DЗЈ''КЭ''ЪТМўЯрЛњЗЈЁЃ''ЕФгХЕуКЭШБЕуБЛзмНсГіРДЁЃЫќПЩвддкБэ2жаевЕНЁЃЪгОѕSLAMЕФШЗЖЈдкММЪѕЩЯОпгаЬєеНадЁЃЕЅблЪгОѕSLAMДцдкГпЖШФЃК§ЁЂБивЊЕФГѕЪМЛЏКЭГпЖШЦЏвЦЕШЮЪЬт(StrasdatЕШШЫ,2010)ЁЃОЁЙмСЂЬхЯрЛњКЭRGB-DЯрЛњПЩвдНтОіГпЖШКЭГѕЪМЛЏЕФЮЪЬт,ЕЋвЛаЉеЯАЪЧВЛШнКіЪгЕФ,ШчПьЫйдЫЖЏЁЂДѓМЦЫуЁЂаЁЪгГЁЁЂекЕВЁЂЖЏЬЌГЁОАЁЂЬиеїЫ№ЪЇКЭЙтЯпБфЛЏЁЃетаЉЮЪЬтЯожЦСЫЪгОѕSLAMдкздЖЏМнЪЛСьгђЕФгІгУЁЃФПЧА,аэЖрбаОПШЫдБЪдЭМНЋВЛЭЌЕФДЋИаЦїМЏГЩЕНVSLAMЯЕЭГжаНјаагІгУЁЃЕфаЭЕФЖрДЋИаЦїШкКЯЗНЗЈЪЧЪгОѕ-ЙпадЁЂЪгОѕ-МЄЙтРзДя(Yang,2019;MaЕШШЫ,2019)ЁЂЪгОѕ-МЄЙтРзДя-IMU(GuillnЕШШЫ,2017;ZhangЕШШЫ,2019)ЁЃ
ЁА3.2. Visual-inertial SLAMЪгОѕЙпадslamЁБ
IMUДЋИаЦїПЩвдЬсЙЉвЛИіКмКУЕФНтОіЗНАИ,вдНтОіЩуЯёЛњвЦЖЏЕНОпгаЬєеНадЕФЛЗОГ(ЮЦРэКЭ/ЛђЙтЯпБфЛЏНЯЩй)ЪБИњзйЪЇАмЕФЮЪЬт,СэвЛЗНУц,ЪгОѕДЋИаЦїПЩвдУжВЙIMUЕФРлЛ§ЦЏвЦЁЃетбљЕФЪгОѕКЭIMUЕФзщКЯБЛГЦЮЊЛЦН№ДюЕЕЁЃгЩгкЩуЯёЭЗКЭIMUЕФЙІФмЛЅВЙ,дкЮоШЫМнЪЛЕШСьгђгаКмКУЕФЗЂеЙЧАОА(Sun and Tian, 2019)ЁЃVI-SLAMЕФжївЊЗНЗЈЪЧНЋIMUаХЯЂНсКЯЕНЪгОѕSLAMЯЕЭГЕФЧАЖЫ,етвВБЛГЦЮЊЪгОѕ-ЙпадВтОр(VIO)ЯЕЭГЁЃвЛАуРДЫЕ,VI-SLAMЯЕЭГПЩвдЗжЮЊСНРр:ЛљгкЙ§ТЫЦїЕФЗНЗЈКЭЛљгкгХЛЏЕФЗНЗЈЁЃ
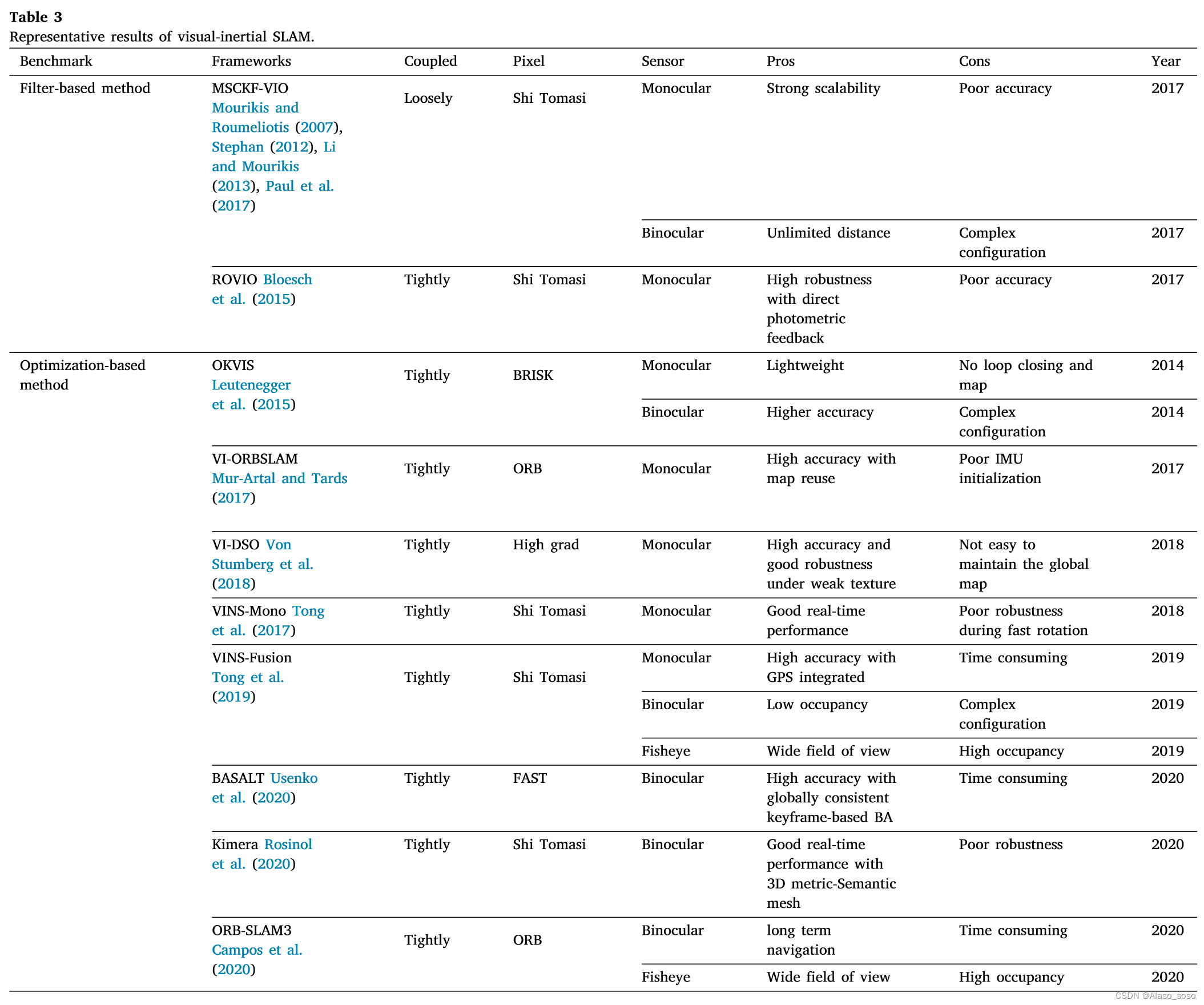
3.2.1. ЛљгкЬиеїЕФЗНЗЈ
2007Фъ,MourikisКЭRoumeliotis(2007)ЬсГіСЫЖрзДЬЌдМЪјПЈЖћТќТЫВЈ(MSCKF),ЫќЪЧзюдчЕФЛљгкРЉеЙПЈЖћТќТЫВЈ(EKF)ЫуЗЈЕФжЊУћЕФЪгОѕ-ЙпадSLAMЯЕЭГЁЃгыДПЪгОѕВтОрЯрБШ,MSCKF(ЭМ5(a))ПЩвддквЛЖЈЪБМфФкЪЪгІИќОчСвЕФдЫЖЏКЭЮЦРэЫ№ЪЇ,ОпгаИќИпЕФТГАєадЁЃ2012Фъ,Stephan(2012)ЬсГіСЫSSF(ЭМ5(b)),ЫќЪЧвЛИіЛљгкЫЩЩЂёюКЯЗНЗЈЕФEKFЕФЪБМфбгГйВЙГЅЕФЕЅДЋИаЦїКЭЖрДЋИаЦїШкКЯПђМмЁЃ2013Фъ,LiКЭMourikis(2013)жИГіСЫMSCKFдкзДЬЌЙРМЦЙ§ГЬжаЕФВЛвЛжТадЁЃ2017Фъ,PaulЕШШЫ(2017)ЬсГіСЫMSCKF2.0,ЦфзМШЗадЁЂвЛжТадКЭМЦЫуаЇТЪЖМгаСЫКмДѓЕФЬсИпЁЃДЫЭт,ROVIO(Robust Visual Inertial Odometry)(BloeschЕШШЫ,2015)(ЭМ5(c))КЭMSCKF-VIO(KeЕШШЫ)(ЭМ5(d))вВЪЧНќФъРДЛљгкТЫВЈЗНЗЈЕФгХаузїЦЗЁЃ
3.2.2. ЛљгкгХЛЏЕФЗНЗЈ
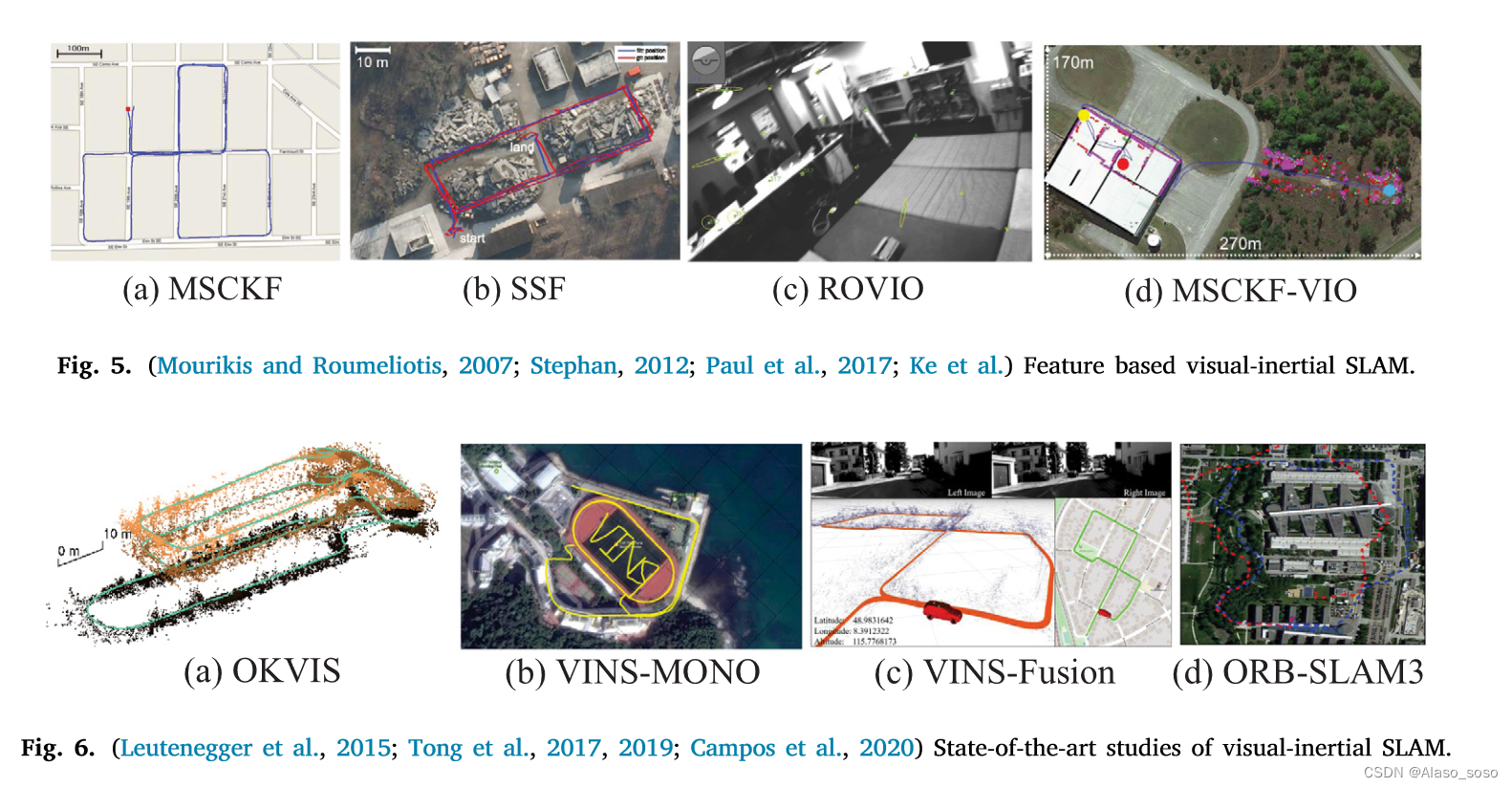
дкЛљгкгХЛЏЕФVI-SLAMЯЕЭГЗНУц,зюОЕфЕФПђМмЪЧOKVIS(Open Keyframe-based Visual-Inertial SLAM)(LeuteneggerЕШ,2015)(ЭМ6(a))КЭVINS-Mono,106(ЭМ6(b))ЁЃ2015Фъ,LeuteneggeЕШШЫЬсГіСЫOKVIS,ЫќЪЙгУIMUВтСПжЕРДдЄВтЕБЧАзДЬЌЁЂПеМфЕуКЭЖўЮЌЭМЯёЬиеї,вдЙЙГЩжиЭЖгАЮѓВюЁЃдЄВтЕФIMUзДЬЌСПКЭгХЛЏЕФВЮЪ§ЙЙГЩIMUЮѓВюЯю,ШЛКѓНЋжиЭЖгАЮѓВюгыIMUЮѓВюЯюЯрНсКЯНјаагХЛЏЁЃ2017Фъ,TongЕШШЫ(2017)ЬсГіСЫVINS-Mono,ЫќБЛШЯЮЊЪЧвЛИігХауЕФЕЅблVI-SLAMЯЕЭГ,ЦфжаЧАЖЫВЩгУЙтСїЗНЗЈ,КѓЖЫВЩгУЛљгкЛЌЖЏДАЕФЗЧЯпадгХЛЏЫуЗЈ(ChengЕШШЫ,2021b)ЁЃДЫЭт,VINS-MonoЕФГѕЪМЛЏЗНЗЈжЕЕУзЂвт,ЫќВЩгУСЫdisjointЗНЗЈ(вдМАVI-ORBSLAM Mur-Artal and Tards, 2017),ЪзЯШГѕЪМЛЏДПЪгОѕзгЯЕЭГ,ШЛКѓЙРМЦIMU(МгЫйЖШМЦКЭЭгТнвЧ)ЕФЦЋВюЁЂжиСІЁЂПЬЖШКЭЫйЖШЁЃЭЈЙ§KITTIКЭEuRoCЪ§ОнМЏЕФВтЪд,VINS-MonoБЛжЄУїОпгагыOKVISЯрЕБЕФЖЈЮЛОЋЖШ,дкГѕЪМЛЏКЭБеЛЗНзЖЮИќМгЭъећКЭЮШНЁЁЃ2019Фъ,VINS-MonoЭХЖгЬсГіСЫЫЋФПАцБО,ВЂећКЯСЫGPSаХЯЂ,МДVINS-Fusion(TongЕШШЫ,2019)ЁЃШчЭМ6(c)ЫљЪО,гЩгкМгШыСЫGPSВтСП,дкЪвЭтЛЗОГжаШЁЕУСЫСМКУЕФЖЈЮЛКЭВтЛцаЇЙћ,вВБЛШЯЮЊдкздЖЏМнЪЛЦћГЕСьгђгаСМКУЕФгІгУЁЃ2020Фъ,CamposЕШШЫ(2020)ЬсГіСЫвЛИіЛљгкЬиеїЕФНєУмМЏГЩЕФЪгОѕ-ЙпадSLAMЯЕЭГ,ORB-SLAM3ЁЃЫќЪЧзюаТЕФГЩЙћ,ЭЈЙ§зюДѓКѓбщ(MAP)ЫуЗЈЪЕЯжСЫИќгааЇЕФГѕЪМЛЏЙ§ГЬ,ВЂЪЕЯжСЫЖрЭМЙІФм,ИУЙІФмвРРЕгквЛжжаТЕФЕиЕуЪЖБ№ЗНЗЈ,ВЂЬсИпСЫейЛиТЪЁЃДЫЭт,ИУЯЕЭГФмЙЛгУЕЅблЁЂЫЋблКЭRGB-DЯрЛњжДааЪгОѕЁЂЪгОѕЙпадКЭЖрЕиЭМSLAMЁЃЛЇЭтГЁОАЕФЪЕбщНсЙћШчЭМ6(d)ЫљЪОЁЃORB-SLAM3ЕФЙмЕРгыORB-SLAM2ЯрЫЦ,ећИіЯЕЭГгЩШ§ИіЯпГЬзщГЩЁЃИњзйЁЂОжВПгГЩфКЭбЛЗЙиБе(МДбЛЗКЭЕиЭМКЯВЂ)ЯпГЬЁЃДЫЭт,ORB-SLAM3ПЩвддкЪгОѕаХЯЂВЛМбЕФЧщПіЯТГЄЦкДцЛю,ЕБЫќУдЪЇЪБ,ЫќЛсЦєЖЏвЛИіаТЕФЕиЭМ,дкжиЗУгГЩфЧјгђЪБНЋгыжЎЧАЕФЕиЭМЮоЗьКЯВЂЁЃБэ3змНсСЫНќФъРДЪгОѕ-ЙпадSLAMПђМмжаЕФжївЊЫуЗЈЁЃФПЧА,ЛљгкгХЛЏЕФVI-SLAMЗНЗЈвбОГЩЮЊжїСїЁЃГ§ЩЯЪіЗНЗЈЭт,ЛЙгаЦфЫћзюЯШНјЕФЙЄзїПЩвдзмНсШчЯТ,ЕЋВЛЯогкBASALTЁЂKimeraЁЂICE-BAЁЂMaplabЁЂStructVIOЁЃRKSLAMЁЃЛљгкЪТМўЯрЛњЕФVI-SLAMЯЕЭГПЩвдСаОйШчЯТ,ЕЋВЛЯогкДЫЁЃЛљгкЩюЖШбЇЯАЕФЗНЗЈПЩвддкJared ShamwellЕШШЫ(2019)жаПДЕН,ЫќеЙЪОСЫвЛИіЭјТч,дкУЛгаIMUФкдкВЮЪ§ЛђIMUКЭЯрЛњжЎМфЕФЭтдкаЃзМЕФЧщПіЯТжДааVIOЁЃЮФЯз(LeeЕШШЫ,2019)ЬсЙЉСЫвЛИіЭјТчРДБмУтЯрЛњКЭIMUДЋИаЦїжЎМфЕФаЃзМЁЃ
 ?КѓУцЪЧЪгОѕ-РзДя-imuНсКЯЕФslam,ОЭУЛгаСаГіРД,ИааЫШЄЕФПЩвдПДдТлЮФЁЃ
?КѓУцЪЧЪгОѕ-РзДя-imuНсКЯЕФslam,ОЭУЛгаСаГіРД,ИааЫШЄЕФПЩвдПДдТлЮФЁЃ
ЁА4. DiscussionsЁБ
ОЁЙмЪгОѕSLAMдкзджїМнЪЛГЕСОЕФЖЈЮЛКЭВтЛцЗНУцШЁЕУСЫОоДѓЕФГЩЙІ,ЕЋШчЧАЫљЪі,ЯжгаЕФММЪѕЛЙВЛЙЛГЩЪь,ЮоЗЈЭъШЋНтОіблЧАЕФЮЪЬтЁЃФПЧАЛљгкЪгОѕЕФЖЈЮЛКЭВтЛцНтОіЗНАИШдДІгкЦ№ВННзЖЮЁЃЮЊСЫТњзуИДдгГЧЪаЛЗОГжаЕФзджїМнЪЛвЊЧѓ,ЮДРДЕФбаОПШЫдБУцСйзХаэЖрЬєеНЁЃетаЉММЪѕЕФЪЕМЪгІгУгІБЛЪгЮЊвЛИіЯЕЭГЕФбаОПЮЪЬтЁЃДЫЭт,SLAMЯЕЭГжЛЪЧздЖЏМнЪЛЦћГЕИДдгЯЕЭГжаЕФвЛИізщГЩВПЗж,здЖЏМнЪЛЯЕЭГВЛФмЭъШЋвРРЕSLAMЯЕЭГ,ЛЙашвЊХфБИПижЦЁЂФПБъМьВтЁЂТЗОЖЙцЛЎЁЂОіВпЕШФЃПщЁЃдкетвЛНкжа,ЮвУЧЖдФПЧАздЖЏМнЪЛЦћГЕгІгУжаЕФЪгОѕКЭЛљгкЪгОѕЕФSLAMЕФЙиМќЮЪЬтвдМАЮДРДЕФЗЂеЙЧїЪЦзіСЫвЛаЉећЬхЕФЙлВьКЭЭЦТлЁЃдкетвЛНкжа,ЮвУЧЖдФПЧАзджїМнЪЛЦћГЕгІгУжаЕФЪгОѕКЭЛљгкЪгОѕЕФSLAMЕФЙиМќЮЪЬт,вдМАЮДРДЕФЗЂеЙЧїЪЦзіСЫвЛаЉЬжТлЁЃ
(a) ЪЕЪБадФмЁЃздЖЏМнЪЛГЕСОЕФгІгУвЊЧѓЪгОѕSLAMЯЕЭГОЁПЩФмПьЕизіГіЗДгІЁЃдкЪгОѕЫуЗЈЕФЧщПіЯТ,10КезШЕФЦЕТЪБЛШЯЮЊЪЧГЕСОдкГЧЪаЕРТЗЩЯЮЌГжзджїМнЪЛЕФзюаЁЦкЭћжЁТЪ(BojarskiЕШШЫ,2016)ЁЃвЛЗНУц,гавЛаЉЪгОѕЫуЗЈБЛЬсГіРДУїШЗгХЛЏЪЕЪБадФм(JaimezЕШШЫ,2017;HolzmannЕШШЫ,2016),СэвЛЗНУц,ЫќУЧПЩвдЭЈЙ§ОпгаИќИпЙцИёадФмЕФгВМўШчЭМаЮДІРэЕЅдЊ(GPU)РДНјвЛВНИФНјЁЃДЫЭт,ПМТЧЕНЯЕЭГЕФзМШЗадКЭТГАєад,гІИУПМТЧЕНИїжжЛЗОГЖЏЬЌ(ШчГЁОАБфЛЏЁЂвЦЖЏЕФеЯАЮяКЭЙтееВЛБфСП(AnЕШ,2017;KimКЭKim,2016;LiuЕШ,2017))ЁЃФПЧА,дкЬиЖЈЕФГЁОАЯТ,ЩуЯёЭЗзюЖргУгкЪЕЯжеЯАЮяМьВтЛђЙцБмвдМАзджїМнЪЛЕФГЕЕРБЃГж,ШчзджїДњПЭВДГЕ(APV)(LovegroveЕШШЫ,2011)ЁЃ
(b) ЖЈЮЛ:ГЧЪаЕРТЗГЁОАЕФздЖЏМнЪЛШдДІгкL2КЭL3ЕФММЪѕЙЅЙиНзЖЮ,ЦфжавЛИіЙиМќЮЪЬтЪЧГЕСОЕФЖЈЮЛОЋЖШБШНЯДжВкЁЃЮвУЧЙлВьЕН,ИпжЪСПЕФздЖЏМнЪЛРыВЛПЊОЋШЗЕФЮЛжУ,МДЪЙЪЧдкУЛгаЕиЭМЕФЛЗОГжа,ГЕСОвВвЊНјааЕМКН,ОЋШЗЕНРхУзМЖЁЃетжжОЋЖШНіППДЋЭГЕФGPSНгЪеЛњЪЧЮоЗЈЪЕЯжЕФ,ЦфОЋЖШдМЮЊ10Уз,ЭЈГЃашвЊАВзААКЙѓЕФВюЗжGPS(DGPS)НгЪеЛњРДЪЕЯж,ЕЋЫќв§ШыСЫШпгр,ЖјЪгОѕSLAMЫуЗЈБОЩэПЩвдБЛгУгкОЋШЗЖЈЮЛЁЃе§ШчБОЮФЫљЛиЙЫЕФ,баОПСЫЦфЫћЖРСЂгкGPSЕФЗНЗЈРДЪЕЯжЯрЖдЖЈЮЛ,ШчЪгОѕ-ЙпадШкКЯЗНЗЈ(Ек3.2Нк),ЪгОѕ-МЄЙтРзДяШкКЯЗНЗЈ(Ек3.3Нк),вдМАЪгОѕ-МЄЙтРзДя-IMUШкКЯЗНЗЈ(Ек3.4Нк)ЁЃОЭЪгОѕ-ЙпадШкКЯЗНЗЈЖјбд,Г§ЗЧIMUЪЧИпЖШОЋШЗЕФ,ЗёдђIMUв§ШыЕФЦЏвЦЮѓВюНЋжИЪ§МЖЕигАЯьОЋЖШЁЃОЭЪгОѕ-МЄЙтРзДяШкКЯЗНЗЈЖјбд,гЩгкШБЗІздЩэЕФЙпадЕМКН(DR)ДЋИаЦї(ШчБрТыКЭIMUДЋИаЦї),зджїМнЪЛГЕСОЕФЖЈЮЛЮШНЁадЕУВЛЕНБЃжЄЁЃдкЪгОѕ-МЄЙтРзДя-IMUШкКЯЗНЗЈЗНУц,ОнЮвУЧЫљжЊ,ФПЧАЛЙУЛгаГЩЪьЕФЛљгкЪгОѕЕФШкКЯSLAMЫуЗЈГЩЙІгІгУгкЯжЪЕЪРНчжаЕФзджїМнЪЛГЕСО,ЕЋзюНќМИФъгааэЖргХауЕФШкКЯЗНЗЈе§дкБЛбаОПЁЃЫцзХМЄЙтРзДяДЋИаЦїГЩБОЕФНЕЕЭ,ЮвУЧШЯЮЊЪгОѕ-МЄЙтРзДя-IMUШкКЯЗНЗЈЪЧзджїМнЪЛГЕСОИпОЋЖШЖЈЮЛЕФзюжеЗНАИЁЃ
(c) ВтЪд:ФПЧА,ЯжЪЕЪРНчЕФЪЕЪЉЪЧВЛГфЗжЕФ,етПЩвдЙщЙІгкЕиЗНСЂЗЈКЭШБЗІгУгкздЖЏМнЪЛВтЪдЕФПЊЗЂГЕСОЁЃдкетРя,ЮвУЧЙлВьЕНМИКѕЫљгазюНќЬсГіЕФЪгОѕSLAMзїЦЗЖМЪЧдкЙЋЙВЪ§ОнМЏ(ШчKITTIЁЂEuROCЁЂTUMЕШ)ЩЯВтЪдЕФЁЃГЯШЛ,етаЉЪ§ОнМЏЖдгкЫуЗЈЕФбщжЄЪЧКмКУЕФ,ЕЋЪЧетаЉЫуЗЈзюжедкецЪЕЪРНчЕФЛЗОГжаЛсгадѕбљЕФБэЯжЛЙгаД§бщжЄЁЃДЫЭт,дкетаЉЪ§ОнМЏЩЯЕФВтЪдвВНЋВтЪдЛЗОГЯожЦдкЪ§ОнМЏВЖЛёЕФЕиЗН,ЫќПЩФмВЛЪЧетаЉЫуЗЈдкЦфЫћЙњМвЛђГЧЪаЕФгааЇжИБъЁЃСэвЛИіШБЗІЯжЪЕЪРНчЪЕЪЉЕФдвђЫЦКѕЪЧгЩгкЪгОѕSLAMЫуЗЈЕФМЦЫувЊЧѓНЯИп,етБэУїдкЯпЪЕЪЉНЋашвЊвЛЬЈОпгазуЙЛКЭзЈгУЕФВЂааДІРэгВМўЕФМЦЫуЛњЁЃГЃМћЕФвЦЖЏМЦЫуЛњ,ШчБЪМЧБОЕчФд,ВЂВЛОпБИзРУцGPUЕФВЂааМЦЫуФмСІЁЃЩЬвЕЛЏЕФздЖЏМнЪЛМЦЫуЛњ,ШчNvidiaЕФDRIVE PX2(NVIDIAЙЋЫО,2017a)ЗЧГЃАКЙѓ,вЛАуРДЫЕ,дЄЫугаЯоЕФПЊЗЂЯюФПЮоЗЈИКЕЃЕУЦ№ЁЃСюШЫЙФЮшЕФЪЧ,зюНќГіЯжСЫИпадФмКЭЕЭГЩБОЕФЧЖШыЪНЩшБИ,ЦфЪгОѕЫуЗЈЕУЕНСЫИФНј,ШчNvidia Jetson(гЂЮАДяЙЋЫО,2017b)КЭПьЫйVO(МДЧАЖЫЛђЪгОѕSLAMЕФВПЗж)ЗНЗЈЕФгХЛЏ(JaimezЕШШЫ,2017;JaimezКЭGonzalez-Jimenez,2015;SteinbrckerЕШШЫ,2011;SunЕШШЫ,2018;ЮтЕШШЫ,2017)ПЩвдДпЛЏетаЉЪЕЯжЁЃ
(d)ЮДРДЕФЗЂеЙЧїЪЦЁЃгЩгкЪгОѕSLAMЕФИДдгФЃПщ(ШчЧАЖЫЁЂКѓЖЫЁЂБеЛЗКЭНЈЭМЕШ),діМгСЫгВМўЦНЬЈЕФМЦЫуИКЕЃ,ИпадФмвЦЖЏМЦЫуЦНЬЈЭљЭљЯожЦСЫЩЯЪіЪгОѕSLAMЫуЗЈдкзджїМнЪЛжаЕФгІгУЁЃЛљгкЖрДњРэЕФЪгОѕSLAMММЪѕЫЦКѕФмЙЛПЫЗўетвЛЮЪЬтЁЃФПЧА,ЛљгкЖрДњРэЕФЪгОѕSLAMЭЈГЃгУгкПежаЮоШЫЛњ,ШчЙћНЋЦфАВзАдкзджїГЕСОЩЯНјаавЦЖЏМЦЫу,вЦЖЏМЦЫуЛњЦНЬЈжЛИКд№ДІРэЧАЖЫЪ§Он,ЖјКѓЖЫгХЛЏКЭгГЩфЕФЙ§ГЬдђгЩдЖГЬЗўЮёЦїЭЈЙ§5G/6GЭЈаХЭјТчДЋЪфЪ§ОнРДНтОі,ЮвУЧЯраХетНЋДѓДѓМгПьЪгОѕSLAMдкЮДРДзджїМнЪЛГЕСОЩЯЕФгІгУЁЃ
5. НсТл
зюНќЕФбаОПЖдНтОіЪгОѕSLAMЕФЮЪЬтгаКмДѓЕФЙБЯзЁЃетЯюЙЄзїЛиЙЫСЫИїжжРраЭЕФЪгОѕSLAMКЭ/ЛђЛљгкЪгОѕЕФSLAMЗНЗЈ,вдМАЫќУЧдкздЖЏМнЪЛжаЕФгІгУЁЃФПЧА,ЪгОѕSLAMдкздЖЏМнЪЛЦћГЕжаЕФгІгУБЛШЯЮЊЪЧВЛГЩЪьЕФ,ЕЋетШдШЛв§Ц№СЫЙуЗКЕФЙизЂЁЃгЩгкзджїМнЪЛЕФЙЋЙВЪ§ОнМЏШнвзЛёЕУ,ЪгОѕSLAMЫуЗЈзмЪЧШнвзБЛбщжЄ,аТЫуЗЈЕФбаОПвВБЛЙФРјЁЃШЛЖј,ОЁЙмЪ§ОнМЏЕФПЩгУадДйНјСЫаТЕФЪгОѕSLAMЫуЗЈЕФЬсГі,ЕЋФПЧАдкГЧЪаЕРТЗЛЗОГжаЕФецЪЕЪРНчЪгОѕSLAMгІгУШдШЛДцдкВЛзуЁЃДЫЭт,Ъ§ОнМЏЕФЦРЙРНсЙћЭљЭљЦЋРыСЫЕБЕиецЪЕЛЗОГжаадФмЕФЭъећжИЪО,вђДЫвЛИіЪЕгУЕФЪгОѕSLAMгаЭћдкздЖЏМнЪЛЦћГЕЕФгІгУжаГіЯжЁЃЭЈЙ§ЛиЙЫзюЯШНјЕФЪгОѕSLAMЫуЗЈ,ПЩвдШЗШЯФПЧАЪгОѕSLAMЯЕЭГЕФЗЂеЙЧїЪЦЪЧЧїЯђгкЧсСПМЖКЭЖрДњРэКЯзї,ЙФРјгІгУгкЧЖШыЪНЩшБИЕШЕЭЙІТЪгВМў,ЖјЖрДЋИаЦїШкКЯЫуЗЈБЛШЯЮЊЪЧЪгОѕSLAMдкздЖЏМнЪЛЦћГЕжагІгУЕФКЫаФЁЃзлЩЯЫљЪі,зджїМнЪЛСьгђШдШЛДцдкИїжжЮЪЬт,гШЦфЪЧЪгОѕSLAMКЭзджїМнЪЛЦћГЕЕФНсКЯашвЊЬНЫїЁЃШЛЖј,ЙЋжкЖдздЖЏМнЪЛЦћГЕЕФШЯПЩЖШдНРДдНИп,ЖјИпадФмвЦЖЏМЦЫуЛњЕФГіЯжЮовЩЛсдкВЛОУЕФНЋРДМЄЗЂЪгОѕSLAMЕФЪЕМЪгІгУЁЃ
ЮФеТСДНг:
 https://reader.elsevier.com/reader/sd/pii/S0952197622001853?token=E53610F0BCFD8EF8FA5D6121585F3CB04CA0EEE3D62FF04769C12D5164AFB8C373D18BDD768347A3A6C5924ED1BF4292&originRegion=us-east-1&originCreation=20220625125045
https://reader.elsevier.com/reader/sd/pii/S0952197622001853?token=E53610F0BCFD8EF8FA5D6121585F3CB04CA0EEE3D62FF04769C12D5164AFB8C373D18BDD768347A3A6C5924ED1BF4292&originRegion=us-east-1&originCreation=20220625125045