文章目录
Concealed Object Detection
伪装目标检测
原论文下载地址:https://arxiv.org/pdf/2102.10274.pdf
Abstract
我们首次对隐藏目标检测(COD)进行了系统研究,旨在识别视觉上嵌入在背景中的目标。隐藏对象与其背景之间的高度内在相似性使得COD比传统的对象检测/分割更具挑战性。为了更好地理解这项任务,我们收集了一个称为COD10K的大规模数据集,该数据集由10000幅图像组成,涵盖了78个对象类别中各种真实场景中的隐藏对象。此外,我们还提供了丰富的注释,包括对象类别、对象边界、挑战性属性、对象级标签和实例级注释。我们的COD10K是迄今为止最大的COD数据集,具有最丰富的注释,能够全面理解隐藏对象,甚至可以用于帮助完成其他一些视觉任务,如检测、分割、分类等。基于动物在野外狩猎的动机,我们还为COD设计了一个简单但强大的baseline,称为搜索识别网络(SINet)。SINet在所有测试数据集上的表现都超过了12条最前沿的baselines,这使得它具有强大的通用架构,可以作为COD未来研究的催化剂。最后,我们提供了一些有趣的发现,并强调了一些潜在的应用和未来的方向。为了激发这一新领域的研究,我们的代码、数据集和在线演示可以在我们的项目页面上找到 http://mmcheng.net/cod.
1 Introduction
你能在10秒内在图1的每个图像中找到隐藏的物体吗?生物学家将其称为背景匹配伪装(background matching camouflage, BMC)[2],其中一个或多个物体试图调整其颜色,使其与周围环境“无缝”匹配,以避免被发现[3]。感觉生态学家发现,这种BMC策略通过欺骗观察者的视觉感知系统来起作用。当然,解决隐蔽目标检测(COD)需要大量的视觉感知知识。了解COD本身不仅具有科学价值,而且对于许多基础领域的应用也很重要,例如计算机视觉(例如,搜索和救援工作或稀有物种发现)、医学(例如,息肉分割[7]、肺部感染分割[8])、农业(例如,蝗虫检测以防止入侵)和艺术(例如,娱乐艺术[9])。

在图2中,我们给出了通用、显著和隐藏对象检测的示例。目标和非目标之间的高度内在相似性使得COD比传统的目标分割/检测更具挑战性【10】、【11】、【12】。尽管最近受到了越来越多的关注,但关于COD的研究仍然很少,主要是因为缺乏足够大的数据集和标准基准,如Pascal VOC【13】、ImageNet【14】、MS-COCO【15】、ADE20K【16】和DA VIS【17】

在本文中,我们首次利用深度学习对隐藏目标检测任务进行了全面的研究,从隐藏的角度为目标检测带来了新的视角。
1.1 Contributions
我们的主要贡献如下:
1)COD10K数据集。基于上述目标,我们仔细收集了大规模隐蔽目标检测数据集COD10K。我们的数据集包含10000幅图像,涵盖78个对象类别,如陆地、两栖动物、飞行、水生动物等。所有隐藏图像都用类别、边界框(bounding-box)、对象级别(object-level)和实例级别(instance-level)标签进行了分层注释(图3),有利于许多相关任务,如对象提议、定位、语义边缘检测、转移学习[21]、域自适应[22],等等。每个隐藏的图像都被赋予了挑战性的属性(例如,形状复杂度SC、不可定义的边界IB、遮挡SOC),这些属性是在现实世界和matting level标签中发现的(这需要~每幅图像60分钟)。这些高质量的标签有助于深入了解模型的性能。
2)COD框架。我们提出了一个简单而有效的框架,名为SINet(搜索识别网)。值得注意的是,SINet的总训练时间为4小时,在所有现有COD数据集上都达到了最新水平(SOTA),这表明它可以为隐蔽目标检测提供潜在的解决方案。我们的网络还产生了一些有趣的发现(例如,搜索和识别策略适用于COD),使各种潜在的应用更加可行。
3)COD基准(Benchmark)。根据收集的COD10K和之前的数据集【24】、【25】,我们对12条SOTA基线进行了严格评估,使我们的COD研究成为最大的COD研究。我们在两种情况下报告基线,即超类(super-class)和子类(sub-class)。我们还通过在线基准跟踪社区的进展(http://dpfan.net/camouflage/)。
4)下游应用程序。为了进一步支持该领域的研究,我们开发了一个在线演示(http://mc.nankai.edu.cn/cod),使其他研究人员能够轻松地测试他们的场景。此外,我们还展示了一些潜在的应用,如医学、制造业、农业、艺术等。
5)未来方向。基于提出的COD10K,我们还讨论了未来十个有希望的研究方向。我们发现,隐蔽目标检测问题远未得到解决,还有很大的改进空间。

本文在几个方面基于并扩展了我们的会议版本[1]。首先,我们对COD10K进行了更详细的分析,包括分类、统计、注释和解析。其次,我们通过引入邻居连接解码器(neighbor connection decoder,NCD)和组反转注意(group-reversal attention,GRA)来改进SINet模型的性能。第三,我们进行了大量的实验来验证我们的模型的有效性,并在我们的框架内为不同的模块提供了一些消融实验(ablation studies )。第四,我们提供了详尽的超类和子类基准测试,并就新的COD任务进行了更深入的讨论。最后,基于我们的基准测试结果,我们得出了一些重要的结论,并指出了隐藏对象排序、隐藏对象提取、隐藏目标实例分割(concealed object ranking, concealed object proposal, concealed instance segmentation)等未来的发展方向。
2 Related Work
在本节中,我们简要回顾了密切相关的工作。在[10]之后,我们大致将目标检测分为三类:一般、显著和隐藏目标检测(generic, salient, and concealed)。
**通用目标分割(Generic Object Segmentation ,GOS)**计算机视觉中最流行的方向之一是通用对象分割[5]、[26]、[27]、[28]。请注意,通用对象可以是突出的,也可以是隐藏的。隐藏对象可以看作是一般对象的困难情况。典型的GOS任务包括语义分割和全景分割(见图2 b)。
**显著目标检测(Salient Object Detection,SOD)**此任务旨在识别图像中最引人注目的对象,然后分割其像素级轮廓【29】、【30】、【31】。利用SOD技术的旗舰产品是华为的智能手机,它利用SOD技术来制作他们所谓的“AI自拍”。最近,秦等人将SOD算法应用于两个(接近)商业应用:AR COPY&PASTE和OBJECT CUT。这些应用程序已经引起了极大的关注(12K github stars),并具有重要的现实影响。尽管术语“显著”本质上与“隐藏”(standout vs. immersion)相反,但显著物体仍然可以为COD提供重要信息,例如,包含显著物体的图像可以用作负片样本。对SOD进行全面审查超出了本工作的范围。我们建议读者参考最近的调查和基准论文【11】、【34】、【35】、【36】,了解更多详细信息。我们的在线基准测试在 http://dpfan.net/socbenchmark/.
**伪装物体检测(Concealed Object Detection,COD)**对COD的研究在生物学和艺术领域有着悠久而丰富的历史,对提高我们的视觉感知知识有着巨大的影响。阿伯特・塞耶(AbbottThayer)[37]和休・科特(HughCott)[38]关于隐蔽动物的两项杰出研究仍然具有巨大影响力。读者可以参考Stevens等人的调查,了解有关这段历史的更多细节。本次提交后,还接受了一些并行工程【39】、【40】、【41】。
COD数据集。变色龙(CHAMELEON)[24]是一个未发布的数据集,只有76幅图像带有手动注释的对象级地面真实性(GTs)。这些图像是通过谷歌搜索引擎从互联网上以“隐藏的动物”为关键词收集的。另一个当代数据集是CAMO【25】,它有2.5K图像(2K用于训练,0.5K用于测试),涵盖八个类别。它有两个子数据集,CAMO和MS-COCO,每个子数据集包含1.25K图像。与现有数据集不同,COD1K的目标是提供一个更具挑战性、更高质量、注释更密集的数据集。COD10K是迄今为止最大的隐蔽目标检测数据集,包含10K图像(6K用于训练,4K用于测试)。详见表1。

伪装的类型。隐藏图像大致可以分为两类:含有天然伪装的图像和含有人工伪装的图像。动物(如昆虫、海马和头足类)使用自然伪装作为一种生存技能,以避免被捕食者识别。相反,人工伪装通常用于艺术设计/游戏中隐藏信息,出现在产品制造过程中(所谓的表面缺陷[42]、缺陷检测[43]、[44]),或出现在我们的日常生活中(例如,透明物体[45]、[46]、[47])
COD公式。与语义分割等类感知任务不同,隐藏对象检测是一项与类无关的任务。因此,COD的公式简单且易于定义。给定一幅图像,该任务需要一个隐藏对象检测算法为每个像素i分配一个标签 L a b e l i Label_i Labeli?∈ {0,1},其中 L a b e l i Label_i Labeli? 表示像素 i 的二进制值。0的标签被赋予不属于隐藏对象的像素,而1的标签表示像素被完全分配给隐藏对象。我们专注于对象级(object-level)隐藏对象检测,将隐藏实例检测(instance detection)留给我们未来的工作。
3 COD10K 数据集
新任务和数据集[16]、[48]、[49]的出现导致了计算机视觉各个领域的快速发展。例如,ImageNet[50]彻底改变了视觉识别中深度模型的使用。有鉴于此,我们研究和开发COD数据集的目标是:(1)从隐蔽的角度提供一个新的具有挑战性的目标检测任务,(2)促进几个新主题的研究,以及(3)激发新的想法。图1显示了COD10K的示例。我们将从三个关键方面提供COD10K的详细信息,包括图像采集、专业注释以及数据集功能和统计。
(数据集这块就不写了,有兴趣可以去看原论文)
3.1 图像采集
3.2 专业注释
3.3 数据集功能和统计信息
4 COD 框架
4.1 网络概述
图13示出了所提议的SINet(搜索识别网络)的整体隐藏对象检测框架。接下来,我们将解释我们的动机并介绍网络概述
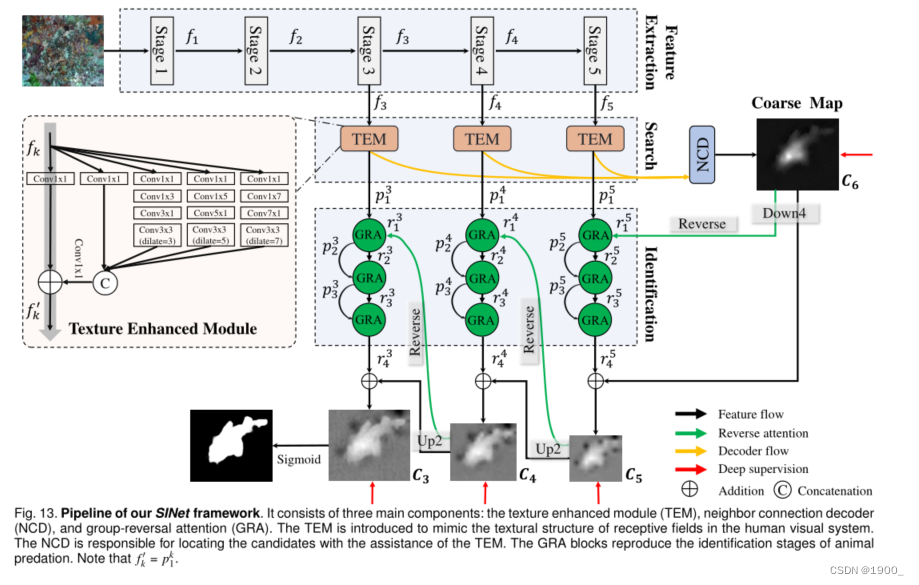
动机。生物学研究[58]表明,捕食者在捕猎时,首先会判断是否存在潜在的猎物,也就是说,它会寻找猎物。然后,可以识别目标动物;最后,它可以被抓住。
介绍。有几种方法【59】、【60】表明,令人满意的性能取决于重新优化策略(即从粗到细),该策略被视为多个子步骤的组合。这也表明,将复杂目标解耦可以打破性能瓶颈。我们的SINet模型包括狩猎的前两个阶段,即搜索和识别。具体而言,前一阶段(第4.2节)负责搜索隐藏对象,而后一阶段(第4.3节)则用于以级联方式精确检测隐藏对象。
接下来,我们详细介绍了三个主要模块的细节,包括
a)纹理增强模块(TEM),该模块用于捕获具有放大上下文线索的细粒度纹理;
b) 邻居连接解码器(NCD),能够提供位置信息;和
c)级联组反转注意(GRA)块,它们协同工作,从深层细化粗略预测。
4.2 搜索阶段
特征提取 对于输入图像(WxHx3,三通道图像)一组特征 { f k , k ∈ { 1 , 2 , 3 , 4 , 5 } 是 从 R e s 2 N e t ? 50 提 取 出 来 的 } \{f_k,k \in \{1,2,3,4,5\}是从Res2Net-50提取出来的\} {fk?,k∈{1,2,3,4,5}是从Res2Net?50提取出来的}(去掉了前三层,即“average pool”,“1000-d fc ”,“softmax”)。因此,每个特征 f k f_k fk?的分辨率是 H / 2 k × W / 2 k , k ∈ { 1 , 2 , 3 , 4 , 5 } H/2^k \times W/2^k,k \in \{1,2,3,4,5\} H/2k×W/2k,k∈{1,2,3,4,5},覆盖从高分辨率、弱语义到低分辨率、强语义的各种特征金字塔
纹理增强模块(TEM) 欧洲科学实验已经证实,在人类视觉系统中,一组不同大小的群体感受野有助于突出靠近视网膜中央凹的区域,该区域对小的空间位移非常敏感[62]。这促使我们在搜索阶段(通常在一个小的/局部空间中)使用TEM【63】来合并更多的区分性特征表示(discriminative feature representations)。如图13所示。
每个TEM由四个平行的残差分支(residual branches)组成 { b i , i = 1 , 2 , 3 , 4 } \{b_i,i=1,2,3,4\} {bi?,i=1,2,3,4},具有不同的膨胀率(dilation rates) d ∈ 1 , 3 , 5 , 7 d∈ {1,3,5,7} d∈1,3,5,7和一个快捷分支(灰色箭头)。在每个分支 b i b_i bi?中,第一卷积层利用1×1卷积运算(Conv1×1)将通道大小减少到32。
然后是其他两层: a ( 2 i ? 1 ) × ( 2 i ? 1 ) a(2i? 1) ×(2i? 1) a(2i?1)×(2i?1) 的卷积层和3×3卷积层(具有特定的膨胀率( 2 i ? 1 ?? w h e n ? i > 1 2i-1 \ \ when \ i > 1 2i?1??when?i>1 )。然后,将前四个分支 b i , 1 , 2 , 3 , 4 {b_i,1,2,3,4} bi?,1,2,3,4串联起来,并通过3×3卷积运算将通道大小减小到C。注意,我们在网络的默认设置了C=32(为了权衡trade-off时间成本)。最后,添加唯一快捷分支,然后将整个模块馈送到 R e L U ReLU ReLU函数,以获得输出特征 f k ′ f{_k}' fk?′。
此外,有几个工作(e.g Inception-V3[64])表明大小为 ( 2 i ? 1 ) × ( 2 i ? 1 ) (2i? 1) ×(2i? 1) (2i?1)×(2i?1)的标准卷积操作能够被分解为两个步骤,卷积核分别为 ( 2 i ? 1 ) × 1 (2i-1)\times 1 (2i?1)×1和 1 × ( 2 i ? 1 ) 1 \times(2i-1) 1×(2i?1)的两步,在不降低表示能力的情况下,提高了推理效率。所有这些想法都基于这样一个事实,即等级为1的2维kernel等价于一系列一维卷积[65]、[66]。简言之,与标准感受野块结构相比,TEM增加了一个具有更大扩张率(dilation rate)的分支,以扩大感受野,并进一步用两个不对称卷积层取代标准卷积。更多详情请参考图13。
邻居连接解码器 (NCD).
正如Wu等人【63】所观察到的,低级别特征由于其较大的空间分辨率而消耗更多的计算资源,但对性能的贡献较小。基于这一观察结果,我们决定只聚合前三个最高级别的特征,以获得更有效的学习能力,而不是将所有特征金字塔都考虑在内。具体来说,在从之前三个TEM中获得候选特征后,在搜索阶段,我们需要定位隐藏的对象。
然而,在聚合多个特征金字塔时,仍然存在两个关键问题;即,如何在一个层内保持语义一致性,以及如何跨层连接上下文。在这里,我们提出使用邻居连接解码器(neighbor connection decoder ,NCD)来解决这些问题。更具体地说,我们使用邻居连接函数修改了部分解码器组件(PDC)[63],得到了三个细化的特征 f k n c = F N C ( f k ′ ; W N C u ) , k ∈ { 3 , 4 , 5 } ? a n d ?? u ∈ { 1 , 2 , 3 } f_{k}^{nc}=F_{NC}(f_k';W_{NC}^{u}),k \in \{3,4,5\} \ and \ \ u \in \{1,2,3\} fknc?=FNC?(fk′?;WNCu?),k∈{3,4,5}?and??u∈{1,2,3},其公式如下:
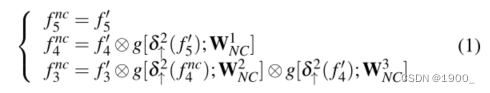
其中 g [ ? ; W N C u ] g[・;W_{NC}^{u}] g[?;WNCu?]表示一个3×3卷积层,然后是一个批量归一化操作。为了确保候选特征之间的形状匹配,我们使用上采样(例如,2次)操作 δ ↑ 2 \delta_{\uparrow}^{2} δ↑2?在元素相乘之前 ? \bigotimes ? ,然后我们将 f k n c , k ∈ { 3 , 4 , 5 } f_{k}^{nc},k \in \{3,4,5\} fknc?,k∈{3,4,5}喂进邻居连接解码器 (NCD)生成粗略位置图 C 6 C_6 C6?。
4.3识别阶段
反向制导Reverse Guidance 如第4.2节所述,我们的全局位置图 C 6 C_6 C6?源自三个最高层,这只能捕获隐藏对象的相对粗略位置,忽略结构和纹理细节(见图13)。为了解决这个问题,我们引入了一种原则性策略,通过擦除对象(erasing objects )来挖掘有区别的隐藏区域[7]、[67]、[68]。如图14(b)所示,我们通过sigmoid和反向操作获得输出反向制导 r 1 k r^k_1 r1k?。更准确地说,我们通过反向操作获得输出反向注意引导 r 1 k r^k_1 r1k?,其可表示为
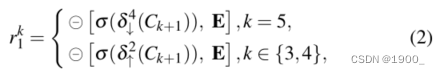
δ ↑ 2 \delta_{\uparrow}^{2} δ↑2?表示一个x2的上采样,同理,x4的下采样。 σ ( x ) = 1 / ( 1 + e ? x ) \sigma (x)= 1/ (1+e^{-x}) σ(x)=1/(1+e?x)是sigmoid函数,用于将掩码转换到区间[0,1]。圆圈中间一个减号,这个符号代表一个从矩阵E中减去输入的反向运算,其中所有元素均为1。
组引导操作Group Guidance Operation (GGO) 如[7]所示,反向注意通过从侧输出特征中删除现有的估计目标区域,用于挖掘互补区域和细节。受[69]的启发,我们提出了一种新的分组操作,以更有效地利用反向制导先验。如图14(a )所示,组引导操作包含两个主要步骤。首先,我们将候选特征 ? { p i k , i = 1 , 2 , 3 ? } \ \{p^k_i,i=1,2,3\ \} ?{pik?,i=1,2,3?}沿通道维度拆分为 g i g_i gi?组,然后,在分割特征 p i , j k ∈ R H / 2 k × C p^k_{i,j} \in R^{H/2^k\times C} pi,jk?∈RH/2k×C之间周期性地内插引导先验 r 1 k r^k_1 r1k?,其中 i ∈ { 1 , 2 , 3 } , j ∈ { 1 , … , g i } , k ∈ { 3 , 4 , 5 } . i∈ \{1,2,3\},j∈ \{1,…,g_i\},k∈ \{3,4,5\}. i∈{1,2,3},j∈{1,…,gi?},k∈{3,4,5}. 因此,此操作可分为两个步骤:
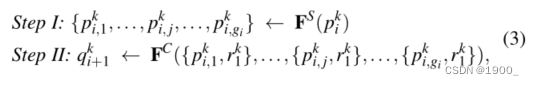
其中, F S F^S FS和 F C F^C FC表示候选通道的按通道拆分和级联函数。

相比之下,[7]更强调确保候选特征直接乘以先验值,这可能会引发两个问题:a)由于网络的辨别能力有限而导致特征混淆,以及b)简单的乘法引入了真制导先验值和假制导先验值,因此容易积累不准确度。与[7]相比,我们的GGO可以在后续的细化过程之前明确地隔离指导优先和候选特征。
Group-Reversal Attention组反转注意力 (GRA). 最后,我们介绍了一种称为GRA块的残差学习过程,该过程借助于反向引导和组引导操作。根据之前的研究【59】、【60】,多级细化可以提高性能。因此,我们组合了多个GRA块
(e.g, G i k 、 i ∈ { 1 , 2 , 3 } , k ∈ { 3 , 4 , 5 } G^k_i、i∈ \{1,2,3\},k∈ \{3,4,5\} Gik?、i∈{1,2,3},k∈{3,4,5}),通过不同的特征金字塔逐步细化粗预测。总的来说,每个GRA模块有三个残差学习过程:
i) 我们通过group guidance operation将候选特征 p i k p^k_i pik?和 r 1 k r^k_1 r1k?相结合,然后使用剩余阶段(residual stage)生成细化特征 p i + 1 k p^k_{i+1} pi+1k?。其公式如下
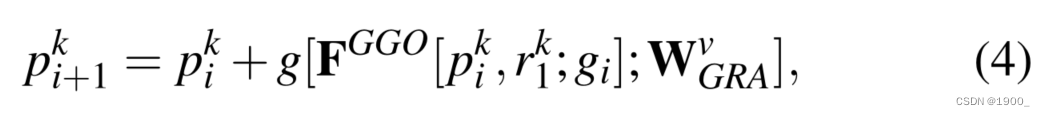
其中, W v W^v Wv表示卷积层,该卷积层具有 3 × 3 3×3 3×3内核,然后是批量归一化(batch normalization )层,用于将通道数从 C + g i C+g_i C+gi?减少到 C C C。请注意,在默认实现中,我们仅在第一个GRA块中(即,当i=1时)反转之前的guidance。有关详细讨论,请参阅第5.3节。
ii) 然后,我们得到单通道剩余制导(residual guidance):
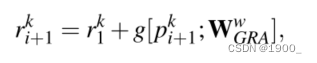
由可学习权重 W G R A w W^w_{GRA} WGRAw?参数化。
iii) 最后,我们只输出精制导,作为残差预测。其公式如下:
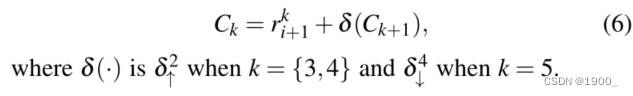
4.4 实现细节
4.4.1 学习策略
我们的loss函数定义为: L = L I o U W + L B C E W L = L^W_{IoU}+L^W_{BCE} L=LIoUW?+LBCEW?,其中, L I o U W L^W_{IoU} LIoUW?和 L B C E W L^W_{BCE} LBCEW?表示全局限制和局部(像素级)限制的联合(IoU)损失和二进制交叉熵(BCE)损失的加权交集。与分割任务中广泛采用的标准IoU损失不同,加权IoU损失增加了硬像素(hard pixels)的权重以突出其重要性。此外,与标准BCE损耗相比, L B C E W L^W_{BCE} LBCEW?更关注硬像素,而不是赋予所有像素相等的权重。这些损失的定义与【59】、【70】中的定义相同,其有效性已在显著目标检测领域得到验证。在这里,我们对三方输出(即 C 3 C_3 C3?、 C 4 C_4 C4?和 C 5 C_5 C5?)和全局映射 C 6 C_6 C6?采用深度监控。将每个地图上采样(例如, C 3 u p C^{up}_3 C3up?)至与ground-truth map G相同的大小。因此,拟定SINet的总损失可表示为:
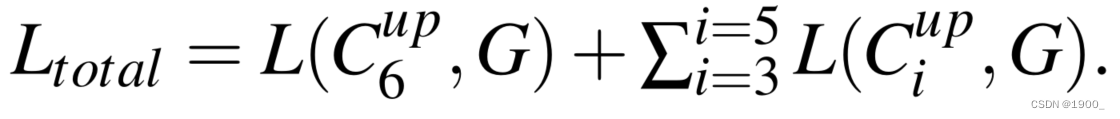
4.4.2 超参数设置
SINet在PyTorch中实现,并使用Adam optimizer进行训练【71】。在训练阶段,batch size设置为36,学习速率从 1 e ? 4 1e-4 1e?4开始,每50个epoch除以10。整个训练时间只有大约4小时,共100个epoch。运行时间在Intelr i9-9820X CPU@3.30GHz×20平台和单个NVIDIA TITAN RTX GPU上测量。在推理过程中,每个图像的大小被调整为352×352,然后输入到建议的管道中,以获得最终预测,而无需任何后处理技术。推理速度为在单个GPU上每秒~45帧,无需输入/输出时间。PyTorch和Jittor对源代码的验证都将公开提供。
5 COD BENCHMARK
5.1 实验设置
5.1.1 评估指标
平均绝对误差(MAE)广泛应用于SOD任务中。继Perazzi等人【83】之后,我们还采用MAE(M)度量来评估predicted map和ground-truth之间的像素级精度。然而,虽然MAE指标有助于评估错误的存在和数量,但无法确定错误发生的位置。最近,Fan等人提出了一种基于人类视觉感知的E-measure( E φ E_φ Eφ?)[74],它同时评估像素级匹配(pixel-level matching )和图像级统计(image-level statistics)。该指标自然适用于评估隐蔽目标检测结果的整体和局部精度。注意,我们在实验中报告了平均 E φ E_φ Eφ?。由于隐藏对象通常包含复杂的形状,COD还需要一个能够判断结构相似性的度量。因此,我们利用S-measure( S α S_α Sα?)[84]作为我们的结构相似性评估指标。
最后,最近的研究[74]、[84]表明,加权F-measure( F β w F^w_β Fβw?)[85]可以提供比传统 F β F_β Fβ?更可靠的评估结果。因此,我们进一步考虑将其作为COD的替代指标。我们的一个关键评估代码也可以在项目页面上找到。
5.1.2 Baseline Models 基础模型
我们根据以下标准选择了12条深度学习baselines【7】、【12】、【25】、【63】、【75】、【76】、【77】、【78】、【79】、【80】、【81】、【82】:
a)经典架构,b)最近发布,c)在特定领域实现SOTA性能
5.1.3 Training/Testing Protocols
为了与之前的版本【1】进行公平比较,我们对baselines采用了相同的训练设置【1】。我们在整个变色龙数据集以及CAMO和COD10K测试集上评估了模型。
5.2 结果和数据分析
本节分别提供了变色龙、迷彩和COD1K数据集的定量评估结果。
(这块有兴趣去看原论文吧)
5.3 消融实验
现在,我们详细分析了变色龙、迷彩和COD10K上的拟议SINet。我们通过解耦各种子组件(包括NCD、TEM和GRA)来验证有效性,如表6所示。注意,在每个消融变体的再培训过程中,我们保持第4.4节中提到的相同超参数。
6 下游应用
伪装目标检测系统在医学、艺术和农业等领域有着广泛的下游应用。在这里,由于这些应用程序的共同特性,我们设想了一些潜在的用途,其中目标对象与背景具有相似的外观。在这种情况下,COD模型非常适合作为这些应用程序的核心组件来挖掘伪装对象。请注意,这些应用程序只是激发未来研究有趣想法的玩具示例。
6.1 应用一:医药
6.1.1 息肉分割
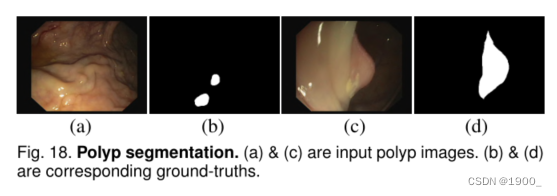
众所周知,通过医学影像进行早期诊断在疾病治疗中起着关键作用。然而,早期疾病区域/病变通常与周围组织具有高度的同质性。因此,医生很难在早期从医学图像中识别病变区域。一个典型的例子是对息肉进行早期结肠镜检查,这有助于降低大约30%的结直肠癌发病率[7]。与隐蔽目标检测类似,息肉分割(见图18)也面临一些挑战,例如外观变化和边界模糊。最近最先进的息肉分割模型PraNet【7】在息肉分割(Top1)和隐藏对象分割(TOP2)方面都显示出了良好的性能。从这个角度来看,将我们的SINet嵌入到这个应用程序中可能会获得更健壮的结果。
6.1.2 肺部感染细分
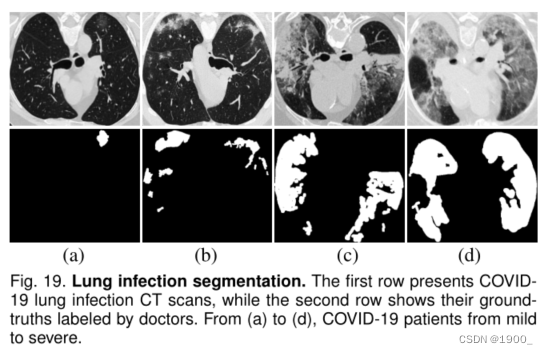
另一个隐藏对象检测示例是医学领域中的肺部感染分割任务。最近,2019冠状病毒疾病引起了特别关注,并导致了全球大流行。配备2019冠状病毒疾病肺部感染分割模型的AI系统将有助于2019冠状病毒疾病的早期筛查。有关此应用程序的更多详细信息,请参见最近的细分模型[8]和调查论文[92]。我们相信,使用2019冠状病毒疾病肺部感染分割数据集保留我们的SINet模型将是另一个有趣的潜在应用。
6.2 应用二:制造
6.2.1 表面缺陷检测
在工业制造业中,质量差的产品(如木材、纺织品和磁砖)将不可避免地对经济产生不利影响。从图20可以看出,表面缺陷具有挑战性,不同的因素包括低对比度、模糊边界等。由于传统的表面缺陷检测系统主要依赖于人,主要问题的识别非常主观且耗时。因此,设计一个基于人工智能的自动识别系统对于提高生产率至关重要。我们正在积极构建这样一个数据集,以推进相关研究。一些相关论文可在以下网址找到: https://github.com/Charmve/Surface-Defect-Detection/tree/master/Papers.

6.3 应用三:农业
6.3.1 害虫检测
自2020年初以来,从非洲到南亚,沙漠蝗灾席卷全球。大量蝗虫啃食农田,彻底摧毁农产品,造成严重的经济损失和粮食短缺造成的饥荒。如图21所示,引入基于AI的技术以提供科学监测,对于实现政府的可持续监管/遏制是可行的。为COD模型收集相关昆虫数据需要丰富的生物学知识,这也是该应用中面临的一个难题。
6.3.2 水果成熟度检测
在成熟的早期阶段,许多水果看起来像绿叶,这使得农民很难监控产量。我们在图22中展示了两种水果,即英仙花和杨梅。这些水果与隐蔽物体具有相似的特征,因此可以利用COD算法对其进行识别,提高监测效率

6.4 应用四:艺术
6.4.1 娱乐艺术
背景扭曲到隐藏的显著对象是SIGGRAPH社区中一项迷人的技术。图23显示了Chu等人在【9】中生成的一些示例。我们认为,这种技术将为现有的数据饥渴的深度学习模型提供更多的训练数据,因此,探索Treisman和Wolfe[93]、[94]所描述的特征搜索和连接搜索理论背后的潜在机制是有价值的。
6.4.2从隐蔽到突出的物体
隐蔽目标检测和显著目标检测是两个对立的任务,这使得我们可以方便地设计一个多任务学习框架,同时提高网络的鲁棒性。如图24所示,存在两个反向对象(a)和(c)。一个有趣的应用程序是提供一个滚动条,允许用户自定义隐藏对象中突出对象的程度。

6.5 应用五:日常生活
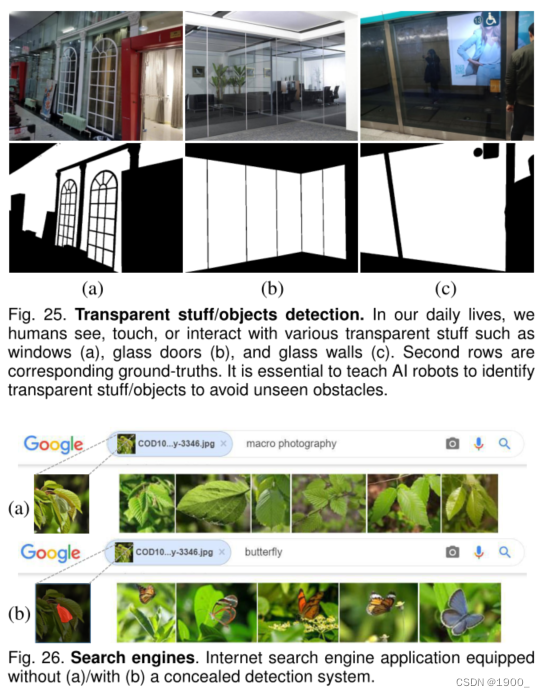
6.5.1透明材料/物体检测
透明物体,如玻璃制品,在我们的日常生活中很常见。如图25所示,包括门和墙在内的这些对象/事物继承了其背景的外观,使其不可见。作为隐蔽目标检测的一个子任务,透明目标检测[47]和透明目标跟踪[95]已显示出良好的前景。
6.5.2搜索引擎
图26显示了来自Google的搜索结果的示例。从结果中(图26 a),我们注意到搜索引擎无法检测到隐藏的蝴蝶,因此只提供具有类似背景的图像。有趣的是,当搜索引擎配备隐蔽检测系统时(这里,我们只需更改关键字),它可以识别隐藏的对象,然后反馈几个蝴蝶图像(图26 b)
7 潜在研究方向
(1) 弱\半监督检测:Weakly/Semi-Supervised Detection:
(2) 自我监督检测:Self-Supervised Detection:
(3) 其他方式的隐蔽物体检测:Concealed Object Detection in Other Modalities:
(4) 隐蔽物分类:Concealed Object Classification:
(5) 隐蔽物建议和跟踪:Concealed Object Proposal and Tracking:
(6) 隐蔽物等级:Concealed Object Ranking:
(7) 隐藏实例分段:Concealed Instance Segmentation:
(8) 多任务通用网络:Universal Network for Multiple Tasks:
(9) 神经架构搜索:Neural Architecture Search
(10) 将突出对象转换为隐藏对象: Transferring Salient Objects to Concealed Objects:
8 总结
我们首次从隐蔽视觉角度对目标检测进行了全面研究。具体而言,我们提供了新的具有挑战性且注释密集的COD10K数据集,进行了大规模基准测试,开发了一个简单但高效的端到端搜索和识别框架(即SINet),并重点介绍了几个潜在的应用。与现有的前沿基线相比,我们的SINet具有竞争力,并产生了更有利的视觉效果。上述贡献为社区提供了为COD任务设计新模型的机会。未来,我们计划扩展COD1K数据集,以提供各种形式的输入,例如多视图图像(例如RGB-D SOD[107]、[108])、文本描述、视频(例如VSOD[103]),等等。我们还计划自动搜索最佳感受野[109],并采用改进的特征表示[110],以获得更好的模型性能。