前情概括
词对齐任务分为三大实现方式,详情见词对齐任务概述,此为其一。
NMT依附下的word alignment
说道机翻显然就想到transformer,其encoder-decoder结构其实即便是在使用了lstm等模型上也是这样的,依附在NMT的word alignment任务就可以直接使用seq2seq的输出对输入的词attention(动图https://www.bilibili.com/video/BV1J441137V6,36:00)来表征word alignment。
词互信息(PMI)直算
这个是很intuitive的方法,我不使用任何模型,直接用概率统计的方法,算出两词间的互信息值,很多文章里叫PMI(pointwise mutual information),直接用这个值作为依据,填出词相关矩阵。
互信息是什么?这个场景下的互信息怎么算?见https://blog.csdn.net/index20001/article/details/79079031。
依附NMT的词对齐
这种形式的word alignment的最终解决方式是求得word的相关矩阵,用分数表示各个词的相关度,文章中名词叫做soft align。
经典seq2seq+att的模型和transformer based模型会在decoder阶段得到当前输出词与原sentence的词的attention,利用此可以组成相关矩阵。
对于老式的seq2seq+att来说,
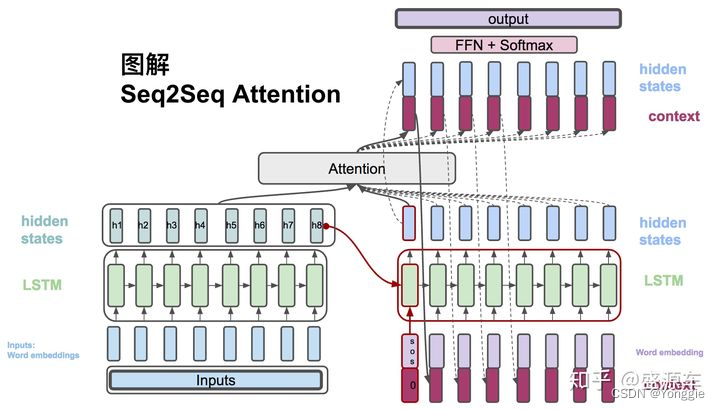
对于transformer来说,

值得注意的一点是,尽管bert是在transformer的基础上发展来的,只取了transformer的encoder,在文字理解、阅读等任务有广泛使用和很好成果,但是在机器翻译这一任务上bert encoder的表现 很一般 ,甚至不如lstm等老牌rnn,连带的word alignment也不算好(ACL 2019)。
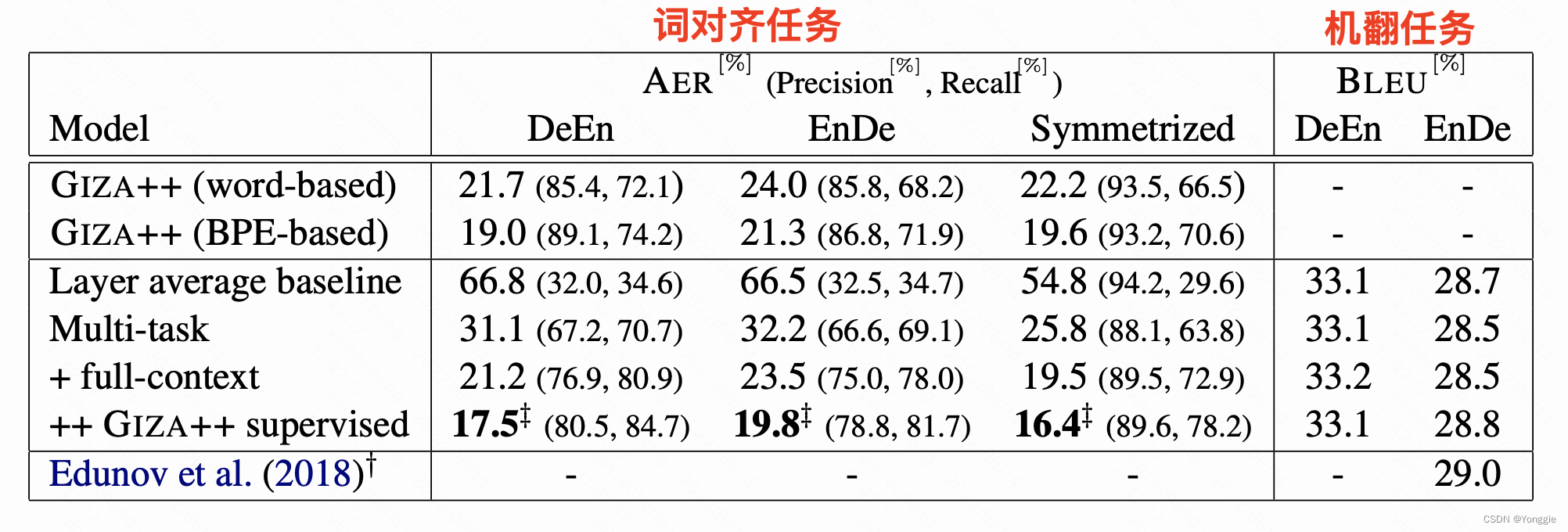
MT和词对齐都做得好 (EMNLP 2019)
文章简介挑明,尽管机翻任务NMT完爆SMT,但是词对齐任务概率统计方法仍然是上风
on the closely related task of word alignment, traditional statistical word alignment models often remain the go-to solution.
也就是尽管深度学习fancy一点,在词对齐任务上还是打不过概率统计模型。
本文提出既能很好的机翻,又能很好的词对齐的模型。
方法
在原有的transformer基础上,增加词对齐loss(文章标识为multi-task),和扩增了attention的范围(文章标识full-context)。
- 增加词对齐loss:新设立一个相关矩阵 G G G,拿transformer的倒数第二层的att做 G G G的label,用KL散度做词对齐的loss。
- 扩增attention:transformer原型decoder阶段只计算前方的att,但词对齐是不管先后的,此文扩增了att的范围,叫做full context。
eval
giza++做baseline,在使用了giza++做训练信息后的模型才能在词对齐任务上打败giza++。
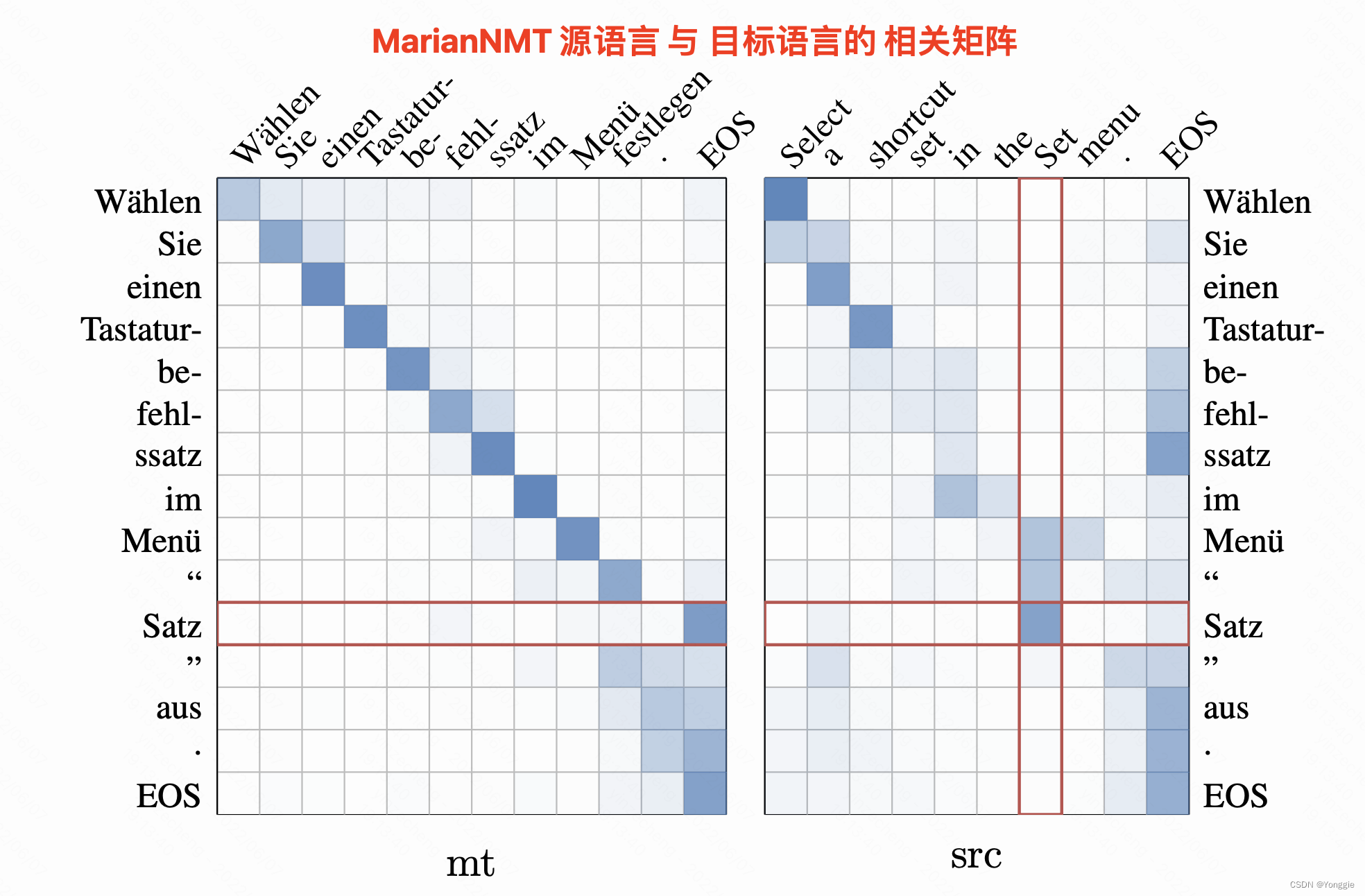
MarianNMT
本身是一个集合了很多seq2seq和transformer的机器翻译的工具箱,word alignment可以依附于机器翻译,使用src的word embedding与target embedding计算词汇的相关矩阵。
从可解释性角度进行word align (ACL 2019)
前言
文章借鉴了LRP删除法判断重要性的方法(ACL 2016)。
LRP最先在cv领域提出。具体来说,对于cv来说,删掉某一局部使得模型错判,则说明此部分对于结果是重要的。
在nlp中,上文提出直接把word embedding全0表示来“删除”这个word。
LRP能给出每个word对结果的相关值。
・
文章首先探索了使用bert的att的方法也不咋地,使用transformer做word alignment任务的话有些甚至不如用互信息(PMI)直算:
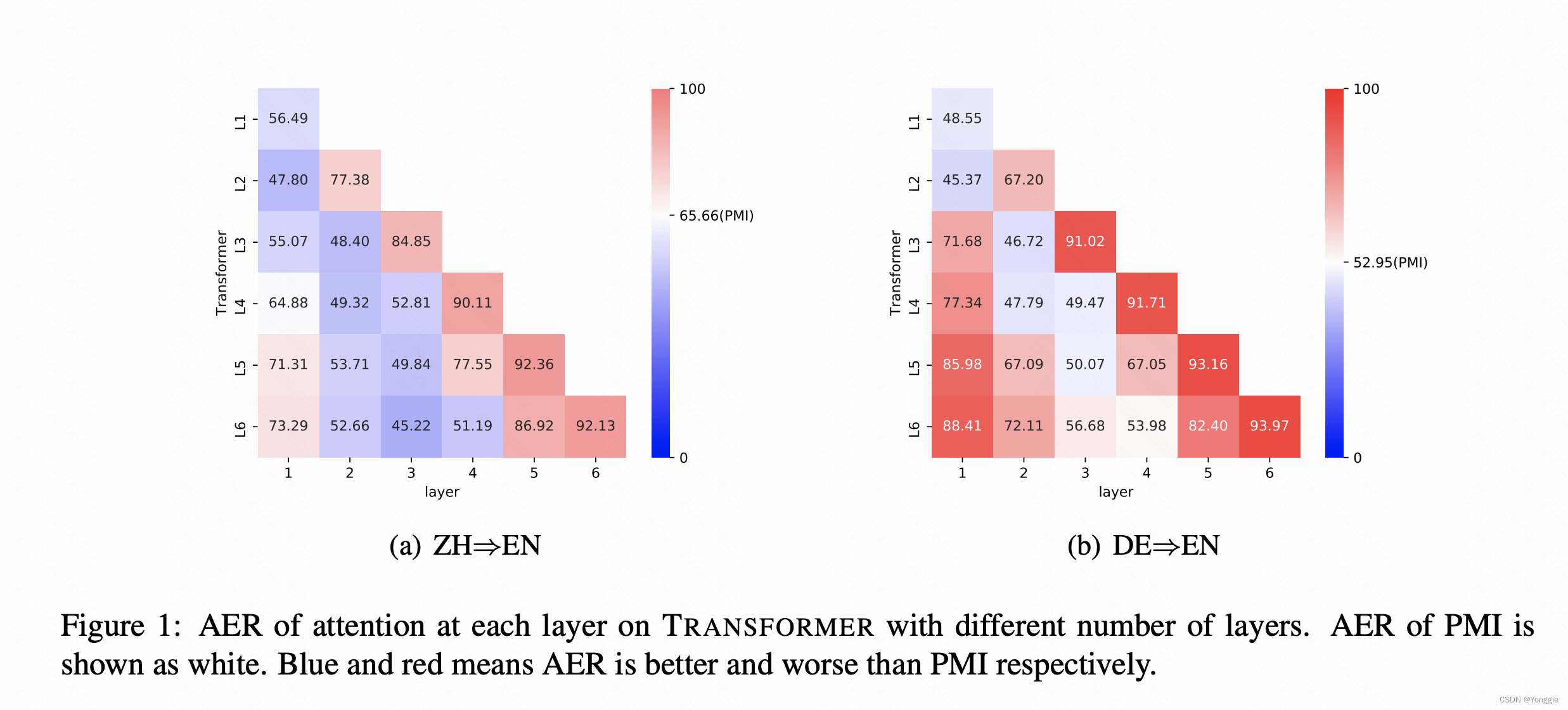
文章一共比较了
- 互信息直算(PMI)
- 用transformer attention
- 他的两种model agnostic的方法,一个叫PD,一个叫EAM
PD(prediction difference)方法
其方法如下,对于一个填词问题来说,把原sentence的某一个word
x
x
x替换成全0embedding,把替换前后的模型输出词
y
y
y的差值作为x与y的“相关度”。
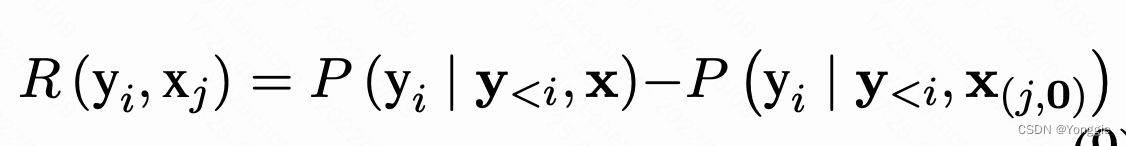
不同于直算或者attention方法的word alignment,本篇文章直接使用删除word对结果的差异大小来作为两个语言相关矩阵的值。
EAM(Explicit Alignment Model)方法
对于一个已经训练好的NMT模型,源语言的word x和目标语言的word y是这样算的:
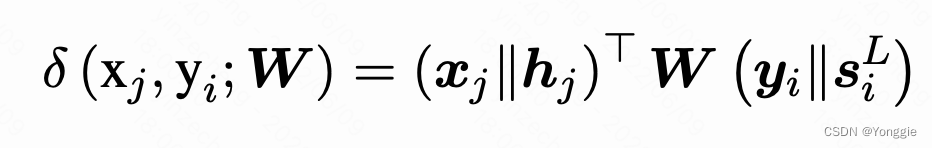

然后归一化一下
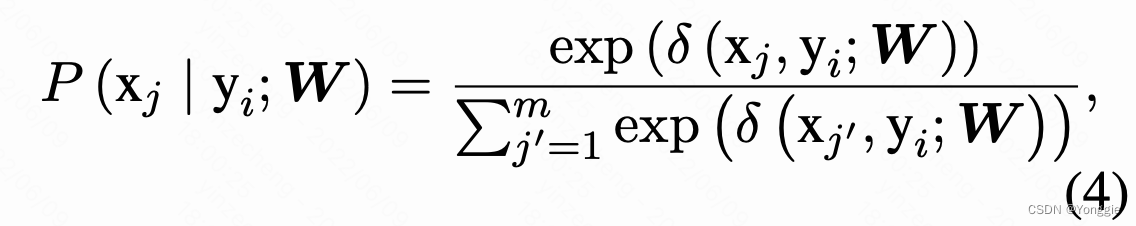
这个
W
W
W是要训练的。
结果
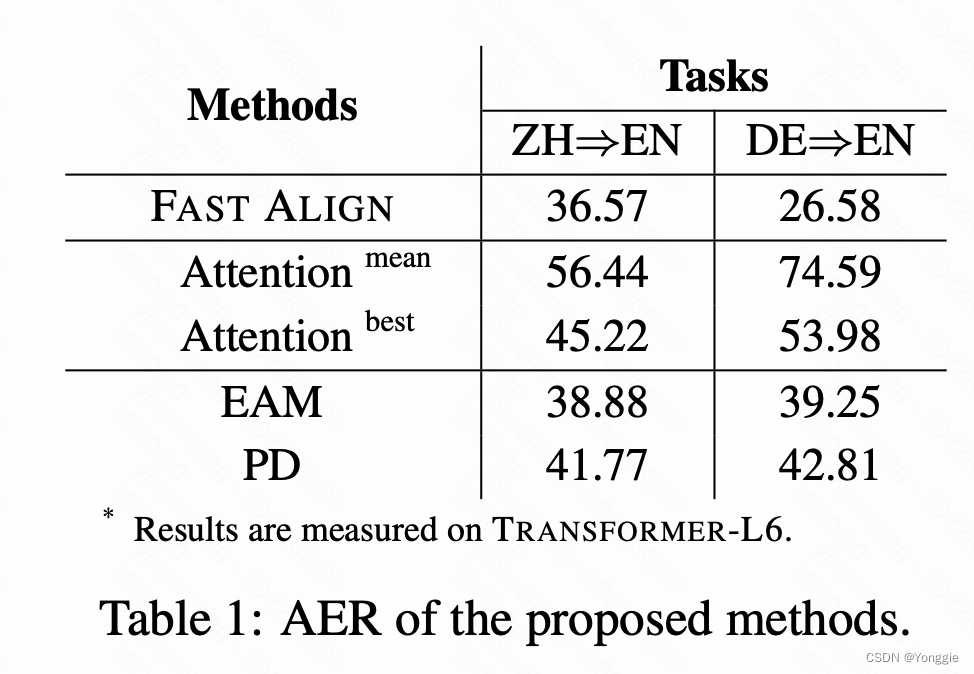
fast align是IBM mode 2的一个实现,就是纯概率统计模型的词对齐模型。AER是越小越好,这表只能看出,作者的EAM和PD比使用transformer的attention做词对齐好,但是比不上IBM model 2.
其实这个结果看了挺失望的,本来就是以词对齐为任务向导,结果搞了一顿这个方法还不如经典概率统计的结果……
但是看完还是有意义的,这篇文章给出了在训练好NMT模型后,想要附加一个词对齐的任务该如何下手。
小结
这篇文章从可解释性角度找了model agnostic的方法进行word alignment,而不是直接给出端到端的模型。
但是不管是EAM还是PD,都首先要有一个完全训练完成的NMT模型,对于EAM方法来说,还要再训一个
W
W
W。
可以这么说,文章的角度是机器翻译任务附带了词对齐任务,算个add on的加分项。